探索 Android 网络优化方法

目录

前言
1. 网络优化的三个要点
1. 多维
网络优化应该是多维的,一般情况下,一谈到网络优化,大部分人首先想到的就是流量消耗,但是实际上流量消耗多少只是网络优化的其中一个维度。
只对流量消耗一个维度进行优化是不够的,甚至有的团队即便在流量优化上也没有做好,比如对于网络流量的消耗统计不够全面和精确。
2. 精准
在做网络流量统计时,我们要做精准度量,如果只是获取了具体消耗了多少的值,对于我们定位和解决问题是没有太大的帮助,因为这个值只能表明用户用了多少流量。
如果线上用户反馈 App 消耗流量较多,但是我们不知道这个用户总共使用了 App 多长时间的话,那就不好定位问题所在,如果用户使用 App 的时间比较长,那消耗流量多一些很可能是正常的。
又比如用户反馈 App 在后台消耗流量比较多,但是我们只统计了整体的值,那就无法断定 App 在后台运行时到底消耗了多少流量。
3. 监控
针对网络优化,我们应该建设全面且完善的网络监控体系,不能只监控一个指标,假如只监控网络请求成功率,那我们就只能知道用户大概的网络使用情况,这种粗粒度的监控没办法帮助我们找出并解决问题的根源。
比如线上用户使用了某个功能使用了 1000 次,然后出现了 1 次异常,而且用户点击重试后就恢复正常了。
这样单从数据上来看的话,网络请求的成功率还是比较高的,但是只通过成功率一个值是无法知道这一次异常出现的原因,也就无法避免后续出现这类异常。
2. 网络优化的两个维度
1. 流量维度
流量维度也就是 App 在一段时间内流量消耗的精准度量。
流量消耗大不仅对用户有影响,对公司的运营成本也有影响,比如带宽、服务器数量、CDN 等方面的开支,而且网络请求密集对手机耗电量也有一定的影响。
在流量维度上,我们要做到区分类型、监控异常、上报日志。
-
区分类型
我们不仅要知道用户在某个时间段内的具体流量消耗,还要知道用户在不同网络类型(流量、WiFi)下的流量消耗、区分 App 在前台和在后台时的流量消耗。
只有积累了不同维度的数据,才能快速断定和解决问题。
-
监控异常
对于流量统计,我们不仅要知道用户的流量消耗均值,还要知道线上用户消耗流量的异常率。
这里的异常分为三种:
-
流量消耗过多
-
请求次数过多
-
下载文件过大
这三个都是我们要注意的异常。
-
-
上报日志
最理想的情况,就是我们对所有的网络请求,在本地都有一个完整的监控,每一个请求的 Request 和 Response 相关的所有信息都全部记录下来。
服务端可以下发指令控制客户端上传这些数据,客户端也可以在相关数据超过阈值后主动上报。
2. 质量维度
网络请求的质量也非常关键,它直接对应了用户的真实体验,如果网络请求速度慢或请求成功率比较低,都会导致不好的用户体验。
对于网络请求质量的监控,可以从下面几个维度进行区分,以便后续能快速定位和解决问题。
- 请求时长
- 请求成功率
- 失败率
- Top 失败接口
3. 网络优化的两个误区
-
只关注流量
只关注流量消耗,忽视了其他维度。
-
忽略个体数据
还有就是做网络监控时只关注均值和整体的数据,忽略了个体的数据。
比如前面提到的请求成功率的例子,从整体上来看成功率非常高,但是这种数据无法帮助我们改善单次请求。
1. 三个线下测试工具
对于线下测试环境,我们要有一个正确的认识,线下测试是为了把问题尽可能在上线前暴露出来,在线下测试环节,我们要注意下面 4 点。
-
网络切换
-
弱网/无网测试
-
请求是否有误
接口请求是否有误,比如传了过多的参数或传参不正确;
-
周期长
C 端的 App 到了稳定期后,用户可能高达几千万甚至更多,这时 App 功能一般是非常复杂的,而且包含了其他功能,比如性能监控等。
这些功能的网络请求往往不是实时上报的,所以我们在做流量消耗测试的时候,周期一般会很长,不能只是简单测 10 分钟。
我们要确保我们的 App 在切换网络、弱网或无网时做到下面这两点。
-
不能中断流程
有的 App 对安全性要求比较高,如果突然切换网络状态,会导致用户的登录态失效,也就是要用户重新登录。
这时我们要注意重新登录后 App 会不会重新回到之前的流程中,不能中断用户正在进行的流程。
-
关闭加载弹窗
而且在弱网或无网状态下,一定要测试 Loading 弹窗是否会停止,如果不注意的话,在无网的情况下,应用的请求失败了,但是却没有关闭 Loading 弹窗,影响了用户的其他操作。
如果对无网状态重视不足,就测不出这样的 Bug 。
下面我们来看 3 个常用的线下测试工具:
- Network Profiler
- Charles
- Stetho
1.1 Network Profiler
Network Profiler 是 AS 自带的网络分析工具,它能显示实时网络活动,比如发送网络请求、接受的数据以及连接数等。
1. 点击开始分析。

