数据分析笔试题(网易,阿里,京东...)
网易
https://blog.csdn.net/weixin_44915703/article/details/97245622
https://www.nowcoder.com/discuss/211212?type=post&order=time&pos=&page=1
https://www.nowcoder.com/discuss/211215?type=all&order=time&pos=&page=1
1. 推荐系统评价指标和实验方法
a. 评价指标:
1)用户满意度:只能通过用户调查或在线实验获得。
对于用户调查方式,用调查问卷方式;对于在线实验方式,主要通过一些对用户行为的统计得到。
对于用户行为,可分为显性和隐性之分。若用户购买了推荐的商品,则说明在一定程度上满意,可用购买率度量。还可用用户反馈界面收集,通过统计两种按钮的单击情况度量。更一般的情况下,用点击率、用户停留时间和转化率等指标度量。
点击率: 指您的广告所获得的点击次数除以其展示次数所得的比值。
转化率: 指在一个统计周期内,完成转化行为的次数占推广信息总点击次数的比率。分为广告转换率和网站转换率。对于广告转换率,转换指的是网民的身份产生转变的标志,如网民从普通浏览者升级为注册用户或购买用户等。转化标志一般指某些特定页面,如注册成功页、购买成功页、下载成功页等,这些页面的浏览量称为转化量。广告用户的转化量与广告到达量的比值称为广告转化率。
2 ) 预测准确度:离线实验测评
表示一个推荐算法预测用户行为的能力。如果是 评分预测模型(即打分)一般用RMSE(均方根误差)和MAE(平均绝对误差)计算。如果是Top N推荐(即个性化推荐),一般用准确率(precision)和召回率(recall)计算。
准确率(accuracy)= 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN) = 70%
精确率(precision) = TP/(TP+FP) = 80%
召回率(recall) = TP/(TP+FN) = 2/3
3 )多样性
满足用户广泛的兴趣需求。描述了推荐列表中物品两两之间的不相似性。多样性和相似性对应。
b. 实验方法:
1)离线实验
需要有一个日志数据集,不需一个实际的系统来供它实验。
优点:不需真实用户参与,直接快速、方便,可测试大量算法。
缺点:无法获得很多商业上关注的指标,如点击率、转化率等。
2 ) 用户调查
在上线测试前需做一次用户调查。
优点:得到与用户主观感受有关的指标,相对在线实验风险很低,出现错误后很容易弥补。
缺点:调查成本很高,需用户花大量时间完成一个任务并回答相关问题。需花钱雇佣测试用户,大多数情况下很难进行大规模的用户调查,得出的结果大多没有统计意义。
3)在线实验
在离线实验和用户调查后将推荐系统上线做AB测试,将新系统和旧算法进行比较。将用户随机分成几组,对不同组用户采用不同算法,比较不同算法性能。
优点:可公平获得不同算法实际在线时的性能指标,包括商业上关注的指标
缺点:周期较长,需进行长期实验才能得到可靠的结果。故只测试在离线实验和用户调查中表现较好的算法。
一般来说,一个新推荐算法上线要完成上述的3个实验。首先,须通过离线实验证明它在很多离线指标上优于现有的算法;然后,通过用户调查确定它的用户满意度不低于现有的算法;最后,通过在线AB测试确定它在我们关心的指标上优于现有的算法,指标包括准确度、覆盖度、新颖度、惊喜度、信任度、透明度等。
A/B测试: A/B测试是一种流行的网页优化方法,可以用于增加转化率注册率等网页指标。简单来说,就是为同一个目标制定两个方案(比如两个页面),将产品的用户流量分割成 A/B 两组,一组试验组,一组对照组,两组用户特点类似,并且同时运行。试验运行一段时间后分别统计两组用户的表现,再将数据结果进行对比,就可以科学的帮助决策。比如在这个例子里,50%用户看到 A 版本页面,50%用户看到 B 版本页面,结果 A 版本用户转化率 23%,高于 B 版本的 11%,在试验流量足够大的情况下,我们就可以判定 A 版本胜出,然后将 A 版本页面推送给所有的用户。
2. 电商推荐系统冷启动期与高峰期的数据分析有什么不同,可举例说明。
a. 冷启动该问题主要分三类:
1 ) 用户冷启动:如何给新用户做个性化推荐。
2 ) 物品冷启动:如何将新的物品推荐给可能对它感兴趣的用户这一问题。
3 ) 系统冷启动:如何在一个新开发的网站上设计个性化推荐系统。
b. 冷启动问题的解决方案:
1 ) 提供非个性化的推荐:热门排行榜,当用户数据收集到一定的时候,再切换为个性化推荐
2 ) 利用用户注册时提供的年龄、性别等数据做粗粒度的个性化,做个用户画像,基于用户的登录信息,利用历史特征下某种特征喜欢某种物品的喜好程度进行个性化推荐。
3 ) 利用用户的社交网络帐号登录,导入用户在社交网站上的好友信息,然后给用户推荐其好友喜欢的物品。
3. 事务与锁机制有什么关系?
事务的隔离级别通过锁的机制来实现。
https://blog.csdn.net/hackxiaoF/article/details/50264939
4. 从数字集合{1,2,3,4,… ,20}中选出3个数字的子集,如果不允许两个相连的数字出现在同一集合中,那么能够形成多少个这种子集?
此问题等价于从20本书排列好的书中取出3本不相邻的书,等价于想17本排列好的书中插入3本不想邻的书,利用插空法的思想为C18,3。
5. 将4个不一样的球随机放入5个杯子中,则杯子中球的最大个数为3的概率是?
从4个球里取出三个放进5个杯子中的任意一个,剩下的一个球放入剩下的四个杯子里的任意一个
(C43 * C51* C41)/5^4
6. 已知y=f(x)的均差f(x0, x1, x2)=14/3,f(x1, x2, x3)=15/3,f(x2,x3,x4)=91/15,f(x0, x2, x3)=18/3,那么均差f(x4, x2, x3)=( 91/15)
(对称性)差商与插值节点的顺序无关。

7. 一个快递公司对同一年龄段的员工,进行汽车,三轮车,二轮车平均送件量的比较,结果给出sig.=0.034,说明。
按照0.05显著性水平,拒绝H0,说明三类交通工具送件量有显著差异。
8. 小明在一次班干部二人竞选中,支持率为百分之五十五,而置信水平0.95以上的置信区间为百分之五十到百分之六十,请问小明未当选的可能性有可能是(3%)
95%落在百分之五十到六十,落在百分之50以下和百分之60以上的概率分别为2.5%,所以不当选的概率(落在百分之50以下)为2.5%约等于3%。
9. 销售员需统计以下公式所示数据=SUM(SUMIF(C2:C9,{"<10","<6"})*{1,-1}), 请问,该公式返回值为14
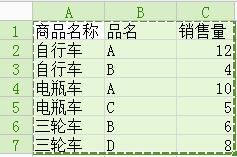
C2:C9按照"<10","<6"条件分别求和,再按照1,-1求和,即23-9=14。
小于10的乘以1,小于6的乘以-1,再求和。
(4+5+6+8)*1+(4+5)*1=14
10. SQL语句执行的顺序是
1.FROM
2.JOIN ON
3.WHERE
4.GROUP BY
5.HAVING
6.SELECT
7.ORDER BY
11. 设随机变量X和Y都服从正态分布,且它们不相关,则( X与Y未必独立)
补充:只有当(X,Y) 服从二维正态分布时,X与Y不相关⇔X与Y独立
若X和Y都服从正态分布且相互独立,则(X,Y)服从二维正态分布
12. 某地区每个人的年收入是右偏的,均值为5000元,标准差为1200元。随机抽取900人并记录他们的年收入,则样本均值的分布为(近似正态分布,均值为5000元,标准差为40元)
中心极限定理,样本量N只要越来越大,抽样样本n的样本均值会趋近于正态分布,并且这个正态分布以u为均值,sigma^2/n为方差。
左偏分布(负偏态)中:mean(平均数)
