第三章:计算机视觉(下)
目录
- LeNet
- LeNet在手写数字识别上的应用
- LeNet 识别手写数字
- LeNet在眼疾识别数据集iChallenge-PM上的应用
- 数据集准备
- 查看数据集图片
- 定义数据读取器
- 启动训练
- AlexNet
- VGG
- GoogLeNet
- ResNet
- 小结
- 参考文献
图像分类是根据 图像的语义信息 对不同类别图像进行区分, 是计算机视觉的核心,是物体检测、图像分割、物体跟踪、行为分析、人脸识别等其他 高层次视觉任务的基础。图像分类在许多领域都有着广泛的应用,如:
- 安防领域的人脸识别和智能视频分析等
- 交通领域的交通场景识别
- 互联网领域基于内容的图像检索和相册自动归类
- 医学领域的图像识别等
上一节主要介绍了卷积神经网络常用的一些基本模块,本节将基于眼疾分类数据集iChallenge-PM,对图像分类领域的经典卷积神经网络进行剖析,介绍如何应用这些基础模块构建卷积神经网络,解决图像分类问题。涵盖如下卷积神经网络:
-
LeNet:Yan LeCun等人于1998年第一次将卷积神经网络应用到图像分类任务上[1],在手写数字识别任务上取得了巨大成功。
-
AlexNet:Alex Krizhevsky等人在2012年提出了AlexNet[2], 并应用在大尺寸图片数据集ImageNet上,获得了2012年ImageNet比赛冠军(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。
-
VGG:Simonyan和Zisserman于2014年提出了VGG网络结构[3],是当前最流行的卷积神经网络之一,由于其结构简单、应用性极强而深受广大研究者欢迎。
-
GoogLeNet:Christian Szegedy等人在2014提出了GoogLeNet[4],并取得了2014年ImageNet比赛冠军。
-
ResNet:Kaiming He等人在2015年提出了ResNet[5],通过引入残差模块加深网络层数,在ImagNet数据集上的错误率降低到3.6%,超越了人眼识别水平。ResNet的设计思想深刻地影响了后来的深度神经网络的设计。
LeNet
LeNet是最早的卷积神经网络之一[1]。1998年,Yan LeCun第一次将LeNet卷积神经网络应用到图像分类上,在手写数字识别任务中取得了巨大成功。LeNet通过连续使用卷积和池化层的组合提取图像特征,其架构如 图1 所示,这里展示的是作者论文中的LeNet-5模型:
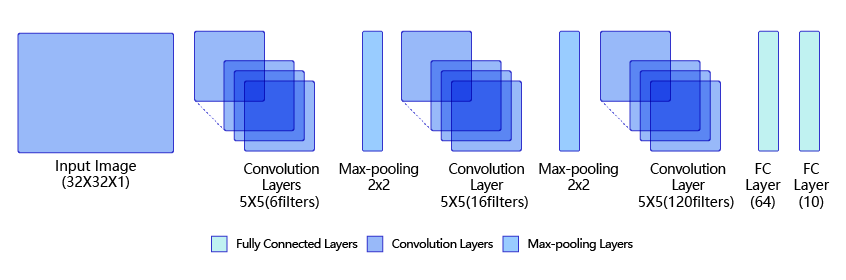
图1:LeNet模型网络结构示意图
-
第一模块:包含5×5的6通道卷积和2×2的池化。卷积提取图像中包含的特征模式(激活函数使用sigmoid),图像尺寸从32减小到28。经过池化层可以降低输出特征图对空间位置的敏感性,图像尺寸减到14。
-
第二模块:和第一模块尺寸相同,通道数由6增加为16。卷积操作使图像尺寸减小到10,经过池化后变成5。
-
第三模块:包含5×5的120通道卷积。卷积之后的图像尺寸减小到1,但是通道数增加为120。将经过第3次卷积提取到的特征图输入到全连接层。第一个全连接层的输出神经元的个数是64,第二个全连接层的输出神经元个数是分类标签的类别数,对于手写数字识别其大小是10。然后使用Softmax激活函数即可计算出每个类别的预测概率。
【提示】:
卷积层的输出特征图如何当作全连接层的输入使用呢?
卷积层的输出数据格式是 [ N , C , H , W ] [N, C, H, W] [N,C,H,W],在输入全连接层的时候,会自动将数据拉平,
也就是对每个样本,自动将其转化为长度为 K K K的向量,
其中 K = C × H × W K = C \times H \times W K=C×H×W,一个mini-batch的数据维度变成了 N × K N\times K N×K的二维向量。
LeNet在手写数字识别上的应用
LeNet网络的实现代码如下:
# 导入需要的包
import paddle
import paddle.fluid as fluid
import numpy as np
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear
# 定义 LeNet 网络结构
class LeNet(fluid.dygraph.Layer):
def __init__(self, num_classes=1):
super(LeNet, self).__init__()
# 创建卷积和池化层块,每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化
self.conv1 = Conv2D(num_channels=1, num_filters=6, filter_size=5, act='sigmoid')
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(num_channels=6, num_filters=16, filter_size=5, act='sigmoid')
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 创建第3个卷积层
self.conv3 = Conv2D(num_channels=16, num_filters=120, filter_size=4, act='sigmoid')
# 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数
self.fc1 = Linear(input_dim=120, output_dim=64, act='sigmoid')
self.fc2 = Linear(input_dim=64, output_dim=num_classes)
# 网络的前向计算过程
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.conv3(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = self.fc2(x)
return x
下面的程序使用随机数作为输入,查看经过LeNet-5的每一层作用之后,输出数据的形状
# 输入数据形状是 [N, 1, H, W]
# 这里用np.random创建一个随机数组作为输入数据
x = np.random.randn(*[3,1,28,28])
x = x.astype('float32')
with fluid.dygraph.guard():
# 创建LeNet类的实例,指定模型名称和分类的类别数目
m = LeNet(num_classes=10)
# 通过调用LeNet从基类继承的sublayers()函数,
# 查看LeNet中所包含的子层
print(m.sublayers())
x = fluid.dygraph.to_variable(x)
for item in m.sublayers():
# item是LeNet类中的一个子层
# 查看经过子层之后的输出数据形状
try:
x = item(x)
except:
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = item(x)
if len(item.parameters())==2:
# 查看卷积和全连接层的数据和参数的形状,
# 其中item.parameters()[0]是权重参数w,item.parameters()[1]是偏置参数b
print(item.full_name(), x.shape, item.parameters()[0].shape, item.parameters()[1].shape)
else:
# 池化层没有参数
print(item.full_name(), x.shape)
[<paddle.fluid.dygraph.nn.Conv2D object at 0x7f1656aab770>, <paddle.fluid.dygraph.nn.Pool2D object at 0x7f1656aaba10>, <paddle.fluid.dygraph.nn.Conv2D object at 0x7f1656aabef0>, <paddle.fluid.dygraph.nn.Pool2D object at 0x7f1616bb1050>, <paddle.fluid.dygraph.nn.Conv2D object at 0x7f1616bb10b0>, <paddle.fluid.dygraph.nn.Linear object at 0x7f1616bb11d0>, <paddle.fluid.dygraph.nn.Linear object at 0x7f1616bb1350>]
conv2d_0 [3, 6, 24, 24] [6, 1, 5, 5] [6]
pool2d_0 [3, 6, 12, 12]
conv2d_1 [3, 16, 8, 8] [16, 6, 5, 5] [16]
pool2d_1 [3, 16, 4, 4]
conv2d_2 [3, 120, 1, 1] [120, 16, 4, 4] [120]
linear_0 [3, 64] [120, 64] [64]
linear_1 [3, 10] [64, 10] [10]
LeNet 识别手写数字
# -*- coding: utf-8 -*-
# LeNet 识别手写数字
import os
import random
import paddle
import paddle.fluid as fluid
import numpy as np
# 定义训练过程
def train(model):
print('start training ... ')
model.train()
epoch_num = 5
opt = fluid.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameter_list=model.parameters())
# 使用Paddle自带的数据读取器
train_loader = paddle.batch(paddle.dataset.mnist.train(), batch_size=10)
valid_loader = paddle.batch(paddle.dataset.mnist.test(), batch_size=10)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
# 调整输入数据形状和类型
x_data = np.array([item[0] for item in data], dtype='float32').reshape(-1, 1, 28, 28)
y_data = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)
# 将numpy.ndarray转化成Tensor
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 计算模型输出
logits = model(img)
# 计算损失函数
loss = fluid.layers.softmax_with_cross_entropy(logits, label)
avg_loss = fluid.layers.mean(loss)
if batch_id % 1000 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
# 调整输入数据形状和类型
x_data = np.array([item[0] for item in data], dtype='float32').reshape(-1, 1, 28, 28)
y_data = np.array([item[1] for item in data], dtype='int64').reshape(-1, 1)
# 将numpy.ndarray转化成Tensor
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 计算模型输出
logits = model(img)
pred = fluid.layers.softmax(logits)
# 计算损失函数
loss = fluid.layers.softmax_with_cross_entropy(logits, label)
acc = fluid.layers.accuracy(pred, label)
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
# 保存模型参数
fluid.save_dygraph(model.state_dict(), 'mnist')
if __name__ == '__main__':
# 创建模型
with fluid.dygraph.guard():
model = LeNet(num_classes=10)
#启动训练过程
train(model)
start training ...