2. 连接视图
然后在 Profiler 下方可以看到连接视图(Connection View),右侧则是某个连接的信息,包括请求时间、响应、请求以及调用栈。

3. 线程视图

4. 请求信息
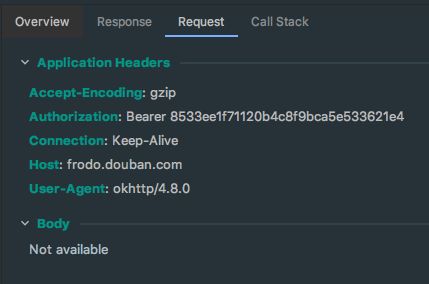
5. 响应信息
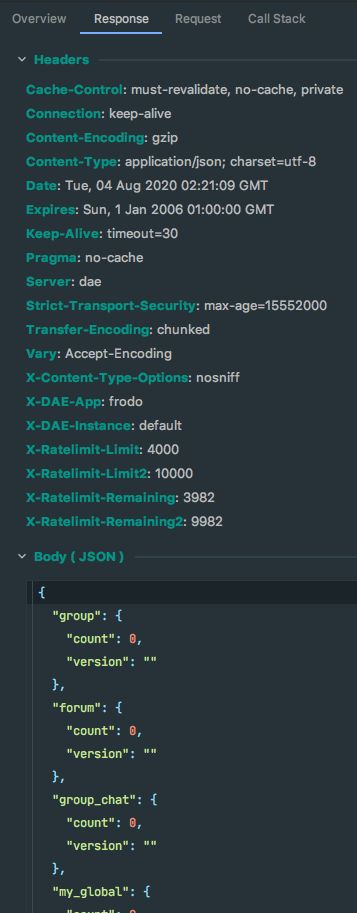
6. 调用栈
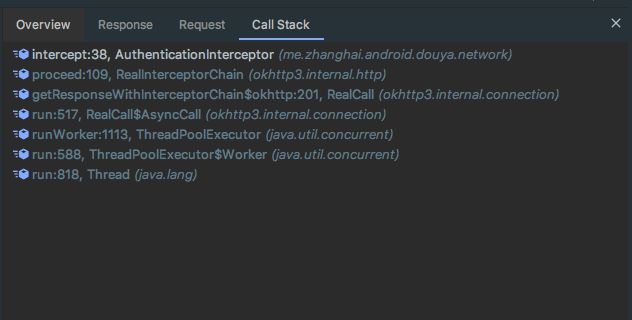
1.2 Charles
下面是 4 个比较常用的抓包工具:
-
Charles
Charles 是使用 Java 开发的,在 Mac 上使用比较多;
-
Fiddler
在 Windows 上使用得比较多;
-
Wireshark
-
TcpDump
下面我们重点来看下 Charles 的使用, Charles 支持断点功能、模拟数据以及弱网模拟等功能。
1.2.1 基础用法
- 在官网上下载 Charles
- 打开 Charles 的代理功能
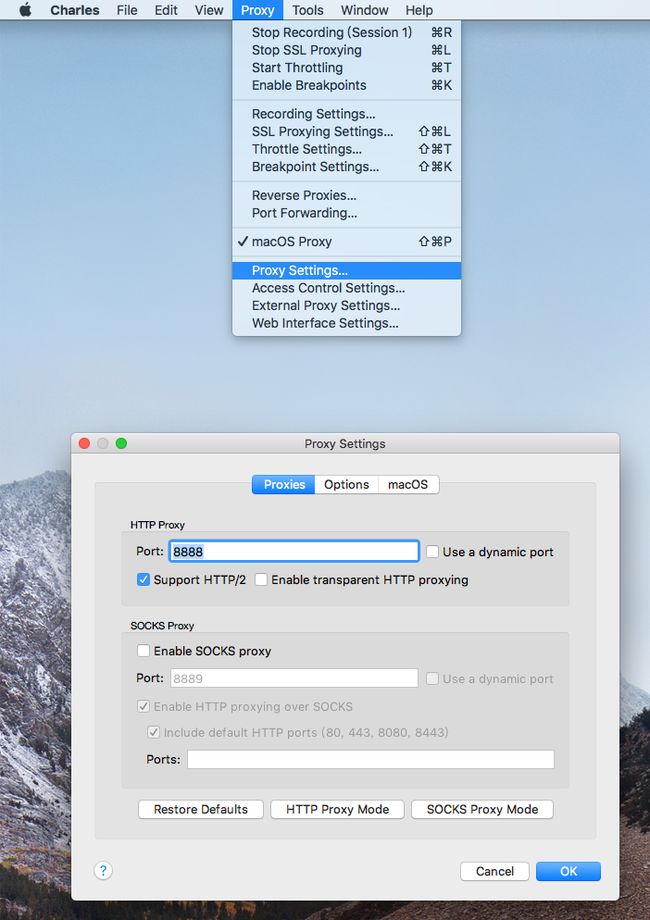
- 查看电脑 IP 地址

