1、官网翻译:
路由和过滤器:Zuul(Router andFilter: Zuul)
Routing in an integral part of a microservice architecture. For example, / may be mapped toyour web application, /api/users is mapped to theuser service and /api/shop is mapped to theshop service. Zuul is a JVM based router and server side load balancerby Netflix.
路由是微服务架构中不可或缺的一部分。比如,/ 可能需要映射到你的web应用, /api/users 映射到用户服务, /api/shop 映射到商城服务. Zuul是Netflix出品的一个基于JVM路由和服务端的负载均衡器。
Netflix uses Zuul for the following:
· Authentication
· Insights
· Stress Testing
· Canary Testing
· Dynamic Routing
· Service Migration
· Load Shedding
· Security
· Static Responsehandling
· Active/Activetraffic management
· 认证
· Insights
· 压力测试
· 金丝雀测试
· 动态路由
· 服务迁移
· 负载削减
· 安全
· 静态响应处理
· 主动/主动交换管理
Zuul’s rule engine allows rules and filters to be written in essentiallyany JVM language, with built in support for Java and Groovy.
Zuul的规则引擎允许通过任何JVM语言来编写规则和过滤器, 支持基于Java和Groovy的构建。
| The configuration property zuul.max.host.connections has been replaced by two new properties, zuul.host.maxTotalConnections and zuul.host.maxPerRouteConnections which default to 200 and 20 respectively. |
|
| 配置属性 zuul.max.host.connections 已经被两个新的配置属性替代, zuul.host.maxTotalConnections 和 zuul.host.maxPerRouteConnections, 默认值分别是200和20. |
|
嵌入Zuul反向代理(Embedded Zuul Reverse Proxy)
Spring Cloud has created an embedded Zuul proxy to ease the development ofa very common use case where a UI application wants to proxy calls to one ormore back end services. This feature is useful for a user interface to proxy tothe backend services it requires, avoiding the need to manage CORS andauthentication concerns independently for all the backends.
Spring Cloud创建了一个嵌入式Zuul代理来缓和急需一个UI应用程序来代理调用一个或多个后端服务的通用需求, 这个功能对于代理前端需要访问的后端服务非常有用, 避免了所有后端服务需要关心管理CORS和认证的问题.
To enable it, annotate a Spring Boot main class with @EnableZuulProxy, and this forwards local calls to the appropriate service. By convention,a service with the ID "users", will receive requests from the proxylocated at /users (with the prefixstripped). The proxy uses Ribbon to locate an instance to forward to viadiscovery, and all requests are executed in a hystrix command, so failures willshow up in Hystrix metrics, and once the circuit is open the proxy will not tryto contact the service.
在Spring Boot主函数上通过注解 @EnableZuulProxy 来开启, 这样可以让本地的请求转发到适当的服务. 按照约定, 一个ID为"users"的服务会收到 /users 请求路径的代理请求(前缀会被剥离). Zuul使用Ribbon定位服务注册中的实例, 并且所有的请求都在hystrix的command中执行, 所以失败信息将会展现在Hystrix metrics中, 并且一旦断路器打开, 代理请求将不会尝试去链接服务.
| the Zuul starter does not include a discovery client, so for routes based on service IDs you need to provide one of those on the classpath as well (e.g. Eureka is one choice). |
| Zuul starter没有包含服务发现的客户端, 所以对于路由你需要在classpath中提供一个根据service IDs做服务发现的服务.(例如, eureka是一个不错的选择) |
To skip having a service automatically added, set zuul.ignored-services to a list ofservice id patterns. If a service matches a pattern that is ignored, but alsoincluded in the explicitly configured routes map, then it will be unignored.Example:
在服务ID表达式列表中设置 zuul.ignored-services, 可以忽略已经添加的服务. 如果一个服务匹配表达式, 则将会被忽略, 但是对于明确配置在路由匹配中的, 将不会被忽略, 例如:
application.yml
zuul:
ignoredServices: '*'
routes:
users: /myusers/**
In this example, all services are ignored except "users".
在这个例子中, 除了"users", 其他所有服务都被忽略了.
To augment or change the proxy routes, you can add external configurationlike the following:
增加或改变代理路由, 你可以添加类似下面的外部配置:
application.yml
zuul:
routes:
users: /myusers/**
This means that http calls to "/myusers" get forwarded to the"users" service (for example "/myusers/101" is forwarded to"/101").
这个意味着http请求"/myusers"将被转发到"users"服务(比如 "/myusers/101" 将跳转到 "/101")
To get more fine-grained control over a route you can specify the path andthe serviceId independently:
为了更细致的控制一个路由, 你可以直接配置路径和服务ID:
application.yml
zuul:
routes:
users:
path: /myusers/**
serviceId: users_service
This means that http calls to "/myusers" get forwarded to the"users_service" service. The route has to have a "path"which can be specified as an ant-style pattern, so "/myusers/*" onlymatches one level, but "/myusers/**" matches hierarchically.
这个意味着HTTP调用"/myusers"被转发到"users_service"服务. 路由必须配置一个可以被指定为ant风格表达式的"path", 所以“/myusers/*”只能匹配一个层级, 但"/myusers/**"可以匹配多级.
The location of the backend can be specified as either a"serviceId" (for a service from discovery) or a "url" (fora physical location), e.g.
后端的配置既可以是"serviceId"(对于服务发现中的服务而言), 也可以是"url"(对于物理地址), 例如:
application.yml
zuul:
routes:
users:
path: /myusers/**
url:http://example.com/users_service
These simple url-routes don’t get executed as a HystrixCommand nor can youloadbalance multiple URLs with Ribbon. To achieve this, specify a service-routeand configure a Ribbon client for the serviceId (this currently requiresdisabling Eureka support in Ribbon: see above for more information), e.g.
这个简单的"url-routes"不会按照 HystrixCommand 执行, 也无法通过Ribbon负载均衡多个URLs. 为了实现这一指定服务路由和配置Ribbon客户端(这个必须在Ribbon中禁用Eureka: 具体参考更多信息), 例如:
application.yml
zuul:
routes:
users:
path: /myusers/**
serviceId: users
ribbon:
eureka:
enabled: false
users:
ribbon:
listOfServers:example.com,google.com
You can provide convention between serviceId and routes using regexmapper.It uses regular expression named groups to extract variables from serviceId andinject them into a route pattern.
