HashMap之扩容(三)
HashMap的容量是有大小的,那随着put的Entity的增多,经过Hash算法出现冲突的概率越来越高,此时HashMap达到一定的饱和度,需要进行扩展它的长度,也就是Resize。决定是否发生Resize的因素有两个:
一是Capacity,即HashMap当前的长度。之前说过HashMap的长度是2的n次幂
二是LoadFactor 即HashMap的负载因子,默认值是0.75f。
当满足如下条件:
HashMap.size>=Capacity*LoadFactor
时,HashMap将会进行Resize操作。
Resize操作可以分为两步,扩容和Rehash
1、扩容
创建一个新的Entry空数组,长度是原HashMap Entry数组的2倍。
2、Rehash
遍历原HashMap的Entry数据,把所有的Entry重新Hash到新数组中,因为Entry经过Hash后的值与Entry数组的长度有关,所以需要Rehash。
之前文章有提到过,Hash公式为:index=HashCode(key)&(Capacity-1)
当Capacity=8时,key的HashCode是跟111做“与”运算。当数组长度变为16时,key的HashCode是与“1111”做“与”运算,结果肯定是不一样的。
ReHash的Java代码如下:
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry
while(null != e) {
Entry
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
当多线程并发时,HashMap是线程不安全的。
初始值如下图:
为了方便画图,假若初始长度是2,存了3个Entity
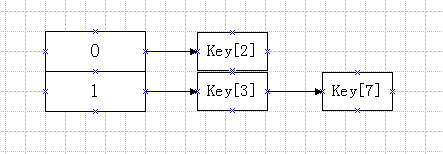
然后有两个线程分别对改HashMap进行扩容操作,线程1执行完Entry
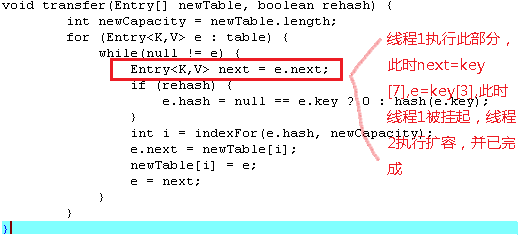
此时,扩容完如下图:
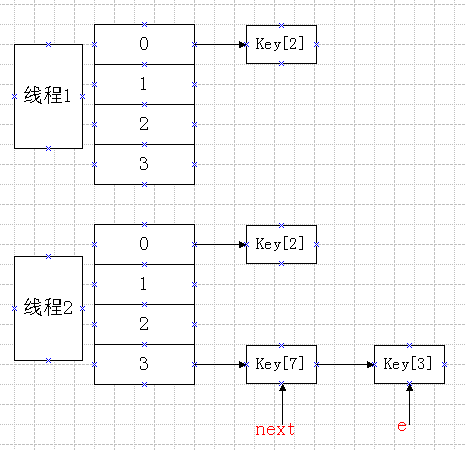
线程2结束,线程1被唤醒,继续进行执行下方代码
第一遍
此时e=key[3] ,e.next=key[7]
执行Entry
next=e.next=key[7];
执行 e.hash = null == e.key ? 0 : hash(e.key);得到
e.hash=hash(3);
执行int i = indexFor(e.hash, newCapacity);得到
i=3;
执行e.next = newTable[i];得到
e.next=key[3].next=null;
执行newTable[i] = e;得到
newTable[3] = e=key[3]
执行e = next;得到
e=next=key[7]
此时e=key[7],newTable[3]头结点为key[3],key[3].next=null,key[7].next=key[3];
第二遍
执行Entry
Entry
执行e.hash = null == e.key ? 0 : hash(e.key);得到
e.hash=hash(3)
执行int i = indexFor(e.hash, newCapacity);得到
i=3;
执行e.next = newTable[i];得到
e.next=newTable[3]=key[3];
执行newTable[i] = e;得到
newTable[3] = e=key[7]
执行e = next;得到
e=next=key[3]
此时e=key[3],newTable[3]头结点为key[7], key[7].next=key[3],e.next=key[3].next=null;
第三遍:
执行Entry
Entry
执行e.hash = null == e.key ? 0 : hash(e.key);得到
e.hash=hash(3)
执行int i = indexFor(e.hash, newCapacity);得到
i=3;
执行e.next = newTable[i];得到
e.next=newTable[3]=key[7];
执行newTable[i] = e;得到
newTable[3] = e=key[3]
执行e = next;得到
e=next=null;
第四遍
执行 while(null != e) 跳出循环
此时
e=null,e.next=null,
key[3].next=key[7]
key[7].next=key[3]
newtable[3]={key[3],key[7]}代码执行完后,会出现如下环
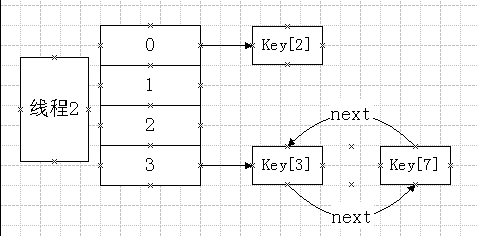
线程1结束后,如果有对HashMap进行查询操作。由于存在环,若查询的key值不在此HashMap,则进入死循环,一直在做查询操作。
由此延伸出另一个问题,即如何判断一个链表中是否有环存在?下一期讲解一下吧