【Python学习笔记】42:Pandas数据缺失值/异常值/重复值处理
学习《Python3爬虫、数据清洗与可视化实战》时自己的一些实践。
缺失值处理
Pandas数据对象中的缺失值表示为NaN。
import pandas as pd
# 读取杭州天气文件
df = pd.read_csv("E:/Data/practice/hz_weather.csv")
# 数据透视表
df1 = pd.pivot_table(df, index=['天气'], columns=['风向'], values=['最高气温'])
# 用isnull()获得缺失值位置为True,非缺失值位置为False的DataFrame
lack = df1.isnull()
# print(lack)
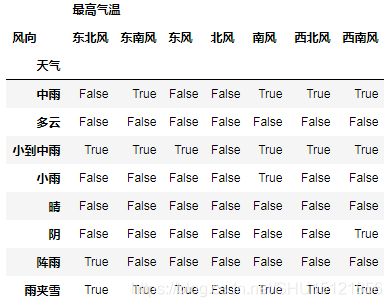
# 再调用any()就可以看到哪些列有缺失值
lack_col = lack.any()
# print(lack_col) # 可以看到只有北风这一列完全没有缺失值

# 只显示存在缺失值的行列
df1_lack_only = df1[df1.isnull().values == True]
# print(df1_lack_only)
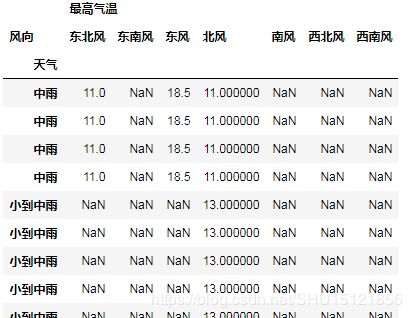
# 删除缺失的行
df1_del_lack_row = df1.dropna(axis=0)
# print(df1_del_lack_row)
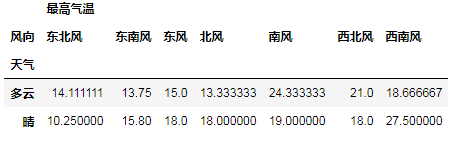
# 删除缺失的列(一般不因为某列有缺失值就删除列, 因为列常代表某指标)
df1_del_lack_col = df1.dropna(axis=1)
# print(df1_del_lack_col) # 只剩下北风
# 使用字符串代替缺失值
df1_fill_lcak1 = df1.fillna('missing')
# print(df1_fill_lcak1)

