cdh集成apache phoenix
Apache-Phoenix
概述
ApachePhoenix是Apache HBase上一个高效的SQL引擎,通过标准的SQL语法来简化HBase的使用,并可以使用标准的JDBC连接HBase,而不是通过HBase的Java客户端APIs。它可以让你执行所有的CRUD和DDL操作,比如创建一张表,插入数据以及查询数据。SQL和JDBC可以大大减少用户代码的开发。
当Phoenix接收到SQL查询后,它会在本地编译成HBase的API,然后推到集群进行分布式的查询或计算。它自动创建了一个元数据库用来存储HBase的表的元数据信息。因为Phoenix是直接调用的HBase的API,coprocessors和自定义的filters,所以对于大量小查询可以实现毫秒级返回,千万级别的数据实现秒级返回。
使用场景
Phoenix非常适合HBase的随机访问,它的二级索引特性同时可以让你实现非主键查询的快速返回,而不需要进行全表扫描。它可以让你像传统数据库表的方式创建和管理HBase中的表,同时Phoenix也支持复合主键。
Phoenix可以给Rowkey加盐,从而避免因为简单递增的Rowkey引起的RegionServer热点问题。通过指定不同的租户连接实现数据访问的隔离,从而实现多租户,租户只能访问属于他的数据。
虽然Phoenix有这么多优势,但是它依旧无法替代RDBMS。比如它还有以下限制:
Phoenix不支持跨行的事务
查询优化和join机制比大多数RDBMS要简陋
二级索引是通过索引表实现的,主表和索引表的同步会存在问题,虽然只是在一段很短的时间内。所以索引无法完全满足ACID
多租户功能比较简单
与Hive/Impala的比较
Phoenix的目标是在HBase之上提供一个高效的类关系型数据库的工具,定位为低延时的查询应用,适合需要在HBase之上使用SQL实现CRUD
Impala则主要是基于HDFS的一些主流文件格式如文本或Parquet提供探索式的交互式查询,适合Ad-hoc的分析类工作负载。
Hive类似于数据仓库,定位为需要长时间运行的批作业。
Phoenix非常轻量级,因为它不需要额外的服务。
Phoenix还支持一些高级功能,比如多个二级索引,flashback查询等。无论是Impala还是Hive都无法提供二级索引支持。

安装
下载软件包
http://mirrors.hust.edu.cn/apache/phoenix/apache-phoenix-4.13.2-cdh5.11.2/parcels/
选择对应的操作系统版本(集群操作版本:centos6.8)

安装Apache-Phoenix
- 将Apache-Phoenix parcels上传到httpd服务下,默认路径:/var/www/html/,启动http服务

浏览器打开,如图:

- 配置Parcel

- 重新检查Parcel,执行下载与分配、激活

4.重启Hbase
使用
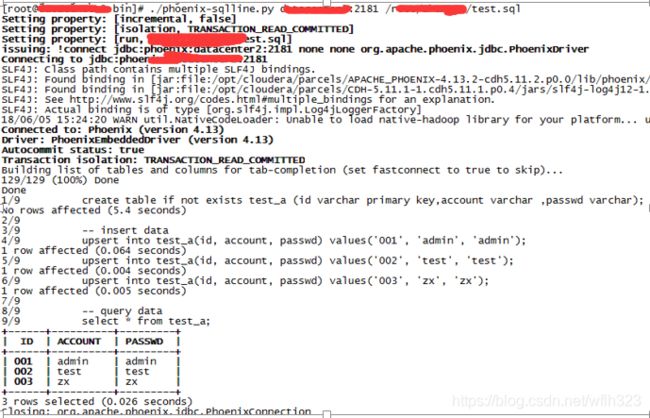
vi test.sql
create table if not exists test_a (id varchar primary key,account varchar ,passwd varchar);
-- insert data
upsert into test_a(id, account, passwd) values('001', 'admin', 'admin');
upsert into test_a(id, account, passwd) values('002', 'test', 'test');
upsert into test_a(id, account, passwd) values('003', 'zx', 'zx');
-- query data
select * from test_a;
进去 /usr/bin 目录
./phoenix-sqlline.py datacenter2:2181 /root/zhangye/test.sql