你可以使用regexmapper提供serviceId和routes之间的绑定. 它使用正则表达式组来从serviceId提取变量, 然后注入到路由表达式中.
ApplicationConfiguration.java
@Bean
public PatternServiceRouteMapper serviceRouteMapper() {
return newPatternServiceRouteMapper(
"(?
"${version}/${name}");
}
This means that a serviceId "myusers-v1" will be mapped to route"/v1/myusers/**". Any regular expression is accepted but all namedgroups must be present in both servicePattern and routePattern. If servicePatterndoes not match a serviceId, the default behavior is used. In the example above,a serviceId "myusers" will be mapped to route "/myusers/**"(no version detected) This feature is disable by default and only applies to discoveredservices.
这个意思是说"myusers-v1"将会匹配路由"/v1/myusers/**". 任何正则表达式都可以, 但是所有组必须存在于servicePattern和routePattern之中. 如果servicePattern不匹配服务ID,则使用默认行为. 在上面例子中,一个服务ID为“myusers”将被映射到路径“/ myusers/**”(没有版本被检测到),这个功能默认是关闭的,并且仅适用于服务注册的服务。
To add a prefix to all mappings, set zuul.prefix to a value, such as /api. The proxy prefixis stripped from the request before the request is forwarded by default (switchthis behaviour off with zuul.stripPrefix=false). You can alsoswitch off the stripping of the service-specific prefix from individual routes,e.g.
设置 zuul.prefix 可以为所有的匹配增加前缀, 例如 /api . 代理前缀默认会从请求路径中移除(通过 zuul.stripPrefix=false可以关闭这个功能). 你也可以在指定服务中关闭这个功能, 例如:
application.yml
zuul:
routes:
users:
path: /myusers/**
stripPrefix: false
In this example, requests to "/myusers/101" will be forwarded to"/myusers/101" on the "users" service.
在这个例子中, 请求"/myusers/101"将被跳转到"users"服务的"/myusers/101"上.
The zuul.routes entries actuallybind to an object of type ZuulProperties. If you look at the properties ofthat object you will see that it also has a "retryable" flag. Setthat flag to "true" to have the Ribbon client automatically retryfailed requests (and if you need to you can modify the parameters of the retryoperations using the Ribbon client configuration).
zuul.routes 实际上绑定到类型为 ZuulProperties 的对象上. 如果你查看这个对象你会发现一个叫"retryable"的字段, 设置为"true"会使Ribbon客户端自动在失败时重试(如果你需要修改重试参数, 直接使用Ribbon客户端的配置)
The X-Forwarded-Host header is added tothe forwarded requests by default. To turn it off set zuul.addProxyHeaders = false. The prefix path is stripped by default, and the request to the backendpicks up a header "X-Forwarded-Prefix" ("/myusers" in theexamples above).
X-Forwarded-Host 请求头默认在跳转时添加. 通过设置 zuul.addProxyHeaders = false 关闭它. 前缀路径默认剥离, 并且对于后端的请求通过请求头"X-Forwarded-Prefix"获取(上面的例子中是"/myusers")
An application with @EnableZuulProxy could act as a standalone server if you set a default route("/"), for example zuul.route.home: / would route all traffic (i.e. "/**") tothe "home" service.
通过 @EnableZuulProxy 应用程序可以作为一个独立的服务, 如果你想设置一个默认路由("/"), 比如 zuul.route.home: / 将路由所有的请求(例如: "/**")到"home"服务.
If more fine-grained ignoring is needed, you can specify specific patternsto ignore. These patterns are evaluated at the start of the route locationprocess, which means prefixes should be included in the pattern to warrant amatch. Ignored patterns span all services and supersede any other routespecification.
如果需要更细力度的忽略, 你可以指定特殊的表达式来配置忽略. 这些表达式从路由位置的头开始匹配, 意味着前缀应该被包括在匹配表达式中. 忽略表达式影响所有服务和取代任何路由的特殊配置.
application.yml
zuul:
ignoredPatterns: /**/admin/**
routes:
users: /myusers/**
This means that all calls such as "/myusers/101" will beforwarded to "/101" on the "users" service. But callsincluding "/admin/" will not resolve.
这个的意思是所有请求, 比如"/myusers/101"的请求会跳转到"users"服务的"/101", 但包含"/admin/"的请求将不被处理.
Cookies和敏感HTTP头(Cookies and Sensitive Headers)
It’s OK to share headers between services in the same system, but youprobably don’t want sensitive headers leaking downstream into external servers.You can specify a list of ignored headers as part of the route configuration.Cookies play a special role because they have well-defined semantics inbrowsers, and they are always to be treated as sensitive. If the consumer ofyour proxy is a browser, then cookies for downstream services also causeproblems for the user because they all get jumbled up (all downstream serviceslook like they come from the same place).
在同一个系统中服务间共享请求头是可行的, 但是你可能不想敏感的头信息泄露到内部系统的下游。 你可以在路由配置中指定一批忽略的请求头列表。 Cookies扮演了一个特殊的角色, 因为他们很好的被定义在浏览器中, 而且他们总是被认为是敏感的. 如果代理的客户端是浏览器, 则对于下游服务来说对用户, cookies会引起问题, 因为他们都混在一起。(所有下游服务看起来认为他们来自同一个地方)。
If you are careful with the design of your services, for example if onlyone of the downstream services sets cookies, then you might be able to let themflow from the backend all the way up to the caller. Also, if your proxy setscookies and all your back end services are part of the same system, it can benatural to simply share them (and for instance use Spring Session to link themup to some shared state). Other than that, any cookies that get set bydownstream services are likely to be not very useful to the caller, so it isrecommended that you make (at least) "Set-Cookie" and"Cookie" into sensitive headers for routes that are not part of yourdomain. Even for routes that are part of yourdomain, try to think carefully about what it means before allowing cookies toflow between them and the proxy.
