排序10G的大文件
一个文件,大小10G,里面都是用逗号分隔的整型数字。怎么排序?文件大概张这个样子。

这个问题的麻烦显然是『大』,多大算大 ,10G,100G,1000G,显然不能考虑直接使用内存来搞。
很显然,分治思维是必然的,需要拆分文件。
直接说下思路,然后上代码。
1.把10G大小的文件拆分成N个小文件,每个文件1M
2.把每个文件拉倒内存排序,可以并行操作,在内存中直接使用快排,然后写入文件
3.对文件做两两合并。
前两步都好办,代码也好写。第3步文件合并,需要考虑几个问题。
① 2个1M的有序文件怎么合并?
先看下简单的2个有序数组怎么合并。
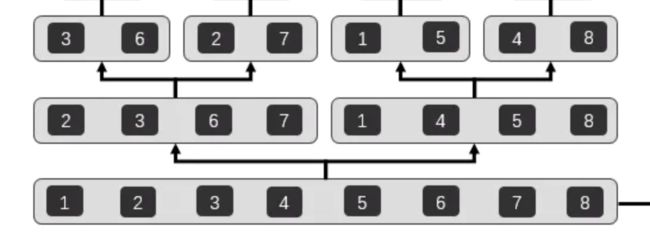
说白了,就是搞一个新的数组,然后遍历2个原数组,把数字小的往前面放。
那2个1M的文件,就是把文件中的数字拉倒内存,搞成数组。就这么合并即可。
② 合并之后的文件越来越大,内存也不好搞,怎么弄?
文件越来越大是个麻烦,2个1G的文件,就不好都拉倒内存合并了。所以根本解决方案,还是得用流式缓冲加载和写入的方案。
比如:2个1G的文件,分别是F1和F2。先从F1读取500个数字,丢到数组byte1。从F2读取500个数字,丢到数组byte2。
如果正常归并,则会搞出1000个数字的新数组。那显然F1或者F2后续的数组会与这1000个数字冲突。1000个直接入新数组显然不行。那么入500个行不行。发现是可以的。因为最坏的情况,就是F1的500个比F2的500个都要小。那么入新数组的500个都是F1的。要不然就是从F1或者F2各来n%的数字。怎么弄。后续未读取的数据都要比这个新数组中的500个数据都要大。如果理解了这一点,就好办了。上代码。
1.把10G大小的文件拆分成N个小文件,每个文件1M
public class SplitFile {
// 待排序目录
private static final String SOURCE_DIR = "/Users/wujian/Desktop/temp/sort/sortdir/";
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream(new File("/Users/wujian/Desktop/temp/sort/sort.txt"));
FileChannel inChannel = fis.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
FileOutputStream fos = null;
FileChannel outChannel = null;
int count = 0;
int batchNum = 0;
while (-1 != inChannel.read(buffer)) {
buffer.flip();// 切换到写模式
if (count++ % 1000 == 0) {
// 扫尾
if (count != 1) {
ByteBuffer tempBuffer = ByteBuffer.allocate(256);
while (true) {
byte b = buffer.get();
tempBuffer.put(b);
// 44代表ascii中的逗号。从后往前找到逗号的位置
if (44 == b) {
tempBuffer.flip();
outChannel.write(tempBuffer);
break;
}
}
}
if (fos != null) {
fos.close();
}
fos = new FileOutputStream(new File(SOURCE_DIR + ++batchNum + ".txt"));
outChannel = fos.getChannel();
}
outChannel.write(buffer);
buffer.clear();// 切换到读模式
}
fos.close();
fis.close();
}
}
拆分文件。这个地方麻烦就是,一个10G的文件就是1行。逗号分隔。缓冲读的过程中,你也不知道1024的最后一个字节是啥,也许某个数字被读到一半呢。所以,每次就从后一个文件中找补第一个逗号,包括前面的数字部分一起写进前一个文件中。
2.把每个文件拉倒内存排序,并且做合并。
这部分代码就不做解释了。过程和细节都在里面了,写了很多注释。
public class SortFiles {
// 待排序目录
private static final String SOURCE_DIR = "/Users/wujian/Desktop/temp/sort/sortdir/";
// 排序过后的目录
private static final String SORTED_DIR = "/Users/wujian/Desktop/temp/sort/sortdir2/";
// 合并目录
private static final String MERGE_DIR = "/Volumes/wujian/temp/";
// 合并时用来对文件名做累加
public static final AtomicInteger mergeCounter = new AtomicInteger(0);
/**
* 排序归并任务
*/
public static class SortTask extends RecursiveTask<File> {
private final int[] idxs;
private final int start;
private final int end;
public SortTask(int[] idxs, int start, int end) {
this.idxs = idxs;
this.start = start;
this.end = end;
}
@Override
protected File compute() {
File result;
if (start == end) {// 当start == end,说明已经是到单个文件任务了。那么就开始排序。1M的文件可以直接使用快速排序