Cache file /home/aistudio/.cache/paddle/dataset/mnist/train-images-idx3-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/train-images-idx3-ubyte.gz
Begin to download
Download finished
Cache file /home/aistudio/.cache/paddle/dataset/mnist/train-labels-idx1-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/train-labels-idx1-ubyte.gz
Begin to download
........
Download finished
Cache file /home/aistudio/.cache/paddle/dataset/mnist/t10k-images-idx3-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/t10k-images-idx3-ubyte.gz
Begin to download
Download finished
Cache file /home/aistudio/.cache/paddle/dataset/mnist/t10k-labels-idx1-ubyte.gz not found, downloading https://dataset.bj.bcebos.com/mnist/t10k-labels-idx1-ubyte.gz
Begin to download
..
Download finished
epoch: 0, batch_id: 0, loss is: [2.4476852]
epoch: 0, batch_id: 1000, loss is: [2.2948332]
epoch: 0, batch_id: 2000, loss is: [2.334548]
epoch: 0, batch_id: 3000, loss is: [2.283103]
epoch: 0, batch_id: 4000, loss is: [2.2783697]
epoch: 0, batch_id: 5000, loss is: [2.3309145]
[validation] accuracy/loss: 0.10530000925064087/2.2899725437164307
epoch: 1, batch_id: 0, loss is: [2.2863708]
epoch: 1, batch_id: 1000, loss is: [2.276087]
epoch: 1, batch_id: 2000, loss is: [2.3081589]
epoch: 1, batch_id: 3000, loss is: [2.2395322]
epoch: 1, batch_id: 4000, loss is: [2.2013073]
epoch: 1, batch_id: 5000, loss is: [2.257289]
[validation] accuracy/loss: 0.554900050163269/2.004681348800659
epoch: 2, batch_id: 0, loss is: [1.9385501]
epoch: 2, batch_id: 1000, loss is: [1.5589781]
epoch: 2, batch_id: 2000, loss is: [1.3764482]
epoch: 2, batch_id: 3000, loss is: [0.8067332]
epoch: 2, batch_id: 4000, loss is: [0.6518642]
epoch: 2, batch_id: 5000, loss is: [0.77211165]
[validation] accuracy/loss: 0.8388999700546265/0.6187658905982971
epoch: 3, batch_id: 0, loss is: [0.41283408]
epoch: 3, batch_id: 1000, loss is: [0.40613115]
epoch: 3, batch_id: 2000, loss is: [0.4012765]
epoch: 3, batch_id: 3000, loss is: [0.15993488]
epoch: 3, batch_id: 4000, loss is: [0.27918053]
epoch: 3, batch_id: 5000, loss is: [0.23777664]
[validation] accuracy/loss: 0.9035999774932861/0.357360303401947
epoch: 4, batch_id: 0, loss is: [0.23886052]
epoch: 4, batch_id: 1000, loss is: [0.2531582]
epoch: 4, batch_id: 2000, loss is: [0.25078607]
epoch: 4, batch_id: 3000, loss is: [0.0727628]
epoch: 4, batch_id: 4000, loss is: [0.15234414]
epoch: 4, batch_id: 5000, loss is: [0.11065292]
[validation] accuracy/loss: 0.9294999241828918/0.25718018412590027
通过运行结果可以看出,LeNet在手写数字识别MNIST验证数据集上的准确率高达92%以上。那么对于其它数据集效果如何呢?我们通过眼疾识别数据集iChallenge-PM验证一下。
LeNet在眼疾识别数据集iChallenge-PM上的应用
iChallenge-PM是百度大脑和中山大学中山眼科中心联合举办的iChallenge比赛中,提供的关于病理性近视(Pathologic Myopia,PM)的医疗类数据集,包含1200个受试者的眼底视网膜图片,训练、验证和测试数据集各400张。下面我们详细介绍LeNet在iChallenge-PM上的训练过程。
说明:
如今近视已经成为困扰人们健康的一项全球性负担,在近视人群中,有超过35%的人患有重度近视。近视会拉长眼睛的光轴,也可能引起视网膜或者络网膜的病变。随着近视度数的不断加深,高度近视有可能引发病理性病变,这将会导致以下几种症状:视网膜或者络网膜发生退化、视盘区域萎缩、漆裂样纹损害、Fuchs斑等。因此,及早发现近视患者眼睛的病变并采取治疗,显得非常重要。
数据可以从AIStudio下载
数据集准备
/home/aistudio/data/data19065 目录包括如下三个文件,解压缩后存放在/home/aistudio/work/palm目录下。
- training.zip:包含训练中的图片和标签
- validation.zip:包含验证集的图片
- valid_gt.zip:包含验证集的标签
注意:
valid_gt.zip文件解压缩之后,需要将/home/aistudio/work/palm/PALM-Validation-GT/目录下的PM_Label_and_Fovea_Location.xlsx文件转存成csv格式,本节代码示例中已经提前转成文件labels.csv。
# 初次运行时将注释取消,以便解压文件
# 如果已经解压过了,则不需要运行此段代码,否则文件已经存在解压会报错
!unzip -o -q -d /home/aistudio/work/palm /home/aistudio/data/data19065/training.zip
%cd /home/aistudio/work/palm/PALM-Training400/
!unzip -o -q PALM-Training400.zip
!unzip -o -q -d /home/aistudio/work/palm /home/aistudio/data/data19065/validation.zip
!unzip -o -q -d /home/aistudio/work/palm /home/aistudio/data/data19065/valid_gt.zip
/home/aistudio/work/palm/PALM-Training400
查看数据集图片
iChallenge-PM中既有病理性近视患者的眼底图片,也有非病理性近视患者的图片,命名规则如下:
-
病理性近视(PM):文件名以P开头
-
非病理性近视(non-PM):
-
高度近视(high myopia):文件名以H开头
-
正常眼睛(normal):文件名以N开头
-
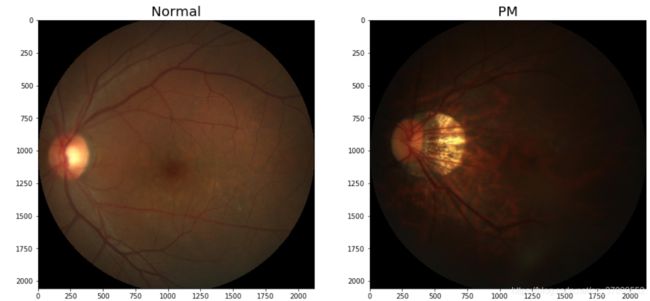
我们将病理性患者的图片作为正样本,标签为1; 非病理性患者的图片作为负样本,标签为0。从数据集中选取两张图片,通过LeNet提取特征,构建分类器,对正负样本进行分类,并将图片显示出来。代码如下所示:
import os
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
from PIL import Image
DATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
# 文件名以N开头的是正常眼底图片,以P开头的是病变眼底图片
file1 = 'N0012.jpg'
file2 = 'P0095.jpg'
# 读取图片
img1 = Image.open(os.path.join(DATADIR, file1))
img1 = np.array(img1)
img2 = Image.open(os.path.join(DATADIR, file2))
img2 = np.array(img2)
# 画出读取的图片
plt.figure(figsize=(16, 8))
f = plt.subplot(121)
f.set_title('Normal', fontsize=20)
plt.imshow(img1)
f = plt.subplot(122)
f.set_title('PM', fontsize=20)
plt.imshow(img2)
plt.show()
2020-08-20 15:57:39,117-INFO: font search path ['/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/afm', '/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/pdfcorefonts']
2020-08-20 15:57:39,604-INFO: generated new fontManager
# 查看图片形状
img1.shape, img2.shape
((2056, 2124, 3), (2056, 2124, 3))
定义数据读取器
使用OpenCV从磁盘读入图片,将每张图缩放到 224 × 224 224\times224 224×224大小,并且将像素值调整到 [ − 1 , 1 ] [-1, 1] [−1,1]之间,代码如下所示:
import cv2
import random
import numpy as np
# 对读入的图像数据进行预处理
def transform_img(img):
# 将图片尺寸缩放道 224x224
img = cv2.resize(img, (224, 224))
# 读入的图像数据格式是[H, W, C]
# 使用转置操作将其变成[C, H, W]
img = np.transpose(img, (2,0,1))
img = img.astype('float32')
# 将数据范围调整到[-1.0, 1.0]之间
img = img / 255.
