JavaSE 进阶 - 第22章 集合(二)
JavaSE 进阶 - 第22章 集合(二)
- 1、List接口、及常用方法
- 2、ArrayList
- 3、LinkedList、链表数据结构
- 4、Vector
- 5、泛型
- 6、增强for循环:foreach
- 7、Set接口
- 传送门
1、List接口、及常用方法
先看看上一章的这张图:
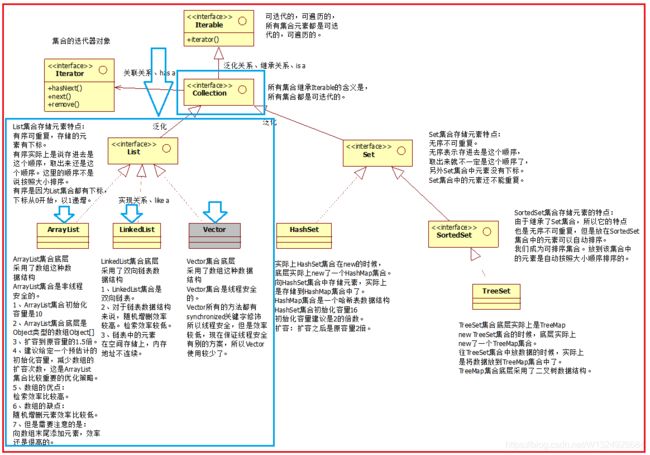
1.1 List接口
List接口继承Collection接口,它们都在java.util包下面。
主要实现类:ArrayList、LinkedList、Vector
• ArrayList:底层数据结构——数组。非线程安全,它的方法之间是线程不同步的,因为它不考虑线程安全,效率会高些。
• LinkedList:底层数据结构——双向链表。非线程安全。
• Vector:底层数据结构——数组。线程安全(也就是说是它的方法之间是线程同步的(synchronized)),但是效率较低,
现在保证线程安全有别的方案,所以Vector使用较少了。
1.2、 List集合存储元素特点:有序可重复
有序:List集合中的元素有下标。从0开始,以1递增。
可重复:存储一个1,还可以再存储1.
1.3 List是Collection接口的子接口。所以List接口中有一些特有的方法。
void add(int index, Object element)——在列表的指定位置插入指定元素(第一个参数是下标)
Object set(int index, Object element)—— 用指定元素替换此列表中指定位置的元素
Object get(int index)—— 返回此列表中指定位置的元素
int indexOf(Object o)—— 获取指定对象第一次出现处的索引。
int lastIndexOf(Object o)—— 获取指定对象最后一次出现处的索引。
Object remove(int index)—— 删除指定下标位置的元素
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListTest01 {
public static void main(String[] args) {
// 创建List类型的集合。
//List myList = new LinkedList();
//List myList = new Vector();
List myList = new ArrayList();
// 添加元素
myList.add("A"); // 默认都是向集合末尾添加元素。
myList.add("B");
myList.add("C");
myList.add("C");
myList.add("D");
//在列表的指定位置插入指定元素(第一个参数是下标)
// 这个方法使用不多,因为对于ArrayList集合来说效率比较低。
myList.add(1, "KING");
// 迭代
Iterator it = myList.iterator();
while(it.hasNext()){
Object elt = it.next();
System.out.println(elt);
}
System.out.println("====================================");
// 根据下标获取元素
Object firstObj = myList.get(0);
System.out.println(firstObj);
// 因为有下标,所以List集合有自己比较特殊的遍历方式
// 通过下标遍历。【List集合特有的方式,Set没有。】
for(int i = 0; i < myList.size(); i++){
Object obj = myList.get(i);
System.out.println(obj);
}
// 获取指定对象第一次出现处的索引。
System.out.println(myList.indexOf("C")); // 3
// 获取指定对象最后一次出现处的索引。
System.out.println(myList.lastIndexOf("C")); // 4
// 删除指定下标位置的元素
// 删除下标为0的元素
myList.remove(0);
System.out.println(myList.size()); // 5
System.out.println("====================================");
// 修改指定位置的元素
myList.set(2, "Soft");
// 遍历集合
for(int i = 0; i < myList.size(); i++){
Object obj = myList.get(i);
System.out.println(obj);
}
}
}
/*
A
KING
B
C
C
D
====================================
A
A
KING
B
C
C
D
3
4
5
====================================
KING
B
Soft
C
D
*/
2、ArrayList
-
2.1、ArrayList底层是一个Object[]数组。
-
2.2、ArrayList是非线程安全的。(不是线程安全的集合。)
-
2.3、ArrayList默认初始化容量10
(底层先创建了一个长度为0的数组,当添加第一个元素的时候,初始化容量10。) -
2.4、ArrayList扩容到原容量的1.5倍。
ArrayList集合底层是数组,怎么优化?
