卷积神经网络学习路线(二十) | Google ICCV 2019 MobileNet V3
前言
MobileNetV3是Google继MobileNet V1和MobileNet V2后的新作,主要使用了网络搜索算法(用NAS通过优化每个网络块来搜索全局网络结构,用NetAdapt算法搜索每个层的滤波器数量),同时在MobileNet V2网络结构基础上进行改进,并引入了SE模块(我们已经讲过了SENet,【cv中的Attention机制】最简单最易实现的SE模块)和提出了H-Swish激活函数。论文原文见附录。
关键点
1. 引入SE模块
下面的Figure3表示了MobileNet V2 Bottleneck的原始网络结构,然后Figure4表示在MobileNet V2 Bottleneck的基础上添加了一个SE模块。因为SE结构会消耗一定的时间,SE瓶颈的大小与卷积瓶颈的大小有关,我们将它们全部替换为固定为膨胀层通道数的1/4。这样做可以在适当增加参数数量的情况下提高精度,并且没有明显的延迟成本。并且SE模块被放在了Depthwise卷积后面。
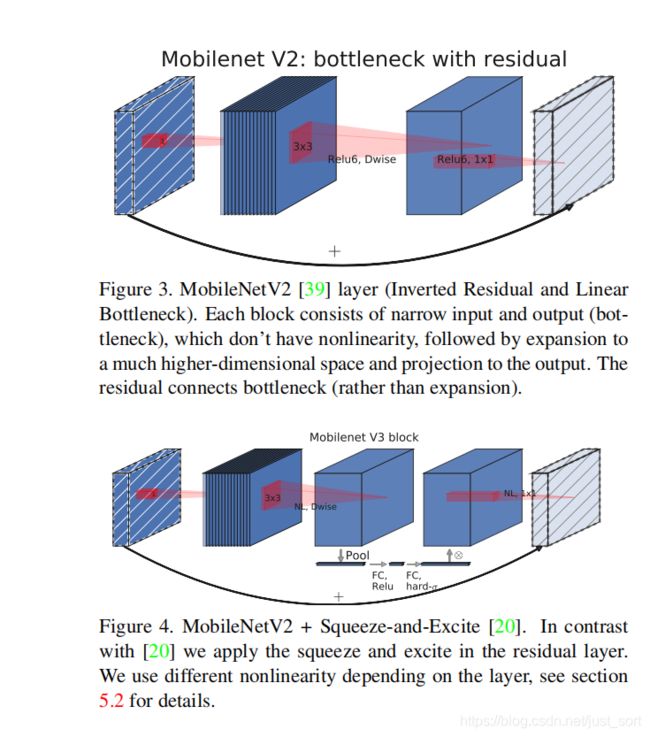
2. 更改网络末端计算量大的层
MobileNetV2的inverted bottleneck结构是使用了1*1卷积作为最后一层,以扩展到高维度的特征空间(也就是下图中的320->1280那一层的1*1卷积)。这一层的计算量是比较大的。MobileNetV3为了减少延迟并保留高维特性,将该1*1层移到最终的平均池化之后(960->Avg Pool->1*1 Conv)。现在计算的最后一组特征图从7*7变成了1*1,可以大幅度减少计算量。最后再去掉了Inverted Bottleneck中的Depthwise和1*1降维的层,在保证精度的情况下大概降低了15%的运行时间。

3. 更改初始卷积核的个数
修改网络头部卷积核通道数的数量,Mobilenet v2中使用的是 32 × 3 × 3 32\times 3\times 3 32×3×3,作者发现,其实 32 32 32可以再降低一点,所以这里改成了 16 16 16,在保证了精度的前提下,降低了 3 m s 3ms 3ms的速度。
4. H-Swish 激活函数
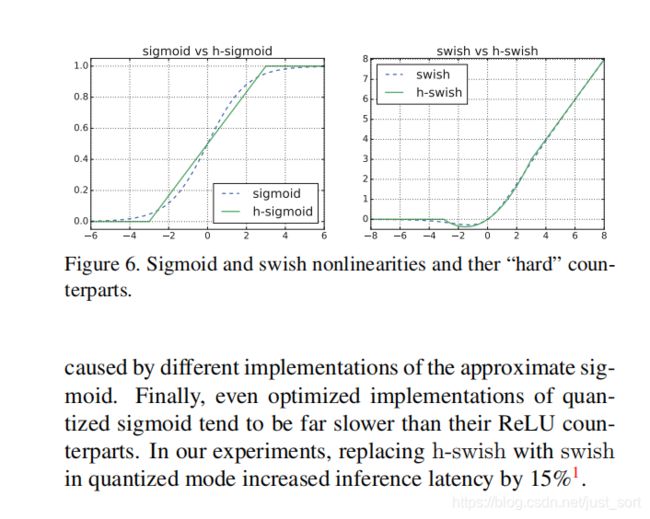
Mobilenet V3引入了新的非线性激活函数:H-Wwish。它是最近的Swish非线性函数的改进版本,计算速度比Swish更快(但比ReLU慢),更易于量化,精度上没有差异。其中Swish激活函数的公式如下:
s w i s h ( x ) = x ∗ δ ( x ) swish(x) = x*\delta(x) swish(x)=x∗δ(x)
其中 δ ( x ) \delta(x) δ(x)是sigmoid激活函数,而H-Swish的公式如下:
h − s w i s h ( x ) = x R e L U ( x + 3 ) 6 h-swish(x)=x\frac{ReLU(x+3)}{6} h−swish(x)=x6ReLU(x+3)
简单说下,Swish激活函数相对于ReLU来说提高了精度,但因为Sigmoid函数而计算量较大。而H-swish函数将Sigmoid函数替换为分段线性函数,使用的ReLU6在众多深度学习框架都可以实现,同时在量化时降低了数值的精度损失。下面这张图提到使用H-Swish在量化的时候可以提升15%的精度,还是比较吸引人的。
5. NAS搜索全局结构和NetAdapt搜索层结构
刚才已经提到MobileNet V3模块是参考了深度可分离卷积,MobileNetV2的具有线性瓶颈的反向残差结构(the inverted residual with linear bottleneck)以及MnasNe+SE的自动搜索模型。实际上上面的1-4点都是建立在使用NAS和NetAdapt搜索出MobileNet V3的基础结构结构之上的,自动搜索的算法我不太了解,感兴趣的可以去查看原文或者查阅资料。
网络结构
开头提到这篇论文提出了2种结构,一种Small,一种Large。结构如Table1和Table2所示:
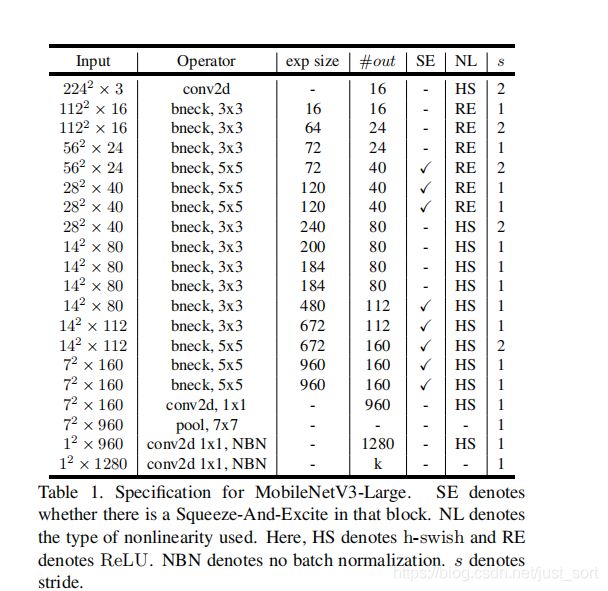
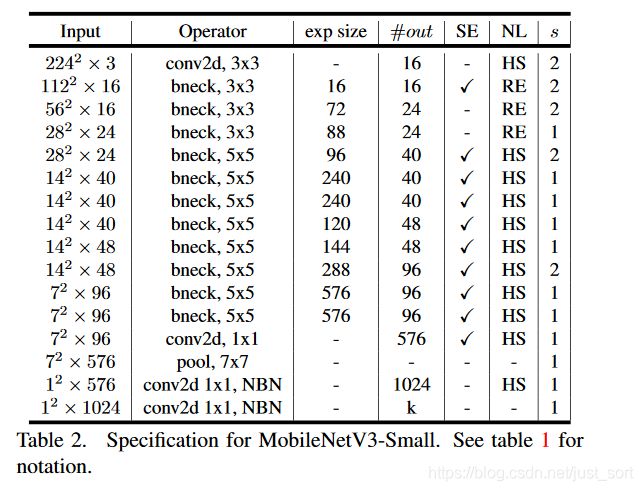
MobileNet V3-Small网络结构图可视化结果见推文最后的图片。
实验
分类都在ImageNet上面进行测试,并将准确率与各种资源使用度量(如推理时间和乘法加法(MAdds))进行比较。推理时间在谷歌Pixel-1/2/3系列手机上使用TFLite运行测试,都使用单线程大内核。下面的Figure1展示了性能和速度的比较结果。
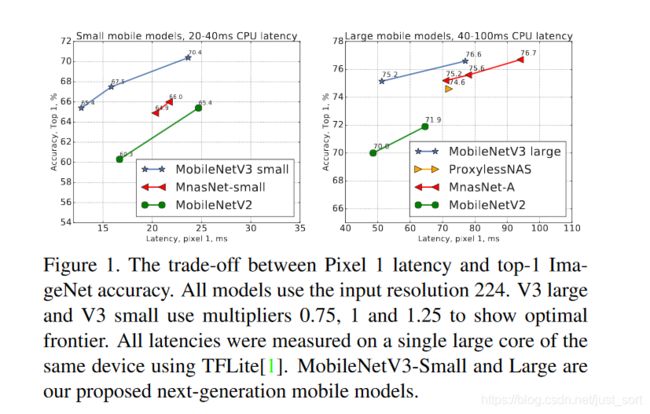
下面的Figure2是运算量和准确率的比较。
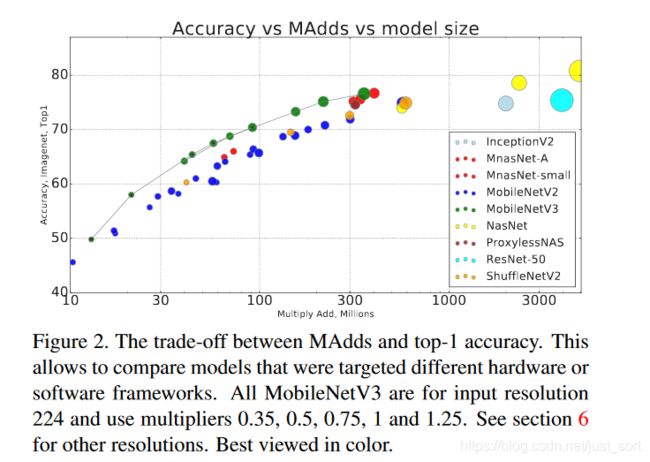
下面的Table3是分类性能和推理速度的比较,而Table4是量化后的结果。

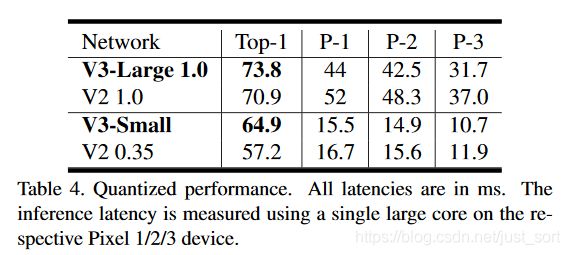
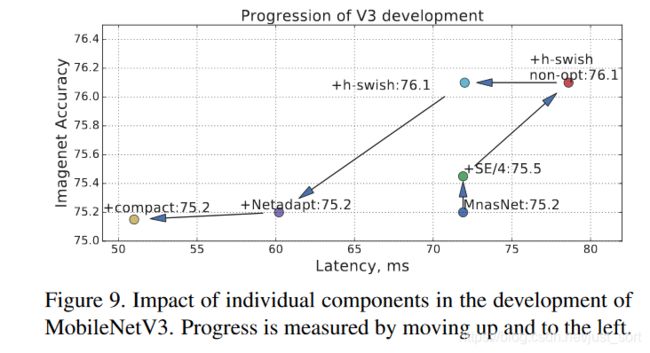
Figure 9展示了不同组件的引入是如何影响了延迟/准确度的。
 下面的Table6是在SSDLite中替换Backbone,在MSCOCO数据集上的比较结果。在通道缩减的情况下,MobileNetV3-Large(V3+)比具有几乎相同mAP值的MobileNetV2快25%。然后在相同的推理速度下,MobileNetV3-Small比MobileNetV2和MnasNet的mAP值高2.4和0.5。
下面的Table6是在SSDLite中替换Backbone,在MSCOCO数据集上的比较结果。在通道缩减的情况下,MobileNetV3-Large(V3+)比具有几乎相同mAP值的MobileNetV2快25%。然后在相同的推理速度下,MobileNetV3-Small比MobileNetV2和MnasNet的mAP值高2.4和0.5。
补充
在知乎上看到一个回答,蛮有趣的:
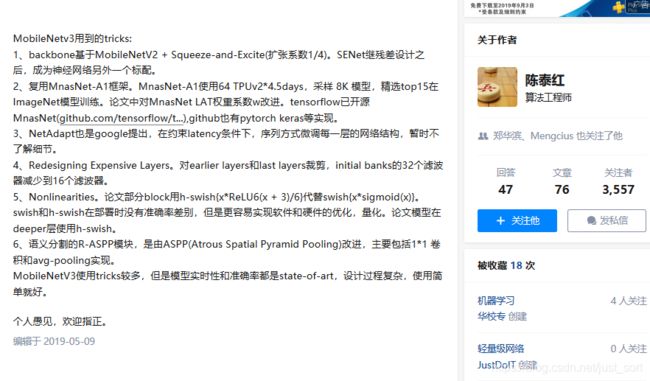
结论
基本上把MobileNet V3除了搜索网络结构的部分说完了,但是似乎这次Google开源的这个V3没有达到业界的预期吧。并且这篇论文给人的感觉是网络本身和相关的Trick很容易懂,但是具体是怎么搜索出V3以及预训练模型未开源这些问题仍会使我们一脸懵。但如果从工程角度来讲,毕竟使用简单,效果好对我们也足够了。
参考文章
- 论文原文:https://arxiv.org/pdf/1905.02244.pdf
- 源码实现:https://github.com/xiaolai-sqlai/mobilenetv3
- 参考资料1:https://zhuanlan.zhihu.com/p/69315156
- 参考资料2:http://tongtianta.site/paper/27865
推荐阅读
-
快2020年了,你还在为深度学习调参而烦恼吗?
-
卷积神经网络学习路线(一)| 卷积神经网络的组件以及卷积层是如何在图像中起作用的?
-
卷积神经网络学习路线(二)| 卷积层有哪些参数及常用卷积核类型盘点?
-
卷积神经网络学习路线(三)| 盘点不同类型的池化层、1*1卷积的作用和卷积核是否一定越大越好?
-
卷积神经网络学习路线(四)| 如何减少卷积层计算量,使用宽卷积的好处及转置卷积中的棋盘效应?
-
卷积神经网络学习路线(五)| 卷积神经网络参数设置,提高泛化能力?
-
卷积神经网络学习路线(六)| 经典网络回顾之LeNet
-
卷积神经网络学习路线(七)| 经典网络回顾之AlexNet
-
卷积神经网络学习路线(八)| 经典网络回顾之ZFNet和VGGNet
-
卷积神经网络学习路线(九)| 经典网络回顾之GoogLeNet系列
-
卷积神经网络学习路线(十)| 里程碑式创新的ResNet
-
卷积神经网络学习路线(十一)| Stochastic Depth(随机深度网络)
-
卷积神经网络学习路线(十二)| 继往开来的DenseNet
-
卷积神经网络学习路线(十三)| CVPR2017 Deep Pyramidal Residual Networks
-
卷积神经网络学习路线(十四) | CVPR 2017 ResNeXt(ResNet进化版)
-
卷积神经网络学习路线(十五) | NIPS 2017 DPN双路网络
-
卷积神经网络学习路线(十六) | ICLR 2017 SqueezeNet
-
卷积神经网络学习路线(十七) | Google CVPR 2017 MobileNet V1
-
卷积神经网络学习路线(十八) | Google CVPR 2018 MobileNet V2
-
卷积神经网络学习路线(十九) | 旷世科技 2017 ShuffleNetV1
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

MobileNetV3 Small结构可视化图
