java.util.HashMap深度学习
一、散列表初探:
同一问题可用不同算法解决,而一个算法的质量优劣将影响到算法乃至程序的效率。算法分析的目的在于选择合适算法和改进算法。一个算法的评价主要从时间复杂度和空间复杂度来考虑。
时间复杂度是指执行算法所需要的计算工作量;而空间复杂度是指执行这个算法所需要的内存空间。两者均体现在消耗计算机重要的两个资源方面。
数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端,数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找 时间复杂度小,为O(log2N);而链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。显然,现实生活中的数据并不会走在这两个极端,更多的是追求空间和时间的均衡。而哈希表((Hash table)的提出既满足了数据的查找方便,同时不占用太多的内容空间,使用也十分方便。
打个比方来说,所有的数据就好像许许多多的书本。如果这些书本是一本一本堆起来的,就好像链表或一样,整个数据会显得非常的无序和凌乱,在你找到自己需要的书之前,你要经历许多的查询过程;而如果你对所有的书本进行编号,并且把这些书本按次序进行排列的话,那么如果你要寻找的书本编号是n,那么经过二分查找,你很快就会找到自己需要的书本。但是如果你每一个种类的书本都不是很多,那么你就可以对这些书本进行归类,哪些是文学类,哪些是艺术类,哪些是工科的,哪些是理科的,你只要对这些书本进行简单的归类,那么寻找一本书也会变得非常简单,比如说如果你要找的书是计算机方面的书,那么你就会到工科一类当中去寻找,这样查找起来就会显得比较简单。
既然哈希表((Hash table)如此神通广大,那不得不揭开她的神秘面纱啦。
哈希表主要分为几个部分和功能:
散列(hash):散列函数:将数据的hashCode映射到散列表中的位置,此过程不需给出冲突解决方案。
好的散列函数的2个必备条件:1,快捷,在O(1)时间内运行;2,均匀的分布hashCode,填充概率相同。
冲突解决方案(collision solution):当一个新项散列到已经被占据的散列表中的位置时,被告之发生冲突,解决方案用于确定新项可以插入散列表中未被占据的位置。
解决冲突主要的主要方法:开放寻址方法(寻找另外的空位);封闭寻址方法(吊挂另一种数据结构)
一般采用后者挂链表的方式。
再散列(rehash):当数据的容量大于散列表的容量的容量时,那么创建一张指定新容量的表,再将原来表中的数据映射到新表中。
二、java.util.HashMap的源码解析
java.util.HashMap是很常见的类,实现了java.util.Map
HashMap主要是用数组来存储数据的,我们都知道它会对key进行哈希运算,
哈系运算会有重复的哈希值,对于哈希值的冲突,HashMap采用链表(挂链)来解决的。
HashMap结构如下图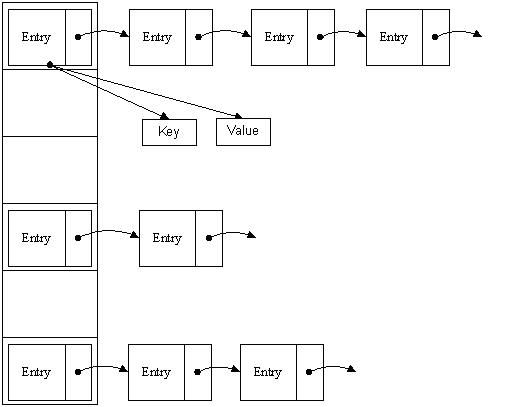
HashMap属性
在HashMap里的属性声明:
transient Entry[] table;//HashMap链表数组,数组的每一项存储一个链表
transient int size;//大小,2的幂,默认16
int threshold;//阈值上限 = 容量 * 负载因子
final float loadFactor;//负载因子,默认0.75
项的存储
Entry就是HashMap存储数据所用的类,相当于链表的节点。它拥有的属性如下
static class Entry implements Map.Entry {
final K key;
V value;
Entry next;
int hash;
}
看到next了吗?next就是为了哈希冲突而存在的。比如通过哈希运算,一个新元素应该在数组的第10个位置,但是第10个位置已经有Entry,那么好吧,将新加的元素也放到第10个位置,将第10个位置的原有Entry赋值给当前新加的 Entry的next属性。数组存储的是链表,链表是为了解决哈希冲突的。
添加项
HashMap的方法put是把一个
Java JDK中的源码:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
源码分析:
第一条语句是对关键字key的判断,假如为null,则将hashCode映射到table[0]中。
private V putForNullKey(V value) {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
第二条语句是散列函数hash,这个暂时放在后面分析。
第三条语句是得到hashCode之后将HashCode映射到表中的位置。
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
方法里面使用了按位取并&的操作符。例如h=25,length=16,把那么返回值就为9。
作用上相当于取模mod或者取余%,但是因为按位取并&不涉及除法,直接进入CPU运算,故能更快的得到结果、(前提为length是2的幂)
第四条语句是循环遍历表中的数据,检查传入的关键字key是否已经存在,假如已经存在,那么用传入的新值取代原关键字关联的值,并返回旧值。
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
关于判断条件if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
首先,key的hash code必须和映射位置的hash code相同,否则,无需进行下一步判断。
如果传入的值和旧值都为null,则使用==判断,否则使用equals检测。
第五条语句主要是addEntry方法(其他略过),将数据添加到链表中指定的节点位置
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
} resize(2 * table.length)是再散列过程,扩大为原来的2倍保证了是2的幂,后面介绍。
散列函数hash
通过hash方法的到key对象的哈希码。具体如下:
final int hash(Object k) {
int h = 0;
if (useAltHashing) {
if (k instanceof String) {//备用的hash函数,容量超过Integer.MAX_VALUE使用
