- Web安全攻防入门教程——hvv行动详解
白帽子黑客罗哥
web安全安全网络安全系统安全红蓝对抗
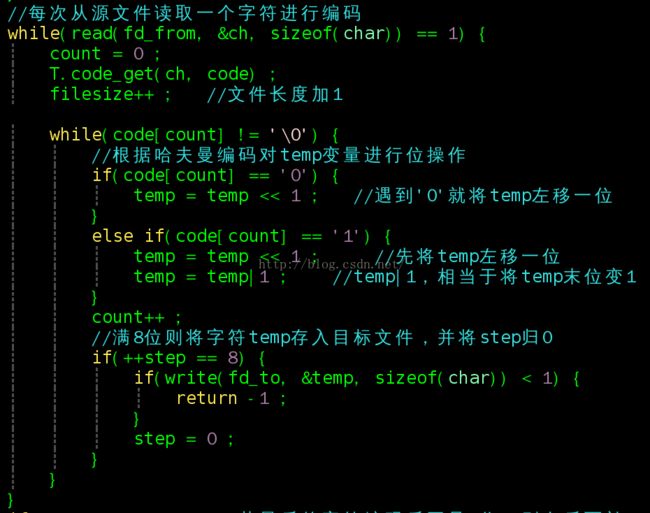
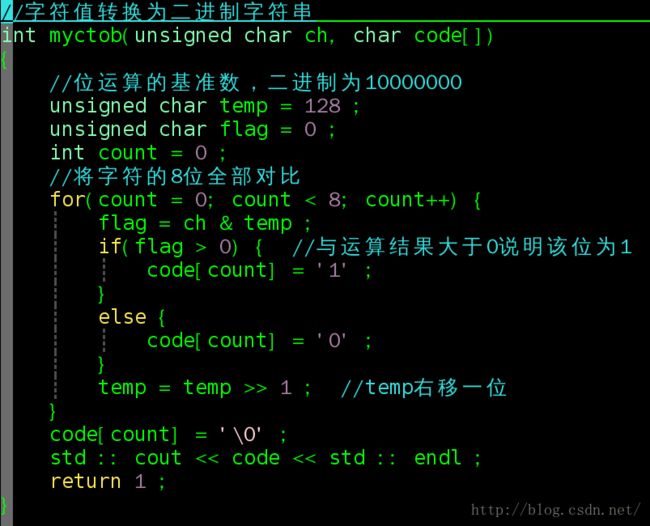
Web安全攻防入门教程Web安全攻防是指在Web应用程序的开发、部署和运行过程中,保护Web应用免受攻击和恶意行为的技术与策略。这个领域不仅涉及防御措施的实现,还包括通过渗透测试、漏洞挖掘和模拟攻击来识别潜在的安全问题。本教程将带你入门Web安全攻防的基础概念、常见攻击类型、防御技术以及一些实战方法。一、Web安全基础Web应用安全的三大核心目标(CIA三原则)机密性(Confidentialit
- 基于 FFmpeg 实现 H.264 转 MP4 视频转码
码农新猿类
FFMPEGffmpeg
引言FFmpeg是强大的开源音视频处理库,能实现多种音视频操作。本文将分享如何用FFmpeg把H.264视频文件转码为MP4格式。代码整体思路代码把转码功能封装在TranceVideo类中,通过一系列步骤完成H.264到MP4的转码,包括初始化、打开输入文件、获取视频流信息、确定输出格式、创建输出文件、转码并写入帧数据,最后清理资源。详细步骤1.初始化在类的构造函数里,进行基础的初始化操作:cpp
- 自己制作一个专业AI(deepseek、chatgtp、文心一言、豆包、kimi、grok4)
小阿技术
dockerchatgpt人工智能深度学习神经网络自然语言处理文心一言
自己制作一个专业AI(deepseek、chatgtp、豆包、通义千问、kimi)智能体这是一个自己制作的AI智能体(模型自己选择:豆包、chatgtp、deepseek、文心一言、kimi、通义千问等)功能可以上传自己的知识库,打造一个基于自己知识库的专业AI实现把自己知识库上传到服务器+调用大模型+调用API+部署到微信小程序需要的联系可以给代码可以教学,包学会不需要代码适合零基础❗️❗️
- Spring Cloud 和 Dubbo 区别
SpringCloud和Dubbo是两种主流的微服务框架,它们在设计理念、技术实现和应用场景上有显著差异。以下是两者的核心区别及各自的优缺点分析:一、核心区别1.初始定位与设计理念SpringCloud:定位为微服务架构的一站式解决方案,提供完整的分布式系统开发工具链(如服务注册、配置中心、网关、熔断器等),注重微服务治理的全面性。Dubbo:起源于SOA时代,核心关注服务调用与治理(如RPC通信
- Python 中链表的个人理解
python链表
链表组成Python中链表由head、节点、tail、三部分组成。节点为Python链表中最重要的部分,通过构建classNode()类,节点引入并存储value和next变量,其中value为Node中存储的链表内容,next为Node中存储的指针,指向下一个Node。即Node由指针域next和结构域value构成。链表由上述Node连结而成,其中head指向链表的第一个节点,tail指向链表
- 为什么使用 RocketMQ?
