实操_Spark_v1.0.0
| 文件名称 | 版本号 | 作者 | 备注 | |
|---|---|---|---|---|
| 实操_Spark | v1.0.0 | 学生宫布 | 8416837 | Spark2.11-2.4.4|Hadoop2.7.7|Ubuntu18 |
文章目录
- 部署
- 安装包式部署-Hadoop已提前部署
- 下载&解压
- 环境变量
- 角色介绍
- 启动
- 单机
- ./bin/spark-shell
- 简单Demo测试
- 任务
- 任务提交
- 简单Demo测试一下
- Spark提交自己编写的Scala或Java程序-待续
部署
安装包式部署-Hadoop已提前部署
下载&解压
sudo wget -O spark.tgz http://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
sudo tar xvzf spark.tgz -C /home/app # 解压
# 进入根目录
pwd # 根目录==/home/app/spark-2.4.4-bin-hadoop2.7
环境变量
- 命令配置到环境变量
sudo vim /etc/profile
export SPARK_HOME=/home/app/spark-2.4.4-bin-hadoop2.7
PATH=${SPARK_HOME}/sbin:$PATH
source /etc/profile
- Scala安装,这个以前没怎么玩过,那就说下安装过程,估计差不多
# 下载地址 https://www.scala-lang.org/download/2.11.12.html
Spark2.x对应Scala2.11.x
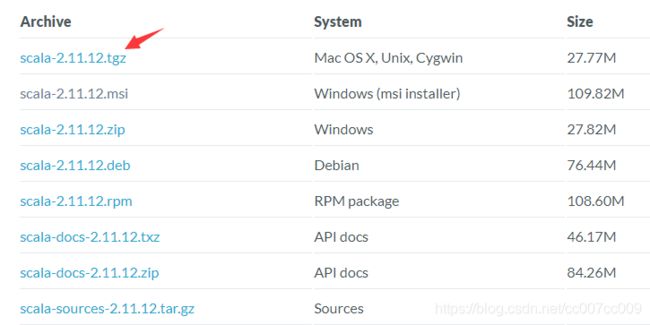
sudo wget https://downloads.lightbend.com/scala/2.11.12/scala-2.11.12.tgz # wget下载Scala
sudo tar xvzf scala-2.11.12.tgz -C /data/app # 一样的,解压
/data/app/scala-2.11.12 # 复制根目录
sudo vim /etc/profile
export SCALA_HOME=/data/app/scala-2.11.12
PATH=${SCALA_HOME}/bin:$PATH
source /etc/profile
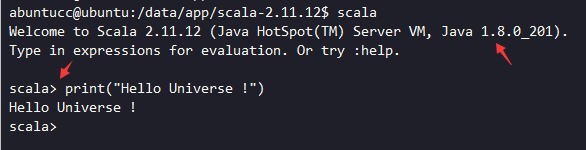
很简单,检验成功↓print和Python3差不多,只是双引号强限定。
- 依赖环境的配置,不少。其中hadoop之前已经部署。
sudo cp conf/spark-env.sh.template conf/spark-env.sh
sudo vim conf/spark-env.sh
在conf/spark-env.sh里填入
#jdk安装目录
export JAVA_HOME=/data/app/jdk1.8.0_201
#scala安装目录
export SCALA_HOME=/data/app/scala-2.11.12
#hadoop安装目录
export HADOOP_HOME=/home/app/hadoop-2.7.7
#hadoop配置文件目录
export HADOOP_CONF_DIR=/home/app/hadoop-2.7.7/etc/hadoop
# export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
#master节点ip
export SPARK_MASTER_IP=192.168.12.132
#每个worker节点能够最大分配给exectors的内存大小
export SPARK_WORKER_MEMORY=1g
#每个worker节点所占有的CPU核数目
export SPARK_WORKER_CORES=1
#每台机器上开启的worker节点的数目
export SPARK_WORKER_INSTANCES=1
打入上述配置。
sudo vim conf/slaves增加从节点
角色介绍
| 角色 | 功能 | 备注 |
|---|---|---|
| Driver端 | 它会运行客户端写好的main方法和构建SparkContext对象,SparkContext对象是所有spark程序执行入口 | |
| Application | 它就是一个应用程序,包括了Driver的代码逻辑和当前这个任务在运行的时候所有需要的资源信息 | |
| ClusterManager | 它可以给当前任务提供计算资源的外部服务 | |
| standAlone | spark自带的集群模式,整个任务的资源分配由Master去负责 | ClusterManager |
| yarn | spark程序可以提交到yarn中去运行,整个任务的资源分配由ResourceManager去负责 | ClusterManager |
| mesos | 它是一个apache开源的类似于yarn的资源管理平台 | ClusterManager |
| Master | 它是spark集群的老大,它负责给任务分配资源,它不会参与计算 | |
| Worker | 它是spark集群的小弟,它负责任务计算的节点 | |
| Executor | 它就是一个进程,它会在worker节点启动executor进程 | |
| task | 它就是一个线程,task是以线程的方式运行在worker节点的executor进程中 |
启动
单机
# 进入根目录
sbin/start-all.sh # 启动全部
查看启动成功的进程,成功。

