深入理解KMP算法
写在最前面
早在大二我就想写一篇KMP的总结,主要是因为大部分blog上的文章有着各种各样的不足:有的过于冗长,有的学习曲线太陡,而《挑战》和《算法竞赛》上相关部分都因为字符串相关的内容过多,KMP算法部分不甚详尽。但是当时没有发在blog上,因为感觉从next数组谈起的话,算法的推导总会很奇怪、不顺畅。
时隔两年,花了两天时间,重新梳理了逻辑,缀字成文。
这里是我的个人网站:
https://endlesslethe.com/kmp-tutorial.html
有更多总结分享,最新更新也只会发布在我的个人网站上。
排版也可能会更好看一点=v=
KMP算法有什么用
在文本编辑中,我们经常要在一段文本(text)中找到一串我们想要的字符串(即模板,pattern)的位置。由此,便产生了字符串的匹配问题。而KMP就是为高效解决这一问题提出来的。
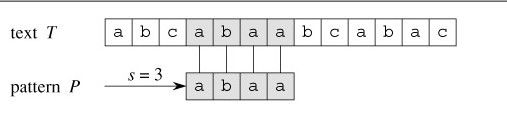
事实上,KMP算法的运行速度和理解的难度都高于其他的单文本单模板匹配算法。但是KMP算法在Tier树上扩展得到的AC自动机算法,是解决单文本多模板匹配的不二法门。如果读者有志于ACM竞赛的话,KMP算法是不能不理解的基础内容。
基础定义
这里简单地定义几个基础的名词,随着推导的深入,新的名词会在文中给出定义。
- 文本较长,模板较短。我们在文本链上查找模板链。
- 文本用T表示,长度为n。模板用P表示,长度为m。
- 文本指针:一个指针,它在文本串上从头到尾一位一位地移动, 指向文本第一个未比较的字符,用i表示。文本指针的编号从0开始。
- 模板指针:一个指针,它在模板链上移动,指向模板第一个未比较的字符,用j表示。模板指针的编号也从0开始。
- 匹配:当它作为动词时,指T[i] == P[j](且前面若干个字符也存在T[i’] == P[j’]),这是针对一个字符而言,其与失配对应。当它作为名词时,指的是T的某个子串与P一一对应,即匹配了恰好m次,称为一个匹配。
- 失配:指T[i] != P[j],虽然前面的若干个字符都匹配,但在这个字符不能匹配。
- 已匹配模板链:当失配发生时,前面若干个已经匹配的字符,称之为已匹配模板链。
先看一个朴素算法
我们不难由“判断两个字符串是否相等”入手,从T[0]开始向后比较len§个字符,如果相等,则找到一个匹配。如果不相等,则继续从T[1]开始比较。
这样的时间复杂度为O((N-M+1)M),显然需要进一步优化。下图为匹配模板nano的过程。

void match(char* T, char* P) {
int n = strlen(T), m = strlen(P);
for (int i = 0; i+m < n; i++)
for (int j = 0; j < m; j++) {
if (T[i+j] != P[j]) break;
if (j == m-1) v.push_back(i+1);
}
}
直观理解
一个天才的想法
朴素算法是非常符合直觉的,但朴素算法效率有点低。KMP算法通过观察模板链移动的过程,找到了一个思路,如下图所示:
[外链图片转存失败(img-UwX4yYde-1562518977406)(https://endlesslethe.com/wordpress/wp-content/uploads/2019/07/kmp3.jpg)]
对这次的移动进行观察可以发现,一旦在“abbaab”后失配,那么就下一次想要再匹配到失配处的话,需要移动4次后匹配“ab”。注意!这里有一个天才的想法,这里的“ab”正是失配时这个“模板链子串”的“最长公共前后缀”。
三个基础的问题
这里突然出现了若干个陌生名词,定义并解释一下:
- 字符串前缀:大多数读者应该了解的名词,即包含字符串首字母的所有子串。比如“abcd”的前缀就是“a”“ab”“abc”,但不包括“abcd”。
- 字符串后缀:大多数读者应该了解的名词,即包含字符串末字母的所有子串。比如“abcd”的后缀就是“d”“cd”“bcd”,但不包括“abcd”。
- 本文用“模板链子串”来特指模板链的某个前缀,这个前缀正好对应了在某个位置失配的“已匹配模板链”。
- 公共前后缀:公共前后缀指的是一个字符串其前缀和后缀相同时对应的字符串。比如“abcabcabc”,其公共前后缀就有“abc”、“abcabc”。最长公共前后缀,即是这些字符串中最长的部分。
依照上面的想法,每一次失配后的移动次数,都和“模板链子串”的“最长公共前后缀”有关,且=len(模板链子串)-len(最长公共前后缀)。当然,对于不同的“模板链子串”,显然移动的次数是不同的。
自然而然,人们会想到三个问题:
问题1:移动次数是如何与公共前后缀联系起来的?
