chapter17 -- 容器的深入研究(Collection)
基本内容
- Collection
1 Collection
Collection接口提供的方法不多,我整理成了一个表格。
| 方法名 | 说明 |
|---|---|
| int size() | 返回此 collection 中的元素数 |
| boolean isEmpty() | 如果此 collection 不包含元素,则返回 true |
| Iterator iterator() | 返回在此 collection 的元素上进行迭代的迭代器 |
| Object[] toArray() | 返回包含此 collection 中所有元素的数组 |
| T[] toArray(T[] a) | 返回包含此 collection 中所有元素的数组;返回数组的运行时类型与指定数组的运行时类型相同 |
| boolean add(E e) | 确保此collection包含指定的元素 |
| boolean addAll(Collection c) | 将指定collection中的所有元素都添加到此 collection 中 |
| void clear() | 移除此 collection 中的所有元素 |
| boolean retainAll(Collection c) | 仅保留此 collection 中那些也包含在指定 collection 的元素 |
| boolean removeAll(Collection c) | 移除此 collection 中那些也包含在指定 collection 中的所有元素 |
| boolean remove(Object o) | 从此 collection 中移除指定元素的单个实例,如果存在的话 |
| boolean contains(Object o) | 如果此 collection 包含指定的元素,则返回 true |
| boolean containsAll(Collection c) | 如果此 collection 包含指定 collection 中的所有元素,则返回 true |
我之前在【CoreJava】常用容器中对ArrayList,LinkedList,HashSet,HashMap和HashTable做过简单的介绍。在这里,我会对之前没有介绍过的内容进行一些补充。
1.1 List
List接口继承自Collection接口,有两个常用的实现类LinkedList和ArrayList。
List的常规用法其实很简单,add添加元素,get取出元素,remove删除制动元素,可以使用Iterator进行遍历,或者使用for(foreach)语句。
1.1.1 LinkedList
LinkedList数据结构
如果学习过数据结构的话,对链表应该是也有一定的印象的。链表最重要的特点就是元素存储在独立的节点中,每个节点都存储着下一个节点的引用。
LinkedList就是Java中的链表(Java中的链表都是双向链表,每个节点都保存了前一个和后一个节点的引用)。
通过一张图说明下LinkedList的存储方式。

这样我们插入和删除元素只需要付出很小的代价了。

从图中可以看出,我们希望在Link1和Link2之间插入Link3,我们只需要修改Link1的next引用和Link2的previous引用就可以了。但是这样的存储方式也会使得LinkedList的读取速度较慢,每次都需要读取next引用才能得知存储在LinkedList中的下一个元素,然后再去读取data中的内容。
LinkedList源码分析
我们来看下LinkedList的构造器:
public LinkedList() {}
public LinkedList(Collection c) {
this();
addAll(c);
}
一个无参构造器,没有任何内容。
一个有参构造器,传入了Collection对象,并调用了addAll方法。
在addAll的源码中,我添加了注释,方便大家去分析。
transient int size = 0;//LinkedList的节点个数
transient Node first;//LinkedList第一个节点
transient Node last;//LinkedList最后一个节点
public boolean addAll(Collection c) {
return addAll(size, c);
}
public boolean addAll(int index, Collection c) {
//检查索引是否在合理范围
checkPositionIndex(index);
//将Collection转换为Object数组
Object[] a = c.toArray();
int numNew = a.length;
//如果数组为空,返回false
if (numNew == 0)
return false;
Node pred, succ;
if (index == size) {//用来在index=size时添加Collection(在LinkedList末尾处或构造器调用时)
succ = null;
pred = last;
} else {//用来在指定位置插入Collection
succ = node(index);
pred = succ.prev;
}
//遍历Object数组,并将元素添加到Node中
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node newNode = new Node<>(pred, e, null);
if (pred == null)//如果开始为空,则开始的位置指向第一个元素
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {//将最后一个节点赋值给last
last = pred;
} else {//更新节点的前后引用