https://baike.baidu.com/item/正偏态/6639492?fr=aladdin
13. 抽取30个手机用户,计算出他们通话时间的方差。要用样本方差推断总体方差,假定前提是所有用户的通话时间应服从(正态分布)
一个总体的方差的区间估计其前提条件是总体服从正态分布。用卡方分布构造总体方差的置信区间。
14. 命题A:随机变量X和Y独立,命题B:随机变量X和Y不相关。A是B的
__充分不必要__条件。
15. 假定树根的深度为0,则高度为6的二叉树最多有___64___个叶节点。
一棵树当中没有子结点(即度为0)的结点称为叶子结点。所以2^6=64。
注:某节点的深度是指从根节点到该节点的最长简单路径边的条数,而高度是指从该节点到叶子节点的最长简单路径边的条数。树的高度和深度是相等的。最深的叶结点的深度就是树的深度。
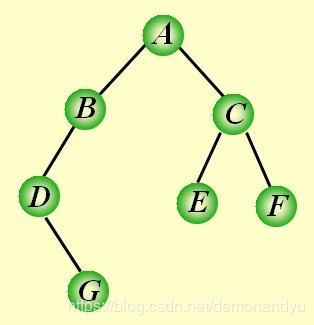
假定树深度为0,上图中二叉树的高度和深度为3
16. 已知一棵树具有10个节点,且度为4,根节点的高度为1,那么(该树的高度至多是7)
X的子女数目称为X的度。
17. 对于以下关键字{55,26,33,80,70,90,6,30,40,20},增量取5的希尔排序的第一趟的结果是:(55,6,30,40,20,90,26,33,80,70)
{55,26,33,80,70,90,6,30,40,20} 增量为5, 从55开始每隔5个距离取值分为1组,共分为5组,分别为{55,90} {26,6}{33,30}{80,40}{70,20}
先组内排序取最小值:55,6,30,40,20,后取剩余值:90,26,33,80,70。
18. 设二叉排序树中关键字由1到999的整数构成,现要查找关键字为321的节点,下面关键字序列中,不可能出现在二叉排序树上的查找序列是(888、231、911、244、898、256、362、366)
补:
1) 二叉排序树的特点就是:
A. 若左子树不空,则左子树上所有结点的值均小于或等于它的根结点的值
B. 若右子树不空,则右子树上所有结点的值均大于或等于它的根结点的值
C. 左、右子树也分别为二叉排序树
2 ) 看B选项的最后两个数,321 和 362 比较以后,明显321< 362 ,必然会去寻找362的左子树,此时应该去寻找362的左子树,但是366大于362肯定不是左子树。
3)二叉排序树的算法就是
首先将待查关键字key与根节点关键字t进行比较:
A.如果key = t, 则返回根节点指针。
B.如果key < t, 则进一步查找左子树。
C.如果key > t, 则进一步查找右子树。
19. 用13的瓷砖密铺320的地板有几种方式?(1278)
一共可能有2,5,8,11,14,17块砖头竖着放((20-2)%3==0其余数字同理。)
竖着放代表长度为3的边刚好接触。A6,6代表6!也等于6的阶乘
当有2块竖着放,一共有8(2+(20-2)/3=8)块转,其中6块为竖着放,2块横着。A8,8/(A6,6A2,2)=28;
当有5块竖着放,一共有10块转,其中5块为竖着放,5块横着。A10,10/(A5,5A5,5)=252;
当有8块竖着放,一共有12块转,其中8块为竖着放,4块横着。A12,12/(A8,8A4,4)=495;
当有11块竖着放,一共有14块转,A14,14/(A11,11A3,3)=364;
当有14块竖着放,一共有16块转,A16,16/(A14,14A2,2)=120;
当有17块竖着放,一共有18块转,A18,18/(A17,17A1,1)=18;
当有20块竖着放,结果为1;
以上加总为1278;
令f(n)为3n的铺法,那么先取出一块:如果这一块竖着铺,则3n变成了3*(n-1),也就是f(n-1);如果这一块横着普,而又因为只有三行,所以下面的两块也只能横着铺,则3n变成了3(n-3)。综上可以得到f(n)=f(n-1) + f(n-3)。
递推获得f(20)即可。
20. 有20个人去看电影,电影票50元。其中只有10个人有50元钱,另外10个人都只有一张面值100元的纸币,电影院没有其他钞票可以找零,问有多少种找零的方法?
卡特兰数问题,关于这个了解甚少就做一个基本介绍,其实这里如果用卡特兰数来做还得有一个条件就是且一人只买一张票,也就是说每一个有50块钱的人要先去付钱,然后再是拿着100块钱的人去付钱,然后这里我们看成是出栈和入栈操作,把出栈次序和进栈次序构成40个数字的序列(进表示收取50元可用1表示。出表示收取100元,找零50元,可用0表示。),因为要进栈和出栈都算在这个序列里面,然后就可以用卡特兰数来求解了,我们这里可以直接用公式C(n,2n)/(n+1)=C(10,20)/11=16796,这个公式是卡特兰数的一般公式。
https://blog.csdn.net/Hackbuteer1/article/details/7450250
-
考拉海购始终以用户为中心,为用户提供高品质的商品,帮助用户“用更少的钱,过更好的生活”。为了满足不同用户的需求(比如新客户的要求可能跟老客户不同,流失客户需要特殊的关怀) ,请你设计一套具体的方案,合理划分不同用户,并能给出相应的建议。
1、新用户——引导性信息收集
任何电商品牌都有一套属于自己的推荐算法,但是对于新用户和新商品这种冷启动问题一般还是没有很好的解决方法。实际上,新商品有很多性能参数,可以根据相近商品进行预测,而新用户对于算法来说是一个完全空白的样本,不利于探测客户需求,所以建议在新用户注册时设计一套能够捕捉购买方向和趋势的问卷,并配合问卷选择发放一些对应的优惠券,这样一方面可以引导新用户在情愿的情况下给出真是的购买意愿,另一方面也能够在最快的时间内捕捉到该用户的一些信息,再一方面促进了用户购买商品的几率。
2、规律用户——捕捉规律行为
大部分用户的购买行为存在周期性,比如优惠周期,使用周期,系统可以根据用户在过去的购买和浏览行为探索用户购买周期,然后预测下一个购买周期,并且发送优惠信息,这样既让用户享受到了优惠,又实现了营销。
3、流失用户——捕捉细节
万事皆有原因,一个用户流失要么是在这里吃过亏,要么是觉得买不到想要的,要么是别的平台更便宜,无非这三大类原因,所以应该捕捉用户最后的浏览信息,浏览表明有购买意愿,针对这些商品基于一些优惠,吸引用户再次浏览,根据一次次吸引浏览来判断不购买原因,再对症下药。
注:要区分流失用户和规律用户,这两类行为存在很大的相似性,但是后者其实并不需要太多优惠或行为进行挽留。 -
bootstrap 是什么原理—有放回的从N个样本中抽样n个。
bootstrap方法是从大小为n的原始训练数据集中随机选择n个样本点组成一个新的训练集,这个选择过程独立重复B次,然后用这B个数据集对模型统计量进行估计(如均值、方差等)。由于原始数据集的大小就是n,所以这B个新的训练集中不可避免的会存在重复的样本。 -
用户消费表中时间格式是“年-月-日-时-分-秒”,在MySQL中获取“年-月-日”的函数是(A)
A DATE --返回日期
B GETDATE —返回日期和时间
C DAY()–1、day(date_expression) 返回date_expression中的日期值
D GETDAY()—无此函数 -
假设使用较短的时间在一个足够大的数据集上训练决策树,可以采用什么办法(C)
A 增加树的深度
B 增加学习率
C减少树的深度
D 减少树的数量
解析: 增加树的深度, 会导致所有节点不断分裂, 直到叶子节点是纯的为止. 所以, 增加深度, 会延长训练时间.决策树没有学习率参数可以调. (不像集成学习和其它有步长的学习方法)决策树只有一棵树, 不是随机森林。 -
需要删除表user的数据,但是保留表结构且不释放空间,以下哪个语句可以实现(D)
A DELETE TABLE user
B REMOVE TABLE user
C DROP TABLE user
