故障描述
时间,监控一直报警,某个接口的响应时间会周期性的变慢;检查报警日志发现,报警机器都来自同一个机房;奇怪的是,其他机房的同一接口却并没有变慢;
排查过程
首先怀疑访问的资源是不是有问题,检查之后发现并没有任何问题;向运维申请权限之后,查看机器的GC日志,一看,吓了一条,机器在不停的进行CMS GC,日志如下:
2017-07-10T00:27:38.561+0800: 222046.226: [GC (CMS Initial Mark) [1 CMS-initial-mark: 761762K(1048576K)] 866632K(1992320K), 0.0188394 secs] [Times: user=0.11 sys=0.00, real=0.02 secs]
2017-07-10T00:27:38.581+0800: 222046.245: [CMS-concurrent-mark-start]
2017-07-10T00:27:38.992+0800: 222046.656: [CMS-concurrent-mark: 0.411/0.411 secs] [Times: user=0.85 sys=0.01, real=0.41 secs]
2017-07-10T00:27:38.992+0800: 222046.656: [CMS-concurrent-preclean-start]
2017-07-10T00:27:38.996+0800: 222046.660: [CMS-concurrent-preclean: 0.004/0.004 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2017-07-10T00:27:38.996+0800: 222046.660: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 2017-07-10T00:27:44.134+0800: 222051.799: [CMS-concurrent-abortable-preclean: 5.137/5.138 secs] [Times: user=5.32 sys=0.06, real=5.14 secs]
2017-07-10T00:27:44.135+0800: 222051.800: [GC (CMS Final Remark) [YG occupancy: 140252 K (943744 K)]2017-07-10T00:27:44.136+0800: 222051.800: [Rescan (parallel) , 0.0261302 secs]2017-07-10T00:27:44.162+0800: 222051.826: [weak refs processing, 0.0001257 secs]2017-07-10T00:27:44.162+0800: 222051.826: [class unloading, 0.0235377 secs]2017-07-10T00:27:44.185+0800: 222051.850: [scrub symbol table, 0.0064071 secs]2017-07-10T00:27:44.192+0800: 222051.856: [scrub string table, 0.0012990 secs][1 CMS-remark: 761762K(1048576K)] 902015K(1992320K), 0.0577149 secs] [Times: user=0.24 sys=0.00, real=0.06 secs]
2017-07-10T00:27:44.193+0800: 222051.858: [CMS-concurrent-sweep-start]
2017-07-10T00:27:44.963+0800: 222052.627: [CMS-concurrent-sweep: 0.769/0.769 secs] [Times: user=0.80 sys=0.02, real=0.77 secs]
2017-07-10T00:27:44.963+0800: 222052.627: [CMS-concurrent-reset-start]
2017-07-10T00:27:44.965+0800: 222052.629: [CMS-concurrent-reset: 0.002/0.002 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2017-07-10T00:28:36.805+0800: 222104.470: [GC (Allocation Failure) 2017-07-10T00:28:36.805+0800: 222104.470: [ParNew
Desired survivor size 80510976 bytes, new threshold 6 (max 6)
- age 1: 1670280 bytes, 1670280 total
: 943744K->104832K(943744K), 0.0949423 secs] 1323361K->589707K(1992320K), 0.0951679 secs] [Times: user=0.53 sys=0.01, real=0.10 secs]
2017-07-10T00:28:37.823+0800: 222105.488: [GC (Allocation Failure) 2017-07-10T00:28:37.824+0800: 222105.488: [ParNew
Desired survivor size 80510976 bytes, new threshold 1 (max 6)
- age 1: 106303472 bytes, 106303472 total
- age 2: 1043512 bytes, 107346984 total
: 943744K->104832K(943744K), 0.4966488 secs] 1428619K->717627K(1992320K), 0.4968997 secs] [Times: user=3.66 sys=0.01, real=0.50 secs]
2017-07-10T00:29:20.274+0800: 222147.938: [GC (Allocation Failure) 2017-07-10T00:29:20.274+0800: 222147.939: [ParNew
Desired survivor size 80510976 bytes, new threshold 1 (max 6)
- age 1: 107347632 bytes, 107347632 total
: 943744K->104832K(943744K), 0.3041730 secs] 1556539K->867316K(1992320K), 0.3044353 secs] [Times: user=2.12 sys=0.01, real=0.30 secs]
2017-07-10T00:29:20.580+0800: 222148.244: [GC (CMS Initial Mark) [1 CMS-initial-mark: 762484K(1048576K)] 867363K(1992320K), 0.0184973 secs] [Times: user=0.10 sys=0.01, real=0.02 secs]
