Pandas花式拼接表格数据(转)
如何用Pandas花式拼接表格数据
通常来说,我们需要的数据不可能都来自同一张表格,所以了解如何对不同格式的表格进行拼接、合并是非常重要的。
本文将介绍Pandas库中常用的合并表格的方法,包括.append(), pd.concat(), pd.merge(), 并配合实例进行讲解。
01
上下拼接
用.append()【1】方法可以实现表格的上下拼接,一般来说它们会有相同的列名,比如,上下拼接两只股票的日线数据。
import tushare as ts
import pandas as pd
pd.set_option('expand_frame_repr', False) # 显示所有列
ts.set_token('your token')
pro = ts.pro_api()
df = pro.daily(ts_code='000001.SZ', start_date='20180701', end_date='20180705')
df1 = pro.daily(ts_code='000002.SZ', start_date='20180701', end_date='20180705')
print(df)
print(df1)
ts_code trade_date open high low close pre_close change pct_chg vol amount
0 000001.SZ 20180705 8.62 8.73 8.55 8.60 8.61 -0.01 -0.12 835768.77 722169.579
1 000001.SZ 20180704 8.63 8.75 8.61 8.61 8.67 -0.06 -0.69 711153.37 617278.559
2 000001.SZ 20180703 8.69 8.70 8.45 8.67 8.61 0.06 0.70 1274838.57 1096657.033
3 000001.SZ 20180702 9.05 9.05 8.55 8.61 9.09 -0.48 -5.28 1315520.13 1158545.868
ts_code trade_date open high low close pre_close change pct_chg vol amount
0 000002.SZ 20180705 23.02 23.41 22.85 23.05 23.00 0.05 0.22 267278.61 619393.007
1 000002.SZ 20180704 23.46 23.75 23.00 23.00 23.42 -0.42 -1.79 249881.03 582470.214
2 000002.SZ 20180703 23.10 23.48 22.80 23.42 22.80 0.62 2.72 549964.88 1274023.575
3 000002.SZ 20180702 24.50 24.55 22.52 22.80 24.60 -1.80 -7.32 846203.86 1981131.638
print(df.append(df1))
ts_code trade_date open high low close pre_close change pct_chg vol amount
0 000001.SZ 20180705 8.62 8.73 8.55 8.60 8.61 -0.01 -0.12 835768.77 722169.579
1 000001.SZ 20180704 8.63 8.75 8.61 8.61 8.67 -0.06 -0.69 711153.37 617278.559
2 000001.SZ 20180703 8.69 8.70 8.45 8.67 8.61 0.06 0.70 1274838.57 1096657.033
3 000001.SZ 20180702 9.05 9.05 8.55 8.61 9.09 -0.48 -5.28 1315520.13 1158545.868
0 000002.SZ 20180705 23.02 23.41 22.85 23.05 23.00 0.05 0.22 267278.61 619393.007
1 000002.SZ 20180704 23.46 23.75 23.00 23.00 23.42 -0.42 -1.79 249881.03 582470.214
2 000002.SZ 20180703 23.10 23.48 22.80 23.42 22.80 0.62 2.72 549964.88 1274023.575
3 000002.SZ 20180702 24.50 24.55 22.52 22.80 24.60 -1.80 -7.32 846203.86 1981131.638表格df的数据在上,表格df1的数据在下,注意到拼接之后的索引并没有随新表更新,这一问题可以通过设置参数ignore_index=True来解决。
print(df.append(df1, ignore_index=True))
ts_code trade_date open high low close pre_close change pct_chg vol amount
0 000001.SZ 20180705 8.62 8.73 8.55 8.60 8.61 -0.01 -0.12 835768.77 722169.579
1 000001.SZ 20180704 8.63 8.75 8.61 8.61 8.67 -0.06 -0.69 711153.37 617278.559
2 000001.SZ 20180703 8.69 8.70 8.45 8.67 8.61 0.06 0.70 1274838.57 1096657.033