vboxnet2 是虚拟机 Virtual Box 的地址。
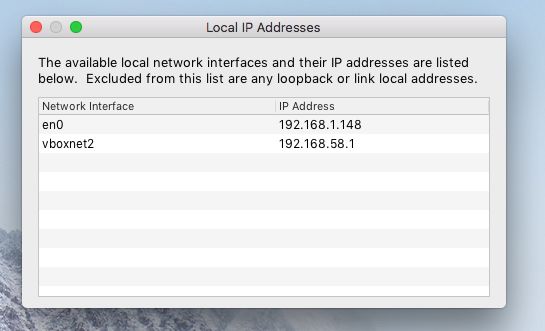
- 设置 WiFi 代理地址

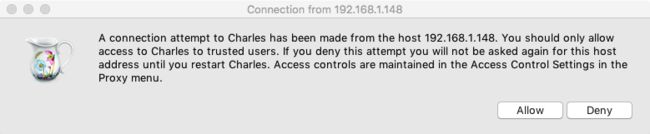
-
同意连接
设置代理后,当我们在设备上访问网络时,Charles 会弹出一个是否允许连接的弹窗,我们点击允许(Allow)即可。
-
安装证书
如果是抓取 HTTPS ,那就要安装证书,否则请求和响应信息都会是乱码。
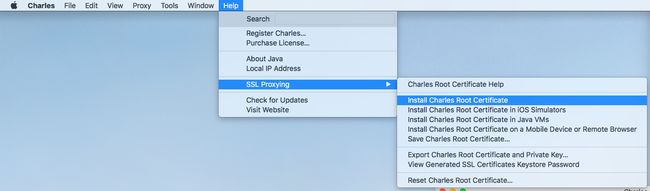
搜索 charles 并选择始终信任。

- 安装手机证书
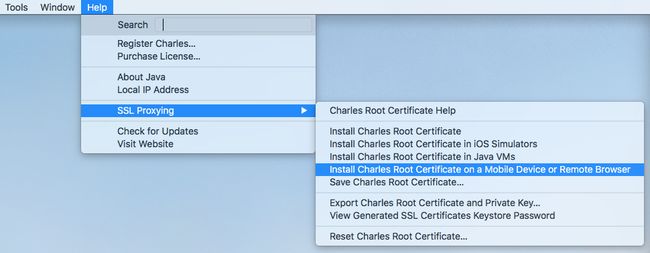
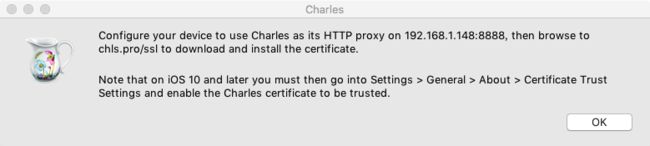
选择安装证书在移动设备后,Charles 会弹出一个代理提示,让我们去 chls.pro/ssl 下载并安装证书。
我已经下载过了,所以这里提示的是重新下载,下载后点击安装即可。
-
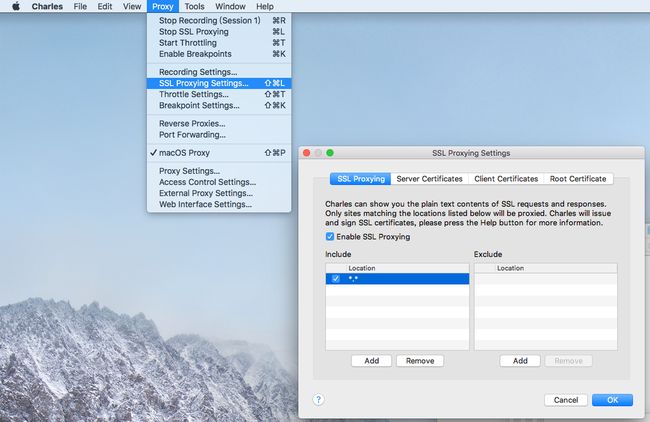
添加主机
然后在 SSL Proxying Settings 中添加我们要抓包的主机地址,这里可以使用通配符 *.* 。
- 添加网络安全配置
在 res/xml 下添加 network_security_config.xml

