Python爬虫-头条街拍(Ajax处理)
目标
爬取今日头条街拍内容中前20组照片(如下图),保存至本地
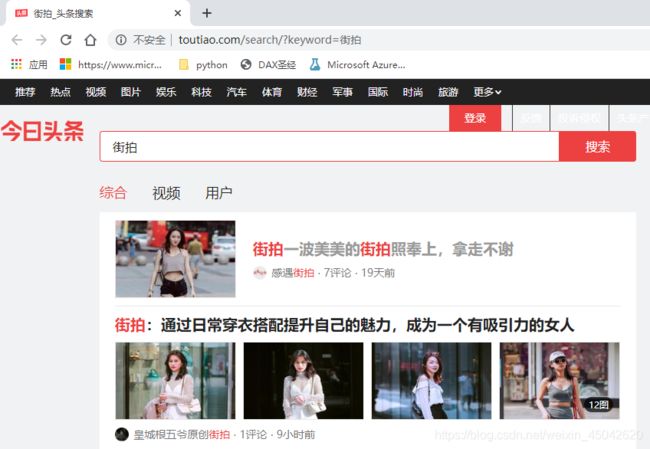
网址:https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D
探索
探索1:通过request.get方法解析出来的文本中,无法获取任何图片信息;
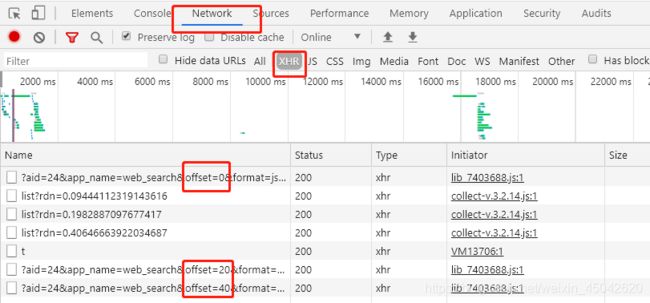
探索2:F12打开开发者模式,选择Network,再选择XHR,将左侧网页的滑块往下拉,可以看到有相似标题内容陆续被加载出来(Ajax),这些相似标题就是Request URL,对比发现只有offset值不一样,依次是0,20,40.。。
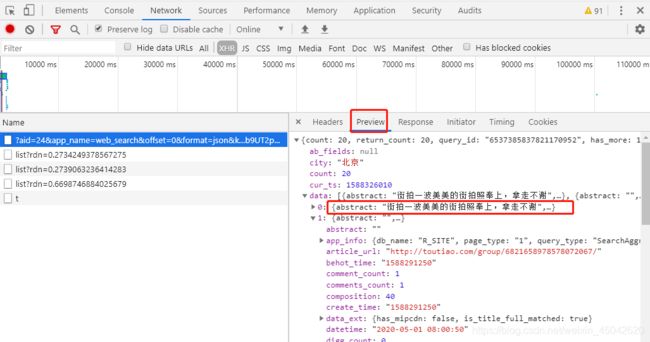
探索3:查看返回的第一个结果:通过Preview发现该返回结果为json形式,且内容中有和第一组图片标题一致的内容;
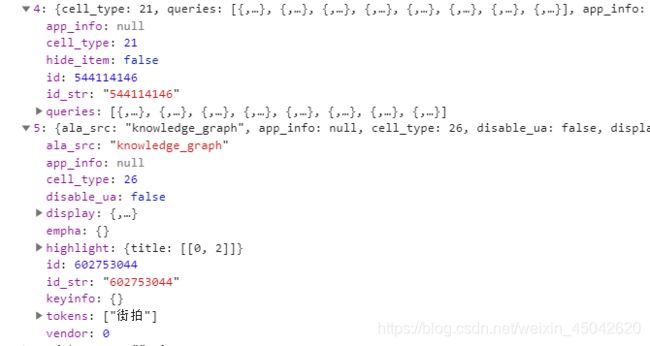
探索4:查看列表的第二项,看看有没有什么规律。可以看到article_url中有指向组图的链接,display中有组图标题内容

探索5:依次查看其他,标签4和标签5中的内容和其他不一样(有的是视频而非图片)
探索6:打开article_url,发现存在两种图片展示方式,有的从左往右,有的从上往下,两种方式的源代码不一样。相同的地方是两种方式都是加载出全部的图片url信息