D TRUNCATE TABLE user
在SQL中,能快速删除数据表中所有记录,但保留数据表结构的语句是Truncate。
使用Truncate删除所有行,该语句总是比不带条件的DELETE语句要快,因为DELETE语句要记录对每行的删除操作,而Truncate 语句只记录整个数据页的释放。Truncate语句立即释放由该表的数据和索引占用的所有空间,所有索引的分发页也将释放。
Delete 删除 表中的行
DROP删除整个表,包括表结构和表定义
REMOVE没有这个查询定义 -
某抽卡公司出示出SSR的概率是0.1,用户画符500次,得到45个符,问在5%的显著水平下,能够认为游戏商在谎报概率吗?(不能)
对于统计检验来说,这里设置的是a=0.05, Ho 假设如果计算的概率p>a大于显著水平,即是没有足够的证据去拒绝原假设,即尚不能拒绝H0(原假设为某抽卡公司出示出SSR的概率是0.1), 如果p
from scipy.stats import binom
pi = 0.1; n = 500
k = 45; m = 50
# 求成功次数为i的概率
pk = 0
for i in range(n):
p = binom( n, pi ).pmf( i )
if i <= k:
pk += p
print( 'P(x = {0:d}) = {1:.4f}'.format( i , p ))
# 求成功小于k次的概率
print('-'*20)
p = binom( n, pi ).cdf( k )
print( 'P(x <= {0:d}) = {1:.4f}'.format( k , p ))
print( '比较累加值:', pk)
# 求成功大于k次,小于m次的概率
print('-'*20)
p = binom( n, pi ).cdf( m ) - binom( n, pi ).cdf( k )
print( 'P({0:d} < x <= {1:d}) = {2:.4f}'.format( k , m, p ))
补: 假设检验: 依据一定的假设条件由样本推断总体的一种方法。
假设检验的思想: 进行假设检验时,假设原假设为真;如果有足够的证据反驳原假设,则拒绝原假设,接受备则假设。
如何理解显著这个词呢? 其实就是有足够强的证据的意思。例如:这个结果显著,翻译成人话,就是我们有足够强的证据表明这个结果超过了容错范围,所以我们要reject掉原假设。
深入浅出统计学中的假设检验:https://zhuanlan.zhihu.com/p/28177571
二项分布:https://www.jianshu.com/p/6dac4fcfa629
假设检验详解: https://blog.csdn.net/andy_shenzl/article/details/81453509
- 某服务器请求分配到集群A,B, C, D 进行处理响应的概率分别是10%,20%,30%,和40%, 测试各集群的稳定性分别是90%, 93%,99%,和99.9%,现在该服务器请求处理失败,且已排除稳定性以外的问题,那么最有可能在处理该服务集群的是(B)
令L代表服务器请求处理失败,A,B,C,D分别代表对应的集群处理响应。
则有P(A)=10%,P(B)=20%,P©=30%,P(D)=40%
P(L|A)=10%,P(L|B)=7%,P(L|C)=1%,P(L|D)=0.1%
题目要求P(X|L),知识点:全概率公式、贝叶斯公式;对于4个集群而言,分母P(失败)是恒定的,因此只需比较分子P(失败|集群=i)*P(集群=i)的大小。
X可取A,B,C,D,求其中的最大值。
根据贝叶斯概率公式
P(A|L)P(L)=P(L|A)P(A)=10% * 10%=0.01
P(B|L)P(L)=P(L|B)P(B)=20% *7%=0.014
P(C|L)P(L)=P(L|C)P (C )=0.003
P(D|L)P(L)=P(L|D)P(D)=0.0004
其中,P(L)虽然未知,但不用计算,即可比较大小,得P(B|L)最大 - 关于大数定理和中心极限定理 说法错误的是(B)
A 大数定理和中心极限定理都是用来描述 独立同分布的随机变量的和的渐进表现
B 它们描述的是在不同收敛速率之下的表现,大数定理的前提条件强一点
C 利用大数定理可以用样本均值估计总体分布的均值
D 中心极限定理描述的是某种形式的随机变量之和的分布
大数定理说的是随机现象平均结果的稳定性
中心极限定理 论证随机变量的极限分布是正态分布
大数定理比中心极限定理宽松,中心极限条件强,结论更强
29. 关于MySQL中数据类型的描述,以下错误的是(C)
A VARCHAR 用于描述可变长度的非二进制字符串
B DATETIME 和TIMESTAMP 是相同的数据类型,可以相互替换 √
C 以“hh:mm:ss”格式存储时间值的是DATETIME 数据类型 ×是TIME
D TINYINT属性只适合数字类型的数据
30. 以下哪些机器学习模型没有用到learning rate 学习率 作为超参数(A)
A 随机森林
B Adaboost
C Gradient Boosting
D lightGBM
决策树没有参数可以调节
只要使用了梯度下降法就会有学习率
31. 游戏中的武器攻击值是60, 使用宝石可以增加攻击值,如果是A有40%的概率打出暴击,攻击值增加一倍,是宝石B的话有20%的概率打出暴击,攻击值增加三倍,如果是C的话10% 攻击值增加5倍, 各个事件均为独立事件,但是多个暴击同时发生时,支取最高值, 这个数学期望是多少(139.68)
40% 20% 10% 30%
120 240 360
E(x)= 600.60.8*0.9 + 120 * 0.4 * 0.8 * 0.9 + 240 * 0.2 * 0.9 + 360 * 0.1 = 139.68 - 对于二分类问题中样本不平衡问题(负例较多),下面那个解决方案不适用(C)
A 对训练集的负样本进行欠采样
B 直接基于原始数据集进行训练 在预测的时候改变阈值
C 对训练集的正负比例进行升采样
D 对正例进行升采样
过抽样: 过抽样也叫做上采样(over-sampling).这种方法通过增加分类中少数样本的数量来实现样本均衡。最直接的方法是简单复制少数样本形成多条记录。比如正负比例为1:10,那么我们可以将正例复制9遍来达到正负比例1:1。但是这种方法的缺点就是如果样本特征少而可能导致过拟合的问题;经过改进的过抽样方法通过在少数类中加入随机噪声、干扰数据或通过一定规则产生新的合成样本,例如SMOTE算法。
欠抽样: 欠抽样也叫做下采样(under-sampling),这种方法通过减少分类中多数分类的样本数量来实现样本均衡,最直接的方法就是随机的去掉一些多数类样本来减小多数类的规模,缺点是会丢失多数类样本中的一些重要信息。
总而言之,过抽样和欠抽样更适合于大数据分布不均衡的情况,尤其是第一种(过抽样)应用更加广泛。 - SQL 中 语句正确的执行顺序是
From—where—group by —having –order by –limit - RNN 在特定的神经元给定任意输入,得到的输出是-0.001. 那么RNN中隐藏层使用的激活函数可能是(B)
A ReLu(0,x)
B Tanh (-1,1)
C Sigmoid–(0,1)
D 其他都不是
该激活函数可能是 tanh,因为该函数的取值范围是 (-1,1)。 - 在含有一个或者两个均值的假设检验中要使用(t检验)。
- 贝叶斯分类利用以下哪种概率计算( 后验概率)
- 假设使用逻辑回归进行 n 多类别分类,使用 One-vs-rest 分类法。下列说法正确的是(需要n个模型)
- 这是一样表 table
id title
1 21
2 21
3 21,45,78
4 47,21,23
5 211,45,74
6 34,321
现在用sql语句查出来字段里包含21的所有记录怎么办?