然后在 Manifest 的 Application 标签中添加该配置。

然后就可以看到抓包结果了。
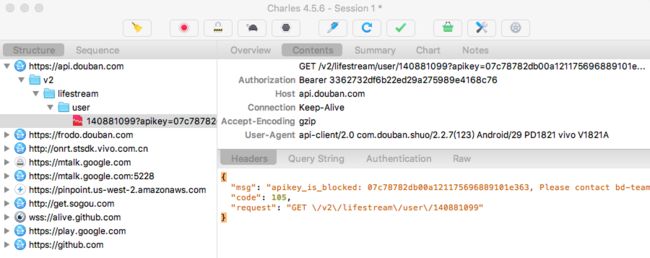
1.2.2 断点
我们右键点击任意一个请求后,就可以看到断点(Breakpoints)选项。

如果想要查看已经添加的断点列表,可以在 Proxy->Breakpoint Settings 中查看。
如果想只对 Request 或 只对 Response 断点,可以点击断点,然后在编辑断点弹窗中设置。
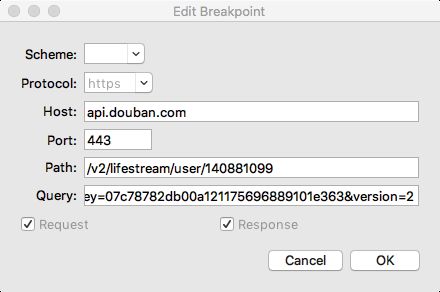
下面看下进入断点后的界面,当我们再次发起打了断点的请求时,可以看到断点界面。
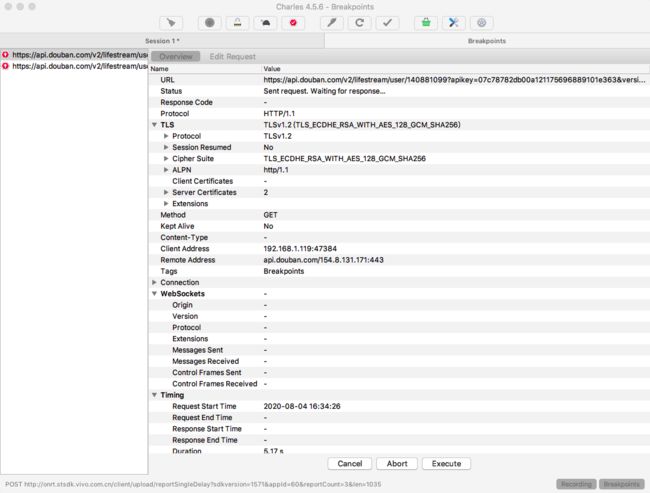
当我们点击 Edit Request 标签后,我们可以在这里编辑请求的信息。
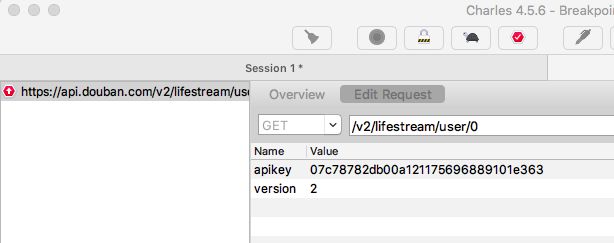
当我把 version 改为 3 后,可以看到请求中的参数改成了 3 。

1.2.3 模拟数据
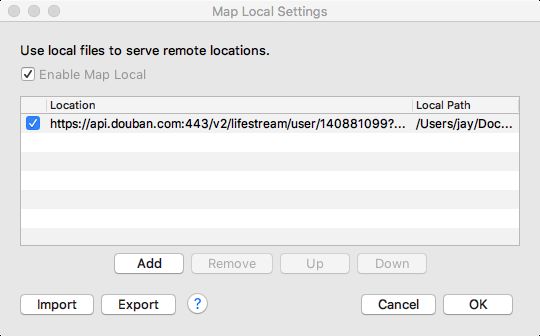
Charles 有一个叫 Map Local 的功能,Map Local 多用于服务端接口未开发完毕,只定义了协议时的情况。
我们可以用 Map Local 模拟自己想要的假数据,可以自由模拟各种脏数据,这样就算服务端开发进度比较慢,不会影响客户端的开发进度,除了 Map Local,也可以使用 MockK 等用于测试的模拟框架来实现功能。
下面我们来看下怎么使用 Map Local。
然后右键点击请求,弹出菜单的最下方就是 Map Local。
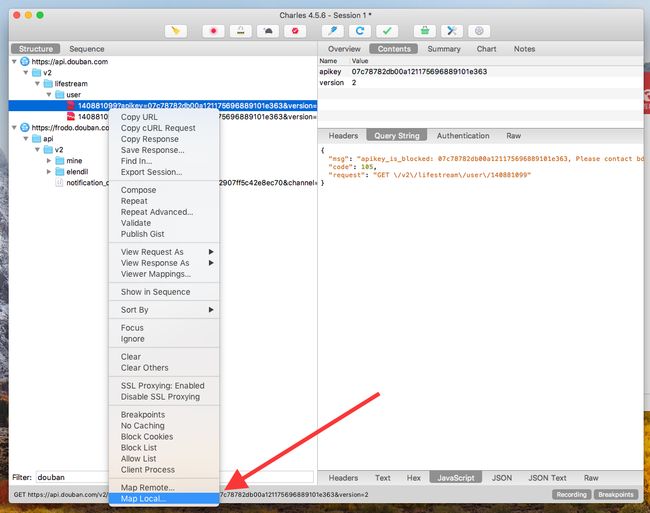
点击 Map Local 后,可以看到 Edit Mapping 弹窗。