rocketmq消息中间件
RocketMQ与其他主流消息队列(如Kafka、RabbitMQ、ActiveMQ)的优缺点对比如下:一、RocketMQ的核心优势高吞吐与低延迟吞吐量:单机可达10万级消息/秒,介于Kafka(29万/秒)与RabbitMQ(2.6万/秒)之间。延迟:毫秒级响应,适用于实时性要求较高的在线业务(如交易系统)。适用场景:大规模分布式系统,日均处理百亿级消息,尤其适合金融交易、订单处理等高并发场景
- 商城项目秒杀业务秒杀业务完善和网关配置路由转发----商城项目
旧约Alatus
电商项目#Spring-Cloud框架#Spring-Boot框架springboot分布式springspringcloud后端mybatis微服务
packagecom.alatus.mall.seckill.app;importcom.alatus.common.utils.R;importcom.alatus.mall.seckill.service.SecKillService;importcom.alatus.mall.seckill.to.SecKillSkuRedisTo;importorg.springframework.bea
- 机器学习校招面经二
Y1nhl
搜广推面经机器学习人工智能算法推荐算法数据挖掘搜索算法pytorch
快手机器学习算法一、AUC(AreaUndertheROCCurve)怎么计算?AUC接近1可能的原因是什么?见【搜广推校招面经四】AUC是评估分类模型性能的重要指标,用于衡量模型在不同阈值下区分正负样本的能力。它是ROC曲线(ReceiverOperatingCharacteristicCurve)下的面积。1.1.ROC曲线的坐标ROC曲线以真正例率(TruePositiveRate,TPR)
- HashMap 的底层数据结构与 put 操作流程
1.HashMap的底层数据结构HashMap是Java中实现了Map接口的一个常用类,主要用来存储键值对(Key-Value)。它底层依赖于哈希表(HashTable)实现,主要使用数组和链表(或红黑树)两种数据结构。主要组成:数组:HashMap使用一个数组来存储所有的桶(bucket),每个桶可以存储一个或多个键值对。链表:当多个键值对的哈希值相同时(即哈希冲突),这些元素会存储在同一个桶的
- 详解DeepSeek模型底层原理及和ChatGPT区别点
瞬间动力
语言模型机器学习AI编程云计算阿里云
一、DeepSeek大模型原理架构基础DeepSeek基于Transformer架构,Transformer架构主要由编码器和解码器组成,在自然语言处理任务中,通常使用的是Transformer的解码器部分。它的核心是自注意力机制(Self-Attention),这个机制允许模型在处理输入序列时,关注序列中不同位置的信息。例如,在处理句子“Thecatchasedthemouse”时,自注意力机制
- Web安全攻防入门教程——hvv行动详解
白帽子黑客罗哥
web安全安全网络安全pythonjava
Web安全攻防入门教程Web安全攻防是指在Web应用程序的开发、部署和运行过程中,保护Web应用免受攻击和恶意行为的技术与策略。这个领域不仅涉及防御措施的实现,还包括通过渗透测试、漏洞挖掘和模拟攻击来识别潜在的安全问题。本教程将带你入门Web安全攻防的基础概念、常见攻击类型、防御技术以及一些实战方法。一、Web安全基础Web应用安全的三大核心目标(CIA三原则)机密性(Confidentialit
- linux 远程文件同步(shell)
黑暗的笑
shellexpect远程传文件while
1.首先安装tcl和expect(先安装tcl,再安装expect,自行百度),sshpass2.我想把本地文件同步到其他几台机器上,因此,需要知道机器的ip,username,password,我用一个文件来存放这些内容machine_info,内容如下:127.0.0.1usernamepassword192.168.12.12usenamepassword编写expectshell#!/us
- 深度解析RocketMQ核心机制:CommitLog存储与DLedger选举算法
千里码!