3 000001.SZ 20180702 9.05 9.05 8.55 8.61 9.09 -0.48 -5.28 1315520.13 1158545.868
4 000002.SZ 20180705 23.02 23.41 22.85 23.05 23.00 0.05 0.22 267278.61 619393.007
5 000002.SZ 20180704 23.46 23.75 23.00 23.00 23.42 -0.42 -1.79 249881.03 582470.214
6 000002.SZ 20180703 23.10 23.48 22.80 23.42 22.80 0.62 2.72 549964.88 1274023.575
7 000002.SZ 20180702 24.50 24.55 22.52 22.80 24.60 -1.80 -7.32 846203.86 1981131.638如果想要批量拼接,可以写一个循环,如将截至某日的所有上市公司股票日线数据拼接成一个大表格,示例中选取的时间段为'20180101'-'20180105',并只选取了前5只股票,效果如下。
df = pro.daily(trade_date='20180105')
code_list = df['ts_code'].tolist()[:5]
stock_data = pd.DataFrame()
for code in code_list:
print(code)
df = pro.daily(ts_code=code, start_date='20180101', end_date='20180105')
stock_data = stock_data.append(df, ignore_index=True)
print(stock_data)
600863.SH
000001.SZ
000002.SZ
000004.SZ
000005.SZ
ts_code trade_date open high low close pre_close change pct_chg vol amount
0 600863.SH 20180105 3.04 3.04 3.00 3.01 3.02 -0.01 -0.33 101317.50 30551.982
1 600863.SH 20180104 3.01 3.03 2.99 3.02 3.00 0.02 0.67 139274.37 41969.249
2 600863.SH 20180103 2.99 3.01 2.98 3.00 2.98 0.02 0.67 113068.36 33859.869
3 600863.SH 20180102 2.97 2.99 2.97 2.98 2.97 0.01 0.34 87204.89 25997.338
4 000001.SZ 20180105 13.21 13.35 13.15 13.30 13.25 0.05 0.38 1210312.72 1603289.517
5 000001.SZ 20180104 13.32 13.37 13.13 13.25 13.33 -0.08 -0.60 1854509.48 2454543.516
6 000001.SZ 20180103 13.73 13.86 13.20 13.33 13.70 -0.37 -2.70 2962498.38 4006220.766
7 000001.SZ 20180102 13.35 13.93 13.32 13.70 13.30 0.40 3.01 2081592.55 2856543.822
8 000002.SZ 20180105 32.98 35.88 32.80 34.76 33.12 1.64 4.95 843101.96 2916787.871
9 000002.SZ 20180104 32.76 33.53 32.10 33.12 32.33 0.79 2.44 529085.80 1740602.533
10 000002.SZ 20180103 32.50 33.78 32.23 32.33 32.56 -0.23 -0.71 646870.20 2130249.691
11 000002.SZ 20180102 31.45 32.99 31.45 32.56 31.06 1.50 4.83 683433.50 2218502.766
12 000004.SZ 20180105 23.23 23.47 22.85 23.18 23.24 -0.06 -0.26 10444.04 24273.307
13 000004.SZ 20180104 23.80 23.83 23.12 23.24 23.80 -0.56 -2.35 14540.66 33908.548
14 000004.SZ 20180103 22.42 23.89 22.27 23.80 22.34 1.46 6.54 18795.39 43218.416
15 000004.SZ 20180102 22.29 22.49 22.00 22.34 22.38 -0.04 -0.18 6261.81 13951.004
16 000005.SZ 20180105 4.26 4.45 4.26 4.34 4.29 0.05 1.17 85226.27 37286.935
17 000005.SZ 20180104 4.27 4.33 4.23 4.29 4.27 0.02 0.47 43809.78 18732.178
18 000005.SZ 20180103 4.35 4.35 4.22 4.27 4.32 -0.05 -1.16 67990.65 28966.791
19 000005.SZ 20180102 4.15 4.50 4.15 4.32 4.14 0.18 4.35 71539.34 30529.757用pd.concat()【2】也能实现上面的效果,同样通过设置参数ignore_index=True来解决索引问题,这里的axis=0为默认值,默认按行拼接。