原始的响应是下面这样的。
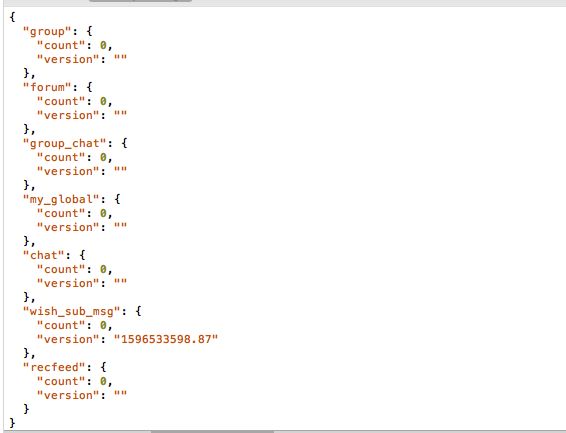
然后建立一个 maplocal 文件,把 group 里的 count 改成 20 。

当客户端再次发起相同的请求时,就可以看到 group 的 count 的值变成了 20 。
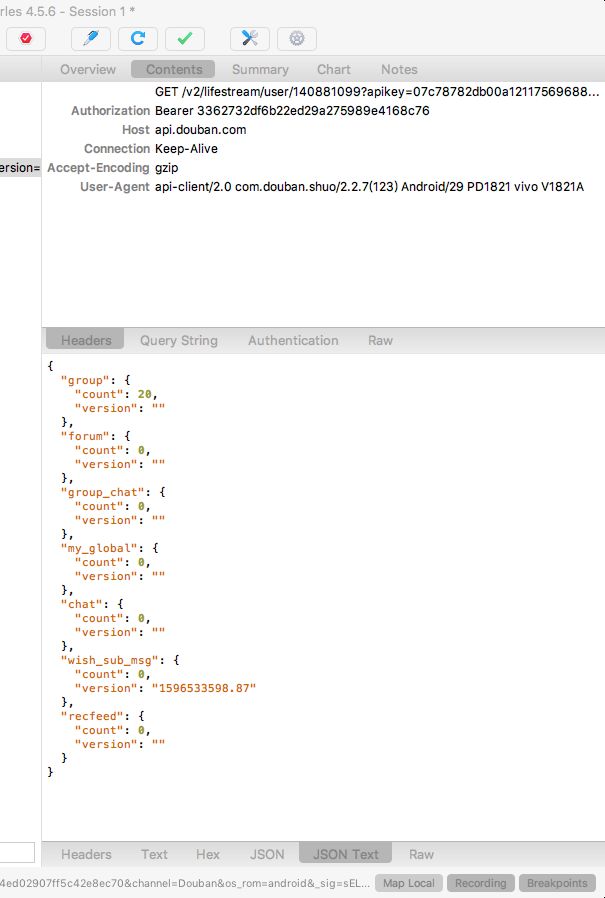
如果想关闭 Map Local,可以点击 Tools -> Map Local,然后把 Enable Map Local 的勾选取消掉。
1.2.4 弱网模拟
Charles 支持弱网模拟功能,点击 Proxy -> Start throtting。
勾选 Enable Throttling 后,就开启了限流功能,限流功能支持下面几个选项。
-
预设值(Throttle preset)
-
带宽(Bandwidth)
-
利用率(Utilisation)
-
往返延迟(Round-trip-latency)
-
MTU(传输 TCP 包的最大尺寸)
-
可靠性(Reliability,丢包)
-
稳定性(Stability,抖动)
-
不稳定质量范围(Unstable quality range)
主要针对 Statbility 中设置的范围;
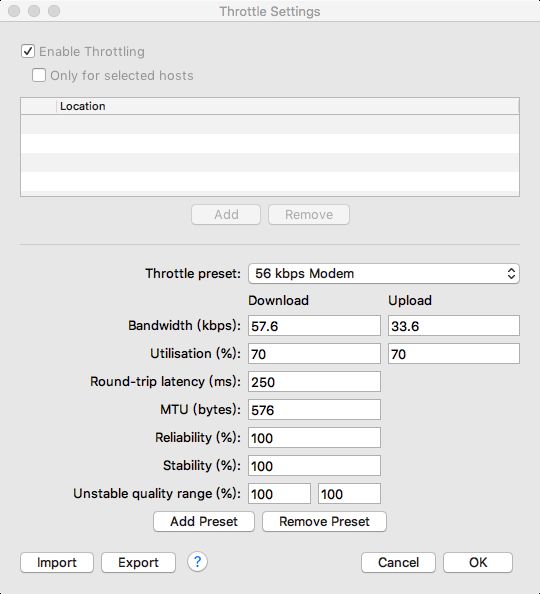
下面是一些常用的预设值。

