文章RSS
云大的博客
云大的技术之路
Wed, 26 Dec 2018 06:03:10 +0800
zh-CN
hourly
1
https://wordpress.org/?v=5.0.2
https://www.wangxinshuo.cn/wp-content/uploads/2018/08/cropped-头像-1-32x32.png
云大的博客
https://www.wangxinshuo.cn
32
32
-
GCC参数
https://www.wangxinshuo.cn/2018/12/26/gcc%e5%8f%82%e6%95%b0/
https://www.wangxinshuo.cn/2018/12/26/gcc%e5%8f%82%e6%95%b0/#respond
Wed, 26 Dec 2018 06:02:29 +0000
https://www.wangxinshuo.cn/?p=521
 ]]>
]]>https://www.wangxinshuo.cn/2018/12/26/gcc%e5%8f%82%e6%95%b0/feed/
0
-
GCC编译C代码
https://www.wangxinshuo.cn/2018/12/26/gcc%e7%bc%96%e8%af%91c%e4%bb%a3%e7%a0%81/
https://www.wangxinshuo.cn/2018/12/26/gcc%e7%bc%96%e8%af%91c%e4%bb%a3%e7%a0%81/#respond
Wed, 26 Dec 2018 02:05:56 +0000
https://www.wangxinshuo.cn/?p=517
编译单个文件
1. gcc -E test.c -o test.i 或 gcc -E test.c // 编译生成中间代码(将头文件包括进文件)
2. gcc -S test.i -o test.s // 生成汇编文件
3. gcc -c test.s -o test.o // 生成目标文件
4. gcc test.o -o test // 生成可执行文件
编译多个文件(包括自己写的头文件)
gcc –c –I /usr/dev/mysql/include test.c –o test.o
使用库文件
gcc –L /usr/dev/mysql/lib –lmysqlclient test.o –o test
]]>
https://www.wangxinshuo.cn/2018/12/26/gcc%e7%bc%96%e8%af%91c%e4%bb%a3%e7%a0%81/feed/
0
-
CSS选择器、jQuery选择器
https://www.wangxinshuo.cn/2018/12/22/css%e9%80%89%e6%8b%a9%e5%99%a8%e3%80%81jquery%e9%80%89%e6%8b%a9%e5%99%a8/
https://www.wangxinshuo.cn/2018/12/22/css%e9%80%89%e6%8b%a9%e5%99%a8%e3%80%81jquery%e9%80%89%e6%8b%a9%e5%99%a8/#respond
Sat, 22 Dec 2018 00:20:21 +0000
https://www.wangxinshuo.cn/?p=512

 ]]>
]]>https://www.wangxinshuo.cn/2018/12/22/css%e9%80%89%e6%8b%a9%e5%99%a8%e3%80%81jquery%e9%80%89%e6%8b%a9%e5%99%a8/feed/
0
-
LSTM in Keras
https://www.wangxinshuo.cn/2018/12/04/lstm-in-keras/
https://www.wangxinshuo.cn/2018/12/04/lstm-in-keras/#respond
Tue, 04 Dec 2018 14:14:50 +0000
https://www.wangxinshuo.cn/?p=505
FireShot Capture 4 – keras:4)LSTM函数详解 _ – https___blog.csdn.net_jiangpeng59_article_details_77646186
]]>
https://www.wangxinshuo.cn/2018/12/04/lstm-in-keras/feed/
0
-
Cglib
https://www.wangxinshuo.cn/2018/11/24/cglib/
https://www.wangxinshuo.cn/2018/11/24/cglib/#respond
Sat, 24 Nov 2018 09:27:53 +0000
https://www.wangxinshuo.cn/?p=498
Spring AOP的实现原理:
1. 如果针对接口做代理默认使用的是JDK自带的Proxy+InvocationHandler
2. 如果针对类做代理使用的是Cglib
cglib实现代理
cglib简单实现
public class Dao {
public void update() {
System.out.println("PeopleDao.update()");
}
public void select() {
System.out.println("PeopleDao.select()");
}
}
public class DaoProxy implements MethodInterceptor {
@Override
public Object intercept(Object object, Method method, Object[] objects, MethodProxy proxy) throws Throwable {
System.out.println("Before Method Invoke");
proxy.invokeSuper(object, objects);
System.out.println("After Method Invoke");
return object;
}
}
public class DaoProxy implements MethodInterceptor {
@Override
public Object intercept(Object object, Method method, Object[] objects, MethodProxy proxy) throws Throwable {
System.out.println("Before Method Invoke");
proxy.invokeSuper(object, objects);
System.out.println("After Method Invoke");
return object;
}
}
cglib不同代理策略
public class DaoAnotherProxy implements MethodInterceptor {
@Override
public Object intercept(Object object, Method method, Object[] objects, MethodProxy proxy) throws Throwable {
System.out.println("StartTime=[" + System.currentTimeMillis() + "]");
method.invoke(object, objects);
System.out.println("EndTime=[" + System.currentTimeMillis() + "]");
return object;
}
}
public class DaoAnotherProxy implements MethodInterceptor {
@Override
public Object intercept(Object object, Method method, Object[] objects, MethodProxy proxy) throws Throwable {
System.out.println("StartTime=[" + System.currentTimeMillis() + "]");
method.invoke(object, objects);
System.out.println("EndTime=[" + System.currentTimeMillis() + "]");
return object;
