可扩展系统构架介绍
翻译自:https://lethain.com/introduction-to-architecting-systems-for-scale/

很少有计算机科学或软件开发程序试图教授可扩展系统的构建块。取而代之的是,系统架构通常是 通过解决不断增长的产品的痛苦 或与已经从该痛苦过程中学到的工程师一起完成的。
在这篇文章中,我将尝试记录一些在Yahoo!上使用系统时所学到的可伸缩性架构课程。和Digg。
我试图维护图表的颜色约定:
- 绿色是来自外部客户端的外部请求(来自浏览器的HTTP请求等),
- 蓝色是您的代码在某个容器中运行(在mod_wsgi上运行的Django应用,监听RabbitMQ的Python脚本等),以及
- 红色是基础架构的一部分(MySQL,Redis,RabbitMQ等)。
负载均衡
理想的系统通过增加硬件来线性增加容量。在这样的系统中,如果有一台计算机并添加另一台计算机,则容量将增加一倍。如果您有三个,然后添加另一个,则容量将增加33%。让我们称之为水平可伸缩性。
在故障方面,理想的系统不会因服务器丢失而中断。丢失服务器应仅使系统容量减少与添加时增加整体容量相同的数量。我们称这种冗余。
水平可伸缩性和冗余通常都通过负载平衡来实现。
(本文不会涉及垂直可伸缩性,因为它通常对于大型系统来说是不受欢迎的,因为不可避免地会出现这样的情况,即在其他计算机上以容量形式添加容量比在一台计算机上增加资源便宜,并且冗余和垂直缩放可能彼此矛盾。)
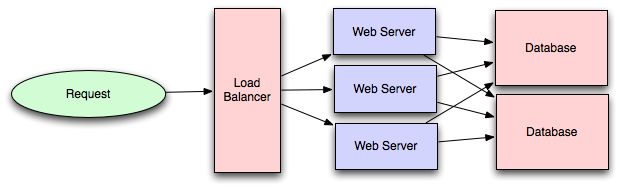
负载平衡是根据某种度量标准(随机,循环,对机器容量加权的随机变量)及其当前状态(可用于请求,不响应,错误率升高等)在多个资源之间分散请求的过程。
需要在用户请求和Web服务器之间平衡负载,但还必须在每个阶段平衡负载,以实现系统的完全可伸缩性和冗余。中等大小的系统可能会在三个层次上平衡负载:
- 用户访问您的Web服务器,
- Web服务器到内部平台层,
- 内部平台层到数据库。
有多种方法可以实现负载平衡。
聪明的客户
通常,将负载平衡功能添加到数据库客户端(缓存,服务等)对于开发人员来说是一种有吸引力的解决方案。它是最简单的解决方案,是否具有吸引力?通常不会 是否最诱人,因为它最诱人?可悲的是没有。是因为易于重用而吸引人吗?可悲的是,没有。
开发人员倾向于智能客户端,因为他们是开发人员,因此他们习惯于编写软件来解决问题,而智能客户端就是软件。
牢记这一警告,什么是聪明的客户?它是一个客户端,它使用一组服务主机并平衡它们之间的负载,检测出现故障的主机并避免以其方式发送请求(它们还必须检测恢复的主机,处理添加的新主机等,使它们变得有趣起来才能体面地工作和一个恐怖的设置)。
硬件负载平衡器
负载平衡最昂贵(但性能非常好)的解决方案是购买专用的硬件负载平衡器(类似于Citrix NetScaler)。尽管它们可以解决各种问题,但是硬件解决方案非常昂贵,而且配置“也不简单”。
这样一来,即使是大型公司,即使预算很多,也常常会避免使用专用硬件来满足其所有负载平衡需求;取而代之的是,它们仅将它们用作从用户请求到其基础结构的第一联系点,并使用其他机制(智能客户端或下一部分中讨论的混合方法)对网络中的流量进行负载平衡。
软件负载均衡器
如果您想避免创建智能客户端的麻烦,并且购买过多的专用硬件,那么Universe已经足够提供混合服务:软件负载平衡器。
HAProxy是这种方法的一个很好的例子。它在您的每个机箱上本地运行,并且您要进行负载平衡的每个服务都有一个本地绑定的端口。例如,你可能也有平台计算机通过访问localhost:9000时,您的数据库中读取池localhost:9001,并在你的数据库写池localhost:9002。HAProxy将管理运行状况检查,并将根据您的配置将计算机删除并返回至这些池,以及在这些池中的所有计算机之间保持平衡。
对于大多数系统,我建议从软件负载平衡器开始,然后仅在有需要时才转向智能客户端或硬件负载平衡。
快取
负载平衡可帮助您在数量不断增加的服务器上横向扩展,但是缓存将使您能够更好地利用现有资源,并使其他无法达到的产品需求变得可行。
缓存包括:预先计算结果(例如,前一天来自每个引用域的访问次数),预先生成昂贵的索引(例如,基于用户的点击历史记录的建议故事)以及将频繁访问的数据的副本存储在更快的后端中(例如Memcache而不是PostgreSQL。
在实践中,缓存在开发过程中比负载平衡更重要,并且从一致的缓存策略开始可以节省以后的时间。它还可以确保您不会优化无法用您的缓存机制复制的访问模式或在添加缓存后性能变得不重要的访问模式(我发现许多经过高度优化的Cassandra应用程序对于干净地添加缓存是一个挑战。无法/何时无法将数据库的缓存策略应用于您的访问模式,因为Cassandra与缓存之间的数据模型通常不一致)。
应用程序与数据库缓存
缓存有两种主要方法:应用程序缓存和数据库缓存(大多数系统都严重依赖两者)。
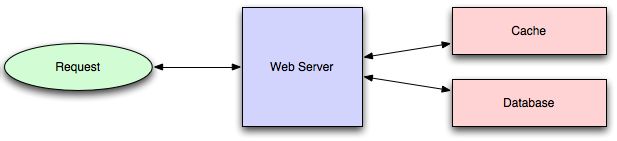
应用程序缓存需要在应用程序代码本身中进行显式集成。通常,它将检查缓存中是否有值;如果不是,则从数据库中检索值;然后将该值写入高速缓存(如果您使用的是观察到最近最少使用的高速缓存算法的高速缓存,则该值特别常见)。该代码通常看起来像(特别是这是一个只读缓存,因为如果缓存中缺少该值,它将从数据库中读取该值):
key = "user.%s" % user_id
user_blob = memcache.get(key)
if user_blob is None:
user = mysql.query("SELECT * FROM users WHERE user_id=\"%s\"", user_id)
if user:
memcache.set(key, json.dumps(user))
return user
else:
return json.loads(user_blob)
硬币的另一面是数据库缓存。
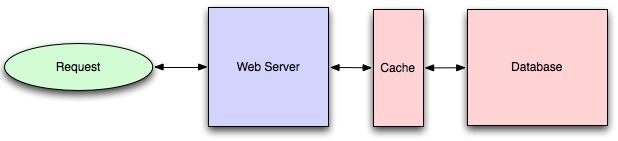
打开数据库时,您将获得某种程度的默认配置,这将提供一定程度的缓存和性能。这些初始设置将针对通用用例进行优化,并且通过将它们调整为系统的访问模式,通常可以极大地提高性能。
数据库缓存的优点在于,您的应用程序代码可以“免费”获得更快的速度,并且有才华的DBA或运营工程师可以在不改变代码的情况下发现相当多的性能(我的同事Rob Coli最近花了一些时间来优化我们的配置Cassandra行缓存,并成功完成了他花了一周的时间骚扰我们的图表,这些图表显示I / O负载急剧下降,请求延迟也大大提高了)。
内存缓存
就原始性能而言,最有效的缓存是将整个数据集存储在内存中的缓存。Memcached和 Redis都是内存中缓存的示例(注意:可以将Redis配置为将某些数据存储到磁盘)。这是因为对RAM的访问 要比对磁盘的访问快几个数量级。
另一方面,通常可用RAM少于磁盘空间,因此需要一种仅将数据的热子集保留在内存缓存中的策略。最直接的策略是最近最少使用的策略,并且由Memcache使用(并且从2.2版开始,Redis也可以配置为采用它)。LRU通过优先使用较不常用的数据逐出较不常用的数据来工作,并且几乎总是合适的缓存策略。
内容分发网络
内容分发网络是一种特殊的缓存(某些人可能会使用该术语的用法,但我觉得很合适),这种缓存在为大量静态媒体提供服务的站点中发挥了作用。
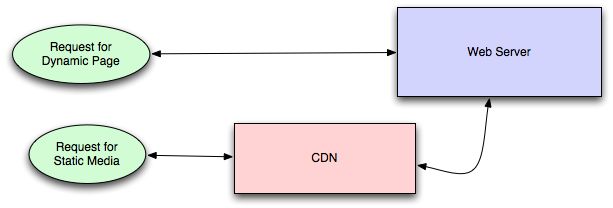
CDN减轻了从您的应用程序服务器上提供静态媒体的负担(通常最适合为动态页面而非静态媒体提供服务),并提供地理分布。总体而言,您的静态资产将更快地加载,并且对服务器的压力较小(但这是新的业务支出压力)。
在典型的CDN设置中,请求首先会向CDN请求静态媒体,如果CDN在本地具有可用状态,则CDN将提供该内容(HTTP标头用于配置CDN缓存给定内容的方式)。如果该文件不可用,则CDN将向您的服务器查询文件,然后将其本地缓存并提供给发出请求的用户(在此配置中,它们充当只读缓存)。
如果您的站点还不够大,无法使用自己的CDN,则可以static.example.com使用轻量级的HTTP服务器(例如Nginx)将静态媒体从单独的子域(例如)提供服务,并将DNS从服务器切换到CDN稍后发布。
缓存失效
尽管缓存非常棒,但它确实需要您在缓存和真实数据源(即数据库)之间保持一致性,从而冒着真正奇怪的应用行为的风险。
解决此问题的方法称为缓存失效。
如果您要处理的是单个数据中心,这通常是一个简单的问题,但是如果您有多个代码路径写入数据库和缓存,则很容易引入错误(如果不使用它,几乎总是会发生这种情况)在编写应用程序时就已经考虑了缓存策略)。在较高的级别上,解决方案是:每次更改值时,将新值写入高速缓存(这称为直写式高速缓存),或者简单地从高速缓存中删除当前值,并允许填充直通式缓存以后再进行选择(在读写缓存之间进行选择取决于您应用程序的详细信息,但是通常我更喜欢直写缓存,因为它们可以减少后端数据库踩踏事件的发生率)。
对于涉及模糊查询的场景(例如,如果您尝试在诸如SOLR之类的全文搜索引擎之前添加应用程序级缓存 )或对未知数量的元素进行修改(例如,删除创建的所有对象超过一周以前)。
在这些情况下,您必须考虑完全依赖数据库缓存,向缓存的数据添加过多的过期时间,或者重新设计应用程序的逻辑以避免出现此问题(例如,代替DELETE FROM a WHERE...,检索所有符合条件的项目,使相应的缓存行无效,并然后通过主键明确删除行)。
离线处理
随着系统变得越来越复杂,几乎总是需要执行无法与客户请求同步执行的处理,因为这会产生不可接受的延迟(例如,您希望在社交图中传播用户的操作) ),或者因为它需要定期发生(例如,要创建每日汇总分析)。
消息队列
对于处理,您希望与请求内联执行,但速度太慢,最简单的解决方案是创建消息队列(例如RabbitMQ)。消息队列使您的Web应用程序可以快速将消息发布到队列,并让其他使用者进程在客户端请求的范围和时间范围之外执行处理。
消费者处理的脱机工作与Web应用程序进行的联机工作之间的划分工作完全取决于您向用户公开的界面。通常,您将:
- 在使用者中几乎不执行任何工作(仅调度任务),并通知您用户该任务将脱机发生,通常使用轮询机制在任务完成后更新接口(例如,按照以下步骤在Slicehost上配置新的VM)模式),或
- 在线执行足够的工作,以使用户看起来该任务已完成,然后将挂起的终端绑起来(在Twitter或Facebook上发布消息可能会通过更新时间轴中的推文/消息来遵循此模式,但会更新您的关注者时间跨度; 实时更新Scobleizer的所有关注者是不可行的。
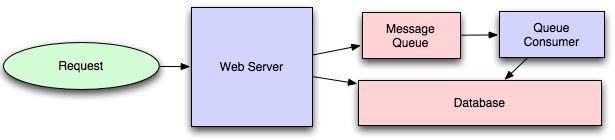
消息队列还有另一个好处,那就是它们使您可以创建一个单独的计算机池来执行脱机处理,而不会增加Web应用程序服务器的负担。这使您可以将资源增加的目标定位为当前的性能或吞吐量瓶颈,而不是在瓶颈和非瓶颈系统上统一增加资源。
安排定期任务
几乎所有大型系统都需要每日或每小时执行任务,但是遗憾的是,等待易于接受的,广泛支持的解决方案仍然是一个问题。同时,您可能仍然对cron感到困惑,但是您可以使用cronjobs将消息发布给使用者,这意味着cron机器仅负责调度,而不需要执行所有处理。
有谁知道解决这个问题的公认工具?我见过许多自制系统,但是没有干净且可重用的系统。当然,您可以将cronjobs存储在计算机的Puppet 配置中,这使得从丢失该计算机的过程中恢复很容易,但是仍然需要手动恢复,这可能是可以接受的,但并不完美。
映射减少
如果您的大型应用程序正在处理大量数据,则有时可能会使用Hadoop以及 Hive或HBase添加对map-reduce的支持。
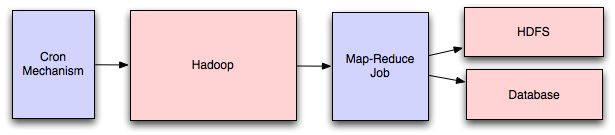
添加地图缩减层可以在合理的时间内执行数据和/或处理密集型操作。您可以使用它来计算社交图中的建议用户或生成分析报告。
对于足够小的系统,您通常可以避免使用SQL数据库上的临时查询,但是一旦存储的数据量或写入负载需要对数据库进行分片,并且通常需要专用的从属服务器,则该方法可能无法轻易扩展。执行这些查询(此时,您可能希望使用设计用于分析大量数据的系统,而不是与数据库打交道)。
平台层
大多数应用程序都是从直接与数据库通信的Web应用程序开始的。对于大多数应用程序来说,这种方法通常就足够了,但是添加平台层有一些令人信服的理由,例如,Web应用程序与平台层进行通信,而平台层又与数据库进行通信。
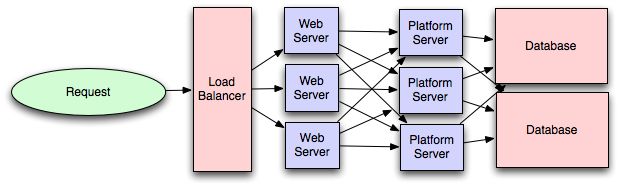
首先,将平台和Web应用程序分开可以使您独立地扩展各个部分。如果添加新的API,则可以添加平台服务器而无需为Web应用程序层添加不必要的容量。(通常,专门发挥服务器角色的作用会带来更高级别的配置优化,这对于通用计算机而言是不可用的;您的数据库计算机通常将具有较高的I / O负载,并会受益于固态驱动器,但是您的配置良好的应用服务器在正常运行期间可能根本不会从磁盘读取数据,但可能会受益于更多的CPU。)
其次,添加平台层是一种将基础架构用于多种产品或接口(Web应用程序,API,iPhone应用程序等)的方法,而无需编写过多的用于处理缓存,数据库等的冗余样板代码。
第三,平台层有时不为人所知的方面是,它们使组织扩展变得更容易。最好的情况是,平台公开了与产品无关的清晰接口,从而掩盖了实施细节。如果做得好,这将允许多个独立团队利用平台的功能进行开发,并允许另一个团队实施/优化平台本身。
我本来打算在处理多个数据中心方面进行适度的详细介绍,但是该主题确实值得一提,因此我只想提一下缓存无效化和数据复制/一致性在那个阶段成为相当有趣的问题。
我敢肯定,我在这篇文章中做了一些有争议的陈述,希望亲爱的读者为之辩护,以便我们都能学到一些。谢谢阅读!