2017-07-10T00:29:20.599+0800: 222148.263: [CMS-concurrent-mark-start]
2017-07-10T00:29:21.034+0800: 222148.698: [CMS-concurrent-mark: 0.435/0.435 secs] [Times: user=0.91 sys=0.01, real=0.44 secs]
2017-07-10T00:29:21.034+0800: 222148.698: [CMS-concurrent-preclean-start]
2017-07-10T00:29:21.040+0800: 222148.704: [CMS-concurrent-preclean: 0.006/0.006 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2017-07-10T00:29:21.040+0800: 222148.704: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 2017-07-10T00:29:26.197+0800: 222153.862: [CMS-concurrent-abortable-preclean: 5.157/5.157 secs] [Times: user=5.38 sys=0.07, real=5.16 secs]
2017-07-10T00:29:26.199+0800: 222153.863: [GC (CMS Final Remark) [YG occupancy: 152740 K (943744 K)]2017-07-10T00:29:26.199+0800: 222153.863: [Rescan (parallel) , 0.0263032 secs]2017-07-10T00:29:26.225+0800: 222153.889: [weak refs processing, 0.0001888 secs]2017-07-10T00:29:26.225+0800: 222153.890: [class unloading, 0.0286006 secs]2017-07-10T00:29:26.254+0800: 222153.918: [scrub symbol table, 0.0113296 secs]2017-07-10T00:29:26.265+0800: 222153.930: [scrub string table, 0.0016177 secs][1 CMS-remark: 762484K(1048576K)] 915225K(1992320K), 0.0682597 secs] [Times: user=0.24 sys=0.00, real=0.07 secs]
2017-07-10T00:29:26.267+0800: 222153.932: [CMS-concurrent-sweep-start]
2017-07-10T00:29:26.985+0800: 222154.650: [CMS-concurrent-sweep: 0.718/0.718 secs] [Times: user=0.77 sys=0.01, real=0.72 secs]
2017-07-10T00:29:26.986+0800: 222154.650: [CMS-concurrent-reset-start]
2017-07-10T00:29:26.988+0800: 222154.652: [CMS-concurrent-reset: 0.003/0.003 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2017-07-10T00:29:40.748+0800: 222168.412: [GC (Allocation Failure) 2017-07-10T00:29:40.748+0800: 222168.412: [ParNew
Desired survivor size 80510976 bytes, new threshold 6 (max 6)
- age 1: 40404536 bytes, 40404536 total
: 943744K->100515K(943744K), 0.1270597 secs] 1324617K->585666K(1992320K), 0.1273832 secs] [Times: user=0.73 sys=0.02, real=0.12 secs]
2017-07-10T00:29:41.544+0800: 222169.208: [GC (Allocation Failure) 2017-07-10T00:29:41.544+0800: 222169.208: [ParNew
Desired survivor size 80510976 bytes, new threshold 2 (max 6)
- age 1: 67918336 bytes, 67918336 total
- age 2: 39428848 bytes, 107347184 total
: 939427K->104832K(943744K), 0.4560649 secs] 1424578K->782170K(1992320K), 0.4564709 secs] [Times: user=3.26 sys=0.01, real=0.46 secs]
2017-07-10T00:29:42.002+0800: 222169.667: [GC (CMS Initial Mark) [1 CMS-initial-mark: 677338K(1048576K)] 796205K(1992320K), 0.0171894 secs] [Times: user=0.11 sys=0.00, real=0.02 secs]
可以看到每隔一分钟左右,由于Allocation Failure导致ParNew GC,而由于存活对象太大,导致又进行了CMS GC;
通过jmap发现果然每隔一段时间,内存中BaseEntry类的对象实例数目急剧增大,检查业务代码发现,业务代码中有段逻辑会周期性的获取最新的IP列表;而判断列表是否有更新,是通过对文件内容md5判断的,正常情况下,文件变化频率会很小,那为什么现在会频繁更新呢?
调用接口发现,IP服务返回的md5并没有变化,但本地文件的md5和服务端不一样;打开文件发现,本地文件存在乱码;
问题的原因基本找到,应该是由于文件乱码导致的,让开发人员修改代码,在保存文件时指定编码,问题得到解决;
故障原因
线上问题是得到了解决,但是奇怪的是,同样的代码为什么其他机房不存在问题呢?检查服务器编码配置:
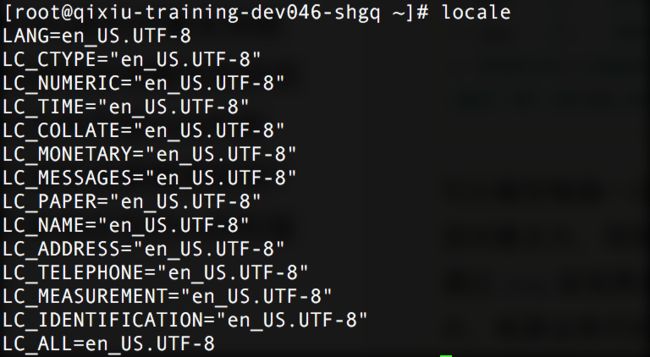
image.png
服务器的Locale配置都是相同的,但是通过jinfo查看java应用的file.encoding,返回的却不一样;
询问运维人员,不同机房的差异,运维人员提到,由于发布系统故障,部分机房的应用是通过手工运行发布脚本发布的;这样问题也就清楚了,应该是ssh会将本地的locale带到服务器环境导致;具体的可以参考这篇文章