zookeeper那些事
一、 ZooKeeper 简介
ZooKeeper 是一个开源的分布式协调服务,ZooKeeper框架最初是在“Yahoo!"上构建的,用于以简单而稳健的方式访问他们的应用程序。 后来,Apache ZooKeeper成为Hadoop,HBase和其他分布式框架使用的有组织服务的标准。 例如,Apache HBase使用ZooKeeper跟踪分布式数据的状态。
二、 ZooKeeper 的作用
1.1 配置管理
在我们的应用中除了代码外,还有一些就是各种配置。比如数据库连接等。一般我们都 是使用配置文件的方式,在代码中引入这些配置文件。当我们只有一种配置,只有一台服务 器,并且不经常修改的时候,使用配置文件是一个很好的做法,但是如果我们配置非常多, 有很多服务器都需要这个配置,这时使用配置文件就不是个好主意了。这个时候往往需要寻 找一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣的 都可以获得变更。Zookeeper 就是这种服务,它使用 Zab 这种一致性协议来提供一致性。现 在有很多开源项目使用 Zookeeper 来维护配置,比如在 HBase 中,客户端就是连接一个 Zookeeper,获得必要的 HBase 集群的配置信息,然后才可以进一步操作。还有在开源的消 息队列 Kafka 中,也使用 Zookeeper来维护broker的信息。在 Alibaba开源的 SOA 框架Dubbo 中也广泛的使用 Zookeeper 管理一些配置来实现服务治理。
1.2 名字服务
名字服务这个就很好理解了。比如为了通过网络访问一个系统,我们得知道对方的 IP 地址,但是 IP 地址对人非常不友好,这个时候我们就需要使用域名来访问。但是计算机是 不能是域名的。怎么办呢?如果我们每台机器里都备有一份域名到 IP 地址的映射,这个倒 是能解决一部分问题,但是如果域名对应的 IP 发生变化了又该怎么办呢?于是我们有了 DNS 这个东西。我们只需要访问一个大家熟知的(known)的点,它就会告诉你这个域名对应 的 IP 是什么。在我们的应用中也会存在很多这类问题,特别是在我们的服务特别多的时候, 如果我们在本地保存服务的地址的时候将非常不方便,但是如果我们只需要访问一个大家都 熟知的访问点,这里提供统一的入口,那么维护起来将方便得多了。
1.3 分布式锁
其实在第一篇文章中已经介绍了 Zookeeper 是一个分布式协调服务。这样我们就可以利 用 Zookeeper 来协调多个分布式进程之间的活动。比如在一个分布式环境中,为了提高可靠 性,我们的集群的每台服务器上都部署着同样的服务。但是,一件事情如果集群中的每个服 务器都进行的话,那相互之间就要协调,编程起来将非常复杂。而如果我们只让一个服务进 行操作,那又存在单点。通常还有一种做法就是使用分布式锁,在某个时刻只让一个服务去干活,当这台服务出问题的时候锁释放,立即 fail over 到另外的服务。这在很多分布式系统 中都是这么做,这种设计有一个更好听的名字叫 Leader Election(leader 选举)。比如 HBase 的 Master 就是采用这种机制。但要注意的是分布式锁跟同一个进程的锁还是有区别的,所 以使用的时候要比同一个进程里的锁更谨慎的使用。
1.4 集群管理
在分布式的集群中,经常会由于各种原因,比如硬件故障,软件故障,网络问题,有些 节点会进进出出。有新的节点加入进来,也有老的节点退出集群。这个时候,集群中其他机 器需要感知到这种变化,然后根据这种变化做出对应的决策。比如我们是一个分布式存储系 统,有一个中央控制节点负责存储的分配,当有新的存储进来的时候我们要根据现在集群目 前的状态来分配存储节点。这个时候我们就需要动态感知到集群目前的状态。还有,比如一 个分布式的 SOA 架构中,服务是一个集群提供的,当消费者访问某个服务时,就需要采用 某种机制发现现在有哪些节点可以提供该服务(这也称之为服务发现,比如 Alibaba 开源的 SOA 框架 Dubbo 就采用了 Zookeeper 作为服务发现的底层机制)。还有开源的 Kafka 队列就 采用了 Zookeeper 作为 Cosnumer 的上下线管理。
三、 ZooKeeper 特点
- 顺序一致性: 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
- 原子性: 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
- 单一系统映像 : 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
- 可靠性: 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