尽可能少的扩容。因为数组扩容效率比较低,建议在使用ArrayList集合的时候预估计元素的个数,给定一个初始化容量。 -
2.5、数组优点:
检索效率比较高。
每个元素占用空间大小相同,内存地址是连续的,知道首元素内存地址,
然后知道下标,通过数学表达式计算出元素的内存地址,所以检索效率最高。 -
2.6、数组缺点:
随机增删元素效率比较低。
另外数组无法存储大数据量。(很难找到一块非常巨大的连续的内存空间。) -
2.7、向数组末尾添加元素,效率很高,不受影响。
-
2.8、问题:这么多的集合中,你用哪个集合最多?
ArrayList集合。增加元素快,直接在数组末尾添加。检索效率高,有下标,每个元素存的大小是一样的,通过数学表达式很快计算出各元素的地址,直接定位。当然数组也有缺点,随机增加,删除元素效率低,需要元素移位;另外数组不能存储大数据量,因为很难在内存地址中找到一块大容量的连续的空间。 -
2.9、集合ArrayList的3个构造方法
ArrayList() ——无参构造方法(默认初始容量为10)
ArrayList(int initialCapacity) ——有参构造方法(参数为初始容量)
ArrayList(Collection c) ——有参构造方法(参数为一个集合)
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashSet;
import java.util.List;
public class ArrayListTest01 {
public static void main(String[] args) {
// 一、默认初始化容量是10
// 数组的长度是10
List list1 = new ArrayList();
// 集合的size()方法是获取当前集合中元素的个数。不是获取集合的容量。
System.out.println(list1.size()); // 0
list1.add(1);
list1.add(2);
list1.add(3);
list1.add(4);
list1.add(5);
list1.add(6);
list1.add(7);
list1.add(8);
list1.add(9);
list1.add(10);
System.out.println(list1.size());//10
// 再加一个元素
list1.add(11);
System.out.println(list1.size()); // 11个元素。
// 二、指定初始化容量
// 数组的长度是20
List list2 = new ArrayList(20);
// 集合的size()方法是获取当前集合中元素的个数。不是获取集合的容量。
System.out.println(list2.size()); // 0
//三、传一个集合
// 创建一个HashSet集合
Collection c = new HashSet();
// 添加元素到Set集合
c.add(100);
c.add(20);
c.add(900);
c.add(50);
// 通过这个构造方法就可以将HashSet集合转换成List集合。
List myList3 = new ArrayList(c);
for(int i = 0; i < myList3.size(); i++){
System.out.println(myList3.get(i));
}
/*
50
100
20
900
*/
}
}
3、LinkedList、链表数据结构
-
3.1、 LinkedList底层是 双向链表。
-
3.2、 LinkedList是非线程安全的。
-
3.3、 LinkedList集合没有初始化大小,也没有扩容的机制
-
3.4、 链表的优点:随机增删效率较高!
由于链表上的元素在空间存储上内存地址不连续,所以随机增删元素的时候不会有大量元素位移,因此随机增删效率较高。
在以后的开发中,如果遇到随机增删集合中元素的业务比较多时,建议使用LinkedList。 -
3.5、 链表的缺点:检索的效率较低!