int idx = idxs[start];
int[] sortNums = this.getSortNums(new File(SOURCE_DIR + "sort" + idx + ".txt"));
Arrays.sort(sortNums);// 1M大小的文件,直接使用快速排序
result = this.write2file(sortNums, new File(SORTED_DIR + "sort" + idx + ".txt"));
} else {
// 如果start != end,那么就需要继续切分任务。
int mid = start + (end - start) / 2;
// 一分为二再搞出2个任务
SortTask left = new SortTask(idxs, start, mid);
SortTask right = new SortTask(idxs, mid + 1, end);
// 执行任务
invokeAll(left, right);
// 等待两个任务执行结果,然后做合并
result = this.merge(left.join(), right.join());
}
return result;
}
/**
* 把排序完成之后的数字数字写入文件
*/
private File write2file(int[] sortNums, File file) {
try (BufferedWriter bw = new BufferedWriter(new FileWriter(file))) {
for (int sortNum : sortNums) {
bw.write(String.valueOf(sortNum));
bw.write(",");
}
bw.flush();
} catch (IOException e) {
e.printStackTrace();
}
return file;
}
/**
* 通过文件获取到里面的所有待排序的数字
*/
private int[] getSortNums(File file) {
try (BufferedReader br = new BufferedReader(new FileReader(file))) {
String str = br.readLine();
String[] split = str.split(",");
int[] res = new int[split.length];
for (int i = 0; i < split.length; i++) {
res[i] = Integer.parseInt(split[i]);
}
return res;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 以1M为单位做merge
* 每满1M就忘目标文件中写入
*/
public File merge(File f1, File f2) {
File mergeFile = new File(MERGE_DIR + "merge" + mergeCounter.incrementAndGet() + ".txt");// 归并后的结果文件
BufferedWriter streamBw = null;
FileInputStream is1 = null;
FileInputStream is2 = null;
ByteBuffer buffer1 = ByteBuffer.allocate(1024);
ByteBuffer buffer2 = ByteBuffer.allocate(1024);
// 上次读完后还剩下的几个字节。
// 比如第一次读1-24个字节,无法保证最后一个自己是逗号, 那么就往前找逗号, 找到之后,后面的几个字节放到下次再用
ByteBuffer remainBytes1 = ByteBuffer.allocate(1024);
ByteBuffer remainBytes2 = ByteBuffer.allocate(1024);
try {
streamBw = new BufferedWriter(new FileWriter(mergeFile));
// 打开文件
is1 = new FileInputStream(f1);
is2 = new FileInputStream(f2);
// 获取channel
FileChannel channel1 = is1.getChannel();
FileChannel channel2 = is2.getChannel();
// 声明链表
LinkedList<Integer> list1 = new LinkedList<>();
LinkedList<Integer> list2 = new LinkedList<>();
boolean hasNext1 = true;// file1还是否有内容可读
boolean hasNext2 = true;// file2还是否有内容可读
Integer mergeNum1 = null;
Integer mergeNum2 = null;
// 只有当两个文件都没有内容可读时才退出循环
while (hasNext1 || hasNext2) {
if (hasNext1) {// 有内容可读时才会去读
// 从文件中读取数据追加到list1
hasNext1 = this.getNums(remainBytes1, channel1, buffer1, list1);
}
if (hasNext2) {// 有内容可读时才会去读
// 从文件中读取数据追加到list2
hasNext2 = this.getNums(remainBytes2, channel2, buffer2, list2);
}
// 每次可以merge这两个数组中最小值,然后写入文件
/**
* 如果文件A是500个单位,文件B是500个单位
* 那么合并之后的前500个单位,一定是没有问题的,一定是有序的。因为最坏的情况是文件A的500个单位都要比文件B的500个单位小。