四、 Zookeeper 的存储结构
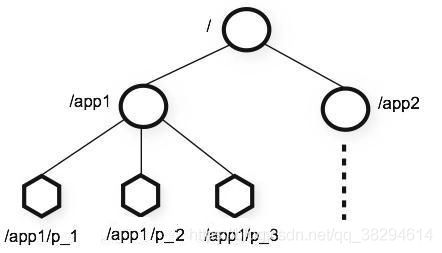
1 Znode
在 Zookeeper 中,znode 是一个跟 Unix 文件系统路径相似的节点,可以往这个节点存储 或获取数据。 Zookeeper 底层是一套数据结构。这个存储结构是一个树形结构,其上的每一个节点, 我们称之为“znode” zookeeper 中的数据是按照“树”结构进行存储的。而且 znode 节点还分为 4 中不同的类 型。 每一个 znode 默认能够存储 1MB 的数据(对于记录状态性质的数据来说,够了) 可以使用 zkCli 命令,登录到 zookeeper 上,并通过 ls、create、delete、get、set 等命令 操作这些 znode 节点
2 Znode 节点类型
(1)PERSISTENT 持久化节点: 所谓持久节点,是指在节点创建后,就一直存在,直到 有删除操作来主动清除这个节点。否则不会因为创建该节点的客户端会话失效而消失。
(2)PERSISTENT_SEQUENTIAL 持久顺序节点:这类节点的基本特性和上面的节点类 型是一致的。额外的特性是,在 ZK 中,每个父节点会为他的第一级子节点维护一份时序, 会记录每个子节点创建的先后顺序。基于这个特性,在创建子节点的时候,可以设置这个属 性,那么在创建节点过程中,ZK 会自动为给定节点名加上一个数字后缀,作为新的节点名。 这个数字后缀的范围是整型的最大值。 在创建节点的时候只需要传入节点 “/test_”,这样 之后,zookeeper 自动会给”test_”后面补充数字。
(3)EPHEMERAL 临时节点:和持久节点不同的是,临时节点的生命周期和客户端会 话绑定。也就是说,如果客户端会话失效,那么这个节点就会自动被清除掉。注意,这里提 到的是会话失效,而非连接断开。另外,在临时节点下面不能创建子节点。 这里还要注意一件事,就是当你客户端会话失效后,所产生的节点也不是一下子就消失 了,也要过一段时间,大概是 10 秒以内,可以试一下,本机操作生成节点,在服务器端用 命令来查看当前的节点数目,你会发现客户端已经 stop,但是产生的节点还在。
(4) EPHEMERAL_SEQUENTIAL 临时自动编号节点:此节点是属于临时节点,不过带 有顺序,客户端会话结束节点就消失。
五、 ZooKeeper 设计目标
1. 简单的数据模型
ZooKeeper 允许分布式进程通过共享的层次结构命名空间进行相互协调,这与标准文件系统类似。 名称空间由 ZooKeeper 中的数据寄存器组成 - 称为znode,这些类似于文件和目录。 与为存储设计的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟。
2. 可构建集群
为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么zookeeper本身仍然是可用的。 客户端在使用 ZooKeeper 时,需要知道集群机器列表,通过与集群中的某一台机器建立 TCP 连接来使用服务,客户端使用这个TCP链接来发送请求、获取结果、获取监听事件以及发送心跳包。如果这个连接异常断开了,客户端可以连接到另外的机器上。
ZooKeeper 官方提供的架构图:

上图中每一个Server代表一个安装Zookeeper服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 Zab 协议(Zookeeper Atomic Broadcast)来保持数据的一致性。
3. 顺序访问
对于来自客户端的每个更新请求,ZooKeeper 都会分配一个全局唯一的递增编号,这个编号反应了所有事务操作的先后顺序,应用程序可以使用 ZooKeeper 这个特性来实现更高层次的同步原语。 这个编号也叫做时间戳——zxid(Zookeeper Transaction Id)
4. 高性能
ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)
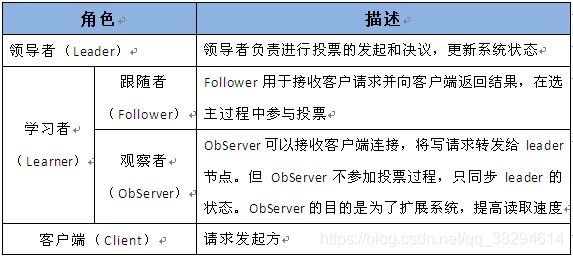
六、Zookeeper 集群中的角色
最典型集群模式: Master/Slave 模式(主备模式)。在这种模式中,通常 Master服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三种角色

七、Watcher机制
1.概述
ZK中引入Watcher机制来实现分布式的通知功能,ZK允许客户端向服务端注册一个Watcher监听,当服务点的的指定事件触发监听时,那么服务端就会向客户端发送事件通知,以便客户端完成逻辑操作(即客户端向服务端注册监听,并将watcher对象存在客户端的Watchermanager中,服务端触发事件后,向客户端发送通知,客户端收到通知后从wacherManager中取出对象来执行回调逻辑)