print(pd.concat([df, df1], axis=0, ignore_index=True))
ts_code trade_date open high low close pre_close change pct_chg vol amount
0 000001.SZ 20180705 8.62 8.73 8.55 8.60 8.61 -0.01 -0.12 835768.77 722169.579
1 000001.SZ 20180704 8.63 8.75 8.61 8.61 8.67 -0.06 -0.69 711153.37 617278.559
2 000001.SZ 20180703 8.69 8.70 8.45 8.67 8.61 0.06 0.70 1274838.57 1096657.033
3 000001.SZ 20180702 9.05 9.05 8.55 8.61 9.09 -0.48 -5.28 1315520.13 1158545.868
4 000002.SZ 20180705 23.02 23.41 22.85 23.05 23.00 0.05 0.22 267278.61 619393.007
5 000002.SZ 20180704 23.46 23.75 23.00 23.00 23.42 -0.42 -1.79 249881.03 582470.214
6 000002.SZ 20180703 23.10 23.48 22.80 23.42 22.80 0.62 2.72 549964.88 1274023.575
7 000002.SZ 20180702 24.50 24.55 22.52 22.80 24.60 -1.80 -7.32 846203.86 1981131.63802
左右拼接
pd.concat()不仅能够实现上下拼接,而且还能通过设置参数axis=1实现左右拼接。以拼接两个不同长度的表格为例,没有值的位置会自动填充为NaN。
print(df)
ts_code trade_date close
0 000001.SZ 20180705 8.60
1 000001.SZ 20180704 8.61
2 000001.SZ 20180703 8.67
3 000001.SZ 20180702 8.61
print(df1)
ts_code trade_date close
0 000002.SZ 20180709 24.01
1 000002.SZ 20180706 23.21
2 000002.SZ 20180705 23.05
3 000002.SZ 20180704 23.00
4 000002.SZ 20180703 23.42
5 000002.SZ 20180702 22.80
print(pd.concat([df, df1], axis=1))
ts_code trade_date close ts_code trade_date close
0 000001.SZ 20180705 8.60 000002.SZ 20180709 24.01
1 000001.SZ 20180704 8.61 000002.SZ 20180706 23.21
2 000001.SZ 20180703 8.67 000002.SZ 20180705 23.05
3 000001.SZ 20180702 8.61 000002.SZ 20180704 23.00
4 NaN NaN NaN 000002.SZ 20180703 23.42
5 NaN NaN NaN 000002.SZ 20180702 22.80如果想要按列拼接有相同索引的行,可以设置参数join='inner',设置参数sort=True升序排列。以两个索引为时间的表格为例,效果如下。
print(df)
ts_code close
trade_date
20180705 000001.SZ 8.60
20180704 000001.SZ 8.61
20180703 000001.SZ 8.67
20180702 000001.SZ 8.61
print(df1)
ts_code close
trade_date
20180709 000002.SZ 24.01
20180706 000002.SZ 23.21
20180705 000002.SZ 23.05
20180704 000002.SZ 23.00
20180703 000002.SZ 23.42
20180702 000002.SZ 22.80
print(pd.concat([df, df1], axis=1, join='inner', sort=True))
ts_code close ts_code close
trade_date
20180702 000001.SZ 8.61 000002.SZ 22.80
20180703 000001.SZ 8.67 000002.SZ 23.42
20180704 000001.SZ 8.61 000002.SZ 23.00
20180705 000001.SZ 8.60 000002.SZ 23.0503
合并表格
pd.merge()【3】方法可以实现表格之间的合并操作,类似于SQL中的连接JOIN的用法。通过设置参数how='left', 'right', 'outer', 'inner',默认为 'inner' ,实现不同形式的合并。
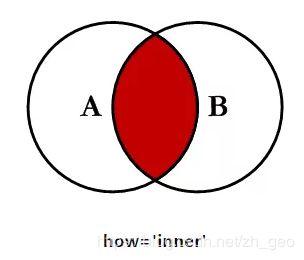
how='inner'
设置参数on='trade_date' 表示两个表格将按照列'trade_date' 中的值进行合并,当参数how为默认值'inner'时,结果和用pd.concat()方法设置参数join='inner'得到的类似。
