Redis主从复制与哨兵模式
本文基于redis-5.0.3版本,环境为Mac OS,单机器上部署。
Redis单机存在的问题
- 单机故障
- 容量瓶颈
- QPS瓶颈
Redis主从复制
主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,mester以写为主,slaver以读为主。
配置原则
- 1.配从不配主。
- 2.使用命令SLAVEOF动态指定主从关系,如果设置了密码,关联后使用 config set masterauth 密码。
- 3.配置文件和命令混合使用时,如果混合使用,动态指定了主从,请注意一定要修改对应的配置文件。
实例演示
下面我们来构建一个一主二从的主从复制结构,架构图如下:

1、新建三个文件夹redis6381 redis6382 redis6383,并将redis.conf文件复制到每个文件夹下,目录结构如下(redis-cluster是我自己建的集群根目录),我们以redis6381为主节点。

2、修改redis.conf配置文件
redis6381/redis.conf
# 指定redis所在服务器IP
bind 10.40.231.95
port 6381
daemonize yes
# 因为是在同一台主机上搭建的主从复制,这里以端口号来区分
pidfile "/var/run/redis_6381.pid"
dir "/redis-cluster/redis6381"
masterauth 123456
requirepass "123456"
redis6382/redis.conf
bind 10.40.231.95
port 6382
daemonize yes
pidfile "/var/run/redis_6382.pid"
dir "/redis-cluster/redis6382"
# 指定copy数据的主节点
replicaof 10.40.231.95 6381
masterauth "123456"
requirepass "123456"
redis6383/redis.conf
bind 10.40.231.95
port 6383
daemonize yes
pidfile "/var/run/redis_6383.pid"
# 指定copy数据的主节点
dir "/redis-cluster/redis6383"
replicaof 10.40.231.95 6381
masterauth "123456"
requirepass "123456"
3.启动示例
➜ redis-5.0.3 src/redis-server /redis-cluster/redis6381/redis.conf
➜ redis-5.0.3 src/redis-server /redis-cluster/redis6382/redis.conf
➜ redis-5.0.3 src/redis-server /redis-cluster/redis6383/redis.conf
4.查看主从信息
➜ redis-5.0.3 src/redis-server /redis-cluster/redis6381/redis.conf
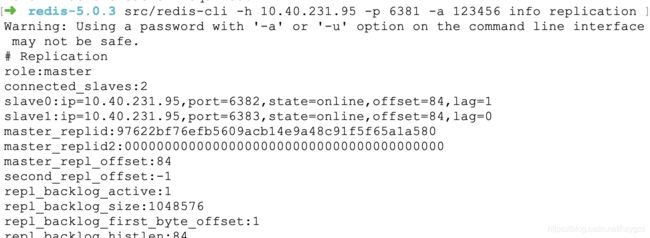
可以看出主从复制结构已搭建成功,6381为主节点,6382、6383为从节点。大家可以通过客户端连接去测试验证下。
主从复制的缺点
1.由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
2.当主机宕机之后,将不能进行写操作,需要手动将从机升级为主机,从机需要重新指定master。
redis哨兵模式
从Redis 2.8版本开始,redis引入了哨兵模式来解决上述故障主节点无法自动转移的问题。
哨兵模式的主要功能
监控: 哨兵会不断地检查主节点和从节点是否运作正常
自动故障转移: 当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
配置提供者: 客户端在初始化时,通过连接哨兵来获得当前Redis服务的主节点地址。
通知: 哨兵可将故障转移的结果发送给客户端。
实例演示
哨兵模式中有两种类型的节点:
哨兵节点: 哨兵系统有一个或多个哨兵节点组成,哨兵节点是特殊的Redis节点,不存储数据。
数据节点: 主节点和从节点都是数据节点。
下面我们来搭建3个哨兵节点,配和上面的的主从复制示例,来演示下哨兵模式的搭建以及故障的转移测试。架构图如下:

1.部署主从节点
哨兵系统中的主从节点,与普通的主从节点配置是一样的,上面我们搭建的示例就是。
2.部署哨兵节点
新建文件夹sentinel,并复制redis安装目录下的sentinel.conf文件,这里我们搭建三个哨兵,所以这里复制三次,文件名后加上端口号识别。目录结构如下:
sentinel-26381.conf
bind 0.0.0.0
port 26381
daemonize yes
# 因为是在同一台主机上搭建的主从复制,这里以端口号来区分
pidfile "/var/run/redis-sentinel26381.pid"
logfile "26381.log"
# mymaster是自定义集群名称,哨兵可以监控多个集群 后面的ip和端口是集群主机的IP和端口 2代表需要至少2个哨兵判定主节点下线,才对该主节点进行客观下线
sentinel monitor mymaster 10.40.231.95 6381 2
# 集群认证密码
sentinel auth-pass mymaster 123456
sentinel-26382.conf
bind 0.0.0.0
port 26382
daemonize yes
# 因为是在同一台主机上搭建的主从复制,这里以端口号来区分
pidfile "/var/run/redis-sentinel26382.pid"
logfile "26382.log"
# mymaster是自定义集群名称,哨兵可以监控多个集群 后面的ip和端口是集群主机的IP和端口 2代表需要至少2个哨兵判定主节点下线,才对该主节点进行客观下线
sentinel monitor mymaster 10.40.231.95 6381 2
# 集群认证密码
sentinel auth-pass mymaster 123456
sentinel-26383.conf
bind 0.0.0.0
port 26383
daemonize yes
# 因为是在同一台主机上搭建的主从复制,这里以端口号来区分
pidfile "/var/run/redis-sentinel26383.pid"
logfile "26383.log"
# mymaster是自定义集群名称,哨兵可以监控多个集群 后面的ip和端口是集群主机的IP和端口 2代表需要至少2个哨兵判定主节点下线,才对该主节点进行客观下线
sentinel monitor mymaster 10.40.231.95 6381 2
# 集群认证密码
sentinel auth-pass mymaster 123456
3.启动示例
➜ redis-5.0.3 src/redis-sentinel /redis-cluster/sentinel/sentinel-26381.conf
➜ redis-5.0.3 src/redis-sentinel /redis-cluster/sentinel/sentinel-26382.conf
➜ redis-5.0.3 src/redis-sentinel /redis-cluster/sentinel/sentinel-26383.conf
启动后,活动监视器里会发现多了三个进程,说明哨兵节点已启动起来。