不能通过数学表达式计算被查找元素的内存地址,每一次查找都是从头节点开始遍历,直到找到为止。 -
3.6、ArrayList:把检索发挥到极致。(末尾添加元素效率还是很高的。)
LinkedList:把随机增删发挥到极致。 -
3.7、加元素都是往末尾添加,所以ArrayList用的比LinkedList多。
-
3.8、LinkedList的2个构造方法
LinkedList() ——无参构造方法
LinkedList(Collection c) ——有参构造方法(参数为一个集合)
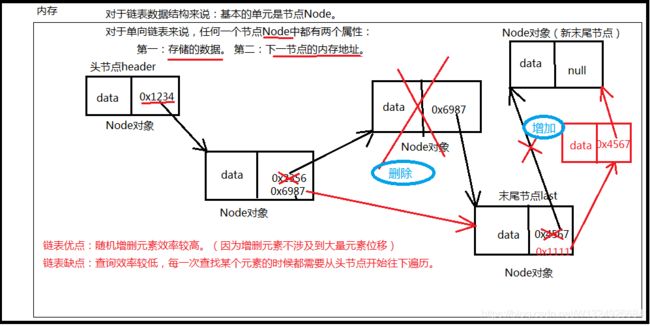

【示例】:
import java.util.*;
public class LinkedListTest01 {
public static void main(String[] args) {
// LinkedList集合底层也是有下标的。
// 注意:ArrayList之所以检索效率比较高,不是单纯因为下标的原因。是因为底层数组发挥的作用。
// LinkedList集合照样有下标,但是检索/查找某个元素的时候效率比较低,因为只能从头节点开始一个一个遍历。
// LinkedList集合有初始化容量吗?没有。
// 最初这个链表中没有任何元素。first和last引用都是null。
// 不管是LinkedList还是ArrayList,以后写代码时不需要关心具体是哪个集合。
// 因为我们要面向接口编程,调用的方法都是接口中的方法。
//List list = new ArrayList(); // 这样写表示底层你用了数组。
List list = new LinkedList(); // 这样写表示底层你用了双向链表。
list.add("a");
list.add("b");
list.add("c");
for(int i = 0; i <list.size(); i++){ //遍历
System.out.println(list.get(i));
}
System.out.println("------------分割线----------------");
Collection list2 = new HashSet();
list2.add("e");
list2.add("g");
list2.add("m");
// 通过这个构造方法就可以将HashSet集合转换成LinkedList集合。
List list3 = new LinkedList(list2);
for(int i = 0; i < list3.size(); i++){
System.out.println(list3.get(i));
}
}
}
/*
a
b
c
------------分割线----------------
e
g
m
*/
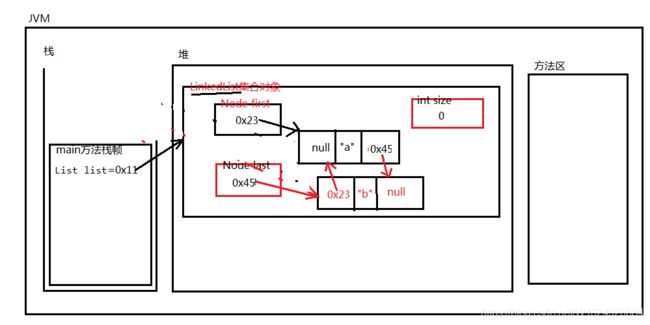
4、Vector
-
4.1、Vector底层也是一个数组。
-
4.2、Vector初始化容量是10
-
4.3、Vector扩容到原容量的2倍。
(上面ArrayList集合扩容到原容量1.5倍) -
4.4、Vector是线程安全的,Vector中所有的方法都是线程同步的,都带有synchronized关键字。效率比较低,使用较少了。
-
4.5、怎么将一个线程不安全的ArrayList集合转换成线程安全的呢?
使用集合工具类:java.util.Collections;
【注意】:
java.util.Collection 是集合接口。
java.util.Collections 是集合工具类。 -
4.6、Vector的4个构造方法
Vector() ——无参构造方法(默认初始容量为10,容量增量为0)
Vector(int initialCapacity) ——有参构造方法(参数为初始容量,容量增量为0)
Vector(int initialCapacity,int capacityIncrement)————有参构造方法(参数分别为初始容量、容量增量)
Vector(Collection c) ——有参构造方法(参数为一个集合)
import java.util.*;
public class VectorTest {
public static void main(String[] args) {
// 创建一个Vector集合
List vector = new Vector();
//Vector vector = new Vector();
// 添加元素
// 默认容量10个。
vector.add(1);
vector.add(2);
vector.add(3);
vector.add(4);
vector.add(5);
vector.add(6);
vector.add(7);
vector.add(8);
vector.add(9);
vector.add(10);
// 满了之后扩容(扩容之后的容量是20.)
vector.add(11);
Iterator it = vector.iterator(); //1、通过迭代器 遍历
while(it.hasNext()){
Object obj = it.next();
System.out.println(obj);
}
for(int i = 0; i <vector.size(); i++){ //2、通过下标 遍历
System.out.println(vector.get(i));
}
System.out.println("------------分割线----------------");
List myList = new ArrayList(); // 非线程安全的。
// 变成线程安全的
Collections.synchronizedList(myList); // 这里没有办法看效果,因为多线程没学,先记住!
// myList集合就是线程安全的了。
myList.add("111");
myList.add("222");
myList.add("333");
}
}
5、泛型
- 5.1、JDK5.0之后推出的新特性:泛型
- 5.2、泛型这种语法机制,只在程序编译阶段起作用,只是给编译器参考的。(运行阶段泛型没用!)
- 5.3、使用了泛型好处是什么?
第一:集合中存储的元素类型统一了。
第二:从集合中取出的元素类型是泛型指定的类型,不需要进行大量的“向下转型”!
// 不使用泛型机制
List myList = new ArrayList();
// 使用泛型List之后,表示List集合中只允许存储Animal类型的数据。
// 用泛型来指定集合中存储的数据类型。
List<Animal> myList = new ArrayList<Animal>();
- 5.4、泛型的缺点是什么?
导致集合中存储的元素缺乏多样性!
大多数业务中,集合中元素的类型还是统一的。所以这种泛型特性被大家所认可。
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class GenericTest01 {
public static void main(String[] args) {
/*
// 不使用泛型机制,分析程序存在缺点
List myList = new ArrayList();
// 准备对象
Cat c = new Cat();
Bird b = new Bird();
// 将对象添加到集合当中
myList.add(c);
myList.add(b);
// 遍历集合,取出每个Animal,让它move
Iterator it = myList.iterator();
while(it.hasNext()) {
// 没有这个语法,通过迭代器取出的就是Object
//Animal a = it.next();
Object obj = it.next();
//obj中没有move方法,无法调用,需要向下转型!
if(obj instanceof Animal){
Animal a = (Animal)obj;
a.move();
}
}
*/
// 使用JDK5之后的泛型机制
// 使用泛型List之后,表示List集合中只允许存储Animal类型的数据。
// 用泛型来指定集合中存储的数据类型。
List<Animal> myList = new ArrayList<Animal>();
// 指定List集合中只能存储Animal,那么存储String就编译报错了。
// 这样用了泛型之后,集合中元素的数据类型更加统一了。
//myList.add("abc");
Cat c = new Cat();
Bird b = new Bird();
myList.add(c);
myList.add(b);
// 获取迭代器
// 这个表示迭代器迭代的是Animal类型。
Iterator<Animal> it = myList.iterator();
while(it.hasNext()){
// 使用泛型之后,每一次迭代返回的数据都是Animal类型。
Animal a = it.next();
// 这里不需要进行强制类型转换了。直接调用。
a.move();
/*
// 调用子类型特有的方法还是需要向下转换的!
if(a instanceof Cat) {
Cat x = (Cat)a;
x.catchMouse();
}
if(a instanceof Bird) {
Bird y = (Bird)a;
y.fly();
}*/
}
}
}
class Animal {
// 父类自带方法
public void move(){
System.out.println("动物在移动!");
}
}
class Cat extends Animal {
// 特有方法
public void catchMouse(){
System.out.println("猫抓老鼠!");
}
}
class Bird extends Animal {
// 特有方法
public void fly(){
System.out.println("鸟儿在飞翔!");
}
}
- 5.5、JDK8新特性:自动类型推断机制(又称为钻石表达式)
钻石表达式(注意,后面new的<>中不用写类型,会自动推断类型)
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
/*
JDK8之后引入了:自动类型推断机制。(又称为钻石表达式)
*/
public class GenericTest02 {
public static void main(String[] args) {
// ArrayList<这里的类型会自动推断>(),前提是JDK8之后才允许。
// 自动类型推断,钻石表达式!
List<Animal> myList = new ArrayList<>();
myList.add(new Animal());
myList.add(new Cat());
myList.add(new Bird());
// 遍历
Iterator<Animal> it = myList.iterator();
while(it.hasNext()){
Animal a = it.next();
a.move();
}
List<String> strList = new ArrayList<>();
// 类型不匹配。
//strList.add(new Cat());
strList.add("http://www.126.com");
strList.add("http://www.baidu.com");
// 遍历
Iterator<String> it2 = strList.iterator();
while(it2.hasNext()){
// 如果没有使用泛型
/*
Object obj = it2.next();
if(obj instanceof String){
String ss = (String)obj;
ss.substring(7);
}
*/
// 直接通过迭代器获取了String类型的数据
String s = it2.next();
// 直接调用String类的substring方法截取字符串。
String newString = s.substring(7);
System.out.println(newString);
}
}
}
/*
动物在移动!
动物在移动!
动物在移动!
www.126.com
www.baidu.com
*/
- 5.6、自定义泛型
自定义泛型的时候,<> 尖括号中的是一个标识符,随便写。
java源代码中经常出现的是:< E >和< T >
E是Element单词首字母。
T是Type单词首字母。
public class GenericTest03<标识符随便写> {
public void doSome(标识符随便写 o){
System.out.println(o);
}
public static void main(String[] args) {
// new对象的时候指定了泛型是:String类型
GenericTest03<String> gt = new GenericTest03<>();
// 类型不匹配
//gt.doSome(100);
gt.doSome("abc");
// =============================================================
GenericTest03<Integer> gt2 = new GenericTest03<>();
gt2.doSome(100);
// 类型不匹配
//gt2.doSome("abc");
// 不用泛型
GenericTest03 gt3 = new GenericTest03();
gt3.doSome(new Object());
MyIterator<String> mi = new MyIterator<>();
String s1 = mi.get();
MyIterator<Animal> mi2 = new MyIterator<>();
Animal a = mi2.get();
}
}
class MyIterator<T> {
public T get(){
return null;
}
}
/*
abc
100
java.lang.Object@f6f4d33
*/
6、增强for循环:foreach
- (JDK5.0新特性)
- 【语法】:
for(元素类型 变量名 : 数组或集合){
System.out.println(变量名);
}
-
注:foreach有一个缺点:没有下标。
在需要使用下标的循环中,不建议使用增强for循环。 -
1、对数组怎么遍历?
for(int i : arr){
System.out.println(i);
}
- 2、对集合怎么遍历?----就不需要使用迭代器了
for(String s : list){
System.out.println(s);
}
7、Set接口
先看看上一章的这张图:
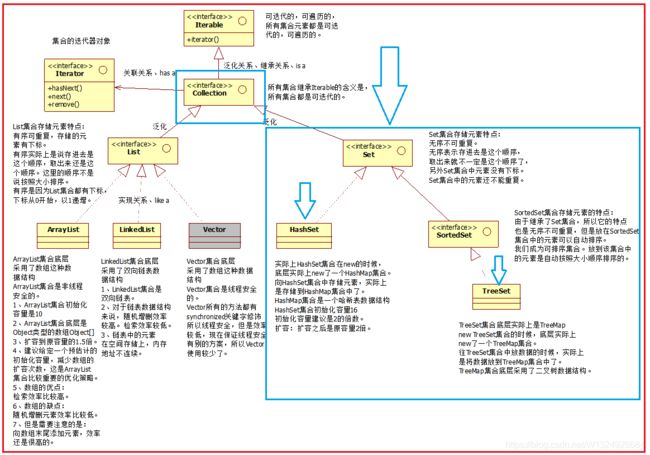
-
7.1、Set接口也是继承Collection接口,它们都在java.util包下面。
主要实现类:HashSet、TreeSet -
7.2、Set集合存储元素特点:无序不可重复
无序:存储时顺序和取出的顺序不同,并且没有下标
不可重复:元素不可重复 -
7.3、HashSet集合:
无序不可重复。
放到HashSet集合中的元素实际上是放到HashMap集合的key部分了 -
7.4、TreeSet集合:
无序不可重复的,但是存储的元素可以自动按照大小顺序排序!称为:可排序集合。
放到TreeSet集合中的元素实际上是放到TreeSet集合的key部分了 -
【注:Set接口实际上对应着Map接口的key部分,可以先仔细学习Map接口,Set接口也就会了】
import java.util.HashSet;
import java.util.Set;
/*
HashSet集合:
无序不可重复。
*/
public class HashSetTest01 {
public static void main(String[] args) {
// 演示一下HashSet集合特点
Set<String> strs = new HashSet<>();
// 添加元素
strs.add("hello3");
strs.add("hello4");
strs.add("hello1");
strs.add("hello2");
strs.add("hello3");
strs.add("hello3");
strs.add("hello3");
strs.add("hello3");
/*
1、存储时顺序和取出的顺序不同。
2、不可重复。
3、放到HashSet集合中的元素实际上是放到HashMap集合的key部分了。
*/
for(String s : strs){ // 遍历
System.out.println(s);
}
}
}
/*
hello1
hello4
hello2
hello3
*/
import java.util.Set;
import java.util.TreeSet;
/*
TreeSet集合存储元素特点:
1、无序不可重复的,但是存储的元素可以自动按照大小顺序排序!
称为:可排序集合。
2、无序:这里的无序指的是存进去的顺序和取出来的顺序不同。并且没有下标。
*/
public class TreeSetTest01 {
public static void main(String[] args) {
// 创建集合对象
Set<String> strs = new TreeSet<>();
// 添加元素
strs.add("A");
strs.add("B");
strs.add("Z");
strs.add("Y");
strs.add("Z");
strs.add("K");
strs.add("M");
// 遍历
for(String s : strs){
System.out.println(s);
}
}
}
/*结果(无序不可重复:存进去两个Z,出来只有1个;可排序:从小到大自动排序!)
A
B
K
M
Y
Z
*/
传送门
上一章:JavaSE 进阶 - 第22章 集合(一)
下一章:JavaSE 进阶 - 第22章 集合(三)