详解数据库的第一范式、第二范式、第三范式、BCNF范式
目录
- 第一范式
- 定义以及分析:
- 问题研究:
- 第二范式
- 必备知识点
- 定义
- 分析:
- 解决办法:
- 问题研究:
- 第三范式:
- 定义:
- 分析:
- 问题分析:
- BCNF范式
- 分析
- 问题研究
- 小结:
- 参考文献
第一范式
定义以及分析:
首先是第一范式(1NF)。符合1NF的关系(你可以理解为数据表。“关系模式”和“关系”的区别,类似于面向对象程序设计中”类“与”对象“的区别。”关系“是”关系模式“的一个实例,你可以把”关系”理解为一张带数据的表,而“关系模式”是这张数据表的表结构。1NF的定义为:符合1NF的关系中的每个属性都不可再分。表1所示的情况,就不符合1NF的要求。范式一强调数据表的原子性。
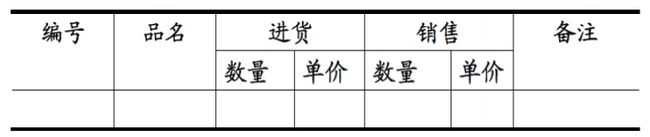
实际上,1NF是所有关系型数据库的最基本要求,你在关系型数据库管理系统(RDBMS),例如SQL Server,Oracle,MySQL中创建数据表的时候,如果数据表的设计不符合这个最基本的要求,那么操作一定是不能成功的。也就是说,只要在RDBMS中已经存在的数据表,一定是符合1NF的。如果我们要在RDBMS中表现表中的数据,就得设计为表2的形式:
| 编号 | 品名 | 进货数量 | 进货单价 | 销售数量 | 销售单价 | 备注 |
|---|---|---|---|---|---|---|
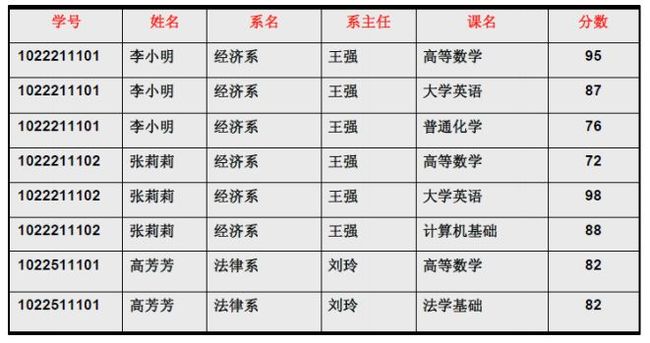
但是仅仅符合1NF的设计,仍然会存在数据冗余过大,插入异常,删除异常,修改异常的问题,例如对于表3中的设计:
问题研究:
但是表三中的设计我们能看到许多的问题,以下:
- 每一名学生的学号、姓名、系名、系主任这些数据重复多次。每个系与对应的系主任的数据也重复多次——数据冗余过大
- 假如学校新建了一个系,但是暂时还没有招收任何学生(比如3月份就新建了,但要等到8月份才招生),那么是无法将系名与系主任的数据单独地添加到数据表中去的 (注1)——插入异常
注1:根据三种关系完整性约束中实体完整性的要求,关系中的码(注2)所包含的任意一个属性都不能为空,所有属性的组合也不能重复。为了满足此要求,图中的表,只能将学号与课名的组合作为码,否则就无法唯一地区分每一条记录。注2:码:关系中的某个属性或者某几个属性的组合,用于区分每个元组(可以把“元组”理解为一张表中的每条记录,也就是每一行)。
- 假如将某个系中所有学生相关的记录都删除,那么所有系与系主任的数据也就随之消失了(一个系所有学生都没有了,并不表示这个系就没有了)。——删除异常
- 假如李小明转系到法律系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据。——修改异常。
正因为仅符合1NF的数据库设计存在着这样那样的问题,我们需要提高设计标准,去掉导致上述四种问题的因素,使其符合更高一级的范式(2NF),这就是所谓的“规范化”。
第二范式
第二范式(2NF)在关系理论中的严格定义我这里就不多介绍了(因为涉及到的铺垫比较多),只需要了解2NF对1NF进行了哪些改进即可。其改进是,2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖。接下来对这句话中涉及到的四个概念——“函数依赖”、“码”、“非主属性”、与“部分函数依赖”进行一下解释。
必备知识点
函数依赖:
我们可以这么理解(但并不是特别严格的定义):若在一张表中,在属性(或属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作 X → Y。也就是说,在数据表中,不存在任意两条记录,它们在X属性(或属性组)上的值相同,而在Y属性上的值不同。这也就是“函数依赖”名字的由来,类似于函数关系 y = f(x),在x的值确定的情况下,y的值一定是确定的。