img = img * 2.0 - 1.0
return img
# 定义训练集数据读取器
def data_loader(datadir, batch_size=10, mode = 'train'):
# 将datadir目录下的文件列出来,每条文件都要读入
filenames = os.listdir(datadir)
def reader():
if mode == 'train':
# 训练时随机打乱数据顺序
random.shuffle(filenames)
batch_imgs = []
batch_labels = []
for name in filenames:
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
if name[0] == 'H' or name[0] == 'N':
# H开头的文件名表示高度近似,N开头的文件名表示正常视力
# 高度近视和正常视力的样本,都不是病理性的,属于负样本,标签为0
label = 0
elif name[0] == 'P':
# P开头的是病理性近视,属于正样本,标签为1
label = 1
else:
raise('Not excepted file name')
# 每读取一个样本的数据,就将其放入数据列表中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 当数据列表的长度等于batch_size的时候,
# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
# 定义验证集数据读取器
def valid_data_loader(datadir, csvfile, batch_size=10, mode='valid'):
# 训练集读取时通过文件名来确定样本标签,验证集则通过csvfile来读取每个图片对应的标签
# 请查看解压后的验证集标签数据,观察csvfile文件里面所包含的内容
# csvfile文件所包含的内容格式如下,每一行代表一个样本,
# 其中第一列是图片id,第二列是文件名,第三列是图片标签,
# 第四列和第五列是Fovea的坐标,与分类任务无关
# ID,imgName,Label,Fovea_X,Fovea_Y
# 1,V0001.jpg,0,1157.74,1019.87
# 2,V0002.jpg,1,1285.82,1080.47
# 打开包含验证集标签的csvfile,并读入其中的内容
filelists = open(csvfile).readlines()
def reader():
batch_imgs = []
batch_labels = []
for line in filelists[1:]:
line = line.strip().split(',')
name = line[1]
label = int(line[2])
# 根据图片文件名加载图片,并对图像数据作预处理
filepath = os.path.join(datadir, name)
img = cv2.imread(filepath)
img = transform_img(img)
# 每读取一个样本的数据,就将其放入数据列表中
batch_imgs.append(img)
batch_labels.append(label)
if len(batch_imgs) == batch_size:
# 当数据列表的长度等于batch_size的时候,
# 把这些数据当作一个mini-batch,并作为数据生成器的一个输出
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
batch_imgs = []
batch_labels = []
if len(batch_imgs) > 0:
# 剩余样本数目不足一个batch_size的数据,一起打包成一个mini-batch
imgs_array = np.array(batch_imgs).astype('float32')
labels_array = np.array(batch_labels).astype('float32').reshape(-1, 1)
yield imgs_array, labels_array
return reader
# 查看数据形状
DATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
train_loader = data_loader(DATADIR,
batch_size=10, mode='train')
data_reader = train_loader()
data = next(data_reader)
data[0].shape, data[1].shape
eval_loader = data_loader(DATADIR,
batch_size=10, mode='eval')
data_reader = eval_loader()
data = next(data_reader)
data[0].shape, data[1].shape
((10, 3, 224, 224), (10, 1))
启动训练
# -*- coding: utf-8 -*-
# LeNet 识别眼疾图片
import os
import random
import paddle
import paddle.fluid as fluid
import numpy as np
DATADIR = '/home/aistudio/work/palm/PALM-Training400/PALM-Training400'
DATADIR2 = '/home/aistudio/work/palm/PALM-Validation400'
CSVFILE = '/home/aistudio/labels.csv'
# 定义训练过程
def train(model):
with fluid.dygraph.guard():
print('start training ... ')
model.train()
epoch_num = 5
# 定义优化器
opt = fluid.optimizer.Momentum(learning_rate=0.001, momentum=0.9, parameter_list=model.parameters())
# 定义数据读取器,训练数据读取器和验证数据读取器
train_loader = data_loader(DATADIR, batch_size=10, mode='train')
valid_loader = valid_data_loader(DATADIR2, CSVFILE)
for epoch in range(epoch_num):
for batch_id, data in enumerate(train_loader()):
x_data, y_data = data
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 运行模型前向计算,得到预测值
logits = model(img)
# 进行loss计算
loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label)
avg_loss = fluid.layers.mean(loss)
if batch_id % 10 == 0:
print("epoch: {}, batch_id: {}, loss is: {}".format(epoch, batch_id, avg_loss.numpy()))
# 反向传播,更新权重,清除梯度
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
model.eval()
accuracies = []
losses = []
for batch_id, data in enumerate(valid_loader()):
x_data, y_data = data
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
# 运行模型前向计算,得到预测值
logits = model(img)
# 二分类,sigmoid计算后的结果以0.5为阈值分两个类别
# 计算sigmoid后的预测概率,进行loss计算
pred = fluid.layers.sigmoid(logits)
loss = fluid.layers.sigmoid_cross_entropy_with_logits(logits, label)
# 计算预测概率小于0.5的类别
pred2 = pred * (-1.0) + 1.0
# 得到两个类别的预测概率,并沿第一个维度级联
pred = fluid.layers.concat([pred2, pred], axis=1)
acc = fluid.layers.accuracy(pred, fluid.layers.cast(label, dtype='int64'))
accuracies.append(acc.numpy())
losses.append(loss.numpy())
print("[validation] accuracy/loss: {}/{}".format(np.mean(accuracies), np.mean(losses)))
model.train()
# save params of model
fluid.save_dygraph(model.state_dict(), 'palm')
# save optimizer state
fluid.save_dygraph(opt.state_dict(), 'palm')
# 定义评估过程
def evaluation(model, params_file_path):
with fluid.dygraph.guard():
print('start evaluation .......')