你得小心你的服务设计, 比如即使只有一个下游服务设置cookies, 你都必须让他们回溯设置所有的调用路线. 当然, 如果你的代理设置cookies和你所有后端服务是同一个系统的一部分, 它可以自然的被简单分享(例如, 使用spring session去将它们联系在一起共享状态). 除此之外, 任何被下游设置的cookies可能不是很有用, 推荐你对于不属于你域名部分的路由添加(至少)"Set-Cookie"和"Cookie" 到敏感头. 即使是属于你的域名的路由, 尝试仔细思考在允许cookies流传在它们和代理之间的意义。
The sensitive headers can be configured as a comma-separated list perroute, e.g.
每个路由中的敏感头部信息配置按照逗号分隔, 例如:
application.yml
zuul:
routes:
users:
path: /myusers/**
sensitiveHeaders:Cookie,Set-Cookie,Authorization
url: https://downstream
Sensitive headers can also be set globally by setting zuul.sensitiveHeaders. If sensitiveHeaders is set on a route,this will override the global sensitiveHeaders setting.
敏感头部也支持全局设置 zuul.sensitiveHeaders. 如果在单个路由中设置 sensitiveHeaders 会覆盖全局 sensitiveHeaders 设置.
| this is the default value for sensitiveHeaders, so you don’t need to set it unless you want it to be different. N.B. this is new in Spring Cloud Netflix 1.1 (in 1.0 the user had no control over headers and all cookies flow in both directions). |
注意: 这是sensitiveHeaders 的默认值, 你无需设置除非你需要不同的配置. 注. 这是Spring Cloud Netflix 1.1的新功能(在1.0中, 用户无法直接控制请求头和所有cookies).
In addition to the per-route sensitive headers, you can set a global valuefor zuul.ignoredHeaders for values thatshould be discarded (both request and response) during interactions withdownstream services. By default these are empty, if Spring Security is not onthe classpath, and otherwise they are initialized to a set of well-known"security" headers (e.g. involving caching) as specified by SpringSecurity. The assumption in this case is that the downstream services might addthese headers too, and we want the values from the proxy.
除了per-route敏感头以外, 你可以设置一个全局的 zuul.ignoredHeaders 在下游相互调用间去丢弃这些值(包括请求和响应). 如果没有将Spring Security 添加到运行路径中, 他们默认是空的, 否则他们会被Spring Secuity初始化一批安全头(例如 缓存相关). 在这种情况下, 假设下游服务也可能添加这些头信息, 我希望从代理获取值.
路由Endpoint(The Routes Endpoint)
If you are using @EnableZuulProxy with tha SpringBoot Actuator you will enable (by default) an additional endpoint, availablevia HTTP as /routes. A GET to this endpoint will return a list of the mapped routes. A POSTwill force a refresh of the existing routes (e.g. in case there have beenchanges in the service catalog).
如果你使用 @EnableZuulProxy 同时引入了Spring Boot Actuator, 你将默认增加一个endpoint, 提供http服务的 /routes. 一个GET请求将返回路由匹配列表. 一个POST请求将强制刷新已存在的路由.(比如, 在服务catalog变化的场景中)
| the routes should respond automatically to changes in the service catalog, but the POST to /routes is a way to force the change to happen immediately. |
| 路由列表应该自动应答服务登记变化, 但是POST是一种强制立即更新的方案. |
窒息模式和本地跳转(Strangulation Patterns and LocalForwards)
A common pattern when migrating an existing application or API is to"strangle" old endpoints, slowly replacing them with differentimplementations. The Zuul proxy is a useful tool for this because you can useit to handle all traffic from clients of the old endpoints, but redirect someof the requests to new ones.
逐步替代旧的接口是一种通用的迁移现有应用程序或者API的方式, 使用不同的具体实现逐步替换它们. Zuul代理是一种很有用的工具, 因为你可以使用这种方式处理所有客户端到旧接口的请求. 只是重定向了一些请求到新的接口.
Example configuration:
配置样例:
application.yml
zuul:
routes:
first:
path: /first/**
url: http://first.example.com
second:
path: /second/**
url: forward:/second
third:
path: /third/**
url: forward:/3rd
legacy:
path: /**
url: http://legacy.example.com
In this example we are strangling the "legacy" app which ismapped to all requests that do not match one of the other patterns. Paths in /first/** have been extracted into a new service with anexternal URL. And paths in /second/** are forwared so they can be handled locally, e.g. with a normal Spring @RequestMapping. Paths in/third/** are also forwarded, but with a different prefix (i.e. /third/foo is forwarded to /3rd/foo).
在这个例子中我们逐步替换除了部分请求外所有到"legacy"应用的请求. 路径 /first/** 指向了一个额外的URL. 并且路径 /second/** 是一个跳转, 所以请求可以被本地处理. 比如, 带有Spring注解的 @RequestMapping . 路径 /third/** 也是一个跳转, 但是属于一个不同的前缀. (比如 /third/foo 跳转到 /3rd/foo )
| The ignored patterns aren’t completely ignored, they just aren’t handled by the proxy (so they are also effectively forwarded locally). |
| 忽略表达式并不是完全的忽略请求, 只是配置这个代理不处理这些请求(所以他们也是跳转执行本地处理) |
通过Zuul上传文件(Uploading Files through Zuul)
If you @EnableZuulProxy you can use theproxy paths to upload files and it should just work as long as the files aresmall. For large files there is an alternative path which bypasses the Spring DispatcherServlet (to avoidmultipart processing) in "/zuul/*". I.e. if zuul.routes.customers=/customers/** then you can POSTlarge files to "/zuul/customers/*". The servlet path is externalizedvia zuul.servletPath. Extremely large files will also require elevated timeout settings if theproxy route takes you through a Ribbon load balancer, e.g.
