Kafka深入分析
1.概述
Kafka起初是由LinkedIn公司开发的一个分布式的消息系统,后来成为Apache的一部分,它使用Scala编写,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark等都支持Kafka集成。
Kafka凭借着自身的优势,越来越受到互联网企业的青睐,唯品会也采用Kafka作为其内部核心消息引擎之一。Kafka作为一个商业级消息中间件,消息可靠性的重要性可想而知。如何确保消息的精确传输?如何确保消息的正确消费?如何确保消息的准确存储?这些都需要考虑的问题。
2.Kafka体系架构
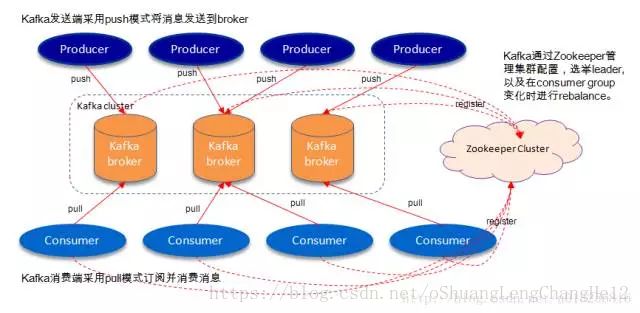
一个典型的的Kafka体系架构包括若干Producer(可以是服务器日志,业务数据,页面前端产生的page view等等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐量越高),若干Consumer(Group),以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。Producer使用push模式将消息发布到broker,Consumer使用pull模式从broker订阅并消费消息。
3.名词解释
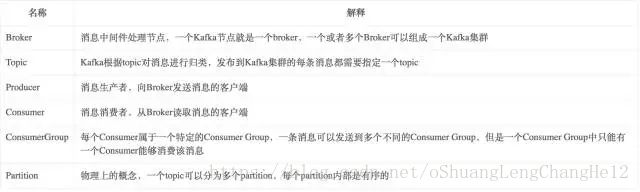
4.Topic&Partition
一个topic可认为一个一类消息,每个topic将被分成多个partition,每个partition在存储层面是append log文件。任何发布到此partition的消息都会被追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型的数字,它唯一标记一条消息。每条消息都被append到partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐量的一个很重要的保证)。
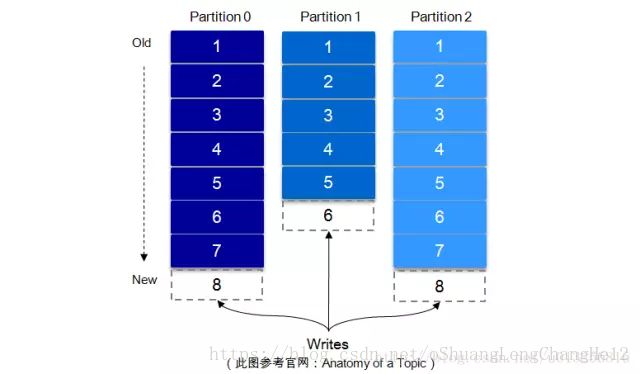
每一条消息被发送到broker中,会根据partition规则选择被存储到哪一个partiton。如果partitoin规则设置的合理,所有消息可以均匀分布到不同的partition,这样就实现了水平扩展(如果一个topic对应一个文件,那么这个文件所在的机器I/O将会成为这个topic的性能瓶颈)。
5.高可靠性存储分析
Kafka的高可靠性的保障来源于其健壮的副本(replication)策略。通过调节其副本相关参数,可以使得Kafka在性能和可靠性之间运转得游刃有余。Kafka从0.8.x版本开始提供partition级别的复制,replication的数量可以在$KAFKA_HOME/config/server.properties中配置(default.replication.refactor)。
这里先从Kafka文件存储机制入手,从最底层了解Kafka的存储细节,进而对其的存储有个微观的认知。之后通过Kafka复制原理和同步方式来阐述宏观层面的概念。最后从ISR,HW,leader选举以及数据可靠性和持久性保证等等各个维度来丰富对Kafka相关知识点的认知。
Kafka中消息是以topic进行分类的,生产者通过topic向Kafka broker发送消息,消费者通过topic读取数据,topic可以分成若干个partition,partition还可以细分为segment,一个partition物理上由多个segment组成。
Kafka中topic的每个partition有一个预写式的日志文件,虽然partiton可以继续细分问若干个segment文件,但是对于上层应用来说可以将partition看成最小的存储单元(一个有多个segment文件拼接的“巨型”文件),每个partition都由一些列有序的、不可变的消息组成,这些消息被连续的追加到partition中。
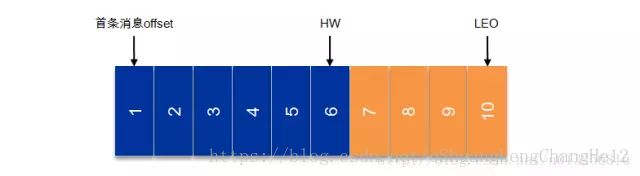
上图中有两个新名词:HW和LEO。这里先介绍下LEO,LogEndOffset的缩写,表示每个partition的log最后一条Message的位置。HW是HighWatermark的缩写,是指consumer能够看到的此partition的位置,这个涉及到多副本的概念。
为了提高消息的可靠性,Kafka每个topic的partition有N个副本(replicas),其中N(大于等于1)是topic的复制因子(replica fator)的个数。Kafka通过多副本机制实现故障自动转移,当Kafka集群中一个broker失效情况下仍然保证服务可用。在Kafka中发生复制时确保partition的日志能有序的写到其他节点上,N个replicas中,其中一个replica为leader,其他都为follower,leader处理partition的所有读写请求,与此同时,follower会被动定期的去复制leader上的数据。
6.高可靠性使用分析
Kafka如何确保消息在producer和consumer之间传输,有以下三种可能的传输保障:
At most once:消息可能会丢,但绝不会重复传输
At least once:消息绝不会丢,但可能会重复传输
Exactly once:每条消息肯定会被传输一次且仅传输一次
Kafka的消息传输保障机制非常直观。当producer向broker发送消息时,一旦这条消息被commit,由于副本机制(replication)的存在,它就不会丢失。但是如果producer发送数据给broker后,遇到的网络问题而造成通信中断,那producer就无法判断该条消息是否已经提交(commit)。虽然Kafka无法确定网络故障期间发生了什么,但是producer可以retry多次,确保消息已经正确传输到broker中,所以目前Kafka实现的是at least once。
Consumer从broker中读取消息后,可以选择commit,该操作在Zookeeper中存下该consumer下一次再读该partition时会从下一条开始读取。如未commit,下一次读取的开始位置会跟上一次commit之后的开始位置相同。当然也可以将consumer设置为auto commit,即consumer一旦读取到数据立即自动commit。如果只讨论这一读取消息的过程,那Kafka是确保了exactly once,但是如果由于前面producer与broker之间的某种原因导致消息的重复,那么这里就是at least once。
考虑这样一种情况,当consumer读完消息之后先commit再处理消息,在这种模式下,如果consumer在commit后还没来得及处理消息就crash了,下次重新开始工作后就无法读取刚刚已经提交而未处理的消息,这就是对应的at most once。
读完消息先处理再commit。这种模式下,如果处理了消息在commit之前consumer crash了,下次重新开始工作时还会处理刚刚未commit的消息,实际上该消息已经处理了,这就是对应的at least once。