rocketmq后端技术javarocketmq算法数据库
深度解析RocketMQ核心机制:CommitLog存储与DLedger选举算法编程相关书籍分享:https://blog.csdn.net/weixin_47763579/article/details/145855793DeepSeek使用技巧pdf资料分享:https://blog.csdn.net/weixin_47763579/article/details/145884039一、Com
- 华为面试题及答案——机器学习(二)
麦当当MDD
题目挖掘机器学习人工智能数据库开发数据库大数据
21.如何评价分类模型的优劣?(1)模型性能指标准确率(Accuracy):定义:正确分类的样本数与总样本数之比。适用:当各类样本的数量相对均衡时。精确率(Precision):定义:预测为正类的样本中实际为正类的比例。适用:当关注假阳性错误的成本较高时(例如垃圾邮件检测)。召回率(Recall):定义:实际为正类的样本中被正确预测为正类的比例。适用:当关注假阴性错误的成本较高时(例如疾病检测)。
- VsCode使用
keep one's resolveY
前端vscodeide编辑器
vscode前端vue项目启动:Vue项目的创建启动及注意事项-CSDN博客vscode使用教程:史上最全vscode配置使用教程-夏天的思考-博客园vscode如何从git拉取代码:vscode如何从git拉取代码•Worktile社区
- Shell:控制脚本 - 信号量
二进制杯莫停
#Shell编程bashlinux
1.处理信号1.1重温Linux信号Linux系统和应用程序可以生成超过30个信号。表16-1列出了在Linux编程时会遇到的最常见的Linux系统信号。通过SIGINT信号,可以中断shell。你可能也注意到了,shell会将这些信号传给shell脚本程序来处理。而shell脚本的默认行为是忽略这些信号。它们可能会不利于脚本的运行。要避免这种情况,你可以脚本中加入识别信号的代码,并执行命令来处理
- Shell:创建函数
二进制杯莫停
#Shell编程bash
1.创建函数的两种方式1.1创建函数有两种格式可以用来在bashshell脚本中创建函数。脚本中定义的每个函数都必须有一个唯一的名称。第一种格式采用关键字function,后跟分配给该代码块的函数名。name属性定义了赋予函数的唯一名称。functionname{commands}第二种格式更接近于其他编程语言中定义函数的方式。name(){commands}1.2使用函数$cattest1#!/
- Shell:呈现数据
二进制杯莫停
#Shell编程bash
1.标准文件描述符Linux系统将每个对象当作文件处理。这包括输入和输出进程。Linux用文件描述符(filedescriptor)来标识每个文件对象。文件描述符是一个非负整数,可以唯一标识会话中打开的文件。每个进程一次最多可以有九个文件描述符。出于特殊目的,bashshell保留了前三个文件描述符(0、1和2)1.1重定向STDINshell从STDIN文件描述符对应的键盘获得输入,在用户输入时
- 征程 6 工具链 BEVPoolV2 算子使用教程 1 - BEVPoolV2 算子详解
算法自动驾驶
1.引言当前,地平线征程6工具链已经全面支持了BEVPoolingV2算子,并与mmdetection3d的实现完成了精准对齐。然而,需要注意的是,此算子因其内在的复杂性以及相关使用示例的稀缺,致使部分用户在实际运用过程中遭遇了与预期不符的诸多问题。在这样的背景下,本文首先会对BEVPoolingV2的实现进行全方位、细致入微的剖析讲解,,让复杂的原理变得清晰易懂。随后,还会通过代表性的示例,来进
- Ubuntu系统下交叉编译libpng
linux运维
一、交叉编译libpng1.下载源码下载libpng:http://www.libpng.org/pub/png/libpng.html下载并解压源码。tar-xvzflibpng-1.6.45.tar.gzcdlibpng-1.6.452.设置环境变量设置交叉编译工具链的bin路径:exportPATH=/home/yoyo/360Downloads/toolchains/arm-linux-g
- shell脚本中set -e用途
二进制杯莫停
#Shell编程bash
在shell脚本中,set-e是一个命令,用于设置shell的退出行为。具体来说,当在脚本中执行一个命令,并且该命令返回非零退出状态时(通常表示错误),set-e会导致整个脚本立即退出,而不是继续执行后续的命令。这有助于在脚本中早期发现错误,并防止可能由于后续命令执行而导致的更严重的问题。例如,考虑以下脚本:#!/bin/bashset-eecho"Startingscript"false#这个命