如果你使用 @EnableZuulProxy , 你可以使用代理路径上传文件, 它能够一直正常工作只要小文件. 对于大文件有可选的路径"/zuul/*"绕过Spring DispatcherServlet (避免处理multipart). 比如对于 zuul.routes.customers=/customers/** , 你可以使用 "/zuul/customers/*" 去上传大文件. Servlet路径通过 zuul.servletPath 指定. 如果使用Ribbon负载均衡器的代理路由, 在 处理非常大的文件时, 仍然需要提高超时配置. 比如:
application.yml
hystrix.command.default.execution.isolation.thread.timeoutInMilliseconds:60000
ribbon:
ConnectTimeout: 3000
ReadTimeout: 60000
Note that for streaming to work with large files, you need to use chunkedencoding in the request (which some browsers do not do by default). E.g. on thecommand line:
注意: 对于大文件的上传流, 你应该在请求中使用块编码. (有些浏览器默认不这么做). 比如在命令行中:
$ curl -v -H"Transfer-Encoding: chunked" \
-F "[email protected]"localhost:9999/zuul/simple/file
简单的嵌入Zuul(Plain Embedded Zuul)
You can also run a Zuul server without the proxying, or switch on parts ofthe proxying platform selectively, if you use @EnableZuulServer (instead of @EnableZuulProxy). Any beans that you add to the application of type ZuulFilterwill be installedautomatically, as they are with @EnableZuulProxy, but without any of the proxyfilters being added automatically.
你可以运行一个没有代理功能的Zuul服务, 或者有选择的开关部分代理功能, 如果你使用 @EnableZuulServer (替代 @EnableZuulProxy ). 你添加的任何 ZuulFilter 类型 实体类都会被自动加载, 和使用 @EnableZuulProxy 一样, 但不会自动加载任何代理过滤器.
In this case the routes into the Zuul server are still specified byconfiguring "zuul.routes.*", but there is no service discovery and noproxying, so the "serviceId" and "url" settings areignored. For example:
在以下例子中, Zuul服务中的路由仍然是按照 "zuul.routes.*"指定, 但是没有服务发现和代理, 因此"serviceId"和"url"配置会被忽略. 比如:
application.yml
zuul:
routes:
api: /api/**
maps all paths in "/api/**" to the Zuul filter chain.
匹配所有路径 "/api/**" 给Zuul过滤器链.
关闭Zuul过滤器(Disable Zuul Filters)
Zuul for Spring Cloud comes with a number of ZuulFilter beans enabled by default in both proxy and servermode. See the zuul filters package for the possiblefilters that are enabled. If you want to disable one, simply set zuul.
在代理和服务模式下, 对于Spring Cloud, Zuul默认加入了一批 ZuulFilter 类. 查阅 the zuul filters package 去获取可能开启的过滤器. 如果你想关闭其中一个, 可以简单的设置 zuul.
通过Sidecar进行多语言支持(Polyglot support with Sidecar)
Do you have non-jvm languages you want to take advantage of Eureka, Ribbonand Config Server? The Spring Cloud Netflix Sidecar was inspired by Netflix Prana. It includes a simple http api to get all of the instances (ie host andport) for a given service. You can also proxy service calls through an embeddedZuul proxy which gets its route entries from Eureka. The Spring Cloud ConfigServer can be accessed directly via host lookup or through the Zuul Proxy. Thenon-jvm app should implement a health check so the Sidecar can report to eurekaif the app is up or down.
你是否有非jvm语言应用程序需要使用Eureka, Ribbon和Config Server的功能? Spring Cloud Netflix Sidecar 受 Netflix Prana启发. 它包含一个简单的HTTP API去获取所有注册的实例信息(包括host和port信息). 你也可以通过依赖Eureka的嵌入式Zuul代理器代理服务调用. The Spring Cloud Config Server可以通过host查找 或Zuul代理直接进入. 非JVM应用程序提供健康检查实现即可让Sidecar向eureka同步应用程序up还是down.
To enable the Sidecar, create a Spring Boot application with @EnableSidecar. This annotation includes @EnableCircuitBreaker, @EnableDiscoveryClient, and @EnableZuulProxy. Run the resulting application on the same host as the non-jvmapplication.
为了开启Sidecar, 创建一个包含 @EnableSidecar 的Springboot应用程序. 这个注解包括了 @EnableCircuitBreaker, @EnableDiscoveryClient 和 @EnableZuulProxy . 运行这个程序在非jvm程序的同一台主机上.
To configure the side car add sidecar.port and sidecar.health-uri to application.yml. The sidecar.port property is theport the non-jvm app is listening on. This is so the Sidecar can properlyregister the app with Eureka. The sidecar.health-uri is a uri accessible on the non-jvm app that mimicksa Spring Boot health indicator. It should return a json document like thefollowing:
配置Sidecar, 添加 sidecar.port and sidecar.health-uri 到 application.yml 中. 属性 sidecar.port 配置非jvm应用正在监听的端口. 这样Sidecar能够注册应用到 Eureka. sidecar.health-uri 是一个非JVM应用程序提供模仿SpringBoot健康检查接口的可访问的uri. 它应该返回一个json文档类似如下:
health-uri-document
{
"status":"UP"
}
Here is an example application.yml for a Sidecar application:
这个是Sidecar应用程序application.yml的列子:
application.yml
server:
port: 5678
spring:
application:
name: sidecar
sidecar:
port: 8000
health-uri:http://localhost:8000/health.json
The api for the DiscoveryClient.getInstances() method is /hosts/{serviceId}. Here is an example response for /hosts/customers that returns two instances on different hosts. This api is accessible tothe non-jvm app (if the sidecar is on port 5678) at http://localhost:5678/hosts/{serviceId}.
DiscoveryClient.getInstances() 方法的API是 /hosts/{serviceId} . 对于 /hosts/customers 响应的例子是返回两个不同hosts的实例. 这个API对于非JVM 应用程序是可访问的. (如果sidecar监听在5678端口上) http://localhost:5678/hosts/{serviceId} .
/hosts/customers
[
{
"host":"myhost",
"port": 9000,
"uri":"http://myhost:9000",
"serviceId":"CUSTOMERS",
"secure": false
},
{
"host":"myhost2",
"port": 9000,
"uri":"http://myhost2:9000",
"serviceId":"CUSTOMERS",
"secure": false
}
]
The Zuul proxy automatically adds routes for each service known in eurekato /
Zuul自动代理所有eureka中的服务, 路径为 /
If the Config Server is registered with Eureka, non-jvm application canaccess it via the Zuul proxy. If the serviceId of the ConfigServer is configserver and the Sidecar is on port 5678, then it can beaccessed athttp://localhost:5678/configserver
如果配置服务已经在eureka里注册, 非JVM应用可以通过Zuul代理访问到它. 如果ConfigServer的serviceId是 configserver 和Sidecar监听在5678端口上, 则它可以通过 http://localhost:5678/configserver 访问到.