2.特性
a.一次性:一旦一个watcher被触发,ZK都会将其从相应的的存储中移除,所以watcher是需要每注册一次,才可触发一次。
b.ZK客户端串行执行:客户端watcher回调过程是一个串行同步的过程
c.轻量:watcher数据结构中只包含:通知状态、事件类型和节点路径
3.watcher类型
data watches:getData()和exists()以及create()
child watches:getChildren()
4.Watch事件类型
ZOO_CREATED_EVENT:节点创建事件,需要watch一个不存在的节点,当节点被创建时触发,此watch通过zoo_exists()设置
ZOO_DELETED_EVENT:节点删除事件,此watch通过zoo_exists()或zoo_get()设置
ZOO_CHANGED_EVENT:节点数据改变事件,此watch通过zoo_exists()或zoo_get()设置
ZOO_CHILD_EVENT:子节点列表改变事件,此watch通过zoo_get_children()或zoo_get_children2()设置
ZOO_SESSION_EVENT:会话失效事件,客户端与服务端断开或重连时触发
ZOO_NOTWATCHING_EVENT:watch移除事件,服务端出于某些原因不再为客户端watch节点时
八、Zookeeper的客户端API:
- create
在给定的path上创建节点,这个path就像文件系统的路径,比如/myapp/data/1,在创建节点的时候还可以指定节点的类型:是永久节 点,永久顺序节点,临时节点,临时顺序节点。这个节点类型是非常强大的。永久节点一经创建就永久保留了,就像我们在文件系统上创建一个普通文件,这个文件 的生命周期跟创建它的应用没有任何关系。而临时节点呢,当创建这个临时节点的应用与zookeeper之间的会话过期之后就会被zookeeper自动删 除了。这个特性是实现很多功能的关键。比如我们做集群感知,我们的应用启动的时候将自己的ip地址作为临时节点创建在某个节点下面。当我们的应用因为某些 原因,比如网络断掉或者宕机,它与zookeeper的会话就会过期了,过期后这个临时节点就删除了。这样我们就可以通过这个特性来感知到我们的服务的集 群有哪些机器是活者的。那么顺序节点又是什么呢。一般,如果我们在指定的path上创建节点,如果这个节点已经被创建了,则会抛出一个 NodeExistsException的异常。如果我们在指定的路径上创建顺序节点,则Zookeeper会自动的在我们给定的path上加上一个顺序 编号。这个特性就是实现分布式锁的关键。假设我们有几个节点共享一个资源,我们这几个节点都想争用这个资源,那我们就都向某个路径创建临时顺序节点。然后 顺序最小的那个就获得锁,然后如果某个节点释放了锁,那顺序第二小的那个就获得锁,以此类推,这样一个分布式的公平锁就实现了。
除此之外,每个节点上还可以保存一些数据。 - delete 删除给定节点。删除节点的时候还可以给定一个version,只有路径和version都匹配的时候节点才会被删除。有了这个version在分布式环境 种我们就可以用乐观锁的方式来确保一致性。比如我们先读取一下节点,获得了节点的version,然后删除,如果删除成功了则说明在这之间没有人操作过这 个节点,否则就是并发冲突了。
- exists 这个节点会返回一个Stat对象,如果给定的path不存在的话则返回null。这个方法有一个关键参数,可以提供一个Watcher对象。 Wathcer是Zookeeper强大功能的源泉。Watcher就是一个事件处理器,一个回调。比如这个exists方法,调用后,如果别人对这个 path上的节点进行操作,比如创建,删除或设置数据,这个Wather都会接收到对应的通知。
- setData/getData 设置或获取节点的数据,getData也可以设置Watcher
- getChildren 获取子节点,可以设置Watcher
- sync zookeeper是一个集群,创建节点的时候只要半数以上的节点确认就认为是创建成功了,但是如果读取的时候正好读取到一个落后的节点上,那就有可能读取到旧的数据,这个时候可以执行一个sync操作,这个操作可以确保读取到最新的数据。
zookeeper的client api基本上介绍完了。zookeeper强大的功能都是通过这些API来实现的,zookeeper通过一个简单的文件系统数据模型对外提供服务。通过临时节点,Watcher等手段我们可以实现一些在分布式环境种很难做到的事情。