- 《围城》:初读不接书中意,再读已是书中人
后端
元数据[!abstract]围城围城|200书名:围城作者:钱钟书简介:钱钟书先生最经典的作品,也是仅有的一部长篇小说,堪称中国现代文学史上风格独特的讽刺经典,被誉为“新儒林外史”,自上世纪八十年代以来一直横贯常销、畅销小说之首。小说塑造了抗战初期以方鸿渐为主的一类知识分子群像,记叙了他们所面临的教育、婚姻和事业困境。虽然有具体的历史背景,但这部小说揭示的人群的弱点,在今天依然能引起人们的共鸣。著
- 四、MyBatis获取参数值的两种方式(重点)
计算机数学仿真智能硬件算法
@[toc]四、MyBatis获取参数值的两种方式(重点)MyBatis获取参数值的两种方式:${}和#{}${}的本质就是字符串拼接,#{}的本质就是占位符赋值${}使用字符串拼接的方式拼接sql,若为字符串类型或日期类型的字段进行赋值时,需要手动加单引号;但是#{}使用占位符赋值的方式拼接sql,此时为字符串类型或日期类型的字段进行赋值时,可以自动添加单引号4.1单个字面量类型的参数若mapp
- vue3 Teleport的使用及场景。
gxw_viva
vue3学习笔记vue.js前端javascript
Vue3中的Teleport(传送门)是一个非常有用的特性,它允许你在DOM树中的任意位置动态地渲染组件。Teleport实质上是将组件的内容“传送”到指定的目标位置,而不受组件自身所在位置的限制。Teleport的使用场景包括但不限于:模态框(Modal):你可以使用Teleport将模态框的内容渲染到标签之外,以避免模态框受到父级容器CSS样式的影响,并且可以保证在层叠顺序上处于最顶层。弹出菜
- MATH2110 - STATISTICS 3
后端
MATH2110-STATISTICS3SPRINGSEMESTERSEMESTER2025Coursework1Deadline:3pm,Friday14/3/2025Yourneat,clearly-legiblesolutionsshouldbesubmittedelectronicallyasaJupyterorPDFfileviatheMATH2110Moodlepagebythedea
- 深入解析/etc/hosts.allow与 /etc/hosts.deny:灵活控制 Linux 网络访问权限
XMYX-0
linux网络服务器
文章目录深入解析/etc/hosts.allow与/etc/hosts.deny:灵活控制Linux网络访问权限引言什么是TCPWrappers?工作原理什么是/etc/hosts.allow和/etc/hosts.deny?匹配规则配置语法详解配置示例允许特定IP访问SSH服务拒绝整个子网访问FTP服务允许内网,拒绝外网记录非法访问尝试注意事项高级配置与技巧允许特定IP地址访问服务拒绝某个网段的
- 大语言模型技术发展
联蔚盘云
经验分享
摘要海外闭源模型领域竞争激烈,OpenAI保持领先地位,而开源模型如Meta的Llama系列也逐渐崛起。LLM技术呈现出大型模型和小型模型并行发展的趋势,同时,多模态功能和长上下文能力成为顶级模型的标准配置。MoE架构的出现推动了模型参数量向万亿级别迈进。未来,ScalingLaw的极限尚未触及,开源模型将扮演重要角色,数据供给成为关键挑战,新的模型架构将涌现,AIAgent和具身智能将成为推动通
- 计算机专业知识【小白必懂的 CIDR “/24” 表示法详解】
一勺菠萝丶
计算机专业知识网络服务器linux
一、引言在计算机网络的世界里,常常会遇到像“/24”这样奇怪的表示,对于刚接触网络知识的小白来说,这简直就像神秘的密码一样难以理解。二、什么是CIDR表示法(一)CIDR的定义CIDR是无类别域间路由(ClasslessInter-DomainRouting)的缩写,它是一种用于表示IP地址和子网掩码的简洁方式。在传统的网络分类(A类、B类、C类等)中,子网掩码的划分比较固定,而CIDR打破了这种
- 第五阶段【MySQL数据库:常用开发语言连接MySQL】01:使用Shell操作MySQL
做一个有趣的人Zz
DBA数据工程师成长之路数据库mysqldba
一、创建测试用户和测试表CREATEUSER'shell_rw'@'%'IDENTIFIEDBY'admin';GRANTcreate,alter,insert,delete,select
- linux shell脚本用while read逐行读取文本的问题
weixin_34060741
shell运维
转自:https://zhidao.baidu.com/question/432126157616850964.html问题:我现在是想用一个脚本获取一定列表服务器的运行时间。首先我建立一个名字为ip.txt的IP列表(一个IP一行),再建好密钥实现不用密码直接登录。然后写脚本如下:#!/bin/bashwhilereadips;doecho$ips;done