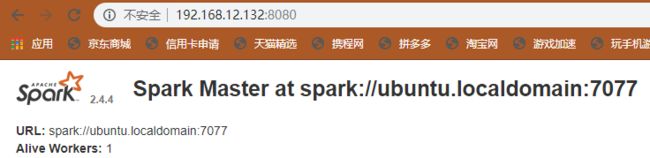
sudo ufw allow 8080;sudo ufw reload;sudo ufw status; # 开启8080端口并查看
访问http://192.168.12.132:8080/,成功
./bin/spark-shell
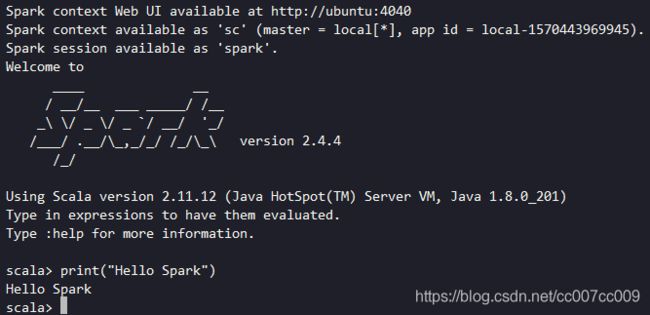
./bin/spark-shell # 启动
启动成功
spark-shell启动时可以传参,参数意义见下表
| 参数 | 意义 | 备注 |
|---|---|---|
| –master local[N] | local:表示本地运行spark程序,跟spark集群没有任何关系 | N:表示一个正整数,在这里local[N]表示本地采用N个线程去运行任务 |
| –master spark://node-x:7077 | 指定具体活着的master |
简单Demo测试
- 文件浏览
执行命令后,它会产生一个Spark-Submit进程。下文任务提交有讲。
val textFile = sc.textFile("file:///home/app/spark-2.4.4-bin-hadoop2.7/README.md");
textFile.first(); # 第一行的内容
textFile.count(); # 总共多少行

没问题,正常。
开启4040端口
sudo ufw allow 4040;sudo ufw reload;sudo ufw status;
访问:http://ubuntu:4040/jobs/,发现刚才执行的两个任务
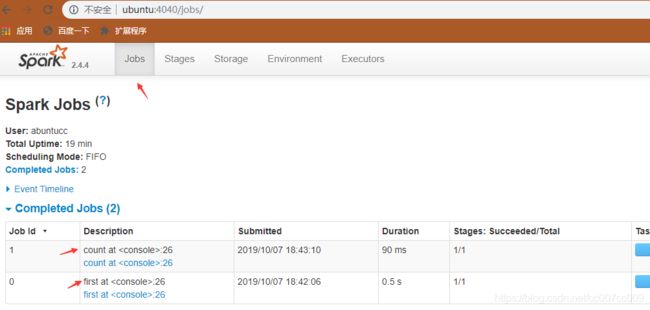
- 从HDFS读取数据进行wordcount统计
sc.textFile("hdfs://localhost:54310/user/hduser_/input006/words.txt").flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).collect
执行成功

