七大排序算法汇总(python实现)
关注“python趣味爱好者”公众号,回复“排序算法”获取源代码
目前,常见的排序算法有:
- 冒泡排序
- 插入排序
- 选择排序
- 堆排序
- 计数排序
- 快速排序
本篇文章将围绕这七大算法进行介绍,我们先来学习一下整体的代码结构:
class SORT(object):
def __init__(self):
self.arr = [20, 64, 34, 25, 12, 22, 11, 90]
self.n = len(self.arr)
self.num = 0
print(self.arr)
def out_put(self):
print(50*'-')
print ("最终排序结果", self.arr)
def bubbleSort(self): #冒泡排序
pass
def shellSort(self): #希尔排序
pass
def insertionSort(self): #插入排序
pass
def Selectionsort(self): #选择排序
pass
def heapSort(self): #堆排序
pass
def countSort(self): #计数排序
pass
def quickSort(self): #快速排序
pass
def main():
sort = SORT()
sort.bubbleSort() #冒泡排序
# sort.shellSort() #希尔排序
# sort.insertionSort() #插入排序
# sort.Selectionsort() #选择排序
# sort.heapSort() #堆排序
# sort.countSort() #计数排序
# sort.quickSort() #快速排序
sort.out_put()
if __name__ == '__main__':
main()
使用方法很简单,在__init__方法里的self.arr修改为自己的数据后,在main函数里选择自己想要使用的排序算法后,即可运行出结果:
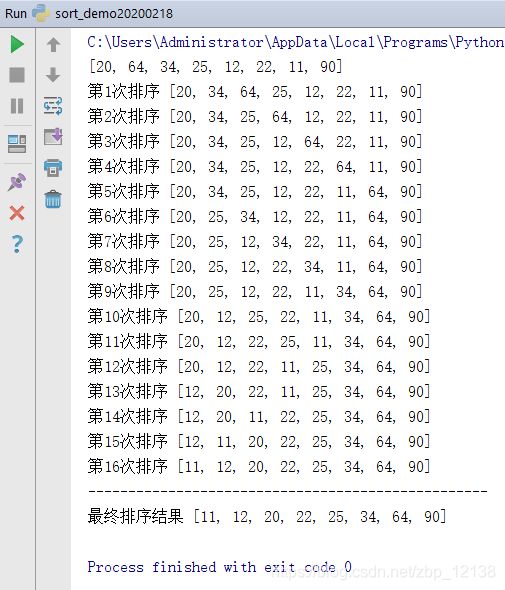
大家看看这是什么排序算法?能不能用一句话讲讲它的排序思路?试着在评论区留言哈!
我们先来看看冒泡排序:
def bubbleSort(self): #冒泡排序
# 遍历所有数组元素
for i in range(self.n):
# Last i elements are already in place
for j in range(0, self.n-i-1):
if self.arr[j] > self.arr[j+1] :
self.num += 1
self.arr[j], self.arr[j+1] = self.arr[j+1], self.arr[j]
print("第%d次排序"%self.num, self.arr)
冒泡冒泡,可以理解为水里的泡泡越大,浮力也越大,就越要往上走。
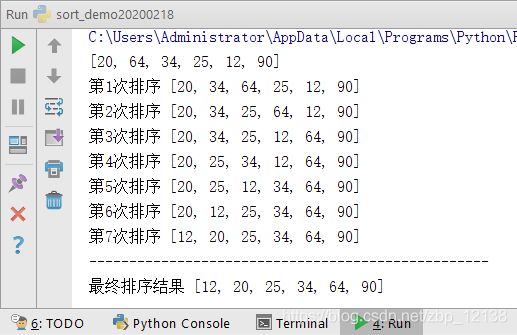
个人认为冒泡排序是最好理解的排序算法,因此放在了第一个来讲解。
下面讲讲插入排序:
def insertionSort(self): #插入排序
for i in range(1, len(self.arr)):
self.num += 1
key = self.arr[i]
j = i-1
while j >=0 and key < self.arr[j] :
self.arr[j+1] = self.arr[j]
j -= 1
self.arr[j+1] = key
print("第%d次排序"%self.num, self.arr)
先从待排序列表中选出一个值,作为监视哨(监视哨其实就是一个变量),然后把第一个数当作有序的,往后的每一个数都和有序数组里面的每一个数作比较,找到合适的位置插入,结果仍然是有序的。
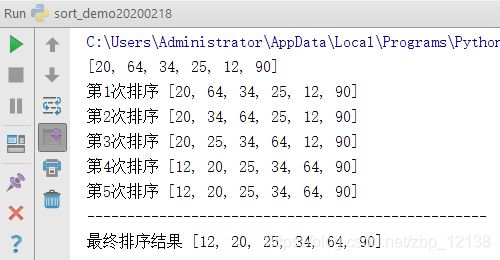
接下来是希尔排序,它的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
def shellSort(self): #希尔排序
gap = int(self.n/2)
while gap > 0:
for i in range(gap,self.n):
self.num += 1
temp = self.arr[i]
j = i
while j >= gap and self.arr[j-gap] >temp:
self.arr[j] = self.arr[j-gap]
j -= gap
self.arr[j] = temp
print("第%d次排序"%self.num, self.arr)
gap = int(gap/2)
因此说,希尔排序是插入排序的一种更高效的改进版本:
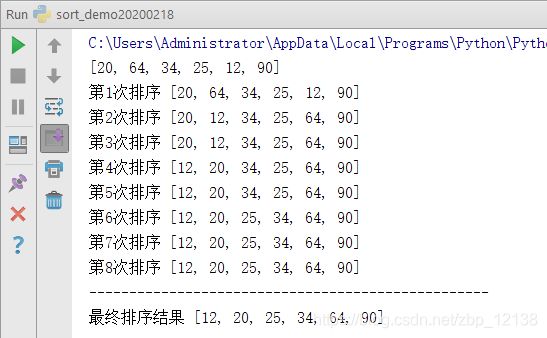
接下来是选择排序,它首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕:
def Selectionsort1(self): #选择排序
for i in range(len(self.arr)):
min_idx = i
self.num += 1
for j in range(i+1, len(self.arr)):
if self.arr[min_idx] > self.arr[j]:
min_idx = j
self.arr[i], self.arr[min_idx] = self.arr[min_idx], self.arr[i]
print("第%d次排序"%self.num, self.arr)