}
}
public class DaoAnotherProxy implements MethodInterceptor {
@Override
public Object intercept(Object object, Method method, Object[] objects, MethodProxy proxy) throws Throwable {
System.out.println("StartTime=[" + System.currentTimeMillis() + "]");
method.invoke(object, objects);
System.out.println("EndTime=[" + System.currentTimeMillis() + "]");
return object;
}
}
]]>
https://www.wangxinshuo.cn/2018/11/24/cglib/feed/
0
-
Python解方程
https://www.wangxinshuo.cn/2018/11/22/python%e8%a7%a3%e6%96%b9%e7%a8%8b/
https://www.wangxinshuo.cn/2018/11/22/python%e8%a7%a3%e6%96%b9%e7%a8%8b/#respond
Thu, 22 Nov 2018 09:50:23 +0000
https://www.wangxinshuo.cn/?p=493
 ]]>
]]>https://www.wangxinshuo.cn/2018/11/22/python%e8%a7%a3%e6%96%b9%e7%a8%8b/feed/
0
-
ClassLoader
https://www.wangxinshuo.cn/2018/11/21/classloader/
https://www.wangxinshuo.cn/2018/11/21/classloader/#respond
Wed, 21 Nov 2018 02:43:35 +0000
https://www.wangxinshuo.cn/?p=490
 ]]>
]]>https://www.wangxinshuo.cn/2018/11/21/classloader/feed/
0
-
Java内存划分
https://www.wangxinshuo.cn/2018/11/20/java%e5%86%85%e5%ad%98%e5%88%92%e5%88%86/
https://www.wangxinshuo.cn/2018/11/20/java%e5%86%85%e5%ad%98%e5%88%92%e5%88%86/#respond
Tue, 20 Nov 2018 08:04:04 +0000
https://www.wangxinshuo.cn/?p=486
虚拟机栈(VM Stack):里面存放栈帧,执行Java方法。
本地方法栈:存放本地方法栈帧
堆(Heap):
程序计数器:记录线程的指令,在执行本地方法的时候此项值为Undefined。
方法区:Java方法都将加载到此区域,非线程私有。
概念解释:
栈帧(Stack Frame):存储局部变量表、操作数栈、动态链接、方法出口等信息。
常量池:
直接内存:DirectBuffer,避免在Java堆和Native堆中来回复制。
]]>
https://www.wangxinshuo.cn/2018/11/20/java%e5%86%85%e5%ad%98%e5%88%92%e5%88%86/feed/
0
-
天池数据库比赛总结
https://www.wangxinshuo.cn/2018/11/20/%e5%a4%a9%e6%b1%a0%e6%95%b0%e6%8d%ae%e5%ba%93%e6%af%94%e8%b5%9b%e6%80%bb%e7%bb%93/
https://www.wangxinshuo.cn/2018/11/20/%e5%a4%a9%e6%b1%a0%e6%95%b0%e6%8d%ae%e5%ba%93%e6%af%94%e8%b5%9b%e6%80%bb%e7%bb%93/#respond
Tue, 20 Nov 2018 02:15:12 +0000
https://www.wangxinshuo.cn/?p=483