- Spring4.1新特性——Spring MVC增强
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- mysql 性能查询优化
annan211
javasql优化mysql应用服务器
1 时间到底花在哪了?
mysql在执行查询的时候需要执行一系列的子任务,这些子任务包含了整个查询周期最重要的阶段,这其中包含了大量为了
检索数据列到存储引擎的调用以及调用后的数据处理,包括排序、分组等。在完成这些任务的时候,查询需要在不同的地方
花费时间,包括网络、cpu计算、生成统计信息和执行计划、锁等待等。尤其是向底层存储引擎检索数据的调用操作。这些调用需要在内存操
- windows系统配置
cherishLC
windows
删除Hiberfil.sys :使用命令powercfg -h off 关闭休眠功能即可:
http://jingyan.baidu.com/article/f3ad7d0fc0992e09c2345b51.html
类似的还有pagefile.sys
msconfig 配置启动项
shutdown 定时关机
ipconfig 查看网络配置
ipconfig /flushdns
- 人体的排毒时间
Array_06
工作
========================
|| 人体的排毒时间是什么时候?||
========================
转载于:
http://zhidao.baidu.com/link?url=ibaGlicVslAQhVdWWVevU4TMjhiKaNBWCpZ1NS6igCQ78EkNJZFsEjCjl3T5EdXU9SaPg04bh8MbY1bR
- ZooKeeper
cugfy
zookeeper
Zookeeper是一个高性能,分布式的,开源分布式应用协调服务。它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如同步, 配置管理,集群管理,名空间。它被设计为易于编程,使用文件系统目录树作为数据模型。服务端跑在java上,提供java和C的客户端API。 Zookeeper是Google的Chubby一个开源的实现,是高有效和可靠的协同工作系统,Zookeeper能够用来lea
- 网络爬虫的乱码处理
随意而生
爬虫网络
下边简单总结下关于网络爬虫的乱码处理。注意,这里不仅是中文乱码,还包括一些如日文、韩文 、俄文、藏文之类的乱码处理,因为他们的解决方式 是一致的,故在此统一说明。 网络爬虫,有两种选择,一是选择nutch、hetriex,二是自写爬虫,两者在处理乱码时,原理是一致的,但前者处理乱码时,要看懂源码后进行修改才可以,所以要废劲一些;而后者更自由方便,可以在编码处理
- Xcode常用快捷键
张亚雄
xcode
一、总结的常用命令:
隐藏xcode command+h
退出xcode command+q
关闭窗口 command+w
关闭所有窗口 command+option+w
关闭当前
- mongoDB索引操作
adminjun
mongodb索引
一、索引基础: MongoDB的索引几乎与传统的关系型数据库一模一样,这其中也包括一些基本的优化技巧。下面是创建索引的命令: > db.test.ensureIndex({"username":1}) 可以通过下面的名称查看索引是否已经成功建立: &nbs
- 成都软件园实习那些话
aijuans
成都 软件园 实习
无聊之中,翻了一下日志,发现上一篇经历是很久以前的事了,悔过~~
断断续续离开了学校快一年了,习惯了那里一天天的幼稚、成长的环境,到这里有点与世隔绝的感觉。不过还好,那是刚到这里时的想法,现在感觉在这挺好,不管怎么样,最要感谢的还是老师能给这么好的一次催化成长的机会,在这里确实看到了好多好多能想到或想不到的东西。
都说在外面和学校相比最明显的差距就是与人相处比较困难,因为在外面每个人都
- Linux下FTP服务器安装及配置
ayaoxinchao
linuxFTP服务器vsftp
检测是否安装了FTP
[root@localhost ~]# rpm -q vsftpd
如果未安装:package vsftpd is not installed 安装了则显示:vsftpd-2.0.5-28.el5累死的版本信息
安装FTP
运行yum install vsftpd命令,如[root@localhost ~]# yum install vsf
- 使用mongo-java-driver获取文档id和查找文档
BigBird2012
driver
注:本文所有代码都使用的mongo-java-driver实现。