Non-jvm app can take advantage of the Config Server’s ability to returnYAML documents. For example, a call to http://sidecar.local.spring.io:5678/configserver/default-master.yml might result in aYAML document like the following
非JVM应用可以使用ConfigServer的功能返回YAML文档. 比如, 调用 http://sidecar.local.spring.io:5678/configserver/default-master.yml 可以返回如下文档:
eureka:
client:
serviceUrl:
defaultZone:http://localhost:8761/eureka/
password: password
info:
description: Spring Cloud Samples
url:https://github.com/spring-cloud-samples
RxJava 与 Spring MVC(RxJava with Spring MVC)
Spring Cloud Netflix includes the RxJava.
Spring Cloud Netflix 包含 RxJava.
RxJava is aJava VM implementation of ReactiveExtensions: a library for composing asynchronousand event-based programs by using observable sequences.
RxJava是一个Java VM实现http://reactivex.io/(Reactive Extensions):是一个使用可观察数据流进行异步编程的编程接口,ReactiveX结合了观察者模式、迭代器模式和函数式编程的精华。与异步数据流交互的编程范式
Spring Cloud Netflix provides support for returning rx.Single objects from Spring MVC Controllers. It alsosupports using rx.Observable objects for Server-sent events (SSE). This can be very convenient if your internal APIs are already builtusing RxJava (see Feign Hystrix Support for examples).
Spring Cloud Netflix提供并支持从Spring MVC Controllers返回rx.Single对象. 它还支持使用 rx.Observable 对象,可观察的对象为 Server-sent events (SSE). 如果你的内部api已经使用RxJava这会非常的方便(见< < spring-cloud-feign-hystrix > >为例)。
Here are some examples of using rx.Single:
这里有一些使用rx.Single的列子:
@RequestMapping(method = RequestMethod.GET, value = "/single")
public Single
return Single.just("singlevalue");
}
@RequestMapping(method = RequestMethod.GET, value ="/singleWithResponse")
public ResponseEntity
return newResponseEntity<>(Single.just("single value"),HttpStatus.NOT_FOUND);
}
@RequestMapping(method = RequestMethod.GET, value = "/throw")
public Single
return Single.error(newRuntimeException("Unexpected"));
}
If you have an Observable, rather than a single, you can use .toSingle() or .toList().toSingle(). Here are someexamples:
如果你有一个 Observable, 而不是单一的, 你可以使用.toSingle() 或 .toList().toSingle(). 下面是些例子:
@RequestMapping(method = RequestMethod.GET, value = "/single")
public Single
return Observable.just("singlevalue").toSingle();
}
@RequestMapping(method = RequestMethod.GET, value = "/multiple")
public Single
returnObservable.just("multiple", "values").toList().toSingle();
}
@RequestMapping(method = RequestMethod.GET, value ="/responseWithObservable")
public ResponseEntity
Observable
HttpHeaders headers = newHttpHeaders();
headers.setContentType(APPLICATION_JSON_UTF8);
return newResponseEntity<>(observable.toSingle(), headers, HttpStatus.CREATED);
}
@RequestMapping(method = RequestMethod.GET, value = "/timeout")
public Observable
return Observable.timer(1,TimeUnit.MINUTES).map(new Func1
@Override
public String call(LongaLong) {
return "singlevalue";
}
});
}
If you have a streaming endpoint and client, SSE could be an option. Toconvert rx.Observable to a Spring SseEmitter use RxResponse.sse(). Here are some examples:
如果你有一个流端点和客户端,SSE可能是一个选项。使用 RxResponse.sse()将rx.Observable转换到Spring 的SseEmitter. 以下是一些例子:
@RequestMapping(method = RequestMethod.GET, value = "/sse")
public SseEmitter single() {
returnRxResponse.sse(Observable.just("single value"));
}
@RequestMapping(method = RequestMethod.GET, value = "/messages")
public SseEmitter messages() {
returnRxResponse.sse(Observable.just("message 1", "message 2","message 3"));
}
@RequestMapping(method = RequestMethod.GET, value = "/events")
public SseEmitter event() {
returnRxResponse.sse(APPLICATION_JSON_UTF8, Observable.just(
newEventDto("Spring io", getDate(2016, 5, 19)),
newEventDto("SpringOnePlatform", getDate(2016, 8, 1))
));
}
指标: Spectator, Servo,and Atlas(Metrics: Spectator, Servo, and Atlas)
When used together, Spectator/Servo and Atlas provide a near real-timeoperational insight platform.
当Spectator/Servo 和 Atlas一起使用时, 提供一个接近实时操作的平台.
Spectator and Servo are Netflix’s metrics collection libraries. Atlas is aNetflix metrics backend to manage dimensional time series data.
Spectator 和 Servo 的metrics的标准收集库. Atlas 是 Netflix 的一个后端指标 管理多维时间序列数据。
Servo served Netflix for several years and is still usable, but isgradually being phased out in favor of Spectator, which is only designed towork with Java 8. Spring Cloud Netflix provides support for both, but Java 8based applications are encouraged to use Spectator.
Servo为netflix服务多年,仍然是可用的,但逐渐被淘汰,取而代之的是Spectator ,仅仅是为了与java8工作, Spring Cloud Netflix 两者都支持, 但使用java8的推荐使用Spectator.
Dimensional vs. Hierarchical Metrics
Spring Boot Actuator metrics are hierarchical and metrics are separatedonly by name. These names often follow a naming convention that embedskey/value attribute pairs (dimensions) into the name separated by periods.Consider the following metrics for two endpoints, root and star-star:
Spring Boot Actuator指标等级和指标是分开的,这些名字常常遵循命名约定,嵌入key/value attribute 隔着时间的名称。考虑以下指标为两个端点,root 和 star-star:
{
"counter.status.200.root": 20,
"counter.status.400.root": 3,
"counter.status.200.star-star": 5,
}
The first metric gives us a normalized count of successful requestsagainst the root endpoint per unit of time. But what if the system had 20endpoints and you want to get a count of successful requests against all theendpoints? Some hierarchical metrics backends would allow you to specify a wildcard such as counter.status.200. that would read all 20 metrics and aggregatethe results. Alternatively, you could provide a HandlerInterceptorAdapter that intercepts and records a metriclike counter.status.200.all for all successful requests irrespective of the endpoint, but nowyou must write 20+1 different metrics. Similarly if you want to know the totalnumber of successful requests for all endpoints in the service, you couldspecify a wild card such as counter.status.2.*.