例如,对于表3中的数据,找不到任何一条记录,它们的学号相同而对应的姓名不同。所以我们可以说姓名函数依赖于学号,写作 学号 → 姓名。但是反过来,因为可能出现同名的学生,所以有可能不同的两条学生记录,它们在姓名上的值相同,但对应的学号不同,所以我们不能说学号函数依赖于姓名。表中其他的函数依赖关系还有如:
- 系名 → 系主任
- 学号 → 系主任
- (学号,课名) → 分数
但以下函数依赖关系则不成立:
- 学号 → 课名
- 学号 → 分数
- 课名 → 系主任
- (学号,课名) → 姓名
由函数依赖,我们引出下面的一些概念
部分函数依赖:设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则称Y部分函数依赖于X。
例1:
| 学号 | 身份证号 | 姓名 |
|---|
表4
上表中(学号,身份证号,姓名)当然学号属性取值是唯一的,在R关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号).
例2:
| sno | grade | cno |
|---|
表5
在上表中,因为Sno不能函数决定Grade,Cno也不能函数决定Grade,但(Sno,Cno)可以唯一地函数决定Grade,所以(Sno,Cno)→Grade是完全函数依赖。因为Sno可以函数决定Sage,所以(Sno,Cno)→Sage是部分函数依赖。
例3:
| Sno | Sname | Sage | Sdept |
|---|
表6
在上表中,函数依赖的决定方是Sno,是单属性,所以Sno→(Sname,Sage,Sdept)是完全函数依赖,不存在着部分函数依赖。
由此,我们知道。只有当函数依赖的决定方是组合属性时,讨论部分函数依赖才有意义,当函数依赖的决定方是单属性时,只能是完全函数依赖。
完全函数依赖:设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。
例子:学生基本信息表R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在R关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
传递函数依赖:在关系模式R(U)中,设X,Y,Z是U的不同的属性子集,如果X确定Y、Y确定Z,且有X不包含Y,Y不确定X,(X∪Y)∩Z=空集合,则称Z传递函数依赖(transitive functional dependency) 于X。
例子:
| 学号 | 宿舍 | 费用 |
|---|---|---|
| 062201 | A | 900 |
| 062230 | B | 1200 |
| 062240 | B | 1200 |
表7
学号确定宿舍、宿舍确定费用,且有学号不包含宿舍,宿舍不确定学号,符合传递函数依赖条件。
所以以上关系R存在添加异常(建了C宿舍但是没人住无法添加了)删除异常(学生062201退学了宿舍A也删除掉)如果存在传递函数依赖,如下更改:将上表拆解为两个表
| 学号 | 宿舍 |
|---|---|
| 062201 | A |
| 062230 | B |
| 062240 | B |
表8
| 宿舍 | 费用 |
|---|---|
| A | 900 |
| B | 1200 |
| B | 1200 |
表9
码:设 K 为某表中的一个属性或属性组,若除 K 之外的所有属性都完全函数依赖于 K(这个“完全”不要漏了),那么我们称 K 为候选码,简称为码。在实际中我们通常可以理解为:假如当 K 确定的情况下,该表除 K 之外的所有属性的值也就随之确定,那么 K 就是码。一张表中可以有超过一个码。(实际应用中为了方便,通常选择其中的一个码作为主码) 例如:对于表3,(学号、课名)这个属性组就是码。该表中有且仅有这一个码。(假设所有课没有重名的情况)
非主属性
包含在任何一个码中的属性成为主属性。除了主属性以外的就是非主属性。例如:对于表3,主属性就有两个,学号 与 课名。
