Windows平台下安装ElasticSearch7.2并集成ik和拼音分词器
1.ElasticSearch的安装以及配置ik和pinyin分词器
自己选择自己需要的版本
ElasticSearch下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
IK分词器下载地址 :https://github.com/medcl/elasticsearch-analysis-ik/releases
pinyin分词器下载地址 :https://github.com/medcl/elasticsearch-analysis-pinyin/release
kabana下载地址 : https://www.elastic.co/cn/downloads/past-releases#kibana
接下来就是把ik和pinyin分词器配置到ElasticSearch中
首先把这两个压缩包解压一下
复制到ElasticSearch目录下的plugins
并且把这两个文件夹名改成ik和pinyin
已经配好的如下图所示



然后启动测试一下,是否成功加载这两个分词插件
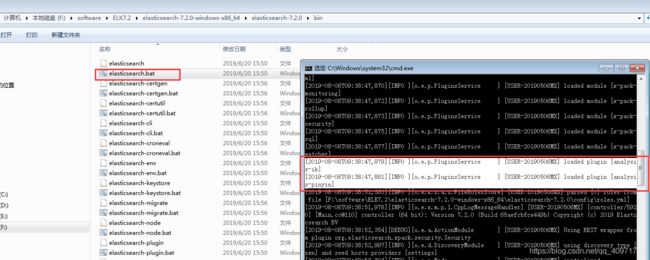
可以看到ik和pinyin分词器已经成功加载了
直接把kabana解压,启动好之后测试一下这两个分词器是否有效果
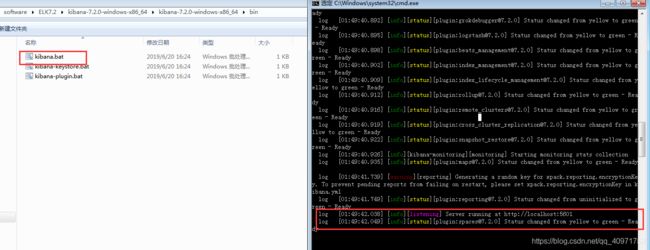
看到这个说明kabana已经启动好了:localhost:5601访问测试一下

选择开发工具,为什么我是中文的?那是因为你没有配kibana.yml,7.x版本已经支持国际化了
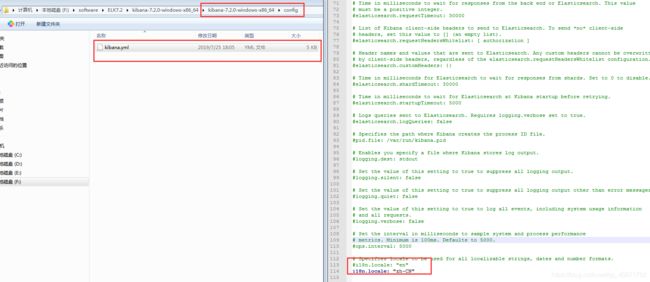
IK有两种分词器,ik_max_word和ik_smart
ik_max_word:最细粒度的进行分词
ik_smart:最粗粒度的分词
废话不多说,直接测试
GET /_analyze
{
"text": "中华人民共和国",
"analyzer": "ik_max_word"
}
返回值
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
}
]
}
pinyin分词测试,pinyin只有pinyin一种分词器,
GET /_analyze
{
"text": "中华人民共和国",
"analyzer": "pinyin"
}
返回值
{
"tokens" : [
{
"token" : "zhong",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 0
},
{
"token" : "zhrmghg",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 0
},
{
"token" : "hua",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 1
},
{
"token" : "ren",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 2
},
{
"token" : "min",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 3
},
{
"token" : "gong",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 4
},
{
"token" : "he",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 5
},
{
"token" : "guo",
"start_offset" : 0,
"end_offset" : 0,
"type" : "word",
"position" : 6
}
]
}