想321 还有 211 这样的记录不能要。
select *
from table
where title=21 or title like '%,21' or title like '%,21,%' or title like '21,%'
- 关于SQL 的优化,以下说法正确的是(AC)
A select 子句 中尽量避免使用 *, 尽量列出需要查询的字段
B 大小表连接是,把大表写入内存,再拼接小表
C KEY键NULL值较多时,把 NULL赋值为特定字符串
D 进行去重时,使用DISTINCT比order by 效率更高
A 实际上,ORACLE在解析的过程中, 会将’*’ 依次转换成所有的列名, 这个工作是通过查询数据字典完成的, 这意味着将耗费更多的时间。
B sql连接大小表在前在后的重要性(小表在前提高执行效率)。
C 答案不确定
D distinct方式就是两两对比,需要遍历整个表。
group by分组类似先建立索引再查索引,所以两者对比,小表destinct快,不用建索引。大表group by快。一般来说小表就算建索引,也不会慢到哪去,但是如果是TB级大表,遍历简直就是灾难。
所以很多ORACLE项目都禁止使用distinct语句,全部要求替换成group by。
- 关于线性回归的描述,以下正确的是(BCE)
A 基本假设包括随机干扰项是均值为0,方差为1的标准正态分布
B 基本假设是包括随机干扰是均值为0的同方差正态分布
C 在违背基本假设是,普通最小二乘法不是是最佳线性无偏估计量
D 在违背基本假设模型不再可以估计
E 可以用DW检验残差是否存在序列相关性
F 多重共线性会使得参数估计值方差减小
A 一元线性回归的基本假设有
1)随机误差项是一个期望值或平均值为0的随机变量;
2)对于解释变量的所有观测值,随机误差项有相同的方差;
3)随机误差项彼此不相关;
4)解释变量是确定性变量,不是随机变量,与随机误差项彼此之间相互独立;
5)解释变量之间不存在精确的(完全的)线性关系,即解释变量的样本观测值矩阵是满秩矩阵;
6)随机误差项服从正态分布
D 违背基本假设的计量经济学模型还是可以估计的,只是不能使用普通最小二乘法进行估计。
E 杜宾-瓦特森(DW)检验,计量经济,统计分析中常用的一种检验序列一阶 自相关 最常用的方法。
补:
当存在异方差时,普通最小二乘法估计存在以下问题: 参数估计值虽然是无偏的,但不是最小方差线性无偏估计。
多重共线性的影响:
(1)完全共线性下参数估计量不存在
(2)近似共线性下OLS估计量非有效
多重共线性使参数估计值的方差增大,1/(1-r2)为方差膨胀因子(Variance Inflation Factor, VIF)
(3)参数估计量经济含义不合理
(4)变量的显著性检验失去意义,可能将重要的解释变量排除在模型之外
(5)模型的预测功能失效。变大的方差容易使区间预测的“区间”变大,使预测失去意义。
- 关于皮尔森系数,下列描述正确的是(ACD)
A 皮尔森系数是描述变量线性相关的程度
B 皮尔森系数越大,变量相关性越小
C 相关系数只适用于线性相关关系
D 皮尔森系数为0,说明两变量之间不存在线性相关关系 - 下列哪些数据分析方法可以对高维数据进行降维(ABCD)
A LASSO
B 主成分分析法
C 聚类分析
D 小波分析 - 下列算法中,可以使用神经网络构造的是(CE)
A KNN
B 线性回归
C 对数几率回归
D 朴素贝叶斯
E SVM - 以下哪些语句属于数据库定义语言DDL(BD)
A DROP
B CREATE
C ALTER
D UPDATA - 关于SQL语句的描述,以下说法正确的是(BCD)
A DELETE FROM TABLE: 删除表
B DESC TABLE:查看数据库表结构
C UPDATA TABLE:更新数据库表
D INSERT INTO TABLE:向数据库表插入新列
A 可以在不删除表的情况下删除所有的行。这意味着表的结构、属性和索引都是完整的:DELETE FROM table_name or DELETE * FROM table_name - 以下哪些条件能够判断随机变量是相互独立的(AD)
A 对任何实数x, y, 均有P{X<=x, Y<=y} = P{X<=x}{Y<=y}。
B E(XY) = E(X)E(Y)
C 对任何实数x, y, 联合密度函数f(x, y) = fx(x)fy(y)
D 对任何实数x, y, 联合分布函数F(x, y) = Fx(x)Fy(y) - 下面哪种说法是正确的(AD)
A R方是反映因变量的全部变异能通过回归关系被自变量解释的比例
B 如果R方变大,说明这个变量是显著的
C 如果R方变小,说明这个变量是不显著的
D 单独观察R方的变化,无法判断这个变量是否显著 - 某二叉查找树的每个节点存放一个整数,中序遍历该树得到的序列为3,4,5,则该树的画法有多少种情况?(5)
分别以3,4,5为根节点,按中序遍历的规则逐个尝试。 - 字符串有5个字符q,w,e,r,t,出现的频率分别为1,2,3,4,5,如果采用Huffman编码对字符串编码,则每个字符编码的平均长度是(2.4)
Huffman编码后分别为:q:000,w:001,e:01,r:10,t:11,平均编码长度为(3+3+2+2+2)/5=2.4。
霍夫曼编码的演算过程:
(一)进行霍夫曼编码前,我们先创建一个霍夫曼树。
1)将每个英文字母依照出现频率由小排到大,最小在左,如Fig.1。
2)每个字母都代表一个终端节点(叶节点),比较F.O.R.G.E.T六个字母中每个字母的出现频率,将最小的两个字母频率相加合成一个新的节点。如图所示,发现F与O的频率最小,故相加2+3=5。
3)比较5.R.G.E.T,发现R与G的频率最小,故相加4+4=8。
4)比较5.8.E.T,发现5与E的频率最小,故相加5+5=10。
5)比较8.10.T,发现8与T的频率最小,故相加8+7=15。
6)最后剩10.15,没有可以比较的对象,相加10+15=25。
最后产生的树状图就是霍夫曼树。
(二)进行编码
1)给霍夫曼树的所有左链接’0’与右链接’1’。
2)从树根至树叶依序记录所有字母的编码。
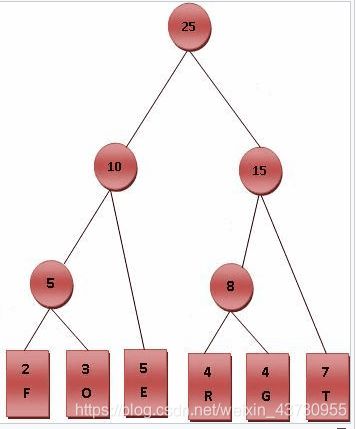
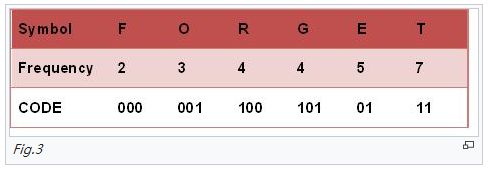
- 下面关于排序的空间复杂度说法不正确的有()(N为被排序数据的长度)
插入排序的空间复杂度为O(N)。
正确答案:堆排序的空间复杂度为O(1);冒泡排序的空间复杂度为O(1);归并排序的空间复杂度为O(N);递归实现的快速排序的空间复杂度为O(logn)。
插入排序的空间复杂度为O(1) - 一个简单无向图有10个顶点,11条边,如果用邻接矩阵来存储它,那么矩阵里面会有多少个0?
78 = 10^2-2*11
图的邻接矩阵存储:https://blog.csdn.net/vicdd/article/details/77983089 - 以下hive sql语法正确的是
答:select * from a inner join b on a.id=b.id
select * from a inner join b on a.id &l t; &g t;b.id,错在lt,gt符号
select * from a where a.id in (select id from b),in后不可以接子查询
select sum(a.amt) as total from a where a.total>20,错在where包含聚合函数
(一)Hive-sql与SQL的区别
总体一致:
Hive-sql与SQL基本上一样,因为当初的设计目的,就是让会SQL不会编程MapReduce的也能使用Hadoop进行处理数据。
因此,大胆使用SQL的,如果遇到不对的,再查。
(二)MyBatis SQL xml处理小于号与大于号
当我们需要通过xml格式处理sql语句时,经常会用到< ,<=,>,>=等符号,但是很容易引起xml格式的错误,这样会导致后台将xml字符串转换为xml文档时报错,从而导致程序错误。这样的问题在iBatiS中或者自定义的xml处理sql的程序中经常需要我们来处理。其实很简单,我们只需作如下替换即可避免上述的错误:

(三)SQL where 和having使用注意事项
1)在带有groupby子句的查询语句中,在select列表中指定的列要么是groupby子句中指定的列,要么包含聚组函数 。
2)当在gropuby子句中使用having子句时,查询结果中只返回满足having条件的组。在一个sql语句中可以有where子句和having子句。having与where子句类似,均用于设置限定条件 。where子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,条件中不能包含聚组函数,使用where条件显示特定的行。 having子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having条件显示特定的组,也可以使用多个分组标准进行分组。
3)having放在group by 的后面。
4)group by 后面只能放非聚合函数的列。 - Hbase是一个面向列分布式数据库,和hive不同的是,hbase能够在它的数据库上实时运行,而不是运行mapreduce任务。
- 大表1000万条数据, 小表1000条数据, 为提高查询效率两行表关联时通常做法是
大表在前 - 有一个地区有2个市,一个来自A市的概率是20%,B市的是80%,A市得病的概率是2%,B市得病的概率是3%,现在有一个病人,问是A市的概率是?
贝叶斯公式计算所得结果 0.20.02/(0.20.02 + 0.8*0.03)= 1/7 - x+y+z+m=10,其中x,y,z,m都是正整数,那么x,y,z,m有多少种不同的取值组合?
此问题等价于将10个球排一排后,中间插入三块隔板将它们分成四堆球,使每一堆至少一个球.隔板不能相邻,也不能放在两端,只能放在中间的9个空内.因此共有C(9,3)=84种。 - 有无限的水源,一个5L无刻度桶和一个7L无刻度桶,则只利用这两个无刻度桶,将不能获得(F)L水
A. 2
B. 3
C. 6
D. 8
E. 11
F. 以上均能获得
其实只要满足5a+7b=t即可。a, b可取任意整数,t就是能获得的容量数。 - 有一堆石子,共80颗,甲,乙轮流从该堆中取石子,每次可以取2,4或者6颗,取得最后的石子的玩家为赢家,甲乙都足够聪明都想赢,若甲先取,则____。
乙必胜。乙能保证在每次甲取完石子后选择合适的数量,使得剩余的石子数量为8的倍数,那么甲在下一次取石子的时候不能一次取完,故乙会获胜。 - A, B 为任意两个事件且 A ⊂ B,P(B) > 0,则下列选项必然成立的是( P(A) ≤ P(A| B))
P(A| B)限定了b为全集,全集缩小,故P(A) ≤ P(A| B) - 将一枚硬币独立地掷两次,引进事件: A1 = {掷第一次出现正面}, A2 = {掷第二次出现正面},A3 = {正、反面各出现一次}, A4 = {正面出现两次},则事件( A1, A2, A3两两独立)
P(A1A2)=P(A1)P(A2),
P(A1A3)=P(A1)P(A3),
P(A2A3)=P(A2)P(A3),
P(A1A2A3)≠P(A1)P(A2)P(A3),
P(A2A4)≠P(A2)P(A4).