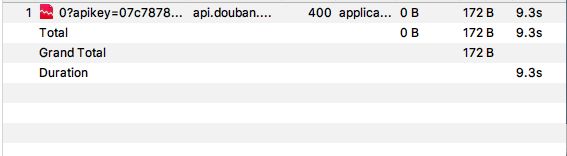
下面这个请求,在限流前的总处理时间是 177 毫秒。

当开启了弱网模拟后,变成了 9.3 秒。
1.3 Stetho
看完了 Charles,下面我们来学习下 Stetho,Stetho 是一个强大的应用连接桥,可以连接 Android 和 Chrome,有网络监控、视图查看、数据库查看、命令行扩展等功能。
1.3.1 Stetho 用法
- 添加依赖。
// Android 应用调试工具
implementation 'com.facebook.stetho:stetho-okhttp3:1.5.1'
这个库是 Stetho 针对 OkHttp 的实现。
- 初始化
- 添加拦截器
- 打开 Chrome inspect
在 Chrome 中输入 Chrome://inspect ,然后就可以看到设备上的 Chrome 已经打开的标签,下方就是打开了 Stetho 调试的 App。

- 打开 DevTools
点击豆芽下面的 inspect 后,就可以看到 DevTools,点击 DevTools 中的 Network 标签,就可以看到 App 发出的请求和接收到的响应等数据。
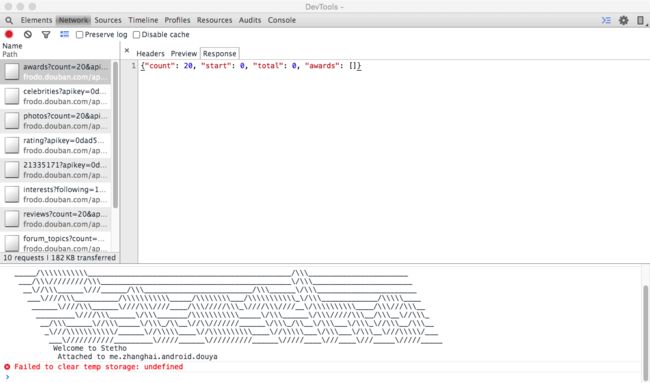
由于 Stetho 的抓包功能没那么强大,所以一般情况下不会用 Stetho 作为抓包工具。
2. 线上监控的三个要点
在看获取网络流量前,我们先来看下线上监控的三个要点:服务端监控、客户端监控以及异常监控。
2.1 服务端监控
1. 耗时统计维度
对于服务端的监控,我们要注意请求的耗时,而且耗时要分多个维度区分。
-
地域
具体是哪个省、哪个城市的请求速度比较慢;
-
时间段
-
版本
-
机型
2. 失败率
服务端要统计失败率:
-
请求失败
-
业务失败
业务相关的失败也是失败,比如网络请求确实成功了,但是用户没有拿到自己需要的数据,对于失败率的统计要全面,这样衡量的指标才能更敏锐地感知线上的异常波动;
3. Top 失败接口
同时在 APM 后台,我们最好统计一下一段时间内,比如 1 天或 1 周内,排行 Top 的失败接口或异常接口,每隔一段时间就进行一次统计,这样就能知道哪些接口不稳定,以便进行针对性的优化。
2.2 客户端监控
客户端监控比服务端监控更关键,在客户端的监控则更全面,能拿到更多的数据。
我们要在线上监控的数据包括请求具体耗时、成功率、错误码以及图片加载每一步的耗时。
虽然图片加载耗时和成功率在服务端也是可以统计的,但是服务端拿到的数据不完整等,因为很多请求压根没有到服务端就失败了。
而且服务端传过来的数据加上网络通道的延迟时间,肯定比服务端统计到的时间要长,所以我们要在客户端也加上统计。
1. API 监控
客户端能拿到请求的每一个步骤的信息,包括 DNS 解析时间、建立连接的时间、请求时间以及网络包大小等信息。
同时我们可以记录用户每一次网络请求的操作,比如具体请求了哪些接口,请求是否成功以及失败的原因,这些信息我们都能作为监控的基础信息传给 APM 服务端,在后面会介绍如何监控网络请求的每一步。
2. 图片监控
同时还要注意做图片监控,一张图片消耗的流量可能比 5 个甚至更多接口的数据还要多。
3. 网络容灾机制
假如某一天我们的用户量突然暴涨,按服务器可能是扛不住这个压力的,对于服务端来说,可以用备用服务器分流,避免把主服务器搞垮。
而我们客户端也可以做一个策略,就是在一定时间内,网络请求失败了多次时,就不再进行网络请求。
3.2 异常监控
异常监控的目的,是提升我们对异常的感知灵敏度,而不是被动等待用户反馈。
1. 服务器防刷