定义
第二范式(Second Normal Form,2nd NF)是指每个表必须有一个(而且仅有一个)数据元素为主关键字(Primary key),其他数据元素与主关键字一一对应。通常称这种关系为函数依赖(Functional dependence)关系,即表中其他数据元素都依赖于主关键字,或称该数据元素惟一地被主关键字所标识。第二范式是数据库规范化中所使用的一种正规形式。它的规则是要求数据表里的所有非主属性都要和该数据表的主键有完全依赖关系;如果有哪些非主属性只和主键的一部份有关的话,它就不符合第二范式。同时可以得出:如果一个数据表的主键只有单一一个字段的话,它就一定符合第二范式(前提是该数据表符合第一范式)
分析:
根据2NF的定义,判断的依据实际上就是看数据表中是否存在非主属性对于码的部分函数依赖。若存在,则数据表最高只符合1NF的要求,若不存在,则符合2NF的要求。判断的方法是:
- 第一步:找出数据表中所有的码。
- 第二步:根据第一步所得到的码,找出所有的主属性。
- 第三步:数据表中,除去所有的主属性,剩下的就都是非主属性了。
- 第四步:查看是否存在非主属性对码的部分函数依赖。
对于表3,根据前面所说的四步,我们可以这么做:
第一步:
(1)查看所有每一单个属性,当它的值确定了,是否剩下的所有属性值都能确定。
(2)查看所有包含有两个属性的属性组,当它的值确定了,是否剩下的所有属性值都能确定。
(3) ……
(4) 查看所有包含了六个属性,也就是所有属性的属性组,当它的值确定了,是否剩下的所有属性值都能确定。
小技巧:就是假如A是码,那么所有包含了A的属性组,如(A,B)、(A,C)、(A,B,C)等等,都不是码了(因为作为码的要求里有一个“完全函数依赖”)。
我们根据第一个步骤确定出函数依赖关系,并画图如下(表3的函数关系)
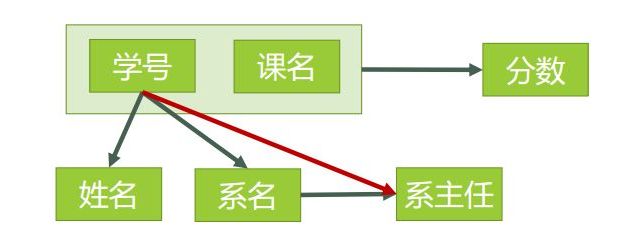
图1
由此可以得到,表3的码只有一个,就是(学号、课名)。
第二步:
主属性有两个:学号 与 课名
第三步:
非主属性有四个:姓名、系名、系主任、分数
第四步:
- 对于(学号,课名) → 姓名,有 学号 → 姓名,存在非主属性 姓名 对码(学号,课名)的部分函数依赖。
- 对于(学号,课名) → 系名,有 学号 → 系名,存在非主属性 系名 对码(学号,课名)的部分函数依赖。
- 对于(学号,课名) → 系主任,有 学号 → 系主任,存在非主属性 对码(学号,课名)的部分函数依赖。
所以表3存在非主属性对于码的部分函数依赖,最高只符合1NF的要求,不符合2NF的要求。
解决办法:
为了让表3符合2NF的要求,我们必须消除这些部分函数依赖,只有一个办法,就是将大数据表拆分成两个或者更多个更小的数据表,在拆分的过程中,要达到更高一级范式的要求,这个过程叫做”模式分解“。
模式分解部分,很难,参考很多文献不得甚解。希望后来者能答疑解惑
大概觉得相关的具体操作可以从以下几点来考量:
1.码(码就是候选码)是多个的时候,一般每一个码需要进行分解,基于每一个候选码的函数依赖要归并到与当前候选码一致的分解中去。
2.码中有多个元素的时候,并且存在基于该码的部分函数依赖的时候,将其进行分解
3.根据函数依赖分解完属性组之后进行化简,去掉每一个分组的重复选项
4.尝试将化简之后的分组重新进行连接操作,对比分解之前的关系模式是不是一致
5.一致则可以认为这种化简是有效的
我们根据以上准则对表3进行分解
1.码只有一个(学号,课号),无需分解
2.码中有部分函数依赖,将其进行分解,分解为两个模式。如下图所示
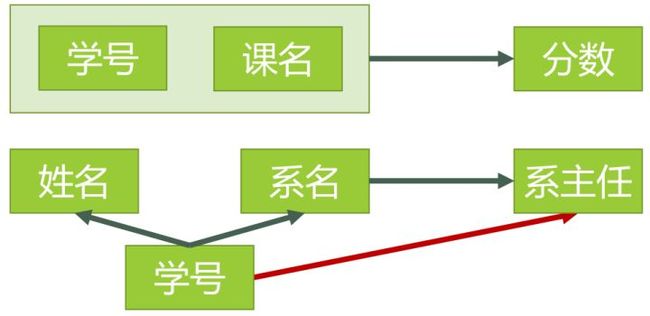
图2
3.无重复项,无需分解
4.重新连接,对比分析前,关系一致。
5.该模式分解有效。
分解后的表的形式如下
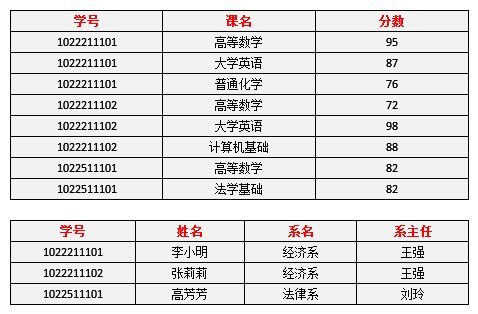
表10
问题研究:
现在我们来看一下,进行同样的操作,是否还存在着之前的那些问题?