pred.next = succ;
succ.prev = pred;
}
//计算节点个数
size += numNew;
modCount++;
return true;
}
Node是LinkedList的内部私有类
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
分析过源码过后,相信大家基本就可以明白了LinkedList的内部实现方式了。由此,我们也可以联想到,LinkedList在指定位置的插入和删除,其实都是通过更新节点的前后引用来实现的。大家可以动手写一个LinkedList,并完成指定位置的插入和删除。
1.1.2 ArrayList
ArrayList数据结构
ArrayList的内部是使用数组实现的,数组是线性存储方式,区别于链表,是一种连续的存储方式。
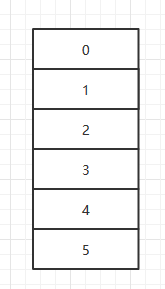
这样的存储方式,可以提升访问速度。但是,当你希望在中间插入和删除元素的时候就会消耗大量资源。
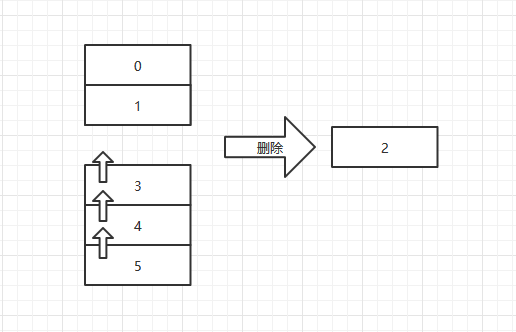
可以看到,我们希望删除下标为2的元素,需要将后续所有的元素都向前移动。如果ArrayList足够大,这会造成大量的资源浪费。
说到ArrayList的存储,我们就必须要讨论扩容问题。在创建ArryList的时候,JVM会分配一块连续的内存给我们使用。当我们再次向ArrayList中添加元素时,可能这一块内存是不够用的,此时,JVM会再次分配一块连续的内存给我们。而实际上,ArryList存储的区域,并不是一整块完全连续的内存。
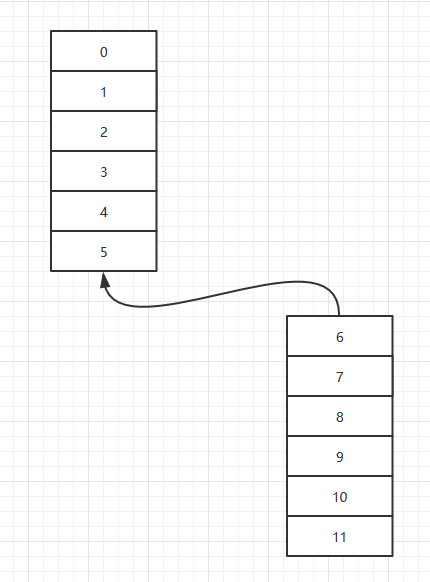
对比LinkedList,如果你只是想取出数据并遍历,那么你应该使用ArrayList,如果你需要频繁的插入和删除操作,那么你应该使用LinkedList。
ArrayList源码分析
我们还是通过构造器分析ArryList的源码,不过在此处我会通过add方法去分析ArrayList的扩容机制。
private static final int DEFAULT_CAPACITY = 10;
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
this.elementData = EMPTY_ELEMENTDATA;
}
}
ArrayList包含三个构造方法,一个无参构造方法和两个有参构造方法。实际上,三个构造器都很好理解,但是我们需要理解以下几个变量的作用。
private static final int DEFAULT_CAPACITY = 10;//默认初始容量
private static final Object[] EMPTY_ELEMENTDATA = {};//空数组,在构造空ArrayList的时候使用
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;//用来存储数据的数组
private int size;//ArrayList中元素的个数
其中DEFAULTCAPACITY_EMPTY_ELEMENTDATA是在Java 1.8中加入的,和EMPTY_ELEMENTDATA作用基本是一样的。以下是官方源码中的注释,最后一句话的大概意思就是,我们将它与EMPTY_ELEMENTDATA区分开来,以了解在添加第一个元素时要膨胀多少。
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
构造器是非常简单了,我们来看下ArrayList的add方法。
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1);
System.arraycopy(elementData, index, elementData, index + 1,size - index);
elementData[index] = element;
size++;
}
可以看到,ArrayList插入元素是很简单的,不过,我们观察到,两个add方法都有使用到ensureCapacityInternal,那么这个方法是不是用来扩容的呢?我们继续来看。
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
//如果数组是空数组,比较默认大小和最小需求,返回较大的值;否则返回最小需求。
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
//比较最小需求和当前大小,如果最小需求较大,则进行扩容操作
private void ensureExplicitCapacity(int minCapacity) {
modCount++;//记录修改次数
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
//扩容操作
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);//默认扩容
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)//超出ArrayList最大值
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0)
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE;
}
可以看到,真正起到扩容操作的是**private void grow(int minCapacity)**这个方法。
一般来说,我们可以忽略超出ArrayList最大值的操作,因为 MAX_ARRAY_SIZE 太了大,大概是21亿多。而且 private static int hugeCapacity(int minCapacity) 方法仅仅能算是最后的挣扎了,因为