在MongoDB中,一个集合(collection)在概念上就类似我们SQL数据库中的表(Table),这个集合包含了一系列文档(document)。一个DBObject对象表示我们想添加到集合(collection)中的一个文档(document),MongoDB会自动为我们创建的每个文档添加一个id,这个id在
- JSONObject以及json串
bijian1013
jsonJSONObject
一.JAR包简介
要使程序可以运行必须引入JSON-lib包,JSON-lib包同时依赖于以下的JAR包:
1.commons-lang-2.0.jar
2.commons-beanutils-1.7.0.jar
3.commons-collections-3.1.jar
&n
- [Zookeeper学习笔记之三]Zookeeper实例创建和会话建立的异步特性
bit1129
zookeeper
为了说明问题,看个简单的代码,
import org.apache.zookeeper.*;
import java.io.IOException;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ThreadLocal
- 【Scala十二】Scala核心六:Trait
bit1129
scala
Traits are a fundamental unit of code reuse in Scala. A trait encapsulates method and field definitions, which can then be reused by mixing them into classes. Unlike class inheritance, in which each c
- weblogic version 10.3破解
ronin47
weblogic
版本:WebLogic Server 10.3
说明:%DOMAIN_HOME%:指WebLogic Server 域(Domain)目录
例如我的做测试的域的根目录 DOMAIN_HOME=D:/Weblogic/Middleware/user_projects/domains/base_domain
1.为了保证操作安全,备份%DOMAIN_HOME%/security/Defa
- 求第n个斐波那契数
BrokenDreams
今天看到群友发的一个问题:写一个小程序打印第n个斐波那契数。
自己试了下,搞了好久。。。基础要加强了。
&nbs
- 读《研磨设计模式》-代码笔记-访问者模式-Visitor
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.List;
interface IVisitor {
//第二次分派,Visitor调用Element
void visitConcret
- MatConvNet的excise 3改为网络配置文件形式
cherishLC
matlab
MatConvNet为vlFeat作者写的matlab下的卷积神经网络工具包,可以使用GPU。
主页:
http://www.vlfeat.org/matconvnet/
教程:
http://www.robots.ox.ac.uk/~vgg/practicals/cnn/index.html
注意:需要下载新版的MatConvNet替换掉教程中工具包中的matconvnet:
http
- ZK Timeout再讨论
chenchao051
zookeepertimeouthbase
http://crazyjvm.iteye.com/blog/1693757 文中提到相关超时问题,但是又出现了一个问题,我把min和max都设置成了180000,但是仍然出现了以下的异常信息:
Client session timed out, have not heard from server in 154339ms for sessionid 0x13a3f7732340003
- CASE WHEN 用法介绍
daizj
sqlgroup bycase when
CASE WHEN 用法介绍
1. CASE WHEN 表达式有两种形式
--简单Case函数
CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
--Case搜索函数
CASE
WHEN sex = '1' THEN
- PHP技巧汇总:提高PHP性能的53个技巧
dcj3sjt126com
PHP
PHP技巧汇总:提高PHP性能的53个技巧 用单引号代替双引号来包含字符串,这样做会更快一些。因为PHP会在双引号包围的字符串中搜寻变量, 单引号则不会,注意:只有echo能这么做,它是一种可以把多个字符串当作参数的函数译注: PHP手册中说echo是语言结构,不是真正的函数,故把函数加上了双引号)。 1、如果能将类的方法定义成static,就尽量定义成static,它的速度会提升将近4倍