区别在于,pd.merge()操作会自动为合并前有相同列名、不同值的列名添加后缀,以便我们进行区分,如下所示的'close_x'和'close_y'。
如果想要让后缀名变得更有意义,可以通过设置参数suffixes=['_000001', '_000002']实现。
print(df)
ts_code close
trade_date
20180705 000001.SZ 8.60
20180704 000001.SZ 8.61
20180703 000001.SZ 8.67
20180702 000001.SZ 8.61
print(df1)
ts_code close
trade_date
20180709 000002.SZ 24.01
20180706 000002.SZ 23.21
20180705 000002.SZ 23.05
20180704 000002.SZ 23.00
20180703 000002.SZ 23.42
20180702 000002.SZ 22.80
print(df.merge(df1, on='trade_date', sort=True))
ts_code_x close_x ts_code_y close_y
trade_date
20180702 000001.SZ 8.61 000002.SZ 22.80
20180703 000001.SZ 8.67 000002.SZ 23.42
20180704 000001.SZ 8.61 000002.SZ 23.00
20180705 000001.SZ 8.60 000002.SZ 23.05
print(df.merge(df1, on='trade_date', sort=True, suffixes=['_000001', '_000002']))
ts_code_000001 close_000001 ts_code_000002 close_000002
trade_date
20180702 000001.SZ 8.61 000002.SZ 22.80
20180703 000001.SZ 8.67 000002.SZ 23.42
20180704 000001.SZ 8.61 000002.SZ 23.00
20180705 000001.SZ 8.60 000002.SZ 23.05如果两个表格中想要进行合并的列名不同,如下所示的表格df中的交易日期列名为'trade_date_stock',表格df_index中的交易日期列名为'trade_date',这时需要我们设置参数left_on和right_on指定要进行合并的列名。
print(df)
ts_code trade_date_stock close
0 000001.SZ 20180704 8.61
1 000001.SZ 20180703 8.67
2 000001.SZ 20180702 8.61
print(df1)
ts_code trade_date close
0 399300.SZ 20180706 3365.1227
1 399300.SZ 20180705 3342.4379
2 399300.SZ 20180704 3363.7473
3 399300.SZ 20180703 3409.2801
4 399300.SZ 20180702 3407.9638
print(df.merge(df_index, left_on='trade_date_stock', right_on='trade_date', sort=True))
ts_code_x trade_date_stock close_x ts_code_y trade_date close_y
0 000001.SZ 20180702 8.61 399300.SZ 20180702 3407.9638
1 000001.SZ 20180703 8.67 399300.SZ 20180703 3409.2801
2 000001.SZ 20180704 8.61 399300.SZ 20180704 3363.7473参数on也可以传入一个包含多个列名的list,如['ts_code', 'trade_date'],此时在默认how='inner'的情况下, 合并后只会返回['ts_code', 'trade_date']值在两个表格中都相等的行。
print(df)
ts_code trade_date close
0 000001.SZ 20180706 8.66
1 000001.SZ 20180705 8.60
2 000001.SZ 20180704 8.61
3 000001.SZ 20180703 8.67
4 000001.SZ 20180702 8.61
print(df1)
ts_code trade_date turnover_rate volume_ratio pe pb
0 000001.SZ 20180702 0.7662 1.28 6.3753 0.7267
0 000001.SZ 20180703 0.7425 1.21 6.4197 0.7318
combined = pd.merge(left=df, right=df1, on=['ts_code', 'trade_date'], sort=True)
print(combined)
ts_code trade_date close turnover_rate volume_ratio pe pb
0 000001.SZ 20180702 8.61 0.7662 1.28 6.3753 0.7267
1 000001.SZ 20180703 8.67 0.7425 1.21 6.4197 0.7318我们还可以通过设置参数how='left', how='right', how='outer', 分别进行左连接、右连接和外连接。
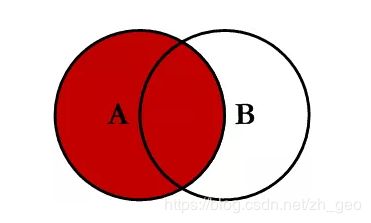