第一个指标为我们提供了一个规范化的成功请求的时间单位根节点. 归一化计算对根节点成功请求的时间. 但是如果系统有20个节点和你想要一个对所有节点成功请求的计数呢? 分级指标后端将允许您指定一个 counter.status.200. 阅读所有20个指标和聚合的结果.或者,你可以提供一个 HandlerInterceptorAdapter 拦截和记录所有成功的请求无论节点 counter.status.200.all , 但是现在你必须写20多个不同的指标。同样的如果你想知道所有节点成功请求服务的总数, y您可以指定一个通配符 counter.status.2.*.
Even in the presence of wildcarding support on a hierarchical metricsbackend, naming consistency can be difficult. Specifically the position ofthese tags in the name string can slip with time, breaking queries. Forexample, suppose we add an additional dimension to the hierarchical metricsabove for HTTP method. Then counter.status.200.root becomes counter.status.200.method.get.root, etc. Our counter.status.200.* suddenly no longerhas the same semantic meaning. Furthermore, if the new dimension is not applieduniformly across the codebase, certain queries may become impossible. This canquickly get out of hand.
即使后端参次指标支持它的存在,命名一致性是很困难的. 特别是这些标签的位置名称字符串可以随着时间的推移,打破查询. 例如, 假设我们为HTTP方法上面的分级指标添加一个额外的dimension . 然后“counter.status.200.root”成为“counter.status.200.method.get.root”等等。我们的“counter.status.200 *’突然不再具有相同的语义。 此外 , 如果新dimension不是整个代码库应用均匀,某些查询可能会变得不可能。这很快就会失控。
Netflix metrics are tagged (a.k.a. dimensional). Each metric has a name,but this single named metric can contain multiple statistics and 'tag'key/value pairs that allows more querying flexibility. In fact, the statisticsthemselves are recorded in a special tag.
Netflix metrics 标记 (又名 dimensional). 每个指标都有一个名字,但这一命名metric 可以包含多个数据和“标签”键/值对,允许更多查询的灵活性. 事实上, 数据本身是记录在一个特殊的标记中的.
Recorded with Netflix Servo or Spectator, a timer for the root endpointdescribed above contains 4 statistics per status code, where the countstatistic is identical to Spring Boot Actuator’s counter. In the event that wehave encountered an HTTP 200 and 400 thus far, there will be 8 available datapoints:
记录Netflix Servo 或 Spectator, 一个计时器根节点上包含4统计和状态码,Spring Boot Actuator’s 计数的统计数据时相同的. 迄今为止如果我们遇到 HTTP 200 and 400 ,将会有8种可用数据点
{
"root(status=200,stastic=count)": 20,
"root(status=200,stastic=max)": 0.7265630630000001,
"root(status=200,stastic=totalOfSquares)": 0.04759702862580789,
"root(status=200,stastic=totalTime)": 0.2093076914666667,
"root(status=400,stastic=count)": 1,
"root(status=400,stastic=max)": 0,
"root(status=400,stastic=totalOfSquares)": 0,
"root(status=400,stastic=totalTime)": 0,
}
默认的 Metrics 集合(Default Metrics Collection)
Without any additional dependencies or configuration, a Spring Cloud basedservice will autoconfigure a Servo MonitorRegistry and begin collecting metrics on every Spring MVC request. By default, aServo timer with the name rest will be recorded for each MVC request which is tagged with:
没有任何额外的依赖关系或配置,Spring Cloud 基于云服务可以使用autoconfigure a Servo MonitorRegistry 并开始收集 metrics 在每一个SpringMVC请求上. 默认情况下, Servo 定时器 的名字 rest 将被记录并为每个MVC请求标记:
1. HTTP method
2. HTTP status (e.g.200, 400, 500)
3. URI (or"root" if the URI is empty), sanitized for Atlas
4. The exceptionclass name, if the request handler threw an exception
5. The caller, if arequest header with a key matching netflix.metrics.rest.callerHeader is set on the request. There is no default key for netflix.metrics.rest.callerHeader. You must add it to your application properties if you wish to collectcaller information.
6. HTTP method
7. HTTP status (e.g.200, 400, 500)
8. URI (or"root" if the URI is empty), sanitized for Atlas
9. 异常类的名称,如果请求处理程序抛出一个异常
10. 调用者, 如果一个请求头和一个key netflix.metrics.rest.callerHeader匹配. callerHeader的设置要求:没有默认的key“netflix.metrics.rest.callerHeader”。您必须将它添加到您的应用程序属性如果你想收集调用信息。
Set the netflix.metrics.rest.metricName property to changethe name of the metric from rest to a name you provide.
更改metrics的名字从rest到你提供的一个名字,您所提供的名称设置netflix.metrics.rest.metricName 属性
If Spring AOP is enabled and org.aspectj:aspectjweaver is present on your runtime classpath, Spring Cloudwill also collect metrics on every client call made with RestTemplate. A Servo timerwith the name of restclient will be recordedfor each MVC request which is tagged with:
如果 Spring AOP的启用和org.aspectj:aspectjweaver 是你目前运行时的classpath, Spring Cloud 也会调用创建RestTemplate收集每一个客户端. Servo timer的restclient 将被记录为每个MVC请求标记:
1. HTTP method
2. HTTP status (e.g.200, 400, 500), "CLIENT_ERROR" if the response returned null, or"IO_ERROR" if an IOExceptionoccurred during the execution of the RestTemplate method
3. URI, sanitized forAtlas
4. Client name
5. HTTP method 2.HTTP状态(如200、400、500),如果响应返回null"CLIENT_ERROR",或着创建RestTemplate方法时抛出"IO_ERROR"
6. URI, sanitized forAtlas
7. Client name
Metrics 集合: Spectator(Metrics Collection:Spectator)
To enable Spectator metrics, include a dependency on spring-boot-starter-spectator:
让Spectator metrics包含并依赖spring-boot-starter-spectator:
In Spectator parlance, a meter is a named, typed, and tagged configurationand a metric represents the value of a given meter at a point in time.Spectator meters are created and controlled by a registry, which currently hasseveral different implementations. Spectator provides 4 meter types: counter,timer, gauge, and distribution summary.