下面是选择排序的输出结果:

然后是计数排序:
def countSort(self): #计数排序
output = [0 for i in range(256)]
count = [0 for i in range(256)]
ans = ["" for _ in self.arr]
for i in self.arr:
count[i] += 1
for i in range(256):
count[i] += count[i-1]
for i in range(len(self.arr)):
output[count[self.arr[i]]-1] = self.arr[i]
count[self.arr[i]] -= 1
for i in range(len(self.arr)):
self.num += 1
ans[i] = output[i]
print("第%d次排序"%self.num, ans)
self.arr = ans
计数排序也很好理解,但是思路稍微想复杂了一点,我们都知道数轴上1,2,3,4…从小到大
计数排序的做法是,把数据一一存放起来,然后按大小顺序取出,也正因如此,输入的数据必须是有确定范围的整数。
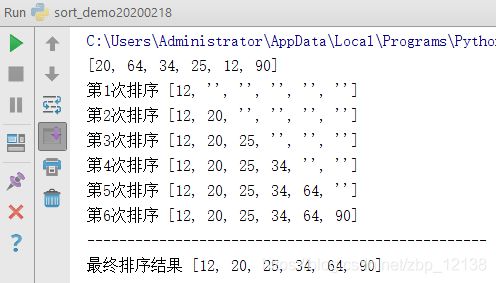
计数排序虽然理解起来不难,但是不推荐使用
再接下来是两个写起来比较复杂的排序算法:堆排序和快速排序
堆排序可以简单理解为,利用堆这种数据结构,找出最大的值,并排在最后面,结果与冒泡排序类似,每次都能找到一个最大值:
def heapify(self, arr, n, i):
largest = i
l = 2 * i + 1 # left = 2*i + 1
r = 2 * i + 2 # right = 2*i + 2
if l < n and self.arr[i] < self.arr[l]:
largest = l
if r < n and self.arr[largest] < self.arr[r]:
largest = r
if largest != i:
self.arr[i],self.arr[largest] = self.arr[largest],self.arr[i] # 交换
self.heapify(self.arr, n, largest)
def heapSort(self): #堆排序
n = len(self.arr)
# Build a maxheap.
for i in range(n, -1, -1):
self.heapify(self.arr, n, i)
# 一个个交换元素
for i in range(n-1, 0, -1):
self.num += 1
self.arr[i], self.arr[0] = self.arr[0], self.arr[i] # 交换
self.heapify(self.arr, i, 0)
print("第%d次排序"%self.num, self.arr)
具体的可以查看下面这篇文章:
https://www.cnblogs.com/chengxiao/p/6129630.html
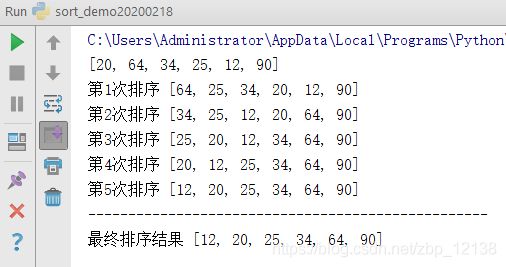
最后是快速排序,一般来说,快速排序是首选:
def partition(self, low, high):
i = ( low - 1 ) # 最小元素索引
pivot = self.arr[high]
for j in range(low , high):
self.num += 1
# 当前元素小于或等于 pivot
if self.arr[j] <= pivot:
i = i+1
self.arr[i],self.arr[j] = self.arr[j],self.arr[i]
print("第%d次排序"%self.num, self.arr)
self.arr[i+1],self.arr[high] = self.arr[high],self.arr[i+1]
return ( i+1 )
# arr[] --> 排序数组
# low --> 起始索引
# high --> 结束索引
# 快速排序函数
def quick_Sort(self, low, high):
n = len(self.arr)
if low < high:
pi = self.partition(low, high)
self.quick_Sort(low, pi-1)
self.quick_Sort(pi+1, high)
def quickSort(self):
self.quick_Sort(0, self.n-1)
简单来说,快速排序就是在区间中随机挑选一个元素作基准,将小于基准的元素放在基准之前,大于基准的元素放在基准之后,再分别对小数区与大数区进行排序:
- 首先设定一个分界值,通过该分界值将数组分成左右两部分。
- 将大于或等于分界值的数据集中到数组右边,小于分界值的数据集中到数组的左边。此时,左边部分中各元素都小于或等于分界值,而右边部分中各元素都大于或等于分界值。
- 然后,左边和右边的数据可以独立排序。对于左侧的数组数据,又可以取一个分界值,将该部分数据分成左右两部分,同样在左边放置较小值,右边放置较大值。右侧的数组数据也可以做类似处理。
重复上述过程,可以看出,这是一个递归定义。通过递归将左侧部分排好序后,再递归排好右侧部分的顺序。当左、右两个部分各数据排序完成后,整个数组的排序也就完成了。
想要了解更多排序算法,可以查看我的往期博客:
快速排序、冒泡排序和插入排序算法 实验笔记5(计算机软件基础)
最后,欢迎大家关注“python趣味爱好者”公众号,回复“排序算法”获取源代码:
