Spark分布式集群部署及HA配置
文章目录
- 1.安装scala
- 1.1上传安装包
- 1.2解压
- 1.3重命名
- 1.4配置环境变量
- 1.5验证
- 2.安装Spark
- 2.1上传安装包
- 2.2解压
- 2.3重命名
- 2.4配置环境变量
- 2.5修改配置文件
- 2.5.1拷贝slaves和spark-env.sh文件
- 2.5.2修改slaves
- 2.5.3修改spark-env.sh
- 2.5.4远程发送到其他节点
- 2.6启动
- 2.6.1修改命令
- 2.6.2启动spark集群
- 3.配置HA环境
- 3.1修改配置文件
- 3.2启动高可用集群
- 3.3测试
安装节点要求:
- jdk
- hadoop
- scala
- zookeeper
1.安装scala
1.1上传安装包
put c:/scala-2.11.8.tgz
1.2解压
tar -zxvf scala-2.11.8.tgz -C /home/hadoop/apps/
1.3重命名
mv scala-2.11.8 scala
1.4配置环境变量
vim ~/.bash_profile
添加如下内容
export SCALA_HOME=/home/hadoop/apps/scala
export PATH=$PATH:$SCALA_HOME/bin
重新加载配置文件
source ~/.bash_profile
1.5验证
scala -version

2.安装Spark
2.1上传安装包
put c:/spark-2.2.2-bin-hadoop2.7
2.2解压
tar -zxvf spark-2.2.2-bin-hadoop2.7 -C /home/hadoop/apps/
2.3重命名
mv spark-2.2.2-bin-hadoop2.7 spark
2.4配置环境变量
vim ~/.bash_profile
添加如下内容
export SPARK_HOME=/home/hadoop/apps/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
重新加载配置文件
source ~/.bash_profile
2.5修改配置文件
先进入到配置文件目录
cd /home/hadoop/apps/spark/conf
2.5.1拷贝slaves和spark-env.sh文件
cp slaves.template slaves
cp spark-env.sh.template spark-env.sh
2.5.2修改slaves
vim slaves
配置spark的从节点的主机名,spark中的从节点叫做worker,主节点叫做Master
删除掉localhost,加入另外两台机器
hadoop02
hadoop03
2.5.3修改spark-env.sh
vi spark-env.sh
按G跳到最后,按O在下一行插入以下内容(配置相关路径),SPARK_WORKER_MEMORY的大小参考自己虚拟机内存,我的虚拟机为2G,这里我给1G内存,注意最好不要小于500M
export JAVA_HOME=/usr/local/jdk1.8.0_73
export SCALA_HOME=/home/hadoop/apps/scala
export SPARK_MASTER_IP=hadoop01
export SPARK_MASTER_PORT=7077 ##rpc通信端口,类似hdfs的9000端口,不是50070
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-2.7.6/etc/hadoop
2.5.4远程发送到其他节点
scala
scp -r /home/hadoop/apps/scala hadoop02:/home/hadoop/apps/
scp -r /home/hadoop/apps/scala hadoop03:/home/hadoop/apps/
spark
scp -r /home/hadoop/apps/spark hadoop02:/home/hadoop/apps/
scp -r /home/hadoop/apps/spark hadoop03:/home/hadoop/apps/
配置文件
scp ~/.bash_profile hadoop02:/home/hadoop/
scp ~/.bash_profile hadoop03:/home/hadoop/
给三台虚拟一起发送命令,重新加载配置文件
source ~/.bash_profile
2.6启动
2.6.1修改命令
因为hadoop中的启动与停止命令与spark中的相同,使用的时候会产生冲突,这里修改一下命令名,这里可以给三台机器同时发送下面三个命令
cd /home/hadoop/apps/spark/sbin
mv start-all.sh start-spark-all.sh
mv stop-all.sh stop-spark-all.sh
2.6.2启动spark集群
记得先启动hdfs
start-dfs.sh
这里在hadoop01上
start-spark-all.sh
查看进程
jps
可以看到Master与Worker成功启动
在地址栏访问 http://hadoop01:8080/
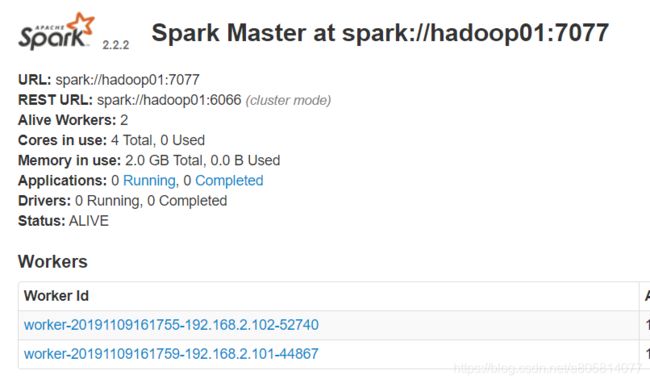
spark分布式集群搭建成功
3.配置HA环境
3.1修改配置文件
cd /home/hadoop/apps/spark/conf
vi spark-env.sh
只需要要原有的基础上加上一句话
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop01:2181,hadoop02:2181,hadoop03:2181 -Dspark.deploy.zookeeper.dir=/spark"
spark.deploy.recoveryMode设置成 ZK
spark.deploy.zookeeper.urlZooKeeper URL
spark.deploy.zookeeper.dir ZooKeeper 保存恢复状态的目录,缺省为 /spark
因为不确定master在哪个节点上面启动,所以这里将export SPARK_MASTER_IP=hadoop01和export SPARK_MASTER_PORT=7077注释
如图

然后将其发送到其他节点
scp -r spark-env.sh hadoop02: /home/hadoop/apps/spark/conf
scp -r spark-env.sh hadoop02: /home/hadoop/apps/spark/conf
HA环境配置成功!
3.2启动高可用集群
关掉刚才启动的集群
stop-dfs.sh
stop-spark-all.sh
在三个节点上启动zk
zkServer.sh start
重新启动hdfs
start-dfs.sh
重新启动集群
start-spark-all.sh
然后在hadoop02启动第二个master
start-master.sh
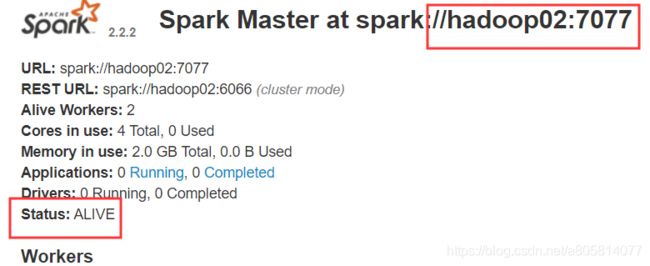
在地址栏访问 http://hadoop01:8080/ 与在地址栏访问 http://hadoop02:8080/
可以看到一个为ALIVE,一个为STANDBY

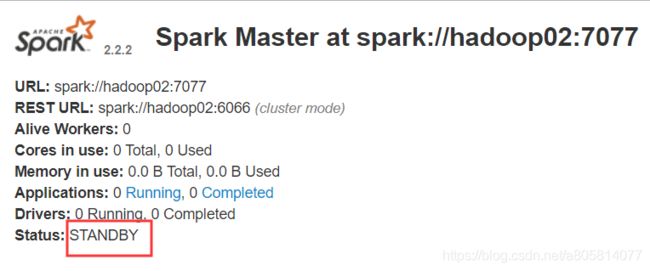
3.3测试
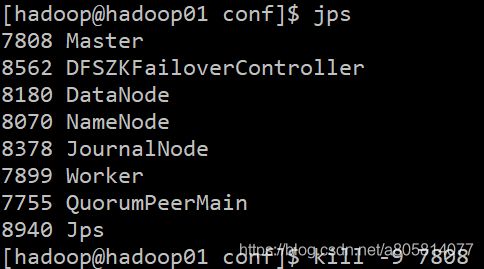
我这里hadoop01为ALIVE所以我再hadoop01杀掉该进程
jps
kill -9 7808
等待十几秒,访问 http://hadoop02:8080/ ,可以看到状态变成了ALIVE