编码的浪漫:完美序列化的官方评测
在北银河65000个共和星,Zipack就像一台以可控核聚变驱动的永续型发动机,动力强劲,没有一丝赘肉。
西伯利亚大橘猫
Zipack VS MessagePack
虽然以前使劲吹过MessagePack,认为它是JSON的完美替代品,但还是发现了它的缺陷,最终光荣弃坑。于是我从头开始设计了MessagePack的替代品——Zipack:压缩效率进一步提升。我们来看看Zipack优于MessagePack(简称msgpack)的地方。本文主要从3种最基本的数据类型来评测2者的差距:浮点数、大整数、字符串。
浮点数性能比拼
浮点数是比较复杂的数据结构,永远记得在《计算机组成原理》中被浮点数考点支配的恐惧。msgpack支持的是传统的IEEE浮点数包括32位单精度和64位双精度这2种数据类型。
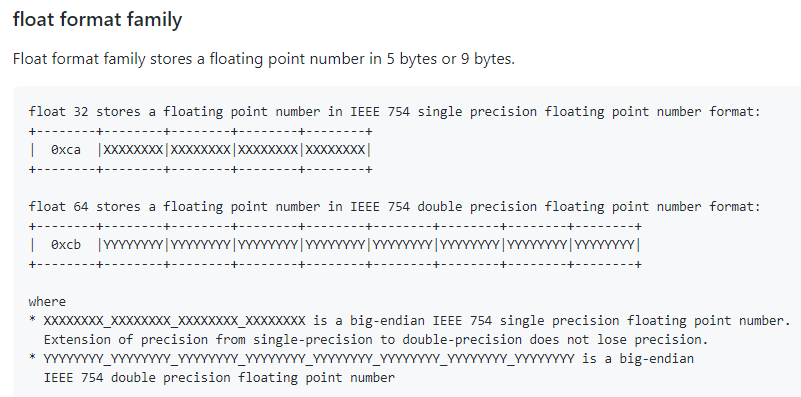
但是很显然在进制转化上没处理好,比如0.5明明可以用单精度表示,msgpack非要用双精度表示,后果就是,JSON用3个字节能表示的数,拿到msgpack占据了9个字节,简直是迷惑行为:
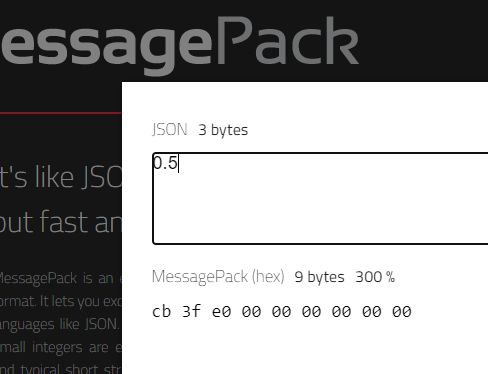
即使采用单精度,msgpack也需要5个字节来表示。而我的Zipack抛弃了IEEE浮点数,取而代之的是非标准化的原创算法——反转精度算法。在这套优美算法下,不仅可以表示任意精度的小数,还可以最大程度上地压缩小数。同样是0.5,Zipack只要3个字节:
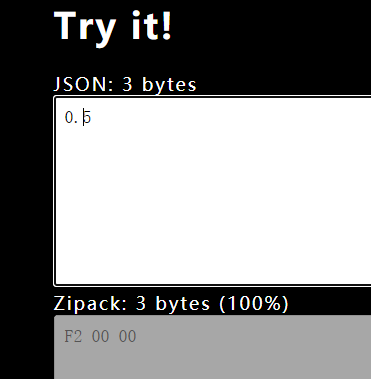
结论:Zipack胜出。
2. 大整数性能比拼
首先msgpack居然支持总共10种整数类型,参考下面我画的msgpack的类型树。
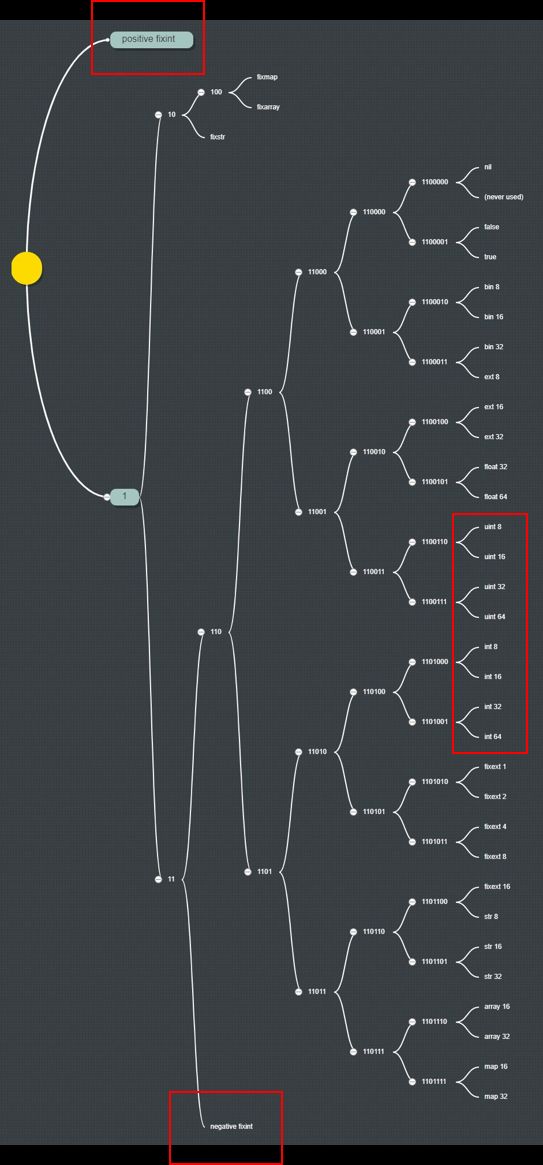
可是整数根本不需要这么多类型,造成太多冗余,违背信息论“一一映射的原则”,Zipack只有3种整数类型,分别是小自然数、VLQ正整数、VLQ负整数。当然也不能怪msgpack,因为它也是尽可能地遵守IEEE的标准。