#加载模型参数
model_state_dict, _ = fluid.load_dygraph(params_file_path)
model.load_dict(model_state_dict)
model.eval()
eval_loader = data_loader(DATADIR,
batch_size=10, mode='eval')
acc_set = []
avg_loss_set = []
for batch_id, data in enumerate(eval_loader()):
x_data, y_data = data
img = fluid.dygraph.to_variable(x_data)
label = fluid.dygraph.to_variable(y_data)
y_data = y_data.astype(np.int64)
label_64 = fluid.dygraph.to_variable(y_data)
# 计算预测和精度
prediction, acc = model(img, label_64)
# 计算损失函数值
loss = fluid.layers.sigmoid_cross_entropy_with_logits(prediction, label)
avg_loss = fluid.layers.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
# 求平均精度
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))
# 导入需要的包
import paddle
import paddle.fluid as fluid
import numpy as np
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear
# 定义 LeNet 网络结构
class LeNet(fluid.dygraph.Layer):
def __init__(self, num_classes=1):
super(LeNet, self).__init__()
# 创建卷积和池化层块,每个卷积层使用Sigmoid激活函数,后面跟着一个2x2的池化
self.conv1 = Conv2D(num_channels=3, num_filters=6, filter_size=5, act='sigmoid')
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(num_channels=6, num_filters=16, filter_size=5, act='sigmoid')
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 创建第3个卷积层
self.conv3 = Conv2D(num_channels=16, num_filters=120, filter_size=4, act='sigmoid')
# 创建全连接层,第一个全连接层的输出神经元个数为64, 第二个全连接层输出神经元个数为分类标签的类别数
self.fc1 = Linear(input_dim=300000, output_dim=64, act='sigmoid')
self.fc2 = Linear(input_dim=64, output_dim=num_classes)
# 网络的前向计算过程
def forward(self, x, label=None):
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.conv3(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
x = self.fc2(x)
if label is not None:
acc = fluid.layers.accuracy(input=x, label=label)
return x, acc
else:
return x
if __name__ == '__main__':
# 创建模型
with fluid.dygraph.guard():
model = LeNet(num_classes=1)
train(model)
# evaluation(model, params_file_path="palm")
start training ...
epoch: 0, batch_id: 0, loss is: [1.0965669]
epoch: 0, batch_id: 10, loss is: [0.70665735]
epoch: 0, batch_id: 20, loss is: [0.6825943]
epoch: 0, batch_id: 30, loss is: [0.70716846]
[validation] accuracy/loss: 0.5275000333786011/0.6924305558204651
epoch: 1, batch_id: 0, loss is: [0.6959075]
epoch: 1, batch_id: 10, loss is: [0.70333457]
epoch: 1, batch_id: 20, loss is: [0.65616727]
epoch: 1, batch_id: 30, loss is: [0.72612846]
[validation] accuracy/loss: 0.5275000333786011/0.693164050579071
epoch: 2, batch_id: 0, loss is: [0.7659072]
epoch: 2, batch_id: 10, loss is: [0.68094516]
epoch: 2, batch_id: 20, loss is: [0.67836446]
epoch: 2, batch_id: 30, loss is: [0.6167338]
[validation] accuracy/loss: 0.5275000333786011/0.6940395832061768
epoch: 3, batch_id: 0, loss is: [0.6759121]
epoch: 3, batch_id: 10, loss is: [0.716102]
epoch: 3, batch_id: 20, loss is: [0.71622777]
epoch: 3, batch_id: 30, loss is: [0.69723225]
[validation] accuracy/loss: 0.5275000333786011/0.6918253898620605
epoch: 4, batch_id: 0, loss is: [0.7005242]
epoch: 4, batch_id: 10, loss is: [0.6697167]
epoch: 4, batch_id: 20, loss is: [0.69497466]
epoch: 4, batch_id: 30, loss is: [0.6828443]
[validation] accuracy/loss: 0.5275000333786011/0.6916337609291077
通过运行结果可以看出,在眼疾筛查数据集iChallenge-PM上,LeNet的loss很难下降,模型没有收敛。这是因为MNIST数据集的图片尺寸比较小( 28 × 28 28\times28 28×28),但是 眼疾筛查数据集图片尺寸比较大 (原始图片尺寸约为 2000 × 2000 2000 \times 2000 2000×2000,经过缩放之后变成 224 × 224 224 \times 224 224×224),LeNet模型很难进行有效分类。这说明在图片尺寸比较大时,LeNet在图像分类任务上存在局限性。
AlexNet
通过上面的实际训练可以看到,虽然LeNet在手写数字识别数据集上取得了很好的结果,但在更大的数据集上表现却并不好。自从1998年LeNet问世以来,接下来十几年的时间里,神经网络并没有在计算机视觉领域取得很好的结果,反而一度被其它算法所超越,原因主要有两方面:
- 计算机算力限制:神经网络的计算比较复杂,对当时计算机的算力来说,训练神经网络是件非常耗时的事情;
- 理论不足:当时还没有专门针对神经网络做算法和训练技巧的优化,神经网络的收敛是件非常困难的事情。
随着技术的进步和发展,计算机的算力越来越强大,尤其是在GPU并行计算能力的推动下,复杂神经网络的计算也变得更加容易实施。另一方面,互联网上涌现出越来越多的数据,极大的 丰富了数据库。同时也有越来越多的研究人员开始专门针对神经网络做算法和模型的优化,Alex Krizhevsky等人提出的AlexNet以很大优势获得了2012年ImageNet比赛的冠军。这一成果极大的激发了产业界对神经网络的兴趣,开创了使用深度神经网络解决图像问题的途径,随后也在这一领域涌现出越来越多的优秀成果。
AlexNet与LeNet相比,具有更深的网络结构,包含5层卷积和3层全连接,同时使用了如下三种方法改进模型的训练过程:
-
数据增广:深度学习中常用的一种处理方式,通过对训练随机加一些变化,比如平移、缩放、裁剪、旋转、翻转或者增减亮度等,产生一系列跟原始图片相似但又不完全相同的样本,从而扩大训练数据集。通过这种方式,可以随机改变训练样本,避免模型过度依赖于某些属性,能从一定程度上抑制过拟合。
-
使用Dropout抑制过拟合
-
使用ReLU激活函数减少梯度消失现象
说明:
下一节详细介绍数据增广的具体实现方式。
AlexNet的具体结构如 图2 所示:
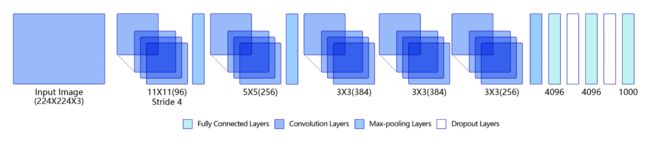
图2:AlexNet模型网络结构示意图
AlexNet在眼疾筛查数据集iChallenge-PM上具体实现的代码如下所示:
# -*- coding:utf-8 -*-
# 导入需要的包
import paddle
import paddle.fluid as fluid
import numpy as np
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear
# 定义 AlexNet 网络结构
class AlexNet(fluid.dygraph.Layer):
def __init__(self, num_classes=1):
super(AlexNet, self).__init__()
# AlexNet与LeNet一样也会同时使用卷积和池化层提取图像特征
# 与LeNet不同的是激活函数换成了‘relu’
self.conv1 = Conv2D(num_channels=3, num_filters=96, filter_size=11, stride=4, padding=5, act='relu')
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv2 = Conv2D(num_channels=96, num_filters=256, filter_size=5, stride=1, padding=2, act='relu')
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.conv3 = Conv2D(num_channels=256, num_filters=384, filter_size=3, stride=1, padding=1, act='relu')
self.conv4 = Conv2D(num_channels=384, num_filters=384, filter_size=3, stride=1, padding=1, act='relu')
self.conv5 = Conv2D(num_channels=384, num_filters=256, filter_size=3, stride=1, padding=1, act='relu')
self.pool5 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
self.fc1 = Linear(input_dim=12544, output_dim=4096, act='relu')
self.drop_ratio1 = 0.5
self.fc2 = Linear(input_dim=4096, output_dim=4096, act='relu')
self.drop_ratio2 = 0.5
self.fc3 = Linear(input_dim=4096, output_dim=num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.pool5(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = self.fc1(x)
# 在全连接之后使用dropout抑制过拟合
x= fluid.layers.dropout(x, self.drop_ratio1)
x = self.fc2(x)
# 在全连接之后使用dropout抑制过拟合
x = fluid.layers.dropout(x, self.drop_ratio2)
x = self.fc3(x)
return x
with fluid.dygraph.guard():
model = AlexNet()
train(model)
start training ...