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode();
//加入高位计算,解决在低位不变,高位变化情况下引起hash冲突严重问题
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
通过上述代码我们可以很深刻的理解到,通过key值的hashCode方法返回的hash码,来产生索引i。如果table[i]为null,则此处没有键值对,可以直接插入。如果table[i]!=null则此处有元素则上面的for循环就是存储的新的Entry元素。
再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) {
while(null != e) {
Entry next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
} tranfer方法将所有的元素重新哈希,由于新表的规模变大,所以映射到表中的位置就将变化,重新按位取并就得到新的位置。但在此过程由于关键字key关联的
搜索操作
搜索操作通过get方法来实现,并返回
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
**
* Returns the entry associated with the specified key in the
* HashMap. Returns null if the HashMap contains no mapping
* for the key.
*/
final Entry getEntry(Object key) {
int hash = (key == null) ? 0 : hash(key);
for (Entry e = table[indexFor(hash, table.length)]; e != null;e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
正确的使用HashMap:不要在并发场景中使用HashMap
HashMap是线程不安全的,如果被多个线程共享的操作,将会引发不可预知的问题。
扩容时,会引起链表的闭环,在get元素时(红色标记),就会无限循环,后果是cpu100%。
Hashtable简要分析
如上,HashMap线程不是安全的,而Hashtable使用线程同步,每一种方法都有synchronized关键字。这是与HashMap主要不同的一点。
同作为一种哈希表,不同的地方还体现在一下几个方面。
继承关系不同:Hashtable继承自Dictionary,而HashMap继承自AbstractMap,同实现Map接口。
public class Hashtable extends Dictionary implements Map, Cloneable, java.io.Serializable
public class HashMap extends AbstractMap
implements Map, Cloneable, Serializable
默认容量为11,扩容容量为原来的2倍+1;而不是HashMap那样满足2的指数幂。
newCapacity = (oldCapacity << 1) + 1;
映射函数不同:
int index = (hash & 0x7FFFFFFF) % tab.length;
不能传入空的key或者value:
if (value == null) {
throw new NullPointerException();
}
这样看来,Hashtable的确比HashMap历史要悠久...
自定义HashMap的实现。
在此就不贴代码了,其余的与系统设计的代码大同小异。主要修改了系统提供的hash函数
/**
* 哈希函数
*
* @param k
* @return
*/
private int hash(String k) {
int hash = 0;
hash ^= k.hashCode();
//将各个位置的字符对应的ASCII码相加
for (int i = 0; i < k.length(); ++i) {
hash += k.charAt(i);
}
//位运算,增加碰撞的几率
hash += (hash << 3);
hash ^= (hash >>> 7);
hash += (hash << 15);
return hash;
}
下面来测试一把,主要在哈希表新建项,下面是往表里面插入1000000项的测试结果
package com.HashMap20131029;
/**
* 自定义哈希表与系统哈希表测试类
* @author YangKang
*
*/
public class MapTest {
/**
* 主函数
*
* @param args
*/
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
java.util.HashMap hm = new java.util.HashMap();
for (int i = 0; i < 1000000; i++) {
hm.put("key" + i, "value" + i);
}
long endTime = System.currentTimeMillis();
System.out.println("系统提供的hashmap所花时间:" + (endTime - startTime));
long startTime2 = System.currentTimeMillis();
MyHashMap myhm = new MyHashMap();
for (int i = 0; i < 1000000; i++) {
myhm.put("key" + i, "value" + i);
}
long endTime2 = System.currentTimeMillis();
System.out.println("自定义hashmap所花时间:" + (endTime2 - startTime2));
}
}
/** log output
*系统提供的hashmap所花时间:2384
*自定义hashmap所花时间:1378
*/
其实测试添加100项的时候,java sdk提供的HashMap还是占明显优势的。
这告诉我们成功是有先决条件的
源代码打包已经上传:http://pan.baidu.com/share/link?shareid=2333258039&uk=219034104
希望大家多多支持和指正。