- 把统计结果保存到HDFS
./bin/spark-shell --master spark://192.168.12.132:7077 # master方式启动脚本
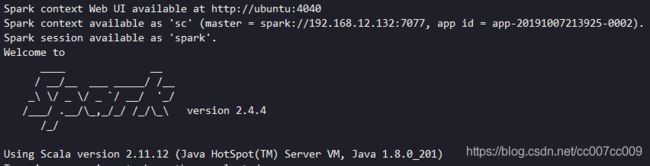
执行前
sc.textFile("hdfs://localhost:54310/user/hduser_/input006/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/user/hduser_/output007")
执行脚本,报错了,输出目录已经存在
![]()
换个不存在的目录,执行成功

用命令预览统计结果或者下载结果成功。
访问http://192.168.12.132:8080/,发现刚才的shell提交

任务
任务提交
简单Demo测试一下
Spark tar包里自带的例子
执行下述命令
# cd spark根目录
bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://192.168.12.132:7077 --executor-memory 1G --total-executor-cores 2 examples/jars/spark-examples_2.11-2.4.4.jar 10
注意,上述命令的jar包版本号以实际位置,比如我的是2.11-2.4.4
另外还有ha高可用模式下的提交,master节点是多个,如spark://node1:7077,node2:7077,node3:7077,需要找活着的master申请资源,由于master特别多,我们无法快速判断哪个master是活着的master,即使判断出了哪个master是活着的master,它也有可能下一秒就挂掉了,这个时候就可以在提交任务的时候指定 --master spark://node1:7077,node2:7077,node3:7077 把所有的master地址进行罗列。后期整个程序会依次轮询master列表,最后找到活着的master,然后向这个活着的master申请资源。

计算结果,参数10 ,只是粗略的计算。
![]()
参数改成30,计算中。。。
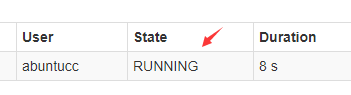
计算结果
![]()
Spark提交自己编写的Scala或Java程序-待续
一个Java版单词统计例子,此例子没有传参,硬编码了参数。把它打成jar包,即可让spark提交执行。待测
//todo:利用java语言开发spark的wordcount程序(本地运行)
public class WordCount_Java {
public static void main(String[] args) { // 这里接收参数
//1、创建SparkConf
SparkConf sparkConf = new SparkConf().setAppName("WordCount_Java").setMaster("spark地址");
//2、创建JavaSparkContext
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
//3、读取文件数据
JavaRDD<String> data = jsc.textFile("E:\\words.txt");
//4、切分每一行,获取所有的单词
JavaRDD<String> words = data.flatMap(new FlatMapFunction<String, String>() {
public Iterator<String> call(String line) throws Exception {
String[] lines = line.split(" ");
return Arrays.asList(lines).iterator();
}
});
//5、每个单词计为1
JavaPairRDD<String, Integer> wordAndOne = words.mapToPair(new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
//6、相同单词出现的1累加
JavaPairRDD<String, Integer> result = wordAndOne.reduceByKey(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//按照单词出现的次数降序排列 (单词,次数)----->(次数,单词).sortByKey----->(单词,次数)
JavaPairRDD<Integer, String> reverseRDD = result.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
public Tuple2<Integer, String> call(Tuple2<String, Integer> t) throws Exception {
return new Tuple2<Integer, String>(t._2, t._1);
}
});
JavaPairRDD<String, Integer> sortedRDD = reverseRDD.sortByKey(false).mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
public Tuple2<String, Integer> call(Tuple2<Integer, String> t) throws Exception {
return new Tuple2<String, Integer>(t._2, t._1);
}
});
//7、收集打印
List<Tuple2<String, Integer>> finalResult = sortedRDD.collect();
for (Tuple2<String, Integer> t : finalResult) {
System.out.println("单词:"+t._1+" 次数:"+t._2);
}
//8、关闭jsc
jsc.stop();
}
}
提交范例
bin/spark-submit --master spark://node1:7077,node2:7077,node3:7077 --class com.hrh.spark.WordCount_Online --executor-memory 1g --total-executor-cores 3 original-spark_class14-1.0-SNAPSHOT.jar /../words.txt /../out_spark # 打好jar包,提交范例,上文也有讲。注意参数路径。