python 文件I/O
- 输出
print '内容'
- 输入
1、raw_input()
//从标准输入读取一个行,并返回一个字符串(去掉结尾的换行符),若输入为python表达式,则会返回表达式原式而不是运算结果。
s=raw_input('Enter a number:')
2、input()
// input 可以接收一个Python表达式作为输入,并将运算结果返回。
s=input('Enter something:')
- 打开文件
file object = open(file_name [, access_mode][, buffering])
file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
buffering:如果buffering的值被设为0,就不会有寄存。如果buffering的值取1,访问文件时会寄存行。如果将buffering的值设为大于1的整数,表明了这就是寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
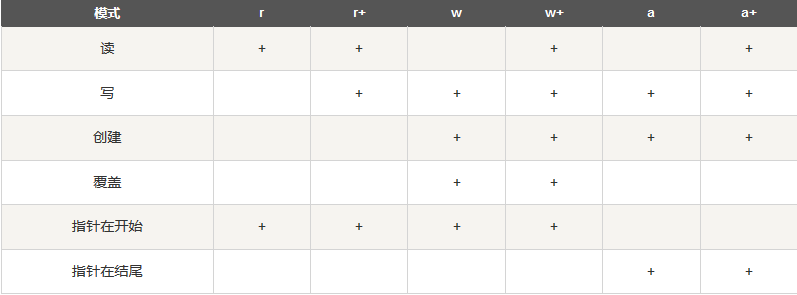
- file 对象属性
- file 对象方法
1、close()
// File 对象的 close()方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入;当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close()方法关闭文件是一个很好的习惯。
文件名.close()
2、write()
//可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字;write()方法不会在字符串的结尾添加换行符('\n')。
fo=open('文件名','w')
fo.write(需写入的字符串)
fo.close()
3、read()
//从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
文件名.read([需要读取的字节数])
- 文件定位
// tell()方法告诉你文件内的当前位置, 换句话说,下一次的读写会发生在文件开头这么多字节之后。
seek(offset [,from])方法改变当前文件的位置。Offset变量表示要移动的字节数。From变量指定开始移动字节的参考位置。
如果from被设为0,这意味着将文件的开头作为移动字节的参考位置。如果设为1,则使用当前的位置作为参考位置。如果它被设为2,那么该文件的末尾将作为参考位置。
文件名.tell():告诉文件内的当前位置
文件名.seek(要移动的字节数,开始移动字节的参考位置)
- 重命名和删除文件
1、rename()
import os
os.rename(当前文件名,新文件名)
2、remove(文件名)
import os
os.ramove(文件名)
- python里的目录
1、mkdir()
//可以使用os模块的mkdir()方法在当前目录下创建新的目录们。
import os
os.mkdir(新目录名)
2、chdir()
//改变当前的目录.
import os
os.chdir(想要跳转到的目录名)
3、getcwd()
//显示当前的工作目录
import os
print os.getcwd()
4、rmdir()
//删除某个目录,目录的完全合规的名称必须被给出,否则会在当前目录下搜索该目录。
import os
os.rmdir(要删除的目录名)
- 文件方法
1、file.close():关闭文件,关闭后文件不能再进行读写操作;
2、file.flush():刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件,而不是被动的等待输出缓冲区写入。
3、file.fileno():返回一个整型的文件描述符,可以用在os模块的read方法等一些底层操作上。
4、file.isatty():如果文件连接到一个终端设备返回 True,否则返回 False。
5、file.next():返回文件下一行。
6、file.read([size]):从文件读取指定的字节数,如果未给定或为负则读取所有。
7、file.readline([size]):读取整行,包括'\n'字符。
8、file.readlines([sizehint]):读取所有行并返回列表,若给定的sizehint>0,则表明一次读取多少行。
9、file.seek[需要偏移的字节[,偏移初始位置]:设置文件当前位置。
10、file.tell():返回文件当前位置。
11、file.truncate([size]):截取文件,截取的字节通过size指定,默认为当前文件位置。
12、file.write(str):将字符串写入文件,没有返回值。
13、file.writelines(sequence):向文件写入一个字符串列表,如果需要换行则自己加入每行的换行符。
python 内置函数
- abs()
返回数字的绝对值 - divmod()
把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b) - input()
input() 和 raw_input() 这两个函数均能接收字符串 ,但 raw_input() 直接读取控制台的输入(任何类型的输入它都可以接收)。而对于 input() ,它希望能够读取一个合法的 python 表达式,即你输入字符串的时候必须使用引号将它括起来,否则它会引发一个 SyntaxError 。
除非对 input() 有特别需要,否则一般情况下我们都是推荐使用 raw_input() 来与用户交互。 - open()
打开一个文件 - staticmethod()
返回函数的静态方法 - all()
用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。元素除了是 0、空、FALSE 外都算 TRUE。空元组、空列表返回值为True。 - enumerate()
将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。 - int()
将一个字符串或数字转换为整型。 - ord()
chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。 - str()
将对象转化为适于人阅读的形式。 - any()
判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。元素除了是 0、空、FALSE 外都算 TRUE。空元组、空列表返回值为False。 - eval()
用来执行一个字符串表达式,并返回表达式的值.