epoch: 0, batch_id: 0, loss is: [0.80138135]
epoch: 0, batch_id: 10, loss is: [0.67886376]
epoch: 0, batch_id: 20, loss is: [0.65310085]
epoch: 0, batch_id: 30, loss is: [0.58786815]
[validation] accuracy/loss: 0.9225000143051147/0.4894911050796509
epoch: 1, batch_id: 0, loss is: [0.4955787]
epoch: 1, batch_id: 10, loss is: [0.46841344]
epoch: 1, batch_id: 20, loss is: [0.28746957]
epoch: 1, batch_id: 30, loss is: [0.1364896]
[validation] accuracy/loss: 0.9325000643730164/0.22642169892787933
epoch: 2, batch_id: 0, loss is: [0.41602606]
epoch: 2, batch_id: 10, loss is: [0.13847905]
epoch: 2, batch_id: 20, loss is: [0.20654806]
epoch: 2, batch_id: 30, loss is: [0.1134614]
[validation] accuracy/loss: 0.9325000047683716/0.1921769380569458
epoch: 3, batch_id: 0, loss is: [0.12857972]
epoch: 3, batch_id: 10, loss is: [0.33363497]
epoch: 3, batch_id: 20, loss is: [0.54201126]
epoch: 3, batch_id: 30, loss is: [0.05251026]
[validation] accuracy/loss: 0.9175000190734863/0.2358420342206955
epoch: 4, batch_id: 0, loss is: [0.2438938]
epoch: 4, batch_id: 10, loss is: [0.35219336]
epoch: 4, batch_id: 20, loss is: [0.19315657]
epoch: 4, batch_id: 30, loss is: [0.13828665]
[validation] accuracy/loss: 0.9300000071525574/0.1791592389345169
通过运行结果可以发现,在眼疾筛查数据集iChallenge-PM上使用AlexNet,loss能有效下降,经过5个epoch的训练,在验证集上的准确率可以达到94%左右。
VGG
VGG是当前最流行的CNN模型之一,2014年由Simonyan和Zisserman提出,其命名来源于论文作者所在的实验室Visual Geometry Group。AlexNet模型通过构造多层网络,取得了较好的效果,但是并没有给出深度神经网络设计的方向。VGG通过使用一系列大小为3x3的小尺寸卷积核和pooling层构造深度卷积神经网络,并取得了较好的效果。VGG模型因为结构简单、应用性极强而广受研究者欢迎,尤其是它的网络结构设计方法,为构建深度神经网络提供了方向。
图3 是VGG-16的网络结构示意图,有13层卷积和3层全连接层。VGG网络的设计严格使用 3 × 3 3\times 3 3×3的卷积层和池化层来提取特征,并在网络的最后面使用三层全连接层,将最后一层全连接层的输出作为分类的预测。
在VGG中每层卷积将使用ReLU作为激活函数,在全连接层之后添加dropout来抑制过拟合。使用小的卷积核能够有效地减少参数的个数,使得训练和测试变得更加有效。比如使用两层 3 × 3 3\times 3 3×3卷积层,可以得到感受野为5的特征图,而比使用 5 × 5 5 \times 5 5×5的卷积层需要更少的参数。由于卷积核比较小,可以堆叠更多的卷积层,加深网络的深度,这对于图像分类任务来说是有利的。VGG模型的成功证明了增加网络的深度,可以 更好的学习图像中的特征模式。
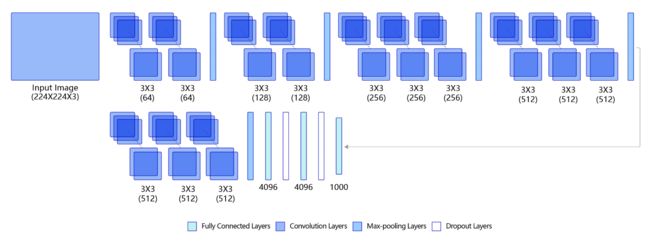
图3:VGG模型网络结构示意图
VGG在眼疾识别数据集iChallenge-PM上的具体实现如下代码所示:
# -*- coding:utf-8 -*-
# VGG模型代码
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.layer_helper import LayerHelper
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear
from paddle.fluid.dygraph.base import to_variable
# 定义vgg块,包含多层卷积和1层2x2的最大池化层
class vgg_block(fluid.dygraph.Layer):
def __init__(self, num_convs, in_channels, out_channels):
"""
num_convs, 卷积层的数目
num_channels, 卷积层的输出通道数,在同一个Incepition块内,卷积层输出通道数是一样的
"""
super(vgg_block, self).__init__()
self.conv_list = []
for i in range(num_convs):
conv_layer = self.add_sublayer('conv_' + str(i), Conv2D(num_channels=in_channels,
num_filters=out_channels, filter_size=3, padding=1, act='relu'))
self.conv_list.append(conv_layer)
in_channels = out_channels
self.pool = Pool2D(pool_stride=2, pool_size = 2, pool_type='max')
def forward(self, x):
for item in self.conv_list:
x = item(x)
return self.pool(x)
class VGG(fluid.dygraph.Layer):
def __init__(self, conv_arch=((2, 64),
(2, 128), (3, 256), (3, 512), (3, 512))):
super(VGG, self).__init__()
self.vgg_blocks=[]
iter_id = 0
# 添加vgg_block
# 这里一共5个vgg_block,每个block里面的卷积层数目和输出通道数由conv_arch指定
in_channels = [3, 64, 128, 256, 512, 512]
for (num_convs, num_channels) in conv_arch:
block = self.add_sublayer('block_' + str(iter_id),
vgg_block(num_convs, in_channels=in_channels[iter_id],
out_channels=num_channels))
self.vgg_blocks.append(block)
iter_id += 1
self.fc1 = Linear(input_dim=512*7*7, output_dim=4096,
act='relu')
self.drop1_ratio = 0.5
self.fc2= Linear(input_dim=4096, output_dim=4096,
act='relu')
self.drop2_ratio = 0.5
self.fc3 = Linear(input_dim=4096, output_dim=1)
def forward(self, x):
for item in self.vgg_blocks:
x = item(x)
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = fluid.layers.dropout(self.fc1(x), self.drop1_ratio)
x = fluid.layers.dropout(self.fc2(x), self.drop2_ratio)
x = self.fc3(x)
return x
with fluid.dygraph.guard():
model = VGG()
train(model)
start training ...