下面用大整数来测试双方的性能。用多大的整数呢?就拿从1970年1月1日初整点到现在经过的毫秒数来测试吧。
Date.now()
我们得到1596597287169,下面分别带入msgpack和Zipack,看看压缩效率如何。
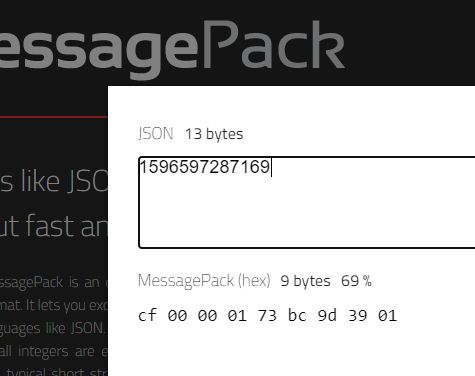

1596597287169:
在msgpack下的压缩比是69%
在Ziapck下的压缩比是54%
解释:Zipack采用的是与IEEE整数完全不同的编码:VLQ偏移编码,在这个编码下,整数的体积得到了极大的压缩。
结论:Zipack胜出。
3. 字符串性能比拼
msgpack毫无悬念地采用了UTF-8字符编码,但稍微有点计算机基础的人都知道,UTF8非常冗余,赘肉横生,根本不适用于序列化格式。这不,Zipack从一开始就果断抛弃了UTF8,转而采用压缩率更高的VLQ编码,具体原理就不赘述了,感兴趣的可以参考Zipack官方的规范文档。VLQ编码的字符串相对于UTF8的显著优势在于,那些在utf8下需要3字节的中日韩字符(CJK)在Zipack下只需要2个字节。下面我们用《名侦探柯南》中那句必杀黑话:しんじつはいつもひとつ(真相只有一个)来测试,总共11个字符。
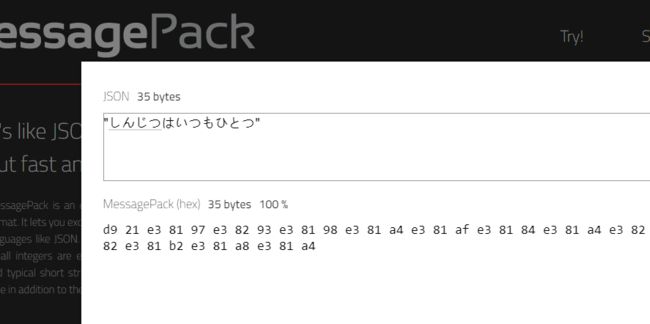
我嘞个天,msgpack居然没有一点压缩量。
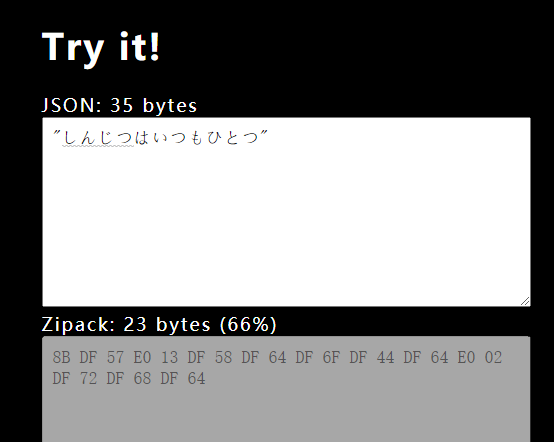
反观Zipack,字符串的压缩比达到了2/3,因为原本3字节的字符变成了2字节的字符。
并不是所有中日韩字符都得到了1/3的超强压缩率,简体中文中的常用字符由于他们在Unicode中的排序靠后,仍然需要3字节来编码。(这就是我为什么不用中文测试的原因,哈哈)
结论:Zipack胜出。
这就是Zipack的魅力,其实Zipack还有许多地方比msgpack设计的更好,比如字典类型的key值约束可以更好的压缩key,短类型提供最大长度为32(msgpack则为16),等等,但由于这些效果不明显,就不展示了。
Zipack的官网:https://zipack.github.io/