- Yii框架中CGridView的使用方法以及详细示例
dcj3sjt126com
yii
CGridView显示一个数据项的列表中的一个表。
表中的每一行代表一个数据项的数据,和一个列通常代表一个属性的物品(一些列可能对应于复杂的表达式的属性或静态文本)。 CGridView既支持排序和分页的数据项。排序和分页可以在AJAX模式或正常的页面请求。使用CGridView的一个好处是,当用户浏览器禁用JavaScript,排序和分页自动退化普通页面请求和仍然正常运行。
实例代码如下:
- Maven项目打包成可执行Jar文件
dyy_gusi
assembly
Maven项目打包成可执行Jar文件
在使用Maven完成项目以后,如果是需要打包成可执行的Jar文件,我们通过eclipse的导出很麻烦,还得指定入口文件的位置,还得说明依赖的jar包,既然都使用Maven了,很重要的一个目的就是让这些繁琐的操作简单。我们可以通过插件完成这项工作,使用assembly插件。具体使用方式如下:
1、在项目中加入插件的依赖:
<plugin>
- php常见错误
geeksun
PHP
1. kevent() reported that connect() failed (61: Connection refused) while connecting to upstream, client: 127.0.0.1, server: localhost, request: "GET / HTTP/1.1", upstream: "fastc
- 修改linux的用户名
hongtoushizi
linuxchange password
Change Linux Username
更改Linux用户名,需要修改4个系统的文件:
/etc/passwd
/etc/shadow
/etc/group
/etc/gshadow
古老/传统的方法是使用vi去直接修改,但是这有安全隐患(具体可自己搜一下),所以后来改成使用这些命令去代替:
vipw
vipw -s
vigr
vigr -s
具体的操作顺
- 第五章 常用Lua开发库1-redis、mysql、http客户端
jinnianshilongnian
nginxlua
对于开发来说需要有好的生态开发库来辅助我们快速开发,而Lua中也有大多数我们需要的第三方开发库如Redis、Memcached、Mysql、Http客户端、JSON、模板引擎等。
一些常见的Lua库可以在github上搜索,https://github.com/search?utf8=%E2%9C%93&q=lua+resty。
Redis客户端
lua-resty-r
- zkClient 监控机制实现
liyonghui160com
zkClient 监控机制实现
直接使用zk的api实现业务功能比较繁琐。因为要处理session loss,session expire等异常,在发生这些异常后进行重连。又因为ZK的watcher是一次性的,如果要基于wather实现发布/订阅模式,还要自己包装一下,将一次性订阅包装成持久订阅。另外如果要使用抽象级别更高的功能,比如分布式锁,leader选举
- 在Mysql 众多表中查找一个表名或者字段名的 SQL 语句
pda158
mysql
在Mysql 众多表中查找一个表名或者字段名的 SQL 语句:
方法一:SELECT table_name, column_name from information_schema.columns WHERE column_name LIKE 'Name';
方法二:SELECT column_name from information_schema.colum
- 程序员对英语的依赖
Smile.zeng
英语程序猿
1、程序员最基本的技能,至少要能写得出代码,当我们还在为建立类的时候思考用什么单词发牢骚的时候,英语与别人的差距就直接表现出来咯。
2、程序员最起码能认识开发工具里的英语单词,不然怎么知道使用这些开发工具。
3、进阶一点,就是能读懂别人的代码,有利于我们学习人家的思路和技术。
4、写的程序至少能有一定的可读性,至少要人别人能懂吧...
以上一些问题,充分说明了英语对程序猿的重要性。骚年
- Oracle学习笔记(8) 使用PLSQL编写触发器
vipbooks
oraclesql编程活动Access
时间过得真快啊,转眼就到了Oracle学习笔记的最后个章节了,通过前面七章的学习大家应该对Oracle编程有了一定了了解了吧,这东东如果一段时间不用很快就会忘记了,所以我会把自己学习过的东西做好详细的笔记,用到的时候可以随时查找,马上上手!希望这些笔记能对大家有些帮助!
这是第八章的学习笔记,学习完第七章的子程序和包之后