在服务端,我们要判断是不是有人在刷我们的服务器,也就是恶意攻击,如果检测到有人在刷服务器,我们可以锁定 IP 拒绝这些 IP 访问。
2. 异常兜底
在客户端,我们可以加上主动预警能力,比如我们下载了一个超过设定值的文件,客户端在下载后就可以把这个结果上报给服务器,表明现在遇到了异常,需要研发同学进一步确认。
在一些场景下,服务端可能出现流量过多扛不住的情况,这时客户端可以做一个兜底策略,如果在一定时间内,比如 30 秒内,接口请求连续失败 5 次,那就不允许持续访问,同时把重试时间设长一些。
3. 单点问题追查
假如线上用户反馈 App 消耗流量过多,或者是在后台时消耗流量较多,我们都可以具体分析用户下的网络请求日志,以及下发命令查看具体时间段的流量消耗。
3. 三个线上监控方案
有的问题只在线上出现,在线下发现不了,比如在线下测试某个版本的时候,H5 包不一定是新版本,但是到了线上后,部分用户可能会被命中,然后下发了新版本的包。
而这些包如果没有经过压缩,这样的异常就无法在线下的测试环境中全部发现,只能通过线上监控发现。
下面我们来看下三个线上监控方案:
- OkHttp 事件监听器
- NetworkStatsManager
- TrafficStats
这三个方案中 OkHttp 事件监听器能获取到的数据最细致,也最实用,而 NetworkStatsManager 和 TrafficStats 主要是用于获取流量消耗。
3.1 OkHttp 事件监听器
3.1.1 自定义事件监听器
下面我们来看下如何结合 OkHttp 获取网络请求质量数据,OkHttp 给我们留了一个事件监听器 EventListener 回调,我们可以自己实现这个监听器,监听每一次的请求。
首先定义一个 Model,用于存储请求和响应相关数据,这里为了演示只加上了部分数据,大家可以根据自己的需要制定自己的 Model。

创建 OkHttpEventListener,并重写我们想要的方法,这里为了演示只重写了部分方法,OkHttpEventListener 提供了非常多的方法,大家可以根据自己的需要重写。

然后设置 OkHttpClient 的事件监听器工厂 。

设置了工厂后,我们就能拿到每个网络请求的每一步的耗时和相关数据,包括 DNS 解析事件、请求事件、响应时间、响应字节数等数据,这些都是我们做线上监控必不可少的数据支撑。
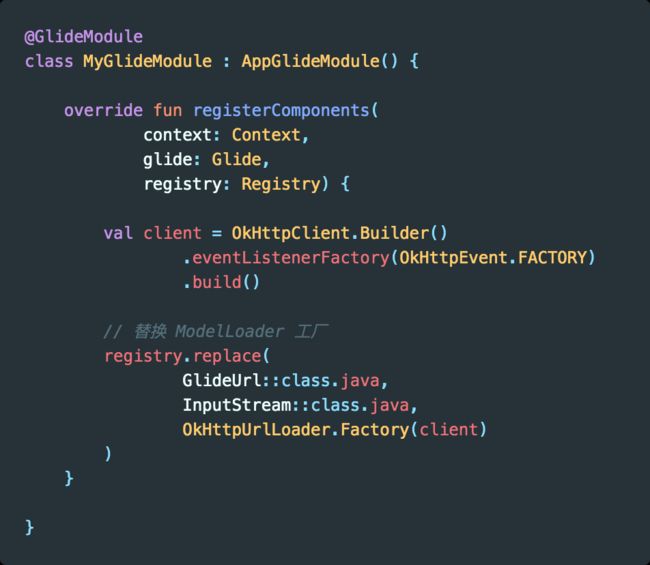
3.1.2 自定义 GlideModule
自定义 GlideModue 是为了监控图片加载的过程,下面我们来看下怎么监控 Glide 加载图片过程的耗时和相关数据。
首先添加插件和依赖。
// Kotlin 插件
apply plugin: 'kotlin-android'
apply plugin: 'kotlin-android-extensions'
apply plugin: 'kotlin-kapt'
android {
// ...
}
dependencies {
// ...
// 图片加载
kapt 'com.github.bumptech.glide:compiler:4.11.0'
implementation 'com.github.bumptech.glide:glide:4.11.0'
implementation "com.github.bumptech.glide:okhttp3-integration:4.11.0"
}
然后定义一个 GlideModue,替换 ModelLoader 工厂。
点击 Build -> Clean Project,再点击 Build -> Make Project。
然后把 Glide 替换为 GlideApp。