在 Spectator 里, 一个流量计一个命名的类型和标记的配置和metric表示在某个时间点的给定值. 通过注册表创建Spectator meters和 controlled, 目前有多种不同的实现. Spectator 提供4种类型: counter, timer, gauge, 还有 distribution summary.
Spring Cloud Spectator integration configures an injectable com.netflix.spectator.api.Registry instance for you.Specifically, it configures a ServoRegistry instance in order to unify the collection of REST metrics and theexporting of metrics to the Atlas backend under a single Servo API.Practically, this means that your code may use a mixture of Servo monitors andSpectator meters and both will be scooped up by Spring Boot Actuator MetricReaderinstances and bothwill be shipped to the Atlas backend.
Spring Cloud Spectator 整合配置实例为你注入 com.netflix.spectator.api.Registry. 具体来说,为了统一REST指标的集合配置和其他Atlas 后端下单一Servo的API,它配置了一个ServoRegistry 实例. 实际上, 这意味着你的代码可以使用Servo monitors 和 Spectator meters ,双方都将被捞起,由 Spring Boot Actuator MetricReader实例运往Atlas后端.
Spectator 计数器(Spectator Counter)
A counter is used to measure the rate at which some event is occurring.
一个计数器是用于测量其中一些事件发生的速率。
// create a counter with a name and a set of tags
Counter counter = registry.counter("counterName","tagKey1", "tagValue1", ...);
counter.increment(); // increment when an event occurs
counter.increment(10); // increment by a discrete amount
The counter records a single time-normalized statistic.
该计数器记录一个单一的时间归一化统计。
Spectator Timer
A timer is used to measure how long some event is taking. Spring Cloudautomatically records timers for Spring MVC requests and conditionally RestTemplate requests, which can later be used to createdashboards for request related metrics like latency:
计时器是用来测量一些事件正在发生的时间. Spring Cloud 为Spring MVC的请求,定时器和有条件RestTemplate请求自动记录, 以后可以用来创建请求相关的指标,如延迟仪表板:
Figure 4. 请求延迟(Request Latency)
// create a timer with a name and a set of tags
// 创建一个具有名称和一组标签的计时器
Timer timer = registry.timer("timerName", "tagKey1","tagValue1", ...);
// execute an operation and time it at the same time
// 在同一时间执行的操作,并且一次
T result = timer.record(() -> fooReturnsT());
// alternatively, if you must manually record the time
// 另外,你必须手动记录时间
Long start = System.nanoTime();
T result = fooReturnsT();
timer.record(System.nanoTime() - start, TimeUnit.NANOSECONDS);
The timer simultaneously records 4 statistics: count, max, totalOfSquares,and totalTime. The count statistic will always match the single normalizedvalue provided by a counter if you had called increment() once on the counter for each time you recorded atiming, so it is rarely necessary to count and time separately for a singleoperation.
计时器同时记录4种统计:计数,最大,总平方和总时间. 如果你调用increment()计数器记录时间,计数统计与单一的标准值总是由计数器设置,,所以很少需要分别计算单个操作时间。
For long running operations, Spectator provides a special LongTaskTimer.
For long running operations, Spectator 提供了一个特殊的 LongTaskTimer.
Spectator Gauge
Gauges are used to determine some current value like the size of a queueor number of threads in a running state. Since gauges are sampled, they provideno information about how these values fluctuate between samples.
仪表用于确定当前的值,如队列的大小或运行状态中的线程数。由于压力表是采样的,它们没有提供关于这些值如何在样品之间波动的信息。
The normal use of a gauge involves registering the gauge once ininitialization with an id, a reference to the object to be sampled, and afunction to get or compute a numeric value based on the object. The referenceto the object is passed in separately and the Spectator registry will keep aweak reference to the object. If the object is garbage collected, thenSpectator will automatically drop the registration. See the note in Spectator’sdocumentation about potential memory leaks if this API is misused.
通常仪表的一旦初始化正常使用包括注册表id,采样对象的引用,和一个函数或计算基于对象的数值. 在 separately 和 Spectator 注册中心将通过弱引用引用对象. 如果对象被垃圾收集,那么Spectator就会自动放弃注册。 See the note 在 Spectator这个文档中关于潜在的内存泄漏,如果这个API被滥用.
// the registry will automatically sample this gauge periodically
// 注册表会自动定期抽样这个gauge
registry.gauge("gaugeName", pool, Pool::numberOfRunningThreads);
// manually sample a value in code at periodic intervals -- last resort!
// 定期手动示例代码中的一个值----最后一招!
registry.gauge("gaugeName", Arrays.asList("tagKey1","tagValue1", ...), 1000);
Spectator分布式汇总(Spectator Distribution Summaries)
A distribution summary is used to track the distribution of events. It issimilar to a timer, but more general in that the size does not have to be aperiod of time. For example, a distribution summary could be used to measurethe payload sizes of requests hitting a server.
一个分布式汇总是用来跟踪事件的分布. 它类似于一个计时器,但更普遍的大小不需要一段时间.举个例子, 分布总结可以测量在服务器上的请求的有效负载大小。
// the registry will automatically sample this gauge periodically
// 注册表会自动定期抽样这个gauge
DistributionSummary ds = registry.distributionSummary("dsName","tagKey1", "tagValue1", ...);
ds.record(request.sizeInBytes());
Metrics 搜集: Servo(Metrics Collection: Servo)
| If your code is compiled on Java 8, please use Spectator instead of Servo as Spectator is destined to replace Servo entirely in the long term. |
| 如果您的代码Java的编译8,请用Spectator ,而不是作为Servo,Spectator注定要在长期内完全替代Servo. |
In Servo parlance, a monitor is a named, typed, and tagged configurationand a metric represents the value of a given monitor at a point in time. Servomonitors are logically equivalent to Spectator meters. Servo monitors arecreated and controlled by a MonitorRegistry. In spite of the above warning,Servo does have a wider array of monitor optionsthan Spectator has meters.