* 所以每次合并只能合并文件A和文件B,size比较小的那个。
* 最后一次合并时,就需要把两边的size想加了。
*/
int mergeSize = (!hasNext1 && !hasNext2) ? list1.size() + list2.size() : Math.min(list1.size(), list2.size());
int[] mergeArr = new int[mergeSize];
for (int i = 0; i < mergeSize; i++) {
if (mergeNum1 == null && !list1.isEmpty()) {
mergeNum1 = list1.remove();
}
if (mergeNum2 == null && !list2.isEmpty()) {
mergeNum2 = list2.remove();
}
// mergeNum1, mergeNum2 每次都是remove出来的,那么下次循环进来还要继续用。
// 所以哪个用完了就得置为null,以方便下次循环进来之后做区分
if (mergeNum1 == null) {
mergeArr[i] = mergeNum2;
mergeNum2 = null;
} else if (mergeNum2 == null) {
mergeArr[i] = mergeNum1;
mergeNum1 = null;
} else if (mergeNum1 < mergeNum2) {
mergeArr[i] = mergeNum1;
mergeNum1 = null;
} else {
mergeArr[i] = mergeNum2;
mergeNum2 = null;
}
}
this.appendFile(mergeArr, streamBw);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
streamBw.close();
is1.close();
is2.close();
// 合并次数太多,会占用太多存储空间,所以合并完成之后的文件就可以被废弃了。删除
f1.delete();
f2.delete();
} catch (IOException e) {
e.printStackTrace();
}
}
return mergeFile;
}
/**
* 合并的时候追加文件
*/
private void appendFile(int[] sortNums, BufferedWriter bw) {
try {
for (int sortNum : sortNums) {
bw.write(String.valueOf(sortNum));
bw.write(",");
}
bw.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 从文件中追加数字进来。
*/
private boolean getNums(ByteBuffer remainBytes, FileChannel channel, ByteBuffer buffer, LinkedList<Integer> list) {
try {
do {
// 一旦这个文件读完了就返回false。作为标识
if (-1 == channel.read(buffer)) {
return false;
}
// 44代表ascii中的逗号。从后往前找到逗号的位置
int idx = 0;
while (44 != buffer.get(buffer.position() - idx - 1)) {
idx++;
}
ByteBuffer tempBuffer = ByteBuffer.allocate(2048);
remainBytes.flip();
if (remainBytes.hasRemaining()) {
// 如果remainBytes有东西,那么先追加进来
tempBuffer.put(remainBytes);
}
// 这几行,就是把buffer中的字节追加到tempBuffer
buffer.flip();
byte[] bytes = new byte[buffer.limit() - idx];
buffer.get(bytes, 0, bytes.length);
tempBuffer.put(bytes);
// 把tempBuffer转换成字符串,然后split,再追加到list中
tempBuffer.flip();
String str = new String(tempBuffer.array(), 0, tempBuffer.limit());
String[] split = str.split(",");
for (String s : split) {
// 追加数字
list.add(Integer.parseInt(s));
}
// 把剩余的放到remainBytes
remainBytes.clear();
remainBytes.put(buffer);
buffer.clear();
// 设置一个阈值,超过10000就做一次归并操作
} while (list.size() <= 10000);
} catch (Exception e) {
e.printStackTrace();
}
return true;
}
}
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
int[] idxs = new int[6728];
for (int i = 1; i <= idxs.length; i++) {
idxs[i - 1] = i;
}
// 启动任务
SortTask sortTask = new SortTask(idxs, 0, idxs.length - 1);
pool.invoke(sortTask);
}
}
总结
这边在编码时使用了ForkJoin框架。实际上,如果文件达到一定程度,比如几十个G。就得上到大数据平台。利用MapReduce或者其他计算框架。其思路都是类似的,就是分治递归。