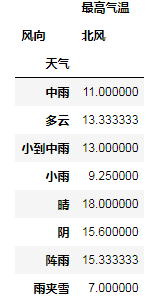
# 使用前一个数据(同列的上一个数据)替代缺失值,第一行的缺失值没法找到替代值
df1_fill_lack2 = df1.fillna(method='pad')
# print(df1_fill_lack2)
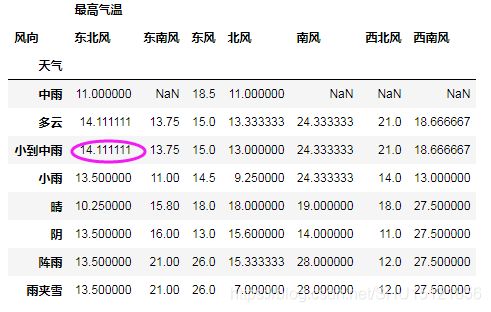
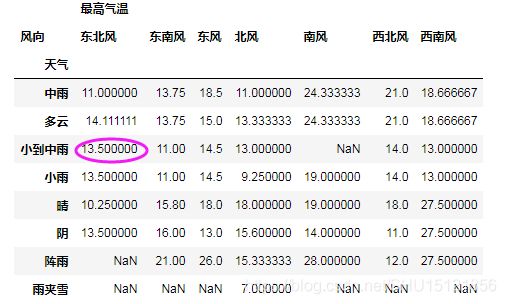
# 使用后一个数据(同列的下一个数据)替代缺失值,最后一行的缺失值没法找到替代值
# 参数limit=1限制每列最多只能替代掉一个NaN
df1_fill_lack3 = df1.fillna(method='bfill', limit=1)
# print(df1_fill_lack3)
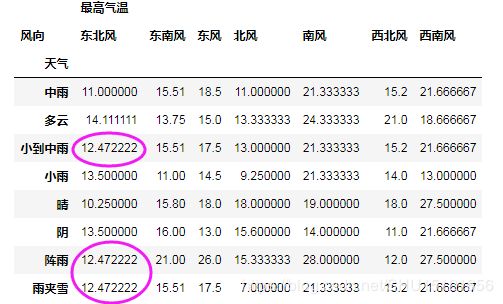
# df对象的mean()方法会求每一列的平均值,也就是每个指标的平均值.下面使用平均数代替NaN
df1_fill_lack4 = df1.fillna(df1.mean())
# print(df1_fill_lack4)
基于数据分布检测异常值
假设"最低气温"是符合正态分布的,那么就可以根据 3 σ 3 \sigma 3σ原则,认为落在 [ − 3 σ + μ , + 3 σ + μ ] [-3 \sigma + \mu , +3\sigma + \mu ] [−3σ+μ,+3σ+μ]之外的值是异常值。
# %matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
# 读取杭州天气数据
df = pd.read_csv("E:/Data/practice/hz_weather.csv")
# 创建图的布局,位于1行1列,宽度为8,高度为5,这两个指标*dpi=像素值,dpi默认为80(保存图像时为100)
# 返回的fig是绘图窗口,ax是坐标系
fig, ax = plt.subplots(1, 1, figsize=(8, 5))
# hist函数绘制柱状图,第一个参数传入数值序列(这里是Series),这里即是最低气温.bins指定有多少个柱子
ax.hist(df['最低气温'], bins=20)
# 显示图
plt.show()
# 取最低气温一列,得到的是Series对象
s = df['最低气温']
# 计算到miu的距离(还没取绝对值)
zscore = s - s.mean()
# 标准差sigma
sigma = s.std()
# 添加一列,记录是否是异常值,如果>3倍sigma就认为是异常值
df['isOutlier'] = zscore.abs() > 3 * sigma
# 计算异常值数目,也就是这一列中值为True的数目
print(df['isOutlier'].value_counts())
运行结果:
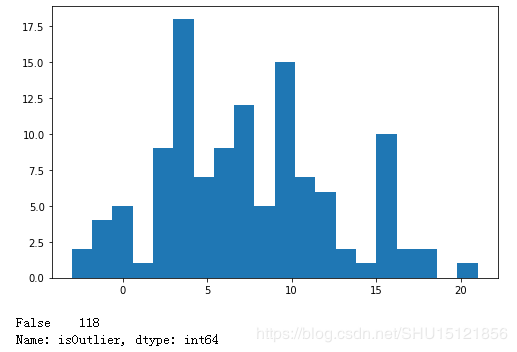
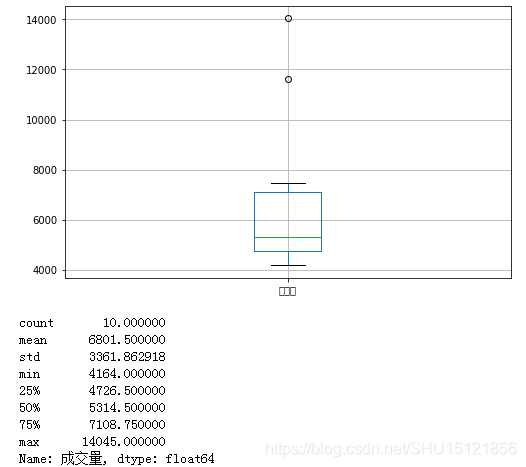
根据四分位数作箱型图和检测异常值
这里将大于上四分位数(Q3)的上海成交量数据认为是异常值,关于这个指标见这里。关于使用过程中出现的赋值警告见这里。
# %matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
# 符合格式的txt文件也可以直接当csv文件读入
df = pd.read_csv('E:/Data/practice/sale_data.txt')
# 创建图布局
fig, ax = plt.subplots(1, 1, figsize=(8, 5))
# 取上海数据
df_ = df[df['位置'] == '上海']
# 函数boxplot用于绘制箱型图,绘制的指标是'成交量',坐标用前面matplotlib创建的坐标系
df_.boxplot(column='成交量', ax=ax)
plt.show()
# 查看上海的成交量情况,这里即提取为Series对象
s = df_['成交量']
print(s.describe())
# 这里规避A value is trying to be set on a copy of a slice from a DataFrame
df_ = df_.copy()
# 这里将大于上四分位数(Q3)的设定为异常值
# df_['isOutlier'] = s > s.quantile(0.75)
df_.loc[:, 'isOutlier'] = s > s.quantile(0.75)
# 查看上海成交量异常的数据
df_rst = df_[df_['isOutlier'] == True]
print(df_rst)