在Servo里, monitor是命名的类型和标记的配置和metric代表在某个时间点的给定monitor的值. Servo monitors 逻辑上等同于Spectator meters. Servo monitors 创建并通过 MonitorRegistry控制. 不管上述警告的, Servo 确实比多Spectator一个链接 :https://github.com/Netflix/servo/wiki/Getting-Started[各种各样].
Spring Cloud integration configures an injectable com.netflix.servo.MonitorRegistry instance for you.Once you have created the appropriate Monitor type in Servo, the process of recording data is wholly similar toSpectator.
一旦您创建了适当的Monitor Servo类型,Spring Cloud集成配置可注入 com.netflix.servo.MonitorRegistry 的实例,记录数据的过程是完全类似于Spectator。
创建 Servo Monitors(Creating Servo Monitors)
If you are using the Servo MonitorRegistry instance provided by Spring Cloud (specifically, an instance of DefaultMonitorRegistry), Servo provides convenience classes for retrieving counters and timers. These convenience classes ensure that only one Monitor is registered for each unique combination of nameand tags.
如果你使用的是 Spring Cloud 提供的Servo MonitorRegistry实例,Servo 类用于提供检索方便 counters and timers. These convenience classes ensure that only one Monitor is registered for each unique combination of nameand tags.
To manually create a Monitor type in Servo, especially for the more exoticmonitor types for which convenience methods are not provided, instantiate theappropriate type by providing a MonitorConfig instance:
手动创建一个监视器类型,尤其是对于更奇特的显示器类型不提供便利的方法,通过提供'MonitorConfig`实例,实例化适当的类型:
MonitorConfig config =MonitorConfig.builder("timerName").withTag("tagKey1","tagValue1").build();
// somewhere we should cache this Monitor by MonitorConfig
// 我们应该用MonitorConfig缓存这个监视器
Timer timer = new BasicTimer(config);
monitorRegistry.register(timer);
Metrics Backend: Atlas
Atlas was developed by Netflix to manage dimensional time series data fornear real-time operational insight. Atlas features in-memory data storage,allowing it to gather and report very large numbers of metrics, very quickly.
Atlas 由Netflix的发展管理多维时间序列数据为实时业务 地图功能内存数据存储,允许它收集和报告非常大量的指标,非常快。
Atlas captures operational intelligence. Whereas business intelligence isdata gathered for analyzing trends over time, operational intelligence providesa picture of what is currently happening within a system.
Atlas 抓住了作战情报. 而商业智能数据分析趋势随着时间的推移,作战情报提供的照片目前发生在一个系统.
Spring Cloud provides a spring-cloud-starter-atlas that has all the dependencies you need. Then justannotate your Spring Boot application with @EnableAtlas and provide a location for your running Atlas serverwith the netflix.atlas.uri property.
Spring Cloud 提供了一个spring-cloud-starter-atlas,它有你所需要的所有依赖项.然后只需要在你的Spring应用程序启动注解@EnableAtlas 和为正在运行的Atlas服务提供一个位置netflix.atlas.uri
Global tags
Spring Cloud enables you to add tags to every metric sent to the Atlasbackend. Global tags can be used to separate metrics by application name,environment, region, etc.
Spring Cloud 您可以添加标签发送到Atlas后端每个指标. Global 标签可通过 application name, environment, region, etc等.
Each bean implementing AtlasTagProvider will contribute to the global tag list:
每个 bean 实现 AtlasTagProvider 将有助于Global标记列表:
@Bean
AtlasTagProvider atlasCommonTags(
@Value("${spring.application.name}") String appName) {
return () ->Collections.singletonMap("app", appName);
}
使用Atlas(Using Atlas)
To bootstrap a in-memory standalone Atlas instance:
引导一个内存中的独立Atlas实例:
$ curl -LOhttps://github.com/Netflix/atlas/releases/download/v1.4.2/atlas-1.4.2-standalone.jar
$ java -jar atlas-1.4.2-standalone.jar
| An Atlas standalone node running on an r3.2xlarge (61GB RAM) can handle roughly 2 million metrics per minute for a given 6 hour window. |
| Atlas的一个独立的节点上运行r3.2xlarge(61gb RAM)可以处理大约200万个指标,每分钟为6小时的窗口。 |
Once running and you have collected a handful of metrics, verify that yoursetup is correct by listing tags on the Atlas server:
一旦运行,你收集的指标屈指可数,验证您的设置是通过列出阿特拉斯服务器上的标签正确的:
$ curl http://ATLAS/api/v1/tags
| After executing several requests against your service, you can gather some very basic information on the request latency of every request by pasting the following url in your browser: http://ATLAS/api/v1/graph?q=name,rest,:eq,:avg |
TIP:在对您的服务执行多个请求之后,您可以通过在浏览器上粘贴以下网址来收集每个请求的请求延迟的一些非常基本的信息: http://ATLAS/api/v1/graph?q=name,rest,:eq,:avg
The Atlas wiki contains a compilation of sample queries for variousscenarios.
The Atlas wiki 包含一个链接:https://github.com/Netflix/atlas/wiki/Single-Line[compilation of samplequeries] 各种场景的示例查询.
Make sure to check out the alerting philosophy and docs on using double exponential smoothing to generatedynamic alert thresholds.
2、Zuul类似nginx,反向代理的功能,不过netflix自己增加了一些配合其他组件的特性
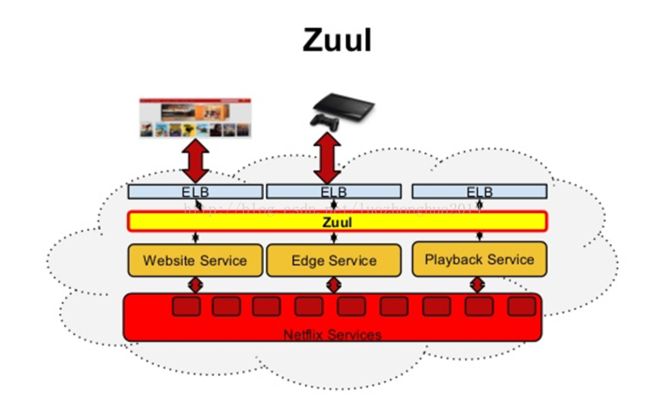
3、验证与源码分析。。。。后续