//eval 方法能使字符串本身的引号去掉,保留字符的原本属性。 - isinstance()
判断一个对象是否是一个已知的类型,类似 type()。
// isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。 - pow()
返回 x^y(x的y次方) 的值。
对于内置pow():pow(x,y[,z])
对于math模块:pow(x,y)
函数是计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z;
pow() 通过内置的方法直接调用,内置方法会把参数作为整型,而 math 模块则会把参数转换为 float。
pow(x,y)==x**y
pow(x,y[,z])==x**y%z
- sum()
对系列进行求和计算。
sum(iterable[,start])
iterable:可迭代对象,如:列表、元组、集合。
start:指定相加的参数,如果没有设置这个值,默认为0。
sum([1,2,3],2)=8
- basestring()
str 和 unicode 的超类(父类),也是抽象类,因此不能被调用和实例化,但可以被用来判断一个对象是否为 str 或者 unicode 的实例,isinstance(obj, basestring) 等价于 isinstance(obj, (str, unicode))。 - execfile()
执行文件内的内容 - issubclass()
issubclass(class,classinfo)
如果 class 是 classinfo 的子类返回 True,否则返回 False。
- print()
打印输出 - super()
调用父类的一个方法 - bin()
返回一个整数(int)或者长整数(long int)的二进制形式.
bin(X)
- file()
创建一个file对象 - iter()
生成迭代器 - property()
在新式类中返回属性值。 - tuple()
将列表转换为元组
tuple(列表)
//对于字典则会返回由键名组成元组,对于元组则会返回本身。
- bool()
将给定参数转换为布尔类型,如果没有参数,返回 False。
//bool是int的子类 - filter()
filter(函数名,序列)
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
- len()
返回对象(字符、列表、元组等)长度或项目个数. - range()
range(开始,结束,间隔数)
//间隔数默认为1,开始位置默认为0,只含两个参数时,若后面一个参数小于前面一个参数,则返回 [ ]。
创建一个整数列表,一般用在 for 循环中.
- type()
如果你只有第一个参数则返回对象的类型,三个参数返回新的类型对象。
// isinstance() 与 type() 区别:
1、type() 不会认为子类是一种父类类型,不考虑继承关系。
2、isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。 - bytearray()
返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256。 - float()
将整数和字符串转换成浮点数。 - list()
将元组转化为列表
//元组 ( ) 中的值无法修改,列表 [ ] 中的值可修改。 - raw_input()
用来获取控制台的输入,将所有输入作为字符串看待;input可以将输入的表达式进行运算。
//raw_input与input后面括号内若给予字符串,则均需要加上 ' '。 - unichr
返回unicode的字符。
//与之相对应的chr(),则根据所给的字符返回对应的ascii码(有一定的范围限制)。 - callable()
检查一个对象是否是可调用的。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝对不会成功。
//对于函数, 方法, lambda 函式, 类, 以及实现了 call 方法的类实例, 它都返回 True。 - format()
增强了字符串格式化的功能。基本语法是通过 {} 和 : 来代替以前的 %;format 函数可以接受不限个参数,位置可以不按顺序。 - locals()
以字典类型返回当前位置的全部局部变量。对于函数, 方法, lambda 函式, 类, 以及实现了 call 方法的类实例, 它都返回 True。 - reduce()
对参数序列中元素进行累积。函数将一个数据集合(链表,元组等)中的所有数据进行下列操作:用传给 reduce 中的函数 function(有两个参数)先对集合中的第 1、2 个元素进行操作,得到的结果再与第三个数据用 function 函数运算,最后得到一个结果。
//在 Python3 中,reduce() 函数已经被从全局名字空间里移除了,它现在被放置在 fucntools 模块里,如果想要使用它,则需要通过引入 functools 模块来调用 reduce() 函数。 - chr()
用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。