epoch: 0, batch_id: 0, loss is: [0.7161968]
epoch: 0, batch_id: 10, loss is: [0.6642461]
epoch: 0, batch_id: 20, loss is: [0.7209179]
epoch: 0, batch_id: 30, loss is: [0.70707047]
[validation] accuracy/loss: 0.9049999117851257/0.4710964262485504
epoch: 1, batch_id: 0, loss is: [0.5014218]
epoch: 1, batch_id: 10, loss is: [0.78943765]
epoch: 1, batch_id: 20, loss is: [0.33502424]
epoch: 1, batch_id: 30, loss is: [0.4098133]
[validation] accuracy/loss: 0.925000011920929/0.24610097706317902
epoch: 2, batch_id: 0, loss is: [0.6452968]
epoch: 2, batch_id: 10, loss is: [0.1209939]
epoch: 2, batch_id: 20, loss is: [0.20664209]
epoch: 2, batch_id: 30, loss is: [0.2076365]
[validation] accuracy/loss: 0.9125000238418579/0.24028487503528595
epoch: 3, batch_id: 0, loss is: [0.05379442]
epoch: 3, batch_id: 10, loss is: [0.20218144]
epoch: 3, batch_id: 20, loss is: [0.2824857]
epoch: 3, batch_id: 30, loss is: [0.34057978]
[validation] accuracy/loss: 0.9274999499320984/0.2034064680337906
epoch: 4, batch_id: 0, loss is: [0.12442993]
epoch: 4, batch_id: 10, loss is: [0.06831865]
epoch: 4, batch_id: 20, loss is: [0.35892805]
epoch: 4, batch_id: 30, loss is: [0.5022484]
[validation] accuracy/loss: 0.9050000309944153/0.2920156419277191
通过运行结果可以发现,在眼疾筛查数据集iChallenge-PM上使用VGG,loss能有效的下降,经过5个epoch的训练,在验证集上的准确率可以达到94%左右。
GoogLeNet
GoogLeNet是2014年ImageNet比赛的冠军,它的主要特点是网络不仅有深度,还在横向上具有“宽度”。由于图像信息在空间尺寸上的巨大差异,如何选择合适的卷积核大小来提取特征就显得比较困难了。空间分布范围更广的图像信息适合用较大的卷积核来提取其特征,而空间分布范围较小的图像信息则适合用较小的卷积核来提取其特征。为了解决这个问题,GoogLeNet提出了一种被称为 Inception模块 的方案。如 图4 所示:
说明:
- Google的研究人员为了向LeNet致敬,特地将模型命名为GoogLeNet
- Inception一词来源于电影《盗梦空间》(Inception)
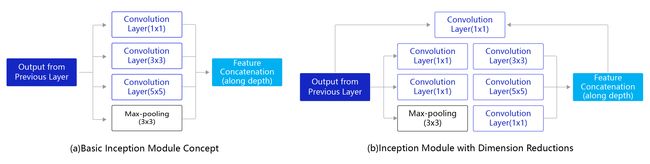
图4:Inception模块结构示意图
图4(a)是Inception模块的设计思想,使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征。Inception模块采用多通路(multi-path)的设计形式,每个支路使用不同大小的卷积核,最终输出特征图的通道数是每个支路输出通道数的总和,这将会导致输出通道数变得很大,尤其是使用多个Inception模块串联操作的时候,模型参数量会变得非常大。为了减小参数量,Inception模块使用了图(b)中的设计方式,在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。基于这一设计思想,形成了上图(b)中所示的结构。下面这段程序是Inception块的具体实现方式,可以对照图(b)和代码一起阅读。
提示:
可能有读者会问,经过3x3的最大池化之后图像尺寸不会减小吗,为什么还能跟另外3个卷积输出的特征图进行拼接?这是因为**池化操作可以指定窗口大小 ∗ ∗ k h = k w = 3 **k_h = k_w = 3 ∗∗kh=kw=3,pool_stride=1和pool_padding=1,输出特征图尺寸可以保持不变。
Inception模块的具体实现如下代码所示:
class Inception(fluid.dygraph.Layer):
def __init__(self, c1, c2, c3, c4, **kwargs):
'''
Inception模块的实现代码,
c1, 图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数
c2,图(b)中第二条支路卷积的输出通道数,数据类型是tuple或list,
其中c2[0]是1x1卷积的输出通道数,c2[1]是3x3
c3,图(b)中第三条支路卷积的输出通道数,数据类型是tuple或list,
其中c3[0]是1x1卷积的输出通道数,c3[1]是3x3
c4, 图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数
'''
super(Inception, self).__init__()
# 依次创建Inception块每条支路上使用到的操作
self.p1_1 = Conv2D(num_filters=c1,
filter_size=1, act='relu')
self.p2_1 = Conv2D(num_filters=c2[0],
filter_size=1, act='relu')
self.p2_2 = Conv2D(num_filters=c2[1],
filter_size=3, padding=1, act='relu')
self.p3_1 = Conv2D(num_filters=c3[0],
filter_size=1, act='relu')
self.p3_2 = Conv2D(num_filters=c3[1],
filter_size=5, padding=2, act='relu')
self.p4_1 = Pool2D(pool_size=3,
pool_stride=1, pool_padding=1,
pool_type='max')
self.p4_2 = Conv2D(num_filters=c4,
filter_size=1, act='relu')
def forward(self, x):
# 支路1只包含一个1x1卷积
p1 = self.p1_1(x)
# 支路2包含 1x1卷积 + 3x3卷积
p2 = self.p2_2(self.p2_1(x))
# 支路3包含 1x1卷积 + 5x5卷积
p3 = self.p3_2(self.p3_1(x))
# 支路4包含 最大池化和1x1卷积
p4 = self.p4_2(self.p4_1(x))
# 将每个支路的输出特征图拼接在一起作为最终的输出结果
return fluid.layers.concat([p1, p2, p3, p4], axis=1)
GoogLeNet的架构如 图5 所示,在主体卷积部分中使用5个模块(block),每个模块之间使用步幅为2的3 ×3最大池化层来减小输出高宽。
- 第一模块使用一个64通道的7 × 7卷积层。
- 第二模块使用2个卷积层:首先是64通道的1 × 1卷积层,然后是将通道增大3倍的3 × 3卷积层。
- 第三模块串联2个完整的Inception块。
- 第四模块串联了5个Inception块。
- 第五模块串联了2 个Inception块。
- 第五模块的后面紧跟输出层,使用全局平均池化层来将每个通道的高和宽变成1,最后接上一个输出个数为标签类别数的全连接层。
说明:
在原作者的论文中添加了图中所示的softmax1和softmax2两个辅助分类器,如下图所示,训练时将三个分类器的损失函数进行加权求和,以缓解梯度消失现象。这里的程序作了简化,没有加入辅助分类器。
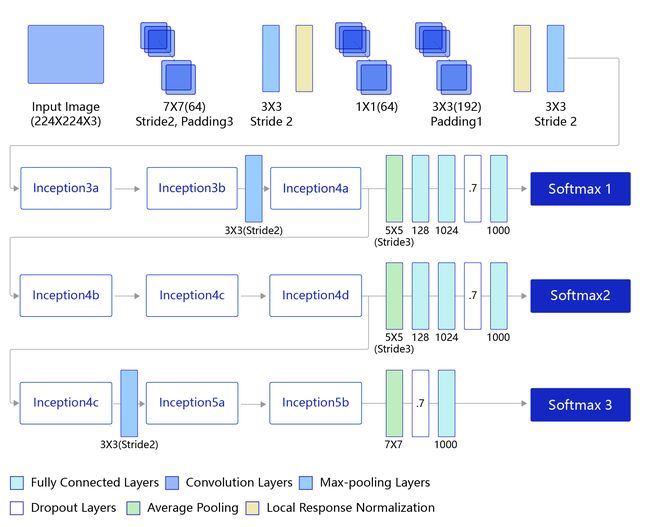
图5:GoogLeNet模型网络结构示意图
GoogLeNet的具体实现如下代码所示:
# -*- coding:utf-8 -*-
# GoogLeNet模型代码
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.layer_helper import LayerHelper
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear
from paddle.fluid.dygraph.base import to_variable
# 定义Inception块
class Inception(fluid.dygraph.Layer):
def __init__(self, c0,c1, c2, c3, c4, **kwargs):
'''
Inception模块的实现代码,
c1, 图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数
c2,图(b)中第二条支路卷积的输出通道数,数据类型是tuple或list,
其中c2[0]是1x1卷积的输出通道数,c2[1]是3x3
c3,图(b)中第三条支路卷积的输出通道数,数据类型是tuple或list,
其中c3[0]是1x1卷积的输出通道数,c3[1]是3x3
c4, 图(b)中第一条支路1x1卷积的输出通道数,数据类型是整数
'''
super(Inception, self).__init__()
# 依次创建Inception块每条支路上使用到的操作
self.p1_1 = Conv2D(num_channels=c0, num_filters=c1,
filter_size=1, act='relu')
self.p2_1 = Conv2D(num_channels=c0, num_filters=c2[0],
filter_size=1, act='relu')
self.p2_2 = Conv2D(num_channels=c2[0], num_filters=c2[1],
filter_size=3, padding=1, act='relu')
self.p3_1 = Conv2D(num_channels=c0, num_filters=c3[0],
filter_size=1, act='relu')
self.p3_2 = Conv2D(num_channels=c3[0], num_filters=c3[1],
filter_size=5, padding=2, act='relu')
self.p4_1 = Pool2D(pool_size=3,
pool_stride=1, pool_padding=1,
pool_type='max')
self.p4_2 = Conv2D(num_channels=c0, num_filters=c4,
filter_size=1, act='relu')
def forward(self, x):
# 支路1只包含一个1x1卷积
p1 = self.p1_1(x)
# 支路2包含 1x1卷积 + 3x3卷积
p2 = self.p2_2(self.p2_1(x))
