Linux下的sed工具及awk工具的使用
在Linux下的sed工具和awk工具是最常用的文本处理工具,配合grep的使用将产生非常大的威力,下面就来说一下sed和awk的基础用法,
sed基本用法如下:
sed命令的语法如下所示:
sed [-nefr] [动作]参数说明:
-n : 使用安静模式,一般所有来自STDIN的数据会被列出到屏幕上,但是 -n 在可以只列出经过 sed 处理过的那一行。
-e : 直接在命令行模式上进行 sed 的动作编辑。
-f : 直接将 sed 的动作卸载一个文件内, -f filename 则可以执行 filename 内的 sed 动作。
-r : sed 的动作支持的是扩展型正则表达式的语法(默认是基础正则表达式语法)。
-i : 直接修改读取的文件内容,而不是由屏幕输出。
动作说明: [n1],[n2] function
n1,n2:不见得会存在,一般代表选择进行动作的行数。
举例来说:如果我的动作是需要在 10 到 20 行之间进行的,则“10,20[动作行为]”
function 有下面这些参数:
a:新增,a 的后面可以接字符串,而这些字符串会在新的一行出现(目前的下一行)。
c:替换,c 的后面可以接字符串,这些字符串可以替换n1,n2之间的行!
d:删除,因为是删除,所以 d 后面通常不接任何参数。
i:插入,i 的后面可以接字符串,而这些字符串会在新的一行出现(目前的上一行)。
p:打印,也就是将某个选择的数据打印出来,通常 p 会与参数 sed -n 一起运行。
s:替换,可以直接进行替换工作。通常这个 s 的动作可以匹配正则表达式!
例如:1,20s/old/new/g 就是。
先练练手,把test文件中的第一行末尾追加一个“OK”,要求不换行
命令如下:
TEMP=$(sed -n "1p" test)
APPEND="OK"
TEMP=${TEMP}${APPEND}
sed -i "719c ${TEMP}" test
以一个日志文件为例,我的日志消息如下

用sed命令配合grep显示第1到第10行所有INFO消息,并将消息输入到新的文件中去
命令![]() (>将文件中所有信息清除,然后输出到文件,>>直接输出到现有文件里,从原文件末端开始写入)
(>将文件中所有信息清除,然后输出到文件,>>直接输出到现有文件里,从原文件末端开始写入)
效果
说完sed,再来说说awk:sed主要是对于行来进行操作,而awk相当与将每一行每一个字段分开再做处理,awk分析字段靠的是空格符,例如提取,awk基本用法
基本语法
awk '条件类型1{动作1} 条件类型2{动作2} ...' filename-
awk 后面接两个单引号病加上大括号{}来设置想要对数据进行的处理动作。
-
awk 可以处理后续接的文件,也可以读取来自签个命令的 standardoutput。
-
如前面说的,awk 主要是处理每一行的字段内的数据,而默认的字段的分隔符为空格键或者[tab]键。 比如:
last -n 5 // 仅取出登陆者的数据前五行(last 可以将登陆者的数据取出来)如果我还要在这些信息中取出:账号与登陆者的IP,且账号与IP之间以[tab]隔开,那么可以这么改命令:
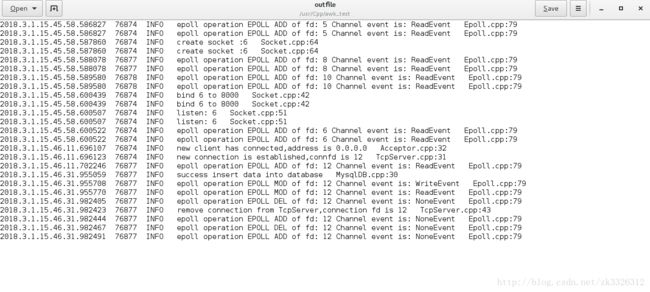
last -n 5 | awk '{print $1 "\t" $3}'下面还是以test日志为例,我想要取出前10条信息中的INFO信息中的前3列信息,第一列和第二列以tab空格分开,第二列和第三列以空格分开,然后输出到outfile代码如下:
sed '1,10p' test| grep "INFO"|awk '{print $1,"\t",$2,$3}' >outfile
效果如下

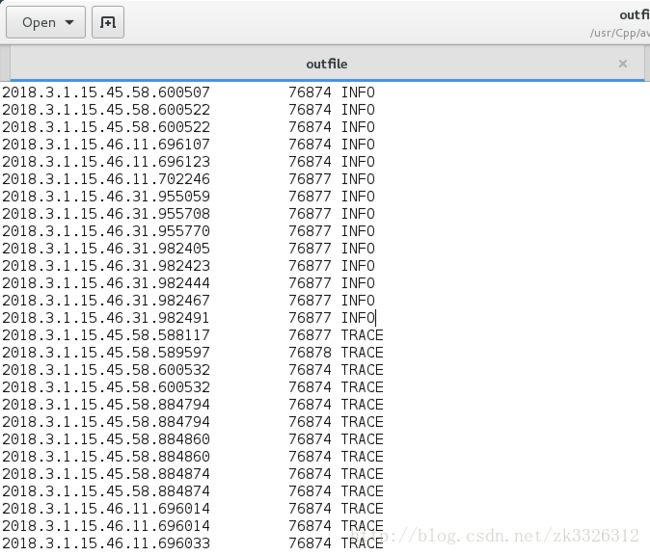
然后再将test的10到20行中的TRACE信息的1到3列提去出添加到outfile,命令如下
sed '10,20p' test | grep "TRACE" | awk '{print $1,"\t",$2,$3}' >>outfile
效果如下
然后再利用awk工具提取outfile中第二列等于 76874 且第三列等于TRACE的消息
awk '$2==76874&&$3=="TRACE" {print $1}' outfile
效果如下