故:A1,A2,A3两两独立但不相互独立;A2,A3,A4不两两独立更不相互独立。 - 设随机变量 X 与 Y 均服从正态分布,X ~ N(µ, 16), Y ~ (µ, 25), 记p1 = P{X ≤ µ - 4}, p2 = P{Y ≥ µ + 5}, 则( p1 = p2)
对任何实数µ,都有 p1 = p2
在“正态分布”中,σ表征概率密度曲线的“宽度”,或展开的程度.不管μ和σ的值如何,区域[μ-σ, μ+σ]都覆盖68.26%的概率。 - 设随机变量X与Y相互独立,且都服从区间(0,1)上的均匀分布,则P{X^2 + Y^2 ≤ 1} =( )
(X,Y)的联合密度为:f(x,y)=fX(x)fY(y)=1, 0<x<1, 0<y <10
设:D={(x,y)|x2+y2≤1,x>0,y>0},则:
P{X2+Y2≤1}=∬f(x,y)dxdy=∬Ddxdy
均匀分布的概率密度函数:
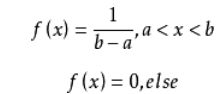
- 随机变量X ~ N(0, 1), Y ~ N(1, 4),且相关系数ρ{XY} = 1,则(D )
A. P{Y=-2X-1}=1
B. P{Y=2X-1}=1
C. P{Y=-2X+1}=1
D. P{Y=2X+1}=1
用排除法.
设Y=aX+b,由ρXY=1,知:X,Y正相关,得:a>0,排除(A)和(C).
由X:N(0,1),Y:N(1,4),得:EX=0,EY=1,E(aX+b)=aEX+b,
即:1=ax0+b,b=1,
从而排除(B)
故选:D。 - 设随机变量X和Y都服从正态分布,且它们不相关,则(X与Y未必独立 )
A. X与Y一定独立
B. (X, Y)服从二维正态分布
C. X与Y未必独立
D. X + Y服从一维正态分布
A.只有当(X,Y) 服从二维正态分布时,X与Y不相关⇔X与Y独立,本题仅仅已知X和Y服从正态分布,因此,由它们不相关推不出X与Y一定独立,故A错误;
B.若X和Y都服从正态分布且相互独立,则(X,Y)服从二维正态分布,但题设并不知道X,Y是否独立,故B错误;
C.由A、B分析可知X与Y未必独立,故C正确;
D.需要求X与Y相互独立时,才能推出X+Y服从一维正态分布,故D错误. - 若总体X~N(µ,δ^2), 其中δ^2已知,当样本容量保持不变时,如果置信度减小,则的置信区间(长度变小 )。
95%置信区间,意味着如果你用同样的步骤,去选样本,计算置信区间,那么100次这样的独立过程,有95%的概率你计算出来的区间会包含真实参数值,即大概会有95个置信区间会包含真值。
而对于某一次计算得到的某一个置信区间,其包含真值的概率,我们无法讨论。 - 某电灯泡生产商声称,它们生产的电灯泡的平均使用时间为85小时。质检部门抽取20个电灯泡的随机样本,在的显著性水平下,检验结果是未能拒绝原假设,这意味着(没有证据证明该企业生产的电灯泡的平均使用时间不是85小时)
- 利用递归对数组进行全排列。
COUNT=0
def perm(n,begin,end):
global COUNT
if begin>=end:
print (n)
COUNT +=1
else:
i=begin
for num in range(begin,end):
n[num],n[i]=n[i],n[num]
perm(n,begin+1,end)
n[num],n[i]=n[i],n[num]
n=[1,2,3,4]
perm(n,0,len(n))
print (COUNT)
[1, 2, 3, 4]
[1, 2, 4, 3]
[1, 3, 2, 4]
[1, 3, 4, 2]
[1, 4, 3, 2]
[1, 4, 2, 3]
[2, 1, 3, 4]
[2, 1, 4, 3]
[2, 3, 1, 4]
[2, 3, 4, 1]
[2, 4, 3, 1]
[2, 4, 1, 3]
[3, 2, 1, 4]
[3, 2, 4, 1]
[3, 1, 2, 4]
[3, 1, 4, 2]
[3, 4, 1, 2]
[3, 4, 2, 1]
[4, 2, 3, 1]
[4, 2, 1, 3]
[4, 3, 2, 1]
[4, 3, 1, 2]
[4, 1, 3, 2]
[4, 1, 2, 3]
24
- 大文件的排序问题
在我们日常开发中有时候会遇到这样一个问题,有一个文件大小为10GB,现在要为里面的数据进行排序,而计算机的内存只有1GB,如何对这10GB的数据进行排序呢?
由于内存空间只有1GB我们无法一次性读取所有的文件来进行排序,因此需要借助外部排序来解决。外部排序的思路很简单,它采用了一种" 排序-归并 " 的策略。大概步骤如下:
1)把10GB文件大小分为10份,每一份1GB。
2)依次把每份文件读取到内存中进行排序,可采用快排、归并、堆排等,然后把排序后的数据写入到磁盘中,这样每一份的文件数据都是有序的。
3)对10个有序的文件,进行两两归并。既把每两个文件中的部分数据读取到内存中进行比较,然后把比较后的结果输出到临时文件中,最终得到的临时文件就是两个小文件整合在一起的有序文件 。然后把该临时文件和其他临时文件再进行两两归并,依次类推,最终输出的文件就是一个有序的文件。
注:而对于同一个文件来说,对其进行外部排序时访问外存的次数同归并的次数成正比,即归并操作的次数越多,访问外存的次数就越多。为了提高外部排序的效率,降低归并次数,所以出现了4路排序、5路排序、10路排序等K路排序。 - 若有33个长度不等的初始归并段,做7路平衡归并排序,为组织最佳归并树,应增加长度为0的初始归并段的个数是____4____。
1)在一般情况下,对于 k–路平衡归并来说,若 (m-1)MOD(k-1)=0,则不需要增加虚段;否则需附加 k-(m-1)MOD(k-1)-1 个虚段。
2)树的带权路径长度(Weighted Path Length of Tree):定义为树中所有叶结点的带权路径长度之和。结点的带权路径长度:结点到树根之间的路径长度与该结点上权的乘积。哈夫曼树是一种带权路径长度最短的二叉树,也称为最优二叉树。
https://blog.csdn.net/sinat_38972110/article/details/82136196 - 将一个整数序列整理为升序,两趟处理后序列变为10,12,21,9,7,3,4,25,则采用的排序算法可能是_插入排序__。
插入排序:第一趟前两个有序,第二趟前三个有序。
快速排序:每经过一趟快排,轴点元素都必然就位,也就是说,一趟下来至少有1个元素在其最终位置,2趟就有两个位置元素就位。10,12,21,9,7,3,4,25 正确的结果是,3,4,7,9,10,12,21,25.。这里只有25一个元素就位了(10,12,21虽然有序,但他们应该在3,4,7,9后面才行)。 - 在数理统计中, 一般通过增加抽样次数取平均来使得预估误差减小, 在机器学习中也有类似的模型处理, 如随机森林, 通过引入随机样本并且增加决策树的数据,对于随机森林主要降低预估的哪个方面值
预估方差 - 以下不属于非监督学习的为(D)
A. 关联规则
B. Kmeans
C. Word2vec
D. Knn
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。K近邻是基本的分类和回归方法。分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。k近邻实际是利用训练数据集对特征向量空间进行划分,并作为其“分类”的模型。k值的选择,距离的度量,分类决策规则是k近邻法的三个基本要素。 - 将当前命令sh test.sh任务在后台执行,下列最优雅的的做法是
nohup sh test.sh & - 截取logfile文件中含有suc的行,并且只输出最后一列,下列操作正确的是:
grep ‘suc’ logfile | awk ‘{print $NF}’ - 哪个不是DDL(数据库定义语言)语句?