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
可能有些同学对>>操作不是很了解,简单的说下计算规则:右移操作是针对二进制位的操作,把数字向右移动一位,右边抛弃,左边补0(左移正好反过来)。
以默认大小10(1010)来计算
1010 + 1010 >> 1 = 1111
1111 + 1111 >> 1 = 10110;
10110 + 10110 >> 1 = 100001;
这样算来起来newCapacity ≈ 1.5 X oldCapacity。
1.2 Set
Set接口继承自Collection,有三个常用的实现类HashSet,LinkedHashSet和TreeSet。
Set的用法和List类似,但是有一个很重要的特点,就是Set中无法存储相同的数据,这个相同不是单指字面值相同。
1.2.1 HashSet和LinkedHashSet
HashSet:
HashSet是基于HashMap实现,底层使用HashMap存储数据。所以各种添加,删除操作其实也是对HashMap的操作。
我们看下源码中是怎么做的
private transient HashMap map;
/**
* Constructs a new, empty set; the backing HashMap instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
以上是四个public构造器,可以看到,都是用HashMap来实现的。第一个构造器上的注释大家可以看下,HashSet的默认大小是16,加载因子是0.75。
HashSet还包含了一个包访问权限的构造器,这个构造器使用LinkedHashMap来存储数据,是用来支持LinkedHashSet的,这个暂且不说。
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
再来看一下add方法。
//定义了一个Object对象
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
传入的对象当做map的key,倒是利用了Map的key不能重复的特点,然后使用PRESENT当做Value。其实在这里,我们可以回想下关于HashMap,添加重复key值得的情况,HashMap在添加两个相同的key的时候,新添加的value会覆盖旧的value,但是key是不产生任何变化的。也就是说,你在HashSet中添加任何重复的对象时,其实都是PRESENT在已知覆盖来覆盖区,但是谁要管一个没有实际意义的PRESENT呢?
最后再来看下iterator方法是怎么返回迭代器的。
public Iterator iterator() {
return map.keySet().iterator();
}
恩,Map和Set真是你中有我,我中有你啊…
LinkedHashSet:
我们先来看LinkedHashSet类的声明。
public class LinkedHashSet extends HashSet implements Set, Cloneable, java.io.Serializable
LinkedHashSet是HashSet的子类,也没有自己特别的方法。并且构造器是直接使用super调用HashSet中包权限构造器。
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
我们在上一小节可以看到,LinkedHashSet使用的构造器底层是用LinkedHashMap来存储数据的,这么做是为了维护LinkedHashSet插入元素的顺序。
1.2.2 TreeSet
TreeSet是基于TreeMap实现,底层使用TreeMap存储数据。
TreeSet有一个区别于HashSet的特点,就是存储于TreeSet中的元素是有序的。但是这个顺序又区别于LinkedHashSet,并非元素的插入顺序,而是使用Comparator比较后的顺序。
我们来看下TreeSet的构造器
public TreeSet() {
this(new TreeMap());
}
public TreeSet(Comparator comparator) {//自定义Comparator
this(new TreeMap<>(comparator));
}
public TreeSet(Collection c) {
this();
addAll(c);
}
public TreeSet(SortedSet s) {
this(s.comparator());
addAll(s);
}
private transient NavigableMap m;
TreeSet(NavigableMap m) {//TreeMap是NavigableMap的实现类
this.m = m;
}
同样还是四个public权限构造器,和一个包权限构造器。底层使用TreeMap存储数据,所以TreeSet的有序实际上是通过TreeMap来实现的。如果不熟悉TreeMap的话,明天我会去分析Map及实现类的。
注意:
在Java 1.8之后,Iterator也有了一个兄弟 – Spliterator(可分割迭代器)。是用来并行遍历元素的迭代器,在Java的容器(其实我是习惯叫集合框架的)中都实现了Spliterator,感兴趣的同学可以自己去看下Spliterator的文档和源码进行学习。
关于Collection接口就说到这里吧,本来是想把Queue和Stack也放在一起说的。但是,我写完List和Set之后,发现写了挺多了,这些就放进【CoreJava】这个系列中吧,有时间再写。最最最重要的是也该去拯救海拉鲁的人民了。
欢迎关注个人公众号,搜索:公子照谏或者QCzhaojian
也可以通过扫描二维码关注。