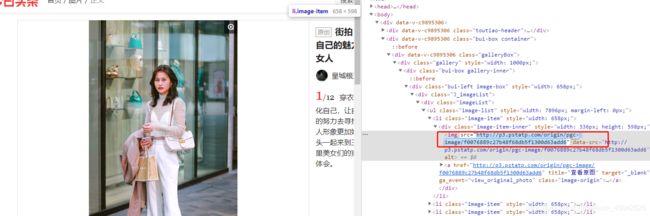
爬虫实施
Step1:设置好请求头参数,URL中假设offset=0
import requests
headers={"host":"www.toutiao.com",
"cookie":"tt_webid=6771665033070413325; s_v_web_id=54da78348aebf667cff9db7c37ecb1b1; WEATHER_CITY=%E5%8C%97%E4%BA%AC; __tasessionId=7nkj4w0441576651144543; csrftoken=cba7b413a5c2925800aa2a4762f6fbc9; tt_webid=6771665033070413325",
"referer":"https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36",
"x-requested-with":"XMLHttpRequest"}
url="https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1588314966137&_signature=MzBQ1AAgEBD1Z-lZJlToqDMxEcAAG2iNKTLZI.VCo-DQwfESov-7ms6xg0ej2dx8zSxxip51qXqsJfpFQ6xi3xytTApWbhJNuEYAmBiJZOLZdcRKZlJhg3ugx1K9AIS0x6l"
r=requests.get(url=url,headers=headers)
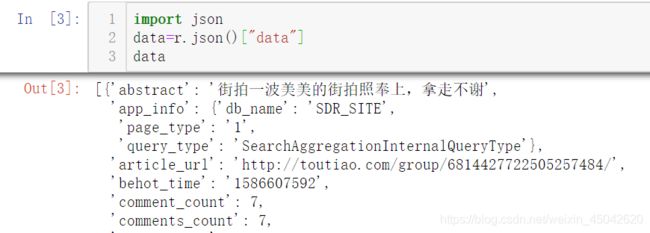
Step2:解析json数据
import json
data=r.json()["data"]
data
Step3:遍历组图列表,提取组图标题和链接
for i in range(20):
try:
title=data[i]['display']['title']['text']
article_url=data[i]['article_url']
except:
continue
因为有的编号中没有组图标题和链接信息,如探索第4步所示,所以此处使用try except语句防止报错
Step4:以第一组图(自上而下展示)和第二组图(自左向右展示)为例,获取组图中每一张图片的url
第一组:
from selenium import webdriver
import time
article_url=data[0]['article_url']
driver = webdriver.Chrome(r"C:\Users\ThinkPad\AppData\Local\Google\Chrome\Application\chromedriver.exe")
driver.get(article_url)
time.sleep(2)
text=driver.page_source
from lxml import etree
html=etree.HTML(text)
hrefs=html.xpath('//div[@class="article-content"]/div[@class="pgc-img"]/img/@src')
第一组组图中的12张图的url获取结果如下:

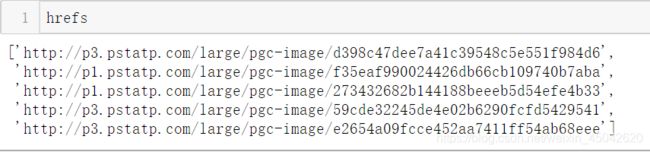
第二组:
from selenium import webdriver
import time
article_url=data[1]['article_url']
driver = webdriver.Chrome(r"C:\Users\ThinkPad\AppData\Local\Google\Chrome\Application\chromedriver.exe")
driver.get(article_url)
time.sleep(2)
text=driver.page_source
from lxml import etree
html=etree.HTML(text)
hrefs=html.xpath('//ul[@class="image-list"]/li[@class="image-item"]/div/a/@href')
第二组组图中的5张图的url获取结果如下:
Step5:以第一组的12张图为例,根据图片url获取信息,保存至本地
import os
from hashlib import md5
os.chdir(r"E:\Py codes\spider")
title=data[0]['title']
os.mkdir(title)
for href in hrefs:
r1=requests.get(href)
file_path='{}/{}.{}'.format(title,md5(r1.content).hexdigest(),'jpg')
with open(file_path,'wb') as f:
f.write(r1.content)
结果如下:

完整代码:
import os
from hashlib import md5
from selenium import webdriver
import time
import requests
import json
from lxml import etree
#首页请求
def get_response(url):
headers={"host":"www.toutiao.com",
"cookie":"tt_webid=6771665033070413325; s_v_web_id=54da78348aebf667cff9db7c37ecb1b1; WEATHER_CITY=%E5%8C%97%E4%BA%AC; __tasessionId=7nkj4w0441576651144543; csrftoken=cba7b413a5c2925800aa2a4762f6fbc9; tt_webid=6771665033070413325",
"referer":"https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D",
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.79 Safari/537.36",
"x-requested-with":"XMLHttpRequest"}
res=requests.get(url,headers=headers)
return res
#从返回的json中解析出组图链接
def get_article_url(text,i):
article_url=text.json()["data"][i]['article_url']
return article_url
#从返回的json中解析出组图标题
def get_title(text,i):
title=text.json()["data"][i]['title']
return title
#从单个组图链接里解析出每张图片的URL地址-自上而下
def parse_article_url_1(article_url):
driver=webdriver.Chrome(r"C:\Users\ThinkPad\AppData\Local\Google\Chrome\Application\chromedriver.exe")
driver.get(article_url)
time.sleep(2)
text=driver.page_source
driver.close()
html=etree.HTML(text)
hrefs=html.xpath('//div[@class="article-content"]/div[@class="pgc-img"]/img/@src')
return hrefs
#从单个组图链接里解析出每张图片的URL地址-自左而右
def parse_article_url_2(article_url):
driver=webdriver.Chrome(r"C:\Users\ThinkPad\AppData\Local\Google\Chrome\Application\chromedriver.exe")
driver.get(article_url)
time.sleep(2)
text=driver.page_source
driver.close()
html=etree.HTML(text)
hrefs=html.xpath('//ul[@class="image-list"]/li[@class="image-item"]/div/a/@href')
return hrefs
#将每张图片保存在对应标题的本地文件夹下
def save_jpg(href):
res=requests.get(href)
file_path='{}/{}.{}'.format(title,md5(res.content).hexdigest(),'jpg')
with open(file_path,'wb') as f:
f.write(res.content)
pages=20 #可以自由更改抓取页面数
os.chdir(r"E:\Py codes\spider")
for i in range(pages):
url='https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset={}&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp=1576651215806'.format(i*20)
r=get_response(url)
for i in range(20):
try: #不是所有的列表中都有组图标题和链接信息,用try防止报错
article_url=get_article_url(r,i)
title=get_title(r,i)
os.mkdir(title) #新建名称的title的文件夹,用来存放图片
hrefs=parse_article_url_1(article_url)
if len(hrefs)==0:
hrefs=parse_article_url_2(article_url)
for href in hrefs:
save_jpg(href)
except:
continue