how='left'
左连接的示意图如上所示,从下面示例代码返回的结果可以观察到,左连接会保留左侧表格的所有数据,以及两个表格按照on设置的条件合并后重合的部分,没有数据的地方会自动填充NaN值。
print(df)
ts_code trade_date close
0 000001.SZ 20180706 8.66
1 000001.SZ 20180705 8.60
2 000001.SZ 20180704 8.61
3 000001.SZ 20180703 8.67
4 000001.SZ 20180702 8.61
print(df1)
ts_code trade_date turnover_rate volume_ratio pe pb
0 000001.SZ 20180702 0.7662 1.28 6.3753 0.7267
0 000001.SZ 20180703 0.7425 1.21 6.4197 0.7318
combined = pd.merge(df, df1, how='left', on=['ts_code', 'trade_date'], sort=True)
print(combined)
ts_code trade_date close turnover_rate volume_ratio pe pb
0 000001.SZ 20180702 8.61 0.7662 1.28 6.3753 0.7267
1 000001.SZ 20180703 8.67 0.7425 1.21 6.4197 0.7318
2 000001.SZ 20180704 8.61 NaN NaN NaN NaN
3 000001.SZ 20180705 8.60 NaN NaN NaN NaN
4 000001.SZ 20180706 8.66 NaN NaN NaN NaN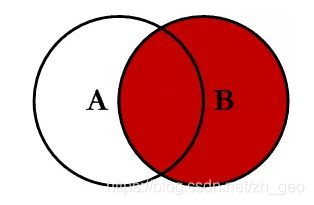
how='right'
同理,右连接则会保留右侧表格的所有数据,以及两个表格按照on设置的条件合并后重合的部分,没有数据的地方会自动填充NaN值。
print(df)
ts_code trade_date close
0 000001.SZ 20180706 8.66
1 000001.SZ 20180705 8.60
2 000001.SZ 20180704 8.61
3 000001.SZ 20180703 8.67
4 000001.SZ 20180702 8.61
print(df1)
ts_code trade_date turnover_rate volume_ratio pe pb
0 000001.SZ 20180702 0.7662 1.28 6.3753 0.7267
0 000001.SZ 20180703 0.7425 1.21 6.4197 0.7318
combined = pd.merge(df, df1, how='right', on=['ts_code', 'trade_date'], sort=True)
print(combined)
ts_code trade_date close turnover_rate volume_ratio pe pb
0 000001.SZ 20180702 8.61 0.7662 1.28 6.3753 0.7267
1 000001.SZ 20180703 8.67 0.7425 1.21 6.4197 0.7318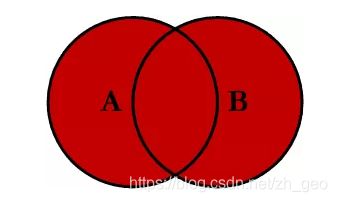
how='outer'
外连接的示意图如上所示,返回满足合并条件的所有行,没有数据的地方会自动填充NaN值。
print(df)
ts_code trade_date close
0 000001.SZ 20180706 8.66
1 000001.SZ 20180705 8.60
2 000001.SZ 20180704 8.61
3 000001.SZ 20180703 8.67
4 000001.SZ 20180702 8.61
print(df1)
ts_code trade_date turnover_rate volume_ratio pe pb
0 000001.SZ 20180706 0.5756 1.03 6.4123 0.7309
0 000001.SZ 20180709 0.8212 1.38 6.6863 0.7621
0 000001.SZ 20180710 0.5223 0.86 6.6493 0.7579
combined = pd.merge(df, df1, how='outer', on=['ts_code', 'trade_date'], sort=True)
print(combined)
ts_code trade_date close turnover_rate volume_ratio pe pb
0 000001.SZ 20180702 8.61 NaN NaN NaN NaN
1 000001.SZ 20180703 8.67 NaN NaN NaN NaN
2 000001.SZ 20180704 8.61 NaN NaN NaN NaN
3 000001.SZ 20180705 8.60 NaN NaN NaN NaN
4 000001.SZ 20180706 8.66 0.5756 1.03 6.4123 0.7309
5 000001.SZ 20180709 NaN 0.8212 1.38 6.6863 0.7621
6 000001.SZ 20180710 NaN 0.5223 0.86 6.6493 0.757904
总结
本文介绍了Pandas中常用的合并表格的方法,分别为.append(), pd.concat()和pd.merge(),我们观察到,通过设置不同的参数值,可以对表格进行不同形式的拼接、合并操作。