问题2:为什么是“最长公共前后缀”而不是仅仅是“公共前后缀”?
问题3:如果“最长公共前后缀”依然失配怎么办呢?继续找“最长公共前后缀”的“最长公共前后缀”吗?
问题一需要大家重新理解一下“移动次数”这个概念。一方面它指的是“当模板链失配时,需要将模板链沿着文本链移动几个字符,才能从失配处继续匹配”,另一方面同样是指“当模板链失配时,需要将模板链指针回退几个字符,才能从失配处继续匹配”。
继续以下图为例,说明这个概念:
[外链图片转存失败(img-CXFSetBJ-1562518977406)(https://endlesslethe.com/wordpress/wp-content/uploads/2019/07/kmp3.jpg)]
一旦在“abbaab”后失配,那么之后若干次需要匹配的模板链前缀就应该是“abbaa”、“abba”、“abb”和“ab”,这是一个将模板链回退的过程。进一步说,只有模板链的对应后缀,“bbaab”、“baab”、“aab”和“ab”,匹配上了这些模板链子串,才能继续匹配。如果前缀和后缀不匹配,那么一定不能继续匹配,这就回答了问题一“移动次数是如何与公共前后缀联系起来的”
理解了每一次移动都对应一次模板链的回退,那么第二个问题就更好回答了:如果说失配时的模板链子串公共前后缀有长有短,为了不遗漏可能的匹配机会,模板链的移动距离应该尽可能的小,也就是前缀尽量的长。以失配时模板链子串“abcabcabc”为例,潜在的匹配机会有“abcabc”和“abc”,那么显然应该选择移动3次的“abcabc”,而不是移动6次的“abc”。
公共前后缀的性质和问题3
不过,如果选择移动3次的最长公共前后缀“abcabc”到底会不会丢失移动6次的公共前后缀“abc”呢?其实如果我们再仔细一点观察,可以发现“abc”正是“abcabc”的最长公共前后缀。这正是公共前后缀的性质!如果一个字符串S有若干个公共前后缀,不妨按照长度的从小到大排列,记作\(s_1,…, s_i\)。那么S的最长公共前后缀是\(s_i\),而\(s_i\)的最长公共前后缀为\(s_{i-1}\)。证明这个性质非常简单,这里就不赘述了。
利用这个性质,我们可以发现第三个问题几乎是显而易见的,“是的”。原来不停失配、不停找“最长公共前后缀”的“最长公共前后缀”这个过程,就是遍历失配时模板链子串的、从长到短的公共前后缀过程。
小结
这样,通过回答这两个问题,我们就大概说清楚了匹配的整个思路:从文本链首部开始匹配,当发生失配时,根据相应模板链子串的最长公共前后缀计算下一次匹配开始的位置,将模板链指针回退。

时间复杂度:下一次匹配开始的位置正好依然是失配时的位置,所以时间复杂度为O(N)。
如何快速计算最长公共前后缀
我已经非常闲得蛋疼地将KMP算法的整体思路写成了伪代码的形式。我们可以发现目前算法尚未说清楚的部分只有一行,即第4行的计算最长公共前后缀的长度。
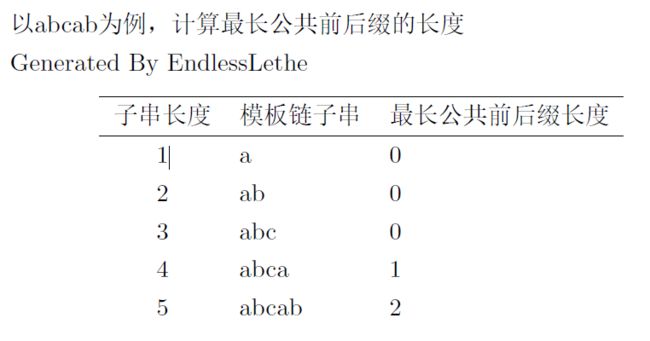
注意到,我们会遍历所有长度的模板链子串(前缀),它们的最长公共前后缀都需要计算。而好消息是,这些子串之间的最长公共前后缀长度是可以通过递推计算的。如下图所示:
为了便于说明和理解代码,这里先进行部分的定义以及符号化:
长度为i的模板链子串\(s_i\)的第\(j\)个公共前后缀记作\(cpf_{i, j}\), 最长公共前后缀记作\(lpf_i\),最长公共前后缀的长度记为next[i],这里的长度也对应下一次开始匹配的字符位置。
那么我们可以从图中发现:
next[0] = next[1] = 0,即模板链子串的长度为0或1时,每次都需要从P[0]开始匹配。
而长度为i的模板链子串的最长公共前后缀,是由长度为i-1的模板链子串的公共前后缀推出来的。不过注意,\(lpf_i\)不一定由\(lpf_{i-1}\)推出,而也可能由\(cpf_{i-1, j}\),推出。