A. ALTER
B. CREATE
C. RENAME
D. GRANT - 若要在员工信息表EMP中增加一列WANGYI_NO(网易id),可用( )。
ALTER TABLE EMP ADD(WANGYI_NO CHAR(10)) - 在机器学习任务中经常假设矩阵为n×n的对称矩阵A, 则以下说法正确的是(对应于A的不同特征值的特征向量之间正交)
对称矩阵不一定满秩;不同特征值之间的特征向量一定正交,而同一特征值的特征向量需要借助公式得正交向量 - python中list的元素可以是tuple
- 一个快递公司对同一年龄段的员工,进行汽车,三轮车,二轮车平均送件量的比较,结果给出sig.=0.034,说明
按照0.05显著性水平,拒绝H0,说明三类交通工具送件量有显著差异。
p值表示接受原假设最小的显著性水平,p值越小,拒绝原假设的理由越充分。 - 已知样本数据,求对应置信度下的置信区间(例题):https://blog.csdn.net/bitcarmanlee/article/details/50911533
- 最小二乘估计是线性无偏估计中方差最小的
- 设{xn}服从独立同分布, E[xn] = 0, Var[xn]=1, 则当n趋向于无穷大时,下式值为:
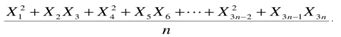
A. 无穷大
B. 0
C. 1
D. 2
E(X2)= E2(X)+Var(X)=1;
E(XiXi+1)=E(Xi)E(Xi+1); 由随机变量相互独立得出
上下取期望有
原式=(1+0+1+0+…+1+0)/n=1
两个相互独立随机变量乘积的期望等于这两个随机变量期望的乘积。 - 关联规则、支持度(support)、置信度(confidence)
例子:
总共有10000个消费者购买了商品,
其中购买尿布的有1000人,
购买啤酒的有2000人,
购买面包的有500人,
同时购买尿布和啤酒的有800人,
同时购买尿布的面包的有100人。
1)关联规则
关联规则:用于表示数据内隐含的关联性,例如:购买尿布的人往往会购买啤酒。
2)支持度(support)
支持度:{X, Y}同时出现的概率,例如:{尿布,啤酒}同时出现的概率

{尿布,啤酒}的支持度 = 800 / 10000 = 0.08
{尿布,面包}的支持度 = 100 / 10000 = 0.01
注意:{尿布,啤酒}的支持度等于{啤酒,尿布}的支持度,支持度没有先后顺序之分。
3)置信度(confidence)
置信度:购买X的人,同时购买Y的概率,例如:购买尿布的人,同时购买啤酒的概率,而这个概率就是购买尿布时购买啤酒的置信度。

( 尿布 -> 啤酒 ) 的置信度 = 800 / 1000 = 0.8
( 啤酒 -> 尿布 ) 的置信度 = 800 / 2000 = 0.4 - 小易有一些彩色的砖块。每种颜色由一个大写字母表示。各个颜色砖块看起来都完全一样。现在有一个给定的字符串s,s中每个字符代表小易的某个砖块的颜色。小易想把他所有的砖块排成一行。如果最多存在一对不同颜色的相邻砖块,那么这行砖块就很漂亮的。请你帮助小易计算有多少种方式将他所有砖块排成漂亮的一行。(如果两种方式所对应的砖块颜色序列是相同的,那么认为这两种方式是一样的。)
例如: s = “ABAB”,那么小易有六种排列的结果:
“AABB”,“ABAB”,“ABBA”,“BAAB”,“BABA”,“BBAA”
其中只有"AABB"和"BBAA"满足最多只有一对不同颜色的相邻砖块。
x = input()
if len(set(x)) == 2:
print(2)
elif len(set(x)) == 1:
print(1)
else:
print(0)
分析一下:如果只有一种大写字母,肯定只有一种情况;
如果有两种大写字母,全排列出来有6中,符合题意的肯定只有两种;
如果有三种字母(或者>3种),不同字母紧靠且符合题意的肯定没有;
所以,显而易见,三种情况考虑就OK了
- 小易为了向他的父母表现他已经长大独立了,他决定搬出去自己居住一段时间。一个人生活增加了许多花费: 小易每天必须吃一个水果并且需要每天支付x元的房屋租金。当前小易手中已经有f个水果和d元钱,小易也能去商店购买一些水果,商店每个水果售卖p元。小易为了表现他独立生活的能力,希望能独立生活的时间越长越好,小易希望你来帮他计算一下他最多能独立生活多少天。
输入描述:
输入包括一行,四个整数x, f, d, p(1 ≤ x,f,d,p ≤ 2 * 10^9),以空格分割
输出描述:
输出一个整数, 表示小易最多能独立生活多少天。
s = input()
s = s.split(' ')
s = [int(x) for x in s]
if s[1] < s[2]/s[0]:
print(s[1] + int((s[2]-s[0]*s[1])/(s[0]+s[3])))
else:
print(int(s[2]/s[0]))
- 一个总体估计参数估计下的不同情形及使用的分布

不同情形下总体均值的区间估计:
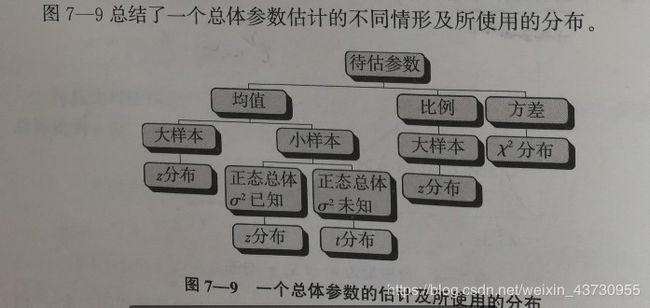
一个总体分布的参数估计(区间,比例,方差的估计)
https://my.oschina.net/u/1785519/blog/1060633
https://blog.csdn.net/liangzuojiayi/article/details/78043658 - 数学期望:反映随机变量平均取值的大小。
离散型:
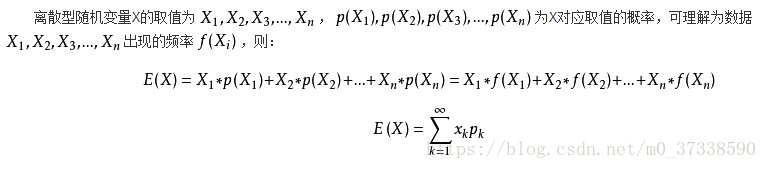
连续型:

性质:

- 二叉排序树:
满足的性质:
1)若他的左子树不空,则左子树上所有的节点的值均小于根节点的值
2)若他的右子树不空,则右子树上所有的节点的值均大于根节点的值
3)他的左子树和右子树分别是一颗二叉排序树。
4)对于二叉排序树的中序遍历得到一个递增序列
二叉排序树的查找:
1)若给定的值等于根节点的值,则查找成功
2)若给定的值小于根节点值,则继续在左子树上查找
3)若给定的值大于根节点的值,则继续在右子树上进行查找 - 对总体进行区间估计时,需要考虑( ACE)
A总体是否服从正态分布
B总体是否服从均匀分布
C总体方差是否已知
D总体均值是否已知
E用于估计的样本是大样本还是小样本 - 极大似然估计和最小二乘法的区别
最小二乘法的核心是权衡,因为要在所有的线之间做选择,选择距离所有的点之和距离最短的(最小化误差平方和);极大似然的核心是自恋,要相信自己是天选之子,自己看到的就是冥冥之中最接近真相的。(利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。)
例如:一个麻袋里有白球与黑球,但是我不知道它们之间的比例,那我就有放回的抽取10次,结果我发现我抽到了8次黑球2次白球,我要求最有可能的黑白球之间的比例时,就采取最大似然估计法:
我假设我抽到黑球的概率为p,那得出8次黑球2次白球这个结果的概率为:P(黑=8)=p8*(1-p)2,现在我想要得出p是多少啊,很简单,使得P(黑=8)最大的p就是我要求的结果,接下来求导的的过程就是求极值的过程啦。可能你会有疑问,为什么要ln一下呢,这是因为ln把乘法变成加法了,且不会改变极值的位置(单调性保持一致嘛)这样求导会方便很多。 - 利用辗转相除法求最大公约数
1)比较两数,并使m>n
2)将m作被除数,n做除数,相除后余数为r
3)循环判断r,若r==0,则n为最大公约数,结束循环。若r !=0 ,执行m=n,n=r;将m作被除数,n做除数,相除后余数为r
num1 = int(input("请输入第一个数字:"))
num2 = int(input("请输入第一个数字:"))
m = max(num1, num2)
n = min(num1, num2)
r = m % n
while r != 0:
m = n
n = r
r = m % n
print(num1, "和", num2, "的最大公约数为", n)
阿里
- 观测宇宙中单位体积内星球的个数,属于什么分布:B
A 学生分布:小样本量下对正态分布的均值进行估计
B 泊松分布:描述单位时间内随机事件发生的次数
C 正态分布:多组(多次独立重复实验下的随机变量的均值)
D 二项分布:多次抛硬币的独立重复试验
把体积看成时间,那么本题符合B泊松分布。
泊松分布的概率函数为:
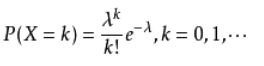
泊松分布的参数λ是单位时间(或单位面积)内随机事件的平均发生次数。 泊松分布适合于描述单位时间内随机事件发生的次数。泊松分布的期望和方差均为 λ。
学生t-分布(Student’s t-distribution)可简称为t分布,用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知或未知(例如在样本数量足够多时),则应该用正态分布来估计呈正态分布的总体的总体均值。