3.故障转移测试
通过一段代码来测试下,当主节点down机后,哨兵模式的自动故障恢复。
// 测试代码 循环打印UUID值
public static void main(String[] args) {
Logger logger = LoggerFactory.getLogger(TestSentinel.class);
Set set = new HashSet<>();
set.add("10.40.231.95:26381");
set.add("10.40.231.95:26382");
set.add("10.40.231.95:26383");
JedisSentinelPool jedisSentinelPool = new JedisSentinelPool("mymaster", set, "123456");
while (true) {
Jedis jedis = null;
try {
jedis = jedisSentinelPool.getResource();
String s = UUID.randomUUID().toString();
jedis.set("k" + s, "V" + s);
System.out.println(jedis.get("k" + s));
Thread.sleep(1000);
} catch (Exception e) {
logger.error(e.getMessage());
} finally {
if (jedis != null) {
jedis.close();
}
}
}
}
kill掉端口号为6381的redis主节点,会发现控制台中停止打印,过一会当重新选出主节点后,程序又恢复正常,说明哨兵模式进行了自动故障恢复。

哨兵模式基本原理
主观下线: 在心跳检测的定时任务中,如果其他节点超过一定时间没有回复,哨兵节点就会将其进行主观下线。顾名思义,主观下线的意思是一个哨兵节点“主观地”判断下线。
客观下线: 哨兵节点在对主节点进行主观下线后,会通过sentinel is-master-down-by-addr命令询问其他哨兵节点该主节点的状态;如果判断主节点下线的哨兵数量达到一定数值,则对该主节点进行客观下线。
需要特别注意的是,客观下线是主节点才有的概念;如果从节点和哨兵节点发生故障,被哨兵主观下线后,不会再有后续的客观下线和故障转移操作。
定时任务: 每个哨兵节点维护了3个定时任务。定时任务的功能分别如下:
- 1.每10秒通过向主从节点发送info命令获取最新的主从结构
- 发现slave节点
- 确定主从关系
- 2.每2秒通过发布订阅功能获取其他哨兵节点的信息
- 交互节点的“看法”和自身情况
- 3.每1秒通过向其他节点发送ping命令进行心跳检测,判断是否下线(monitor)。
- 心跳检测,失败判断依据
选举领导者哨兵节点: 当主节点被判断客观下线以后,各个哨兵节点会进行协商,选举出一个领导者哨兵节点,并由该领导者节点对其进行故障转移操作。监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者。
故障转移: 选举出的领导者哨兵,开始进行故障转移操作,该操作大体可以分为3个步骤:
- 在从节点中选择新的主节点:选择的原则是,首先过滤掉不健康的从节点;然后选择优先级最高的从节点(由replica-priority指定);如果优先级无法区分,则选择复制偏移量最大的从节点;如果仍无法区分,则选择runid最小的从节点。
- 更新主从状态:通过slaveof no one命令,让选出来的从节点成为主节点;并通过slaveof命令让其他节点成为其从节点。
- 对已经下线的主节点保持关注,当节点重新上线后设置为新的主节点的从节点
实践建议
哨兵节点的数量应不止一个。一方面增加哨兵节点的冗余,避免哨兵本身成为高可用的瓶颈;另一方面减少对下线的误判。此外,这些不同的哨兵节点应部署在不同的物理机上。
哨兵节点的数量应该是奇数,便于哨兵通过投票做出“决策”:领导者选举的决策、客观下线的决策等。
各个哨兵节点的配置应一致,包括硬件、参数等;此外应保证时间准确、一致。
哨兵模式的优缺点
优点
在主从复制的基础上,哨兵引入了主节点的自动故障转移,进一步提高了Redis的高可用性。
缺点
哨兵无法对从节点进行自动故障转移,在读写分离场景下,从节点故障会导致读服务不可用,需要我们对从节点做额外的监控、切换操作。此外,哨兵仍然没有解决写操作无法负载均衡、及存储能力受到单机限制的问题。