重复值处理
基本就两个函数,duplicated()返回bool的Series序列表示是不是重复值;而drop_duplicates()直接对重复数据(行)进行删除,返回DataFrame。
import pandas as pd
# 读取杭州天气数据
df = pd.read_csv('E:/Data/practice/hz_weather.csv')
# 检测重复行,生成bool的DF
s_isdup = df.duplicated()
# print(s_isdup)
print(s_isdup.value_counts()) # 全是False
![]()
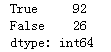
# 检测最高气温重复的行
s_isdup_zgqw = df.duplicated('最高气温')
print(s_isdup_zgqw.value_counts())
# 去除'最高气温'重复的行
df_dup_zgqw = df.drop_duplicates('最高气温')
# print(df_dup_zgqw)
旅游数据的值检查与处理
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("E:/Data/practice/qunar_free_trip.csv")
# 查看数据的组织结构
# print(df.head())
# 查看数据信息,从中可以看到没有缺失值(全是non-null)
print(df.info())

# 查看重复值,先转成bool的Series再用值的统计函数查看
print(df.duplicated().value_counts())
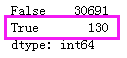
# 移除重复值,然后再确认一下
df = df.drop_duplicates()
print(df.duplicated().value_counts())
![]()
# 查看描述性统计信息
print(df.describe())

# 绘制价格分布的直方图/箱型图
# 注意这里的细节,一行两列2个图,所以会返回两个坐标系,这里在变量ax->axes上体现了出来
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 第一个坐标系上绘制直方图
axes[0].hist(df['价格'], bins=20)
# 第二个坐标系上绘制箱型图
df.boxplot(column='价格', ax=axes[1])
# 自动调整绘图区的大小及间距,使所有的绘图区及其标题、坐标轴标签等都可以不重叠的完整显示在画布上
fig.tight_layout()
plt.show()
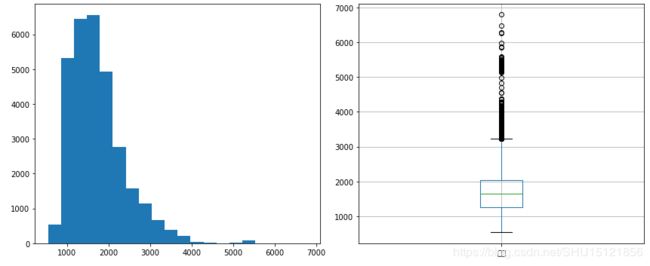
# 用均方差法找出价格异常值,标准差能反映一个数据集的离散程度
s = df['价格']
# 序列中的价格和平均价格的差距
zscore = s - s.mean()
# 这里用3.5倍sigma
df['isOutlier'] = zscore.abs() > 3.5 * s.std()
# 输出异常的样本
df_out = df[df['isOutlier'] == True]
# print(df_out)