计算模板链子串的最长公共前后缀,需要看此时的最长公共前后缀能不能依据上一次的某个公共前缀添加而成,而且添加的字符正是P[i]。以图中为例:"abc"是不存在公共前后缀的,那么“abca”的最长公共前后缀要么同样不存在,要么就是新添加的字符“a”。"abca"的公共前后缀是“a”,那么“abcab”的最长公共前后缀要么不存在,要么就是“a”加上新添加的字符“b”。
这里会涉及到从长到短遍历公共前后缀的问题,利用前面提到的公共前后缀性质即可简单遍历。
用代码可以写作:
while (j && P[i] != P[j]) j = next[j]
next[i] = P[next[i-1]] == P[i] ? next[i-1] + 1 : 0
实现代码
下一次匹配位置next[]的求法
根据前文发现的规律:
next[0] = next[1] = 0
next[i] = P[next[i-1]] == P[i] ? next[i-1] + 1 : 0
void getFail(char *P) {
int m = strlen(P);
next[0] = next[1] = 0;
for (int i = 1; i < m; i++) {
int j = next[i];
while (j && P[i] != P[j]) j = next[j];
next[i+1] = P[i] == P[j] ? j+1 : 0;
}
}
匹配过程
综上所述,匹配过程从i=0和j=0开始。
- 如果T[i] == P[j],则i++,j++。
j == m后仍然继续比较,此时P[j] == '\0’必然失配 - 如果失配,则将j转跳后比较是否匹配,如果依然失配,则继续转跳。
- 一直重复步骤1、2到i == n-1。
void find(char *T, char *P) {//T为文本串 P为模板串 文本串为长的串
int n = strlen(T), m = strlen(P);
getFail(P);
int j = 0;
for (int i = 0; i < n; i++) {
while (j && P[j] != T[i]) j = next[j];
if (P[j] == T[i]) j++;
if (j == m) {//匹配上
v.push_back(i-m+2);//字符串的起始地址(i-m+1)+从1开始的编号偏移量(1)
}
}
}
其他的单文本单模板匹配算法
KMP算法关注的移动过程是模板链子串不断回退、直到又从失配处开始匹配的过程。而通过关注移动中的不同特点,比如说“如果失配字符不存在字符串中,就应该直接从适配字符下一个位置开始匹配”,产生了许多其他的算法。
- BM算法
- Horspool算法
- Sunday算法
题目总结
- 匹配问题
○ HDU 2087 求文本串T中不重叠的模板P的匹配数
如果题目要求不重叠,那么当整个P匹配完成后不再转跳到f(m),而转跳到0
○ SCU 4438 删除文本串的所有敏感词(删除后因为拼接的原因可能会继续删除)
每次匹配后可以倒退整个P的长度重新匹配。
用’ '表示删除就可以过了,如果想继续优化,可以用栈 - 循环节问题
○ LA 3016(SEERC 2004)求字符串S每个前缀的循环节
这里给出一个失配函数的重要性质:对于文本指针i,如果 i % (i-f[i]) == 0,则说明0~i-1的位置有循环节,且长度为i-f[i]。
不难通过举例理解,这里给出一例"ababababa"。
○ HDU 3746 求字符串S最少需要补全多少字母使其成为循环串 - next性质问题
○ 基本题型 求一个字符串和所有前缀匹配的所有后缀
不就是公共前后缀吗?白送题
用字符串hash的方法,hash所有前缀和所有后缀也可以。
后记
为什么KMP成为了一个伟大的算法?我觉得是因为KMP敏锐地发现了最长公共前后缀的存在。最长公共前后缀是模板链自身的特点,和文本链无关,因此KMP可以很容易地拓展到多模板链的匹配问题上。而且通过对next数组的研究,可以进一步挖掘模板链自身的性质,比如循环节问题。
参考文献
《算法竞赛入门经典 训练指南》