https://zh.wikipedia.org/wiki/学生t-分布
二项分布(英语:Binomial distribution)是n个独立的是/非试验中成功的次数的离散概率分布,其中每次试验的成功概率为p。这样的单次成功/失败试验又称为伯努利试验。实际上,当n = 1时,二项分布就是伯努利分布。

- 一些关于数据挖掘说法是正确的(D)
A 数据挖掘是万能的(错)
B 如果你建立了一个database,那就意味着你已经有足够的数据可以做数据挖掘了(错)
C 数据挖掘=数据+算法,数据挖掘人员大部分的时间用来处理复杂的挖掘算法(错,业务上的时间大部分在调研和沟通需求,技术上大部分时间在清洗数据)
D ABC均有错 - 已知随机变量X,Y分别服从泊松分布P(S),卡方分布X2(t),E(X)=4,D(Y)=9,则参数s,t分别:
A 2,9
B 4,9
C 4,4.5(√)
D 2,4.5
k个独立的标准正态分布变量的平方和服从自由度为k的卡方分布。卡方变量之期望值=自由度 卡方变量之方差=两倍自由度
https://zh.wikipedia.org/wiki/卡方分佈 - 下面算法中哪一种不属于广义线性回归算法 (D)
A 生存模型算法(如Cox比例风险回归,属于)
B beta回归算法(属于)
C logit回归算法(属于)
D 判别分析算法(如线性判别分析LDA) - 有一列1000万淘宝买家的淘宝运费险保费数据,要计算该列数据的P1-P100分位数,可使用哪个SAS语句?(C)
A proc sort
B proc rank
C proc univariate(√)
D proc freq - X服从区间(2,6)上的均匀分布,求对X进行3次独立观测中,至少有2次的观测值大于3的概率
A 0.84375(√)
B 0.75275
C 0.65275
D 0.80370
一个均匀分布在区间[a,b]上的连续型随机变量X可给出如下函数:
概率密度函数:
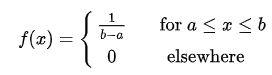
- 下面对于“预测变量间可能存在较严重的多重共线性”的论述中错误的是?
A 回归系数的符号与专家经验知识不符(对)
B 方差膨胀因子(VIF)<5(错,大于10认为有严重多重共线性)
C 其中两个预测变量的相关系数>=0.85(对)
D 变量重要性与专家经验严重违背(对)
A,D为导致的结果,B,C为判断严重多重共线性的依据。
随机森林算法原理:
只要了解决策树的算法,那么随机森林是相当容易理解的。随机森林的算法可以用如下几个步骤概括:
1)用有放回抽样的方法(bootstrap)从样本集中选取n个样本作为一个训练集
2)用抽样得到的样本集生成一棵决策树。在生成的每一个结点:
a. 随机不重复地选择d个特征
b. 利用这d个特征分别对样本集进行划分,找到最佳的划分特征(可用基尼系数、增益率或者信息增益判别)
3)重复步骤1到步骤2共k次,k即为随机森林中决策树的个数。
4)用训练得到的随机森林对测试样本进行预测,并用票选法决定预测的结果。
特征重要性评估
现实情况下,一个数据集中往往有成百上千个特征,如何在其中选择比结果影响最大的那几个特征,以此来缩减建立模型时的特征数。这样的方法其实很多,比如主成分分析,lasso,随机森林等等。
用随机森林进行特征重要性评估的思想其实很简单,说白了就是看看每个特征在随机森林中的每颗树上做了多大的贡献,然后取个平均值,最后比一比特征之间的贡献大小。 那么这个贡献是怎么一个说法呢?通常可以用基尼指数(Gini index)或者袋外数据(OOB)错误率作为评价指标来衡量。 - 由于淘宝买家消费数据是亿级别,假设为了快速计算买家每月的平均消费额,采用抽样1W个买家来计算
A 采用分层抽样方法把全量淘宝买家按照星级,每层抽取相同的数量,计算平均值(要求的是总的分布,分层抽样每层抽一样的把分布改变了)
B 采用系统抽样方法,把全量买家随机排序,每隔一定数量抽一个,计算平均值(√)
C 采用无放回随机方法,从全量买家中随机挑选一个买家,不放回,如此循环(√)
D 采用有放回随机方法,从全量买家中随机挑选一个买家,然后再放回,如此循环(理论上会改变样本分布,虽然很小) - 请找出数列4,9,23,60,157的下一项()
A 411(√)
B 314
C 425
D ABC均错
603-23=157,1573-60=411 - 以下哪个语法不是R的基础语言
A proc glot(这个是sas)
B select *from table(这个是sql)
C kc<-kmeans(data,3)(是R)
D print ”hello world”(这个是python2.7)
E sd<-summary(data)(是R)
F import(python有,R不知道有没有) - 分析师在工作中的良好习惯是
A 将工作空间的密码共享给别人
B 将数据下载到私人电脑进行分析处理
C 在处理资源高峰期提交大任务运算
D 不定期地将分析报告分享给团队(√)
E 定期清理存储空间
F 固化日常需要分析的数据表方便计算(√) - 以下算法对缺失值敏感的模型包括:
A Logistic Regression (√)
B 随机森林
C 朴素贝叶斯
D C4.5 - 投掷均匀正六面体骰子的熵是:
A 1bit
B 2.6bit(√)
C 3.2bit
D 3.6bit
H = -(6 * (1/6 * log(1/6) ) = 2.6
香农熵的计算公式
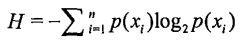
设用计算器求log以2为底,对数为5的函数,操作方法:log5÷log2(计算器指令)。同理,求log2为底,对数为x,计算器指令:logx÷log2
京东
- 三种遍历互求:https://www.cnblogs.com/weiyi-mgh/p/6616008.html
a. 由前序遍历和中序遍历求后序遍历:前序遍历第一个即是根节点,根据确定的根节点到中序遍历中确定左子树和右子树分别包含的节点,然后再通过前序遍历确定左子树中的根节点,以此类推完善整棵树。
b. 由后序遍历和中序遍历求后序遍历:后序遍历最后一个一个即是根节点,根据确定的根节点到中序遍历中确定左子树和右子树分别包含的节点,然后再通过后序遍历确定左子树中的根节点,以此类推完善整棵树。
c. 有前序遍历和后序遍历不能完全确定一棵树,但是在一定情况下可以推出不同的可能树。如果前序遍历的第二个数和后序遍历的倒数第二个数不相等,则前序遍历的第二个数为整棵树的根节点的左子树的根节点,后序遍历的倒数第二个数为整棵树的根节点的右子树的根节点。 - 在软件开发过程中,我们可以采用不同的过程模型,下列有关增量模型描述正确的(B)
A. 已使用一种线性开发模型,具有不可回溯性
B. 把待开发的软件系统模块化,将每个模块作为一个增量组件,从而分批次地分析、设计、编码和测试这些增量组件
C. 适用于已有产品或产品原型(样品),只需客户化的工程项目
D. 软件开发过程每迭代一次,软件开发又前进一个层次
增量模型也称为渐增模型,是把待开发的软件系统「模块化」,将每个模块作为一个增量组件,从而分批次地分析、设计、编码和测试这些增量组件。
增量模型
优点:
(1)将待开发的软件系统模块化,可以「分批次地提交软件产品」,使用户可以及时了解软件项目的进展。
(2)以组件为单位进行开发「降低了软件开发的风险」。一个开发周期内的错误不会影响到整个软件系统。
(3)「开发顺序灵活」。开发人员可以对组件的实现顺序进行优先级排序,先完成需求稳定的核心组件。当组件的优先级发生变化时,还能及时地对实现顺序进行调整。
缺点
(1)要求待开发的软件系统可以被模块化。如果待开发的软件系统很难被模块化,那么将会给增量开发带来很多麻烦。 - 关于TCP协议的描述,以下错误的是?B
A. 面向连接
B. 可提供多播服务
C. 可靠交付
D. 报文头部长,传输开销大
TCP(Transmission Control Protocol
传输控制协议)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。 - 以下命令用于设置环境变量的是:
A. export
B. cat
C. echo
D. env - 置信区间为95%:样本数目不变的情况下,做一百次试验,有95个置信区间包含了总体真值。
数据分析概率题
-
杀人游戏,6个人互相投票,有一个人被其他5个人一起投死的概率是多少()?假设每个人都不会投自己,投其他每个人是等概率的。
分母:每个人可以投其他5个人,共5^6种可能;分子:C(1,6)六种可能,六个人选一个死,所以p=6/3125 -
20个阿里巴巴B2B技术部的员工被安排为4排,每排5个人,我们任意选其中4人送给他们一人一本《effective c++》,那么我们选出的4人都在不同排的概率为():
A.5^4*5!15!/20!