# 支路3包含 1x1卷积 + 5x5卷积
p3 = self.p3_2(self.p3_1(x))
# 支路4包含 最大池化和1x1卷积
p4 = self.p4_2(self.p4_1(x))
# 将每个支路的输出特征图拼接在一起作为最终的输出结果
return fluid.layers.concat([p1, p2, p3, p4], axis=1)
class GoogLeNet(fluid.dygraph.Layer):
def __init__(self):
super(GoogLeNet, self).__init__()
# GoogLeNet包含五个模块,每个模块后面紧跟一个池化层
# 第一个模块包含1个卷积层
self.conv1 = Conv2D(num_channels=3, num_filters=64, filter_size=7,
padding=3, act='relu')
# 3x3最大池化
self.pool1 = Pool2D(pool_size=3, pool_stride=2,
pool_padding=1, pool_type='max')
# 第二个模块包含2个卷积层
self.conv2_1 = Conv2D(num_channels=64, num_filters=64,
filter_size=1, act='relu')
self.conv2_2 = Conv2D(num_channels=64, num_filters=192,
filter_size=3, padding=1, act='relu')
# 3x3最大池化
self.pool2 = Pool2D(pool_size=3, pool_stride=2,
pool_padding=1, pool_type='max')
# 第三个模块包含2个Inception块
self.block3_1 = Inception(192, 64, (96, 128), (16, 32), 32)
self.block3_2 = Inception(256, 128, (128, 192), (32, 96), 64)
# 3x3最大池化
self.pool3 = Pool2D(pool_size=3, pool_stride=2,
pool_padding=1, pool_type='max')
# 第四个模块包含5个Inception块
self.block4_1 = Inception(480, 192, (96, 208), (16, 48), 64)
self.block4_2 = Inception(512, 160, (112, 224), (24, 64), 64)
self.block4_3 = Inception(512, 128, (128, 256), (24, 64), 64)
self.block4_4 = Inception(512, 112, (144, 288), (32, 64), 64)
self.block4_5 = Inception(528, 256, (160, 320), (32, 128), 128)
# 3x3最大池化
self.pool4 = Pool2D(pool_size=3, pool_stride=2,
pool_padding=1, pool_type='max')
# 第五个模块包含2个Inception块
self.block5_1 = Inception(832, 256, (160, 320), (32, 128), 128)
self.block5_2 = Inception(832, 384, (192, 384), (48, 128), 128)
# 全局池化,尺寸用的是global_pooling,pool_stride不起作用
self.pool5 = Pool2D(pool_stride=1,
global_pooling=True, pool_type='avg')
self.fc = Linear(input_dim=1024, output_dim=1, act=None)
def forward(self, x):
x = self.pool1(self.conv1(x))
x = self.pool2(self.conv2_2(self.conv2_1(x)))
x = self.pool3(self.block3_2(self.block3_1(x)))
x = self.block4_3(self.block4_2(self.block4_1(x)))
x = self.pool4(self.block4_5(self.block4_4(x)))
x = self.pool5(self.block5_2(self.block5_1(x)))
x = fluid.layers.reshape(x, [x.shape[0], -1])
x = self.fc(x)
return x
with fluid.dygraph.guard():
model = GoogLeNet()
train(model)
start training ...
epoch: 0, batch_id: 0, loss is: [0.7579155]
epoch: 0, batch_id: 10, loss is: [0.6246462]
epoch: 0, batch_id: 20, loss is: [0.9587361]
epoch: 0, batch_id: 30, loss is: [0.6807982]
[validation] accuracy/loss: 0.6149999499320984/0.6208078861236572
epoch: 1, batch_id: 0, loss is: [0.6219161]
epoch: 1, batch_id: 10, loss is: [0.62514496]
epoch: 1, batch_id: 20, loss is: [0.6032827]
epoch: 1, batch_id: 30, loss is: [0.643366]
[validation] accuracy/loss: 0.5850000381469727/0.5550951361656189
epoch: 2, batch_id: 0, loss is: [0.5029544]
epoch: 2, batch_id: 10, loss is: [0.60328794]
epoch: 2, batch_id: 20, loss is: [0.34638476]
epoch: 2, batch_id: 30, loss is: [0.30516872]
[validation] accuracy/loss: 0.9550000429153442/0.24882125854492188
epoch: 3, batch_id: 0, loss is: [0.3864692]
epoch: 3, batch_id: 10, loss is: [0.21371146]
epoch: 3, batch_id: 20, loss is: [1.3379304]
epoch: 3, batch_id: 30, loss is: [0.73985326]
[validation] accuracy/loss: 0.48499998450279236/0.6859872937202454
epoch: 4, batch_id: 0, loss is: [0.6212202]
epoch: 4, batch_id: 10, loss is: [0.60551196]
epoch: 4, batch_id: 20, loss is: [0.78616333]
epoch: 4, batch_id: 30, loss is: [0.44808716]
[validation] accuracy/loss: 0.925000011920929/0.3515985906124115
通过运行结果可以发现,使用GoogLeNet在眼疾筛查数据集iChallenge-PM上,loss能有效的下降,经过5个epoch的训练,在验证集上的准确率可以达到95%左右。
ResNet
ResNet是2015年ImageNet比赛的冠军,将识别错误率降低到了3.6%,这个结果甚至超出了正常人眼识别的精度。
通过前面几个经典模型学习,我们可以发现随着深度学习的不断发展,模型的层数越来越多,网络结构也越来越复杂。那么是否加深网络结构,就一定会得到更好的效果呢?从理论上来说,假设新增加的层都是恒等映射,只要原有的层学出跟原模型一样的参数,那么深模型结构就能达到原模型结构的效果。换句话说,原模型的解只是新模型的解的子空间,在新模型解的空间里应该能找到比原模型解对应的子空间更好的结果。但是实践表明,增加网络的层数之后,训练误差往往不降反升。
Kaiming He等人提出了 残差网络ResNet 来解决上述问题,其基本思想如 图6所示。
- 图6(a):表示增加网络的时候,将x映射成 y = F ( x ) y=F(x) y=F(x)输出。
- 图6(b):对图6(a)作了改进,输出 y = F ( x ) + x y=F(x) + x y=F(x)+x。这时不是直接学习输出特征y的表示,而是学习 y − x y-x y−x。
- 如果想学习出原模型的表示,只需将F(x)的参数全部设置为0,则 y = x y=x y=x是恒等映射。
- F ( x ) = y − x F(x) = y - x F(x)=y−x也叫做残差项,如果 x → y x\rightarrow y x→y的映射接近恒等映射,图6(b)中通过学习残差项也比图6(a)学习完整映射形式更加容易。
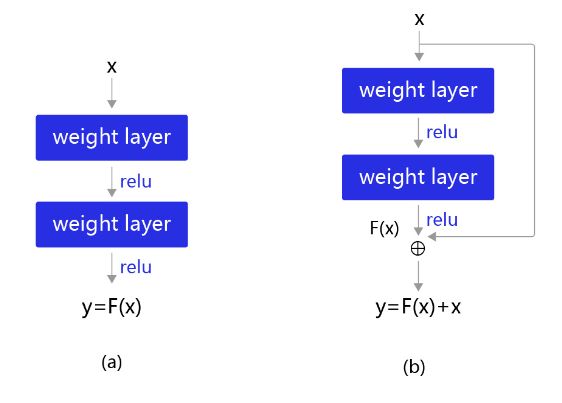
图6:残差块设计思想
图6(b)的结构是残差网络的基础,这种结构也叫做残差块(residual block)。输入x通过跨层连接,能更快的向前传播数据,或者向后传播梯度。残差块的具体设计方案如 图7 所示,这种设计方案也成称作瓶颈结构(BottleNeck)。

图7:残差块结构示意图
下图表示出了ResNet-50的结构,一共包含49层卷积和1层全连接,所以被称为ResNet-50。

图8:ResNet-50模型网络结构示意图
ResNet-50的具体实现如下代码所示:
# -*- coding:utf-8 -*-
# ResNet模型代码
import numpy as np
import paddle
import paddle.fluid as fluid
from paddle.fluid.layer_helper import LayerHelper
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, BatchNorm, Linear
from paddle.fluid.dygraph.base import to_variable
# ResNet中使用了BatchNorm层,在卷积层的后面加上BatchNorm以提升数值稳定性
# 定义卷积批归一化块
class ConvBNLayer(fluid.dygraph.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
act=None):
"""
num_channels, 卷积层的输入通道数
num_filters, 卷积层的输出通道数
stride, 卷积层的步幅
groups, 分组卷积的组数,默认groups=1不使用分组卷积
act, 激活函数类型,默认act=None不使用激活函数
"""
super(ConvBNLayer, self).__init__()
# 创建卷积层
self._conv = Conv2D(
num_channels=num_channels,
num_filters=num_filters,
filter_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
act=None,
bias_attr=False)
# 创建BatchNorm层
self._batch_norm = BatchNorm(num_filters, act=act)