因为本人前期使用Java来实现,后期考虑到性能的原因采用CPP的方式来实现,因此本次也将从Java和CPP这两个方面来谈一下实现思路与具体细节。
此比赛存在两阶段,分别是正确性验证、性能验证两个方面,由于正确性验证较为简单就不赘述,但要注意当key相同的时候需要更新value
所有阶段代码:https://github.com/wangxinshuo426/HPKV
赛题分析
硬件分析
硬件采用optane硬盘,读写速度相对较快。
Intel Optane技术结合了目前英特尔在存储研究上最为先进硬件介质和软件方案,其中硬件介质3D XPoint是整个Optane技术的核心。
在性能方面,16GB版本Optane内存持续读取最高为900MB/s,持续写入最高为145MB/s;4K 随机读取为190000 IOPS,4K随机写入是35000 IOPS。32GB版本持续读取速度为1200MB/s,持续写入最高为280MB/s;4K 随机读取为300000 IOPS,4K随机写入是70000 IOPS。从官方给的数据看,Optane内存不管是持续性能还是随机性能,读取性能均远好于写入性能。
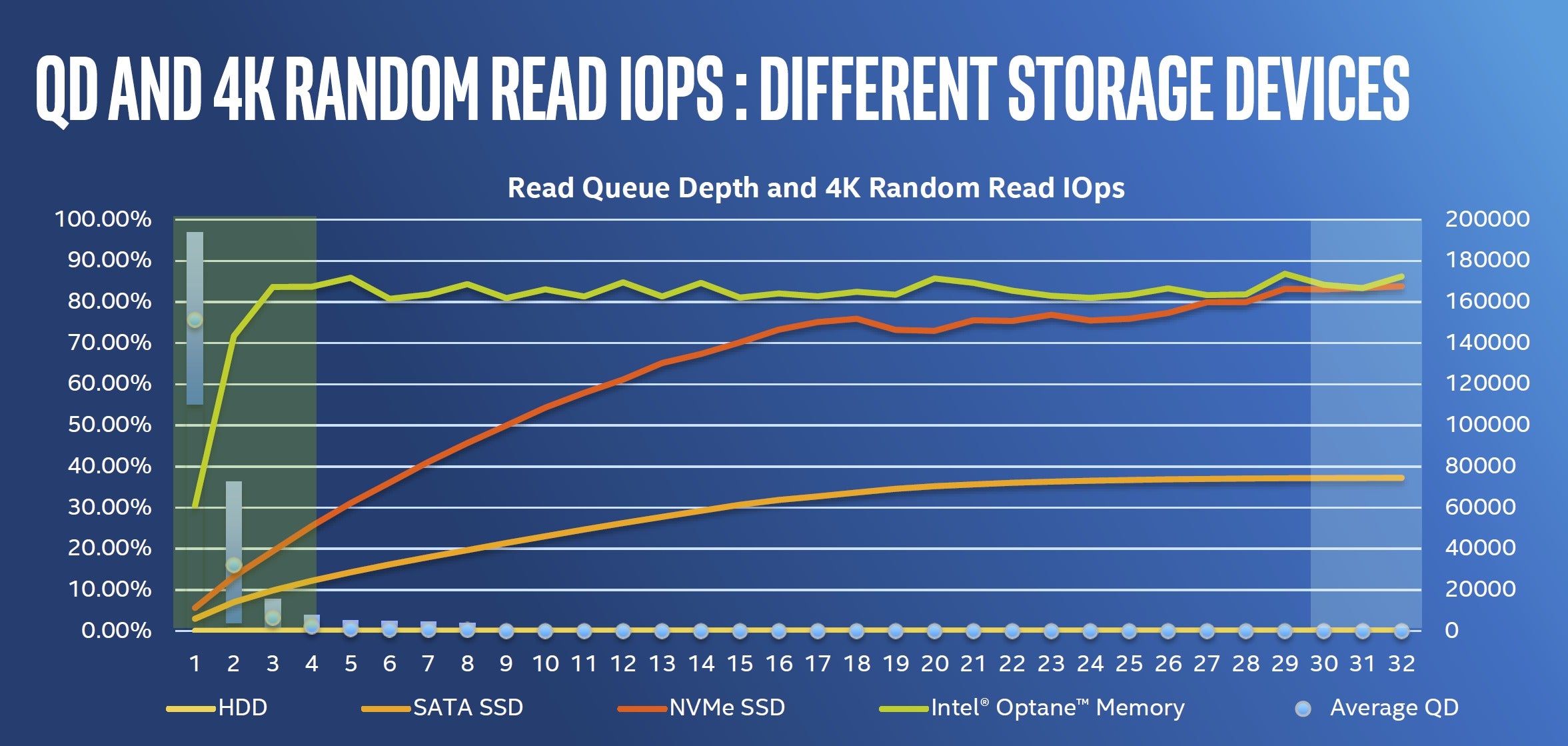
本次比赛初的时候本人对赛题的预估不足,认为只有IOPS是瓶颈,但是在比赛过程中才发现内存、IOPS都是瓶颈,尤其需要注意内存问题,因为使用的是cgroup来限定内存,因此当程序使用内存过高的时候就会直接被杀死并报OOM错误。
Java
阶段一
思路:此阶段利用Java自带的HashMap来实现,得到key、value并写入HashMap,将HashMap进行序列化,增量的写入到文件中
分析
- 首先检查HashMap的增长状态是否与键值对的数量成正相关,由下列实验可得大致正相关,相关系数为键值对的大小。


- 部分序列化并写入的策略是可行的:利用序列化之后的byte数组和RandomAccessFile来进行部分重写。(RandomAccessFile是会覆盖原记录的,在使用的时候还需要密切注意文件指针的位置)
- 选用序列化的原因是因为我判定CPU不是此次赛题的瓶颈,可以放心操作。
性能
在单线程写10000key与value的情况下耗时7494分钟,遍历完成时间为66.680秒
缺陷
最大的缺陷就是写入时间过长,不可接受。
阶段二
此阶段利用LSM树(Log Structure Merge Tree)思想来实现,LSM树的思想是:利用磁盘顺序写性能大于随机写性能,首先对一定数量范围内的Key和Value进行写日志(顺序写),当到达一定范围之后将其放到磁盘中封存,但是当小树到达一定数量之后就需要进行树的合并。
分析
目标:利用LSM树与WAL(Write Ahead Log)算法实现高性能写入
1. LSM树的特点:利用硬盘读取性能远大于写入性能的特点来构造,在牺牲了小部分的查询开销的基础上获得较大的写入速度(将随即写转换为连续写)
2. 由于日志文件是连续写,因此性能也相当可观
3. 对于CPU的性能要求并不高,连续写入100万数据的时候i7-7700K只有10%左右的利用率
4. 写放大一定存在且不可避免,此种方案的写放大还是稍大
性能
- 当log文件存储4096个键值对的时候性能在300s左右,当log文件存储8192个键值对的时候性能在210ss左右,因此可以得出结论,写入速度与log文件设定大小呈正相关(读取的时候不需要对log进行遍历)。
- 由于64个线程需要写入256GB左右的数据,因此需要控制文件的个数,使得文件大小控制在2^31到2^32的范围内(暂时不清楚如果越界会出现什么情况),文件个数也不能过多,否则将影响SSD延迟时间。
缺陷
此种方法在写入阶段是不存在任何问题的,预估的写入时间也将在230s~250s之间,但是在查询阶段就不能满足需求,因为在查询的时候需要将HashMap都反序列化到内存中,而一个HasMap进行反序列化之后就会占用2GB左右的内存,而赛题只给了3GB内存,在本地测试中发现峰值内存大概是5GB左右,所以此种方法也不得不舍弃。
Java阶段总结
Java由于受限于JVM的GC、HashMap的无序导致Java最终被舍弃
C++
阶段一
使用HashMap进行实现
此阶段使用不同的Map来实现:
1. 首先使用STL的map来实现,因为其底层是红黑树,有利于第二阶段实现按序遍历,但是由于红黑树的缺点(一个节点会拥有两个指向子节点的指针),所以被废弃。
2. 其次我采用Github中的一个内存优化的HasMap进行实现,但是还是由于OOM错误不得不放弃,经分析我认为:他的HashMap会有扩容等操作来浪费内存,因此我决定自己实现HashMap。
3. 最后我使用自制的HashMap来实现,因为已知最大的KV数量是6400万,所以可以在制作HashMap的过程中尽量避免扩容这种可能导致OOM操作的问题。
最终我还是因为OOM问题不得不放弃HashMap方法,这与一开始对运行时所需内存的预估不足导致的,一开始预估的时候我认为索引只占1~1.5GB左右的内存((8Bkey+8Bvalue+8Bpointer)× 64000000 = 1.5GB),但是频繁发生的OOM问题使我重新认识到我之前的错误。
阶段二
使用BPlusTree、查询索引、降低写锁的粒度来实现
由于在内存中建立全量索引的不可行性,而且对于Key的压缩也不怎么现实(key是完全随机值),所以我决定不在内存中维持全量索引,转而在磁盘中位置全量索引,而在内存中采用自制可控的LRU(Least Recently Used)索引(HahsMap实现)
此阶段的重难点:
1. 怎样在磁盘中维持一个树?这个树要是怎样的结构?答:利用类似指针的方式保存节点,将每个节点(8BKey、8Bvalue、8Bpointer)的起始位置当作指针项;对于树的结构一开始考虑采用的是AVL或者红黑树,但是由于不能很好的配和磁盘的4K读写,因此也需要放弃,最后选用B+Tree来实现,这种方式也是通用的数据库建立索引方式。
2. 如果内存只用来进行写入那么将造成巨大的浪费,怎样有效的利用内存?答:由于全量索引的不现实、内存的珍贵性,所以我决定采用LRU缓存淘汰策略来进行部分缓存,以期加快查询速度。
3. HashMap由于在上一阶段已经实现并验证,因此只能算是重点。
B+Tree采用Github上的开源代码来实现,但是目测应该具有相当大的写放大。
降低锁粒度主要是通过将锁细化到每个文件(在我的实现中文件有index.db,value.db.0 … value.db.127等多个文件,value之所以具有多个文件也就是考虑到降低锁粒度的需求而建立的),写入或者查询的时候使用Hash方式来进行判断value的具体归属。
未来优化方向
- 对于B+Tree来说可以浪费一定的空间来实现降低写放大的目的。
- 写入数据的时候可以采用mmap方法来加快写入速度
]]>
https://www.wangxinshuo.cn/2018/11/20/%e5%a4%a9%e6%b1%a0%e6%95%b0%e6%8d%ae%e5%ba%93%e6%af%94%e8%b5%9b%e6%80%bb%e7%bb%93/feed/
0
-
MMAP(c++版)
https://www.wangxinshuo.cn/2018/11/16/mmapc%e7%89%88/
https://www.wangxinshuo.cn/2018/11/16/mmapc%e7%89%88/#respond
Fri, 16 Nov 2018 07:56:08 +0000
https://www.wangxinshuo.cn/?p=481
#include <unistd.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <string.h>
int main(void) {
int fd = open("test_file", O_RDWR | O_CREAT, (mode_t)0600);
const char *text = "hello";
size_t textsize = strlen(text) + 1;
lseek(fd, textsize-1, SEEK_SET);
write(fd, "", 1);
char *map = mmap(0, textsize, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
memcpy(map, text, strlen(text));
msync(map, textsize, MS_SYNC);
munmap(map, textsize);
close(fd);
return 0;
}