B.4^55!15!/20!
C.5^44!16!/20!
D.4^54!*16!/20!
所有选择的方法数是P2 = C(20,4) = 20!/4!/16!
选的在不同排的有P1 = 5^4种 因为每排有5个人嘛
所以概率 P = P1 / P2 -
有8只球队,采用抽签的方式随机配对,组成4场比赛。假设其中有4只强队,那么出现强强对话 (任意两只强队相遇)的概率是____。(组合问题)
给8只球队编号(1-8),第一个球队选择对手有7种可能,第二个球队选择对手有5种,第三个球队选择有3种,剩余两个球队为一组对手,共7 * 5 * 3
强强不做对手,第一个强队选择弱队有4种可能,第二个强队选择弱队有3种,依次类推。有4 * 3 * 2 * 1种,故有1-4 * 3 * 2 * 1/(7 * 5 * 3)=27/35。 -
两个人轮流抛硬币,规定第一个抛出正面的人可以吃到苹果,请问先抛的人能吃到苹果的概率多大?
a. 第一种方法(列出所有可能性):p=1/2+ 1/2^3 + 1/2^5+…=2/3。
b. 第二种方法(甲先抛吃到苹果的情况分两种,甲第一次抛出正面,甲第一次抛出反面后甲先抛吃到苹果):先抛为p,为反后继续抛,吃到的概率还是p,所以其实p=1/2(正)+1/2(反)*p,解得p=2/3。 -
两种描述分别对应哪种分类算法的评价标准?
描述有多少比例的小偷被警察抓了?警察抓小偷,描述警察抓的人中有多少是小偷?答案:Recall和Precision
精确率:被推荐到正例的,有多少是真正正例;
召回率:正例中,有多少真的被推荐到正例的,与真阳性率一样。 -
有一个箱子,N把钥匙,只有一把钥匙能打开箱子,现在拿钥匙去看箱子。问恰好第k次打开箱子的概率?

-
某国家非常重男轻女,若一户人家生了一个女孩,便再要一个,直到生下男孩为止,假设生男生女概率相等,请问平均每户人家有________个女孩。
首次成功的概率为(1-p)k p,也就是首次出现男孩的概率,那么发生的次数也就是孩子的个数服从几何分布,则期望为2,所以女孩是1个。几何分布的数学期望为1/p。 -
中关村电子城某卖手机的店铺给客人报价,如果按照底价500元(成本价)报出,那么客人就一定会选择在该店铺购买;价格每增加1元,客人流失的可能性增加1%。那么该店铺给客人报出的最优价格是?
若按原价则n名客人都选择在该店购买,且每增加一元,客人流失1%。所以可以列出总利润为p*(1-p%)n,其中p为增加的价格。由于n不变,所以当p(1-p%)最大时,总利润最大,也就是-(p/10-5)2 =0时,此时p=50。那么最优价格就是500+50=550. -
硬币游戏:连续扔硬币,直到 某一人获胜,A获胜条件是先正后反,B获胜是出现连续两次反面,问AB游戏时A获胜概率是?
考虑先抛两次,共4种情况:正正,正反,反正,反反;
正反 A胜,反反 B胜;
正正 情况下,接着抛,如果是正,游戏继续;如果是反,A胜。所以这种情况下最终也是A胜。
反正 情况下也是类似的,最终也是A胜。
所以A得胜率是3/4. -
小a和小b一起玩一个游戏,两个人一起抛掷一枚硬币,正面为H,反面为T。两个人把抛到的结果写成一个序列。如果出现HHT则小a获胜,游戏结束。如果HTT出现则小b获胜。小a想问一下他获胜的概率是多少?
https://www.nowcoder.com/questionTerminal/86b03d05c5bd429a8ba35dd5df3fbda2?source=relative -
假定抛出的硬币落地之后正反两面出现的概率分别为1/2,那么抛10次和100次硬币(分别称为T10和T100)相比,以下说法正确的是 aT100出现一半正面比T10出现一半正面的概率更大;bT100前3次都是正面的概率比T10前3次都是正面的可能性大;cT100正面次数的方差小于T10出现正面次数的方差;dT100出现正面的比例比T10出现正面的比例在(0.45,0.55)区间中的可能性更大?
A: T00出现一半正面的概率:C10050/(2100) T0出现一半正面的概率:C105/(210) 前面小与后面
B:T100 与T10 前三次都为正面概率一样均为 1/8
C:二项分布的方差 np(1-p) T100大
https://www.nowcoder.com/questionTerminal/f676794d1eb54be8b78fd48c27629261
- 有4副相同的牌,每副牌有4张不同的牌.先从这16张牌中,随机选4张出来.然后,在这4张牌中随机选择一张牌,然后把抽出的一张放回3张中,再随机选择一张牌.与上次选出的牌一样的概率是()
首先看最后抽的那次,与上次一样有两种可能,一:就是上次抽的那张,二:不是上次抽的那张但是花色和上次一样。所以就是上次的那张概率为1/4,不是那张为3/4,但是这里面有同样花色的概率为3/15。所以1/4+3/4*3/15=2/5。 - 五个海盗抢到了100颗宝石,每一颗都一样大小和价值连城。他们决定这么分:
抽签决定自己的号码(1、2、3、4、5)
首先,由1号提出分配方案,然后大家表决,当且仅当超过半数的人同意时,按照他的方案进行分配,否则将被扔进大海喂鲨鱼
如果1号死后,再由2号提出分配方案,然后剩下的4人进行表决,当且仅当超过半数的人同意时,按照他的方案进行分配,否则将被扔入大海喂鲨鱼,依此类推
条件:每个海盗都是很聪明的人,都能很理智地做出判断,从而做出选择。
问题:第一个海盗提出怎样的分配方案才能使自己的收益最大化?
倒推法: ①假设1、2、3号都死了,只剩4号和5号。这时无论4号怎么分(哪怕分5号100个),5号只要反对,4号就死了(因为没有超过半数同意,非要大于50%才行),4号的生命得不到保障,所以,4号不能让3号死,3号死了4号就危险,所以,3号不论怎么分,4号都得同意。 ②假设1、2号死了,3号来分的话,他肯定分自己100个,4号和5号都0个,因为3号肯定同意,4号也必须同意,就有大于50%的选票。 ③假设1号死了,2号来分。2号肯定不会收买3号,收买4号和5号更好些,因为只要给他们1人1个,4号和5号就都得同意(由假设2,2号死了的话,4号和5号一个也分不到,现在2号给了他们1人1个,他们只得同意,2号会这么分:98、0、1、1)。 ④假设1号来分,他不会收买2号,那起码要给2号99个才行,他肯定会收买3号,因为给3号1个,3号就会同意1号的分法,3号要是不同意,1号死了2号分的话,3号一个也得不到,这时1号只要再收买4号和5号中任何一人就行了,给这个人两个,他就必须同意。 所以,1号的分配方案为:97、0、1、2、0 或97、0、1、0、2。 - 老王有两个孩子,已知至少有一个孩子是在星期二出生的男孩。问:两个孩子都是男孩的概率是多大?
https://blog.csdn.net/u012662688/article/details/52813387 - u(z)、t检验(计算统计量后与表中数据对照判断是否通过检验)
u检验和t检验可用于样本均数与总体均数的比较以及两样本均数的比较。理论上要求样本来自正态分布总体。但在实用时,只要样本例数n较大,或n小但总体标准差σ已知时,就可应用u检验;n小且总体标准差σ未知时,可应用t检验,但要求样本来自正态分布总体。两样本均数比较时还要求两总体方差相等。
例题: https://www.cnblogs.com/emanlee/archive/2008/10/25/1319587.html