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y)
return y
# 定义残差块
# 每个残差块会对输入图片做三次卷积,然后跟输入图片进行短接
# 如果残差块中第三次卷积输出特征图的形状与输入不一致,则对输入图片做1x1卷积,将其输出形状调整成一致
class BottleneckBlock(fluid.dygraph.Layer):
def __init__(self,
num_channels,
num_filters,
stride,
shortcut=True):
super(BottleneckBlock, self).__init__()
# 创建第一个卷积层 1x1
self.conv0 = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=1,
act='relu')
# 创建第二个卷积层 3x3
self.conv1 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters,
filter_size=3,
stride=stride,
act='relu')
# 创建第三个卷积 1x1,但输出通道数乘以4
self.conv2 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters * 4,
filter_size=1,
act=None)
# 如果conv2的输出跟此残差块的输入数据形状一致,则shortcut=True
# 否则shortcut = False,添加1个1x1的卷积作用在输入数据上,使其形状变成跟conv2一致
if not shortcut:
self.short = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters * 4,
filter_size=1,
stride=stride)
self.shortcut = shortcut
self._num_channels_out = num_filters * 4
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
conv2 = self.conv2(conv1)
# 如果shortcut=True,直接将inputs跟conv2的输出相加
# 否则需要对inputs进行一次卷积,将形状调整成跟conv2输出一致
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = fluid.layers.elementwise_add(x=short, y=conv2)
layer_helper = LayerHelper(self.full_name(), act='relu')
return layer_helper.append_activation(y)
# 定义ResNet模型
class ResNet(fluid.dygraph.Layer):
def __init__(self, layers=50, class_dim=1):
"""
layers, 网络层数,可以是50, 101或者152
class_dim,分类标签的类别数
"""
super(ResNet, self).__init__()
self.layers = layers
supported_layers = [50, 101, 152]
assert layers in supported_layers, \
"supported layers are {} but input layer is {}".format(supported_layers, layers)
if layers == 50:
#ResNet50包含多个模块,其中第2到第5个模块分别包含3、4、6、3个残差块
depth = [3, 4, 6, 3]
elif layers == 101:
#ResNet101包含多个模块,其中第2到第5个模块分别包含3、4、23、3个残差块
depth = [3, 4, 23, 3]
elif layers == 152:
#ResNet50包含多个模块,其中第2到第5个模块分别包含3、8、36、3个残差块
depth = [3, 8, 36, 3]
# 残差块中使用到的卷积的输出通道数
num_filters = [64, 128, 256, 512]
# ResNet的第一个模块,包含1个7x7卷积,后面跟着1个最大池化层
self.conv = ConvBNLayer(
num_channels=3,
num_filters=64,
filter_size=7,
stride=2,
act='relu')
self.pool2d_max = Pool2D(
pool_size=3,
pool_stride=2,
pool_padding=1,
pool_type='max')
# ResNet的第二到第五个模块c2、c3、c4、c5
self.bottleneck_block_list = []
num_channels = 64
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
bottleneck_block = self.add_sublayer(
'bb_%d_%d' % (block, i),
BottleneckBlock(
num_channels=num_channels,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1, # c3、c4、c5将会在第一个残差块使用stride=2;其余所有残差块stride=1
shortcut=shortcut))
num_channels = bottleneck_block._num_channels_out
self.bottleneck_block_list.append(bottleneck_block)
shortcut = True
# 在c5的输出特征图上使用全局池化
self.pool2d_avg = Pool2D(pool_size=7, pool_type='avg', global_pooling=True)
# stdv用来作为全连接层随机初始化参数的方差
import math
stdv = 1.0 / math.sqrt(2048 * 1.0)
# 创建全连接层,输出大小为类别数目
self.out = Linear(input_dim=2048, output_dim=class_dim,
param_attr=fluid.param_attr.ParamAttr(
initializer=fluid.initializer.Uniform(-stdv, stdv)))
def forward(self, inputs):
y = self.conv(inputs)
y = self.pool2d_max(y)
for bottleneck_block in self.bottleneck_block_list:
y = bottleneck_block(y)
y = self.pool2d_avg(y)
y = fluid.layers.reshape(y, [y.shape[0], -1])
y = self.out(y)
return y
with fluid.dygraph.guard():
model = ResNet()
train(model)
start training ...
epoch: 0, batch_id: 0, loss is: [0.70162076]
epoch: 0, batch_id: 10, loss is: [0.6864364]
epoch: 0, batch_id: 20, loss is: [0.85821795]
epoch: 0, batch_id: 30, loss is: [0.82133573]
[validation] accuracy/loss: 0.6399999856948853/0.5687372088432312
epoch: 1, batch_id: 0, loss is: [0.55176413]
epoch: 1, batch_id: 10, loss is: [0.612422]
epoch: 1, batch_id: 20, loss is: [0.7963198]
epoch: 1, batch_id: 30, loss is: [0.4506402]
[validation] accuracy/loss: 0.6975000500679016/0.6059812903404236
epoch: 2, batch_id: 0, loss is: [0.7324375]
epoch: 2, batch_id: 10, loss is: [0.29943112]
epoch: 2, batch_id: 20, loss is: [0.13322839]
epoch: 2, batch_id: 30, loss is: [0.34201986]
[validation] accuracy/loss: 0.9424999952316284/0.20020268857479095
epoch: 3, batch_id: 0, loss is: [0.2825745]
epoch: 3, batch_id: 10, loss is: [0.32170212]
epoch: 3, batch_id: 20, loss is: [0.5328837]
epoch: 3, batch_id: 30, loss is: [0.19485706]
[validation] accuracy/loss: 0.925000011920929/0.23580585420131683
epoch: 4, batch_id: 0, loss is: [0.24522881]
epoch: 4, batch_id: 10, loss is: [0.66783035]
epoch: 4, batch_id: 20, loss is: [0.4252493]
epoch: 4, batch_id: 30, loss is: [0.17882237]
[validation] accuracy/loss: 0.949999988079071/0.17504319548606873
通过运行结果可以发现,使用ResNet在眼疾筛查数据集iChallenge-PM上,loss能有效的下降,经过5个epoch的训练,在验证集上的准确率可以达到95%左右。
小结
在这一节里,给读者介绍了几种经典的图像分类模型,分别是LeNet, AlexNet, VGG, GoogLeNet和ResNet,并将它们应用到眼疾筛查数据集上。除了LeNet不适合大尺寸的图像分类问题之外,其它几个模型在此数据集上损失函数都能显著下降,在验证集上的预测精度在90%左右。如果读者有兴趣的话,可以进一步调整学习率和训练轮数等超参数,观察是否能够得到更高的精度。
参考文献
[1] Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learn- ing applied to document recognition. Proc. of the IEEE, 86(11):2278–2324, 1998
[2] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, pages 1097–1105, 2012.
[3] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014b.
[4]Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolu- tions. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015.
[5] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016a.