然后我们就可以在自定义的事件监听器里监听到图片加载过程的耗时和大小了。
3.1.3 OkHttp 最大并发请求数
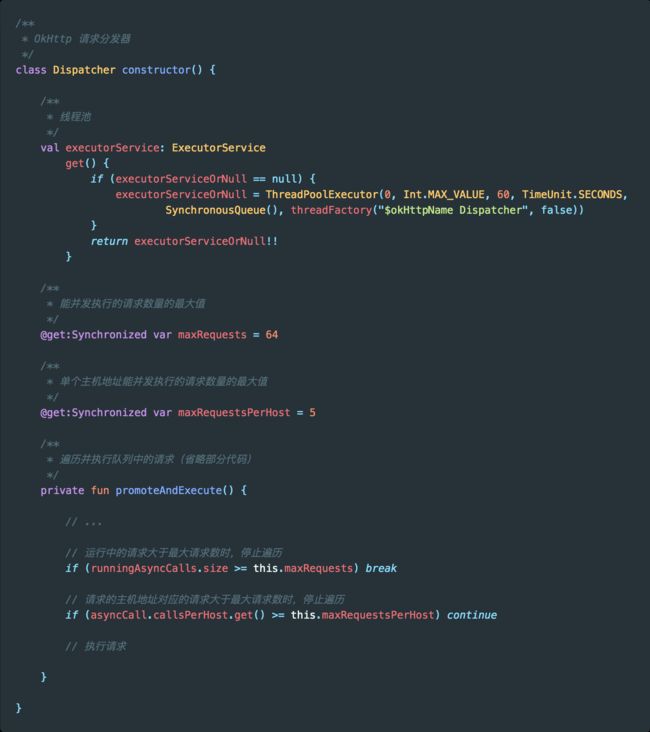
关于请求的频率,我们可以看下 OkHttp 默认的请求池,在 OkHttp 的 Dispatcher 分发器中,有一个 executeService 线程池,它的核心池大小为 0 ,最大值是整型的最大值。
但这并不是意味着通过 OkHttp 发送的网络请求可以并发无数个,对于 IO 密集型任务我们可以多发送一些,因为这类任务对 CPU 消耗不大,但是我们还是要注意,单个 App 能创建的线程数也是有上限的。
虽然线程池大小没有限制,但是在请求执行前会在 promoteAndExecute() 方法中判断是否已超出最大请求数量,而判断的依据就是 maxRequests(最大并发请求数) 和 maxRequestsPerHost(单个主机最大并发请求数)。
之所以要设置单个主机最多能并发执行的请求数量,防止某个域名的请求过多,导致其他域名没有机会执行。
假如我们的项目中已经做了域名收敛,只有一个域名,就可以增加单个域名下的数量限制,这样同时执行的网络请求的数量就能多一些。
3.1.4 区分前后台流量
之所以要在日志中区分前后台流量,是因为很多用户会担心 App 一直在后台消耗流量,如果粗粒度地只获取流量数据,是不知道这些流量有多少是 App 在后台运行时消耗的,这样的话不要说解决用户反馈的问题,就连定位问题都定位不了。
通过 ProcessLifecycleOwner 给请求数据打上标志,这样我们就可以分别知道用户在前台和后台的流量消耗,而且用户反馈时,我们就可以自己查看该用户的流量消耗统计,判断是否存在异常。
这个方案存在的不足,就是当用户在 30 秒内切换 App 的前后台状态时,会有一定的误差,但是这个误差是在可接受范围内的。
使用这种方式,再结合 APM 后台设置的阈值,让客户端在流量消耗达到阈值后自动上报,从而实现更精准的流量消耗监控。
下面我们来看下怎么使用 ProcessLifecycleOwner 。
1. 添加依赖
有很多 AndroidX 的库自带了 process 库,大家可以在 External Libraries 中看下有没有,有就不用添加下面这个 库了。
dependencies {
// AndroidX Lifecycle 进程
implementation 'androidx.lifecycle:lifecycle-process:2.2.0'
}
2. 定义应用生命周期观察器

3. 开始监听