//chr(i)中的 i 既可以是十进制又可以是十六进制。 - frozenset()
返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。 - long()
将数字或字符串转换为一个长整型。
long(x,base=10)
- reload()
重新载入之前载入的模块。 - vars()
返回对象object的属性和属性值的字典对象,如果没有参数,就打印当前调用位置的属性和属性值类似 locals()。 - classmethod修饰符
classmethod 修饰符对应的函数不需要实例化,不需要 self 参数,但第一个参数需要是表示自身类的 cls 参数,可以来调用类的属性,类的方法,实例化对象等。 - getattr()
返回一个对象属性值。 - map()
根据提供的函数对指定序列做映射。第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。 - repr()
将对象转化为供解释器读取的形式,返回一个对象的 string 格式。 - xrange()
用法与range()类似,只是生成的不是一个数组,而是一个生成器。
list(xrange(10))==range(10)
- cmp()
用于比较2个对象,如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。
cmp(x,y)
//python3中使用的是operator模块
- globals()
以字典类型返回当前位置的全部全局变量;包括所有导入的变量。 - max()
返回给定参数的最大值,参数可以为序列。 - reverse()
该方法没有返回值,但是会对列表的元素进行反向排序。 - zip()
用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。 - compile()
将一个字符串编译为字节代码;返回表达式执行结果。 - hasattr()
用于判断对象是否包含对应的属性;如果对象有该属性返回 True,否则返回 False。 - memoryview()
返回给定参数的内存查看对象(Momory view)。所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问。 - round()
返回浮点数x的四舍五入值。
//python2中是保留值将保留到离上一位更近的一端(四舍六入),如果距离两端一样远,则保留到离0远的一边。所以round(0.5)会近似到1,而round(-0.5)会近似到-1。
python3中是如果距离两边一样远,会保留到偶数的一边。比如round(0.5)和round(-0.5)都会保留到0,而round(1.5)会保留到2。 - __ import __()
用于动态加载类和函数 。如果一个模块经常变化就可以使用 __ import __() 来动态载入 - complex()
用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。 - hash()
获取取一个对象(字符串或者数值等)的哈希值。
//函数可以应用于数字、字符串和对象,不能直接应用于 list、set、dictionary。在 hash() 对对象使用时,所得的结果不仅和对象的内容有关,还和对象的 id(),也就是内存地址有关。 - min()
返回给定参数的最小值,参数可以为序列;与max()相对应。比较时,从第一个字符开始,第一个相同,比较第二个,依次类推。 - set()
创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。 - delattr()
删除属性
delattr(对象,对象属性)
- help()
查看函数或模块用途的详细说明。 - next()
返回迭代器的下一个项目。 - setattr()
设置属性值,该属性必须存在。 - dict()
创建一个字典。 - hex()
将10进制整数转换成16进制,以字符串形式表示。 - slice()
实现切片对象,主要用在切片操作函数里的参数传递。 - dir()
不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法dir(),该方法将被调用。如果参数不包含dir(),该方法将最大限度地收集参数信息。 - id()
获取对象的内存地址。 - oct()
将一个整数转换成8进制字符串。 - sorted()
对所有可迭代的对象进行排序操作。
// sort 与 sorted 区别:sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。 - exec()
执行储存在字符串或文件中的Python语句,相比于 eval,exec可以执行更复杂的 Python 代码。exec 返回值永远为 None。
//在 Python2 中exec不是函数,而是一个内置语句(statement),但是Python 2中有一个 execfile() 函数。可以理解为 Python 3 把 exec 这个 statement 和 execfile() 函数的功能够整合到一个新的 exec() 函数中去了。
上一篇:python基础知识(4)
下一篇:python基础知识(进阶篇--正则表达式)