残差
残差在数理统计中是指实际观察值与估计值(拟合值)之间的差。在集成学习中可以通过基模型拟合残差,使得集成的模型变得更精确;在深度学习中也有人利用layer去拟合残差将深度神经网络的性能提高变强。这里笔者选了Gradient Boosting和Resnet两个算法试图让大家更感性的认识到拟合残差的作用机理。
Gradient Boosting
下面的式子时Gradient Boosting的损失函数,其中。
这里的意味着最后通过 Gradient Boosting学习出来的模型,而这个最终的模型怎么来呢,参照下方代码大致可以总结为三部:
- 训练一个基学习器Tree_1(这里采用的是决策树)去拟合data和label。
- 接着训练一个基学习器Tree_2,输入时data,输出是label和上一个基学习器Tree_1的预测值的差值(残差),这一步总结下来就是使用一个基学习器学习残差。
- 最后把所有的基学习器的结果相加,做最终决策。
下方代码仅仅做了3步的残差拟合,最后一步就是体现出集成学习的特征,将多个基学习器组合成一个组合模型。
from sklearn.tree import DecisionTreeRegressor
tree_reg1 = DecisionTreeRegressor(max_depth=2)
tree_reg1.fit(X, y)
y2 = y - tree_reg1.predict(X)
tree_reg2 = DecisionTreeRegressor(max_depth=2)
tree_reg2.fit(X, y2)
y3 = y2 - tree_reg2.predict(X)
tree_reg3 = DecisionTreeRegressor(max_depth=2)
tree_reg3.fit(X, y3)
y_pred = sum(tree.predict(X_new) for tree in (tree_reg1, tree_reg2, tree_reg3))
其实上方代码就等价于调用sklearn中的GradientBoostingRegressor这个集成学习API,同时将基学习器的个数n_estimators设为3。
from sklearn.ensemble import GradientBoostingRegressor
gbrt = GradientBoostingRegressor(max_depth=2, n_estimators=3, learning_rate=1.0)
gbrt.fit(X, y)
形象的理解Gradient Boosting,其的过程就像射箭多次射向同一个箭靶,上一次射的偏右,下一箭就会尽量偏左一点,就这样慢慢调整射箭的位置,使得箭的位置和靶心的偏差变小,最终射到靶心。这也是boosting的集成方式会减小模型bias的原因。
接下来我们再来了解一下最近在深度学习领域中的比较火的Residual Block。
Resnet
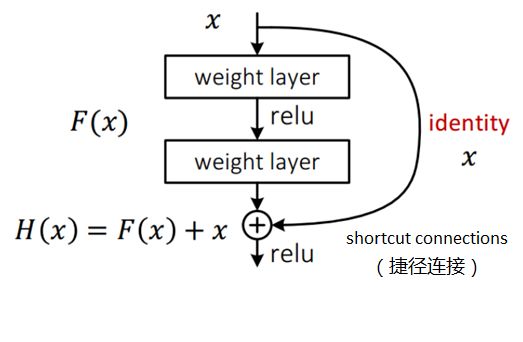
Resnet是2015年何凯明大神提出来的一个深度CNN模型,主要解决了随着神经网络层数变多,拟合效果反而变差的问题。而Residual Block是Resnet中一个最重要的模块,Residual Block的做法是在一些网络层的输入和输出之间添加了一个快捷连接,这里的快捷连接默认为恒等映射(indentity),说白了就是直接将原始输入不做任何改变和输出做加和,其公式如下:
如下图所示,x 表示residual block的输入, H(x)表示residual block的输出,而F(x)代表着残差,把公式简单变换一下:
就变成了通过神经网络去拟合输入与输出之间的残差F(x)。加了这个模块之后,神经网络的层数可以构建得越来越深,而且不会出现效果变差的现象,反之该模型在imagenet这个任务上再进一步,拿下了2015年的冠军。这充分说明使用residual block拟合残差使得深度学习模型变得更加强大。
对着下方代码我们可以更清晰的看到residual block的具体操作:
- 输入x,
- 将x通过三层convolutiaon层之后得到输出m,
- 将原始输入x和输出m加和。
就得到了residual block的总输出,整个过程就是通过三层convolutiaon层去拟合residual block输出与输出的残差m。
from keras.layers import Conv2D
from keras.layers import add
def residual_block(x, f=32, r=4):
"""
residual block
:param x: the input tensor
:param f: the filter numbers
:param r:
:return:
"""
m = conv2d(x, f // r, k=1)
m = conv2d(m, f // r, k=3)
m = conv2d(m, f, k=1)
return add([x, m])
在resnet中残差的思想就是去掉相同的主体部分,从而突出微小的变化,让模型集中注意去学习一些这些微小的变化部分。这和我们之前讨论的Gradient Boosting中使用一个基学习器去学习残差思想几乎一样。
结语
至此,我们了解到了集成学习和深度学习中如何使用模型拟合残差去加强模型的性能。使用模型拟合残差的过程,还可以理解成模型在 Loss 函数上沿着梯度下降的方向前进,每增加一个基学习器就对应着梯度下降的一次更新。如下图中,每一个红点就代表着一个当前时刻的集成模型,最终的模型对应于loss函数图像中最低的那个点。

Gradient Boosting通过拟合残存使得模型的 更加精确(降低模型的偏差Bias),Residual Block的通过拟合残差使得深度网络能够变得 更深更强。所以,如果你的模型效果性能不足,可以考虑考虑拟合残差让模型变强哦。
参考:
https://blog.csdn.net/u014665013/article/details/81985082
https://mp.weixin.qq.com/s/Dhp3FbbK5yPYRwJTKjGZSQ
Deep Residual Learning for Image Recognition