1、李小明转系到法律系只需要修改一次李小明对应的系的值即可。——有改进数据冗余是否减少了?
2、学生的姓名、系名与系主任,不再像之前一样重复那么多次了。——有改进
3、删除某个系中所有的学生记录该系的信息仍然全部丢失。——无改进
4、插入一个尚无学生的新系的信息。因为学生表的码是学号,不能为空,所以此操作不被允许。——无改进
所以说,仅仅符合2NF的要求,很多情况下还是不够的,而出现问题的原因,在于仍然存在非主属性系主任对于码学号的传递函数依赖。为了能进一步解决这些问题,我们还需要将符合2NF要求的数据表改进为符合3NF的要求。
第三范式:
定义:
第三范式(Third Normal Form,3rd NF)就是指表中的所有数据元素不但要能惟一地被主关键字所标识,而且它们之间还必须相互独立,不存在其他的函数关系。也就是说,对于一个满足2nd NF 的数据结构来说,表中有可能存在某些数据元素依赖于其他非关键字数据元素的现象,必须消除。
通俗的说,第三范式(3NF)3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖。也就是说, 如果存在非主属性对于码的传递函数依赖,则不符合3NF的要求。
分析:
接下来我们看看表10中的设计,是否符合3NF的要求。对于选课表,主码为(学号,课名),主属性为学号和课名,非主属性只有一个,为分数,不可能存在传递函数依赖,所以选课表的设计,符合3NF的要求。
对于学生表,主码为学号,主属性为学号,非主属性为姓名、系名和系主任。因为 学号 → 系名,同时 系名 → 系主任,所以存在非主属性系主任对于码学号的传递函数依赖,所以学生表的设计,不符合3NF的要求。为了让数据表设计达到3NF,我们必须进一步进行模式分解为以下形式:选课(学号,课名,分数)学生(学号,姓名,系名)系(系名,系主任)对于选课表,符合3NF的要求,之前已经分析过了。对于学生表,码为学号,主属性为学号,非主属性为系名,不可能存在非主属性对于码的传递函数依赖,所以符合3NF的要求。对于系表,码为系名,主属性为系名,非主属性为系主任,不可能存在非主属性对于码的传递函数依赖(至少要有三个属性才可能存在传递函数依赖关系),所以符合3NF的要求。。
我们画出新的函数依赖关系图如下:
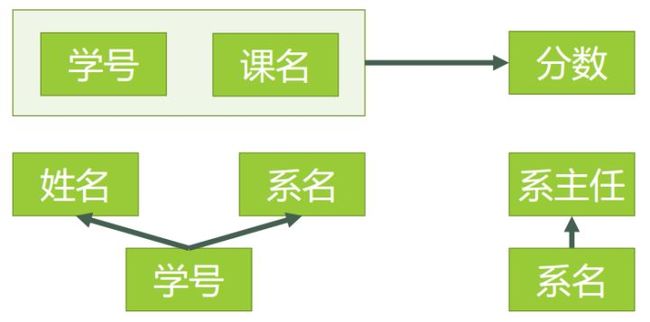
图3
我们得到新的关系表如下:
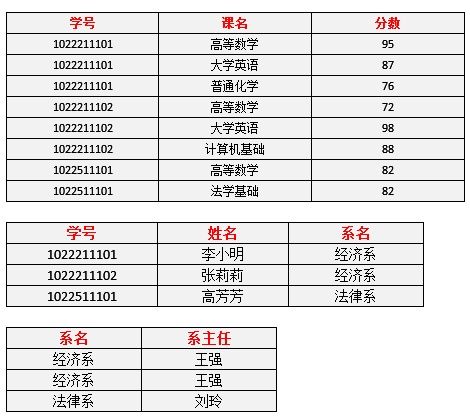
表11
问题分析:
现在我们来看一下,进行同样的操作,是否还存在着之前的那些问题?
- 删除某个系中所有的学生记录,该系的信息不会丢失。——有改进
- 插入一个尚无学生的新系的信息。因为系表与学生表目前是独立的两张表,所以不影响。——有改进
- 数据冗余更加少了。——有改进
BCNF范式
分析
要了解 BCNF 范式,那么先看这样一个问题:
若:某公司有若干个仓库;每个仓库只能有一名管理员,一名管理员只能在一个仓库中工作;一个仓库中可以存放多种物品,一种物品也可以存放在不同的仓库中。每种物品在每个仓库中都有对应的数量。那么关系模式 仓库(仓库名,管理员,物品名,数量) 属于哪一级范式?
答:已知函数依赖集:仓库名 → 管理员,管理员 → 仓库名,(仓库名,物品名)→ 数量码:(管理员,物品名),(仓库名,物品名)主属性:仓库名、管理员、物品名非主属性:数量∵ 不存在非主属性对码的部分函数依赖和传递函数依赖。∴ 此关系模式属于3NF。基于此关系模式的关系(具体的数据)如下表所示:
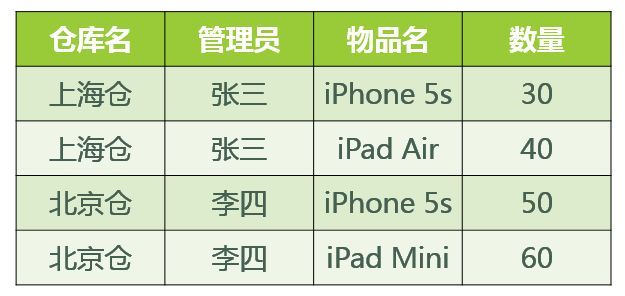
表12
问题研究
好,既然此关系模式已经属于了 3NF,那么这个关系模式是否存在问题呢?我们来看以下几种操作:
- 先新增加一个仓库,但尚未存放任何物品,是否可以为该仓库指派管理员?
——不可以,因为物品名也是主属性,根据实体完整性的要求,主属性不能为空。 - 某仓库被清空后,需要删除所有与这个仓库相关的物品存放记录,会带来什么问题?
——仓库本身与管理员的信息也被随之删除了。 - 如果某仓库更换了管理员,会带来什么问题?
——这个仓库有几条物品存放记录,就要修改多少次管理员信息。
从这里我们可以得出结论,在某些特殊情况下,即使关系模式符合 3NF 的要求,仍然存在着插入异常,修改异常与删除异常的问题,仍然不是 ”好“ 的设计。
造成此问题的原因:存在着主属性对于码的部分函数依赖与传递函数依赖。(在此例中就是存在主属性【仓库名】对于码【(管理员,物品名)】的部分函数依赖。解决办法就是要在 3NF 的基础上消除主属性对于码的部分与传递函数依赖。
仓库(仓库名,管理员)库存(仓库名,物品名,数量)
这样,之前的插入异常,修改异常与删除异常的问题就被解决了。
以上就是关于 BCNF 的解释。
小结:
至今为止没有亲自设计过数据库,最多也就是在课堂上做过数据库课程设计。将来如果自己设计数据库了,再回头看这一篇博客。修改修改。本文中大量内容和案例,来自于知乎上刘老师,后文附有参考链接。
参考文献
- 链接:https://www.zhihu.com/question/24696366/answer/29189700
- 链接:http://blog.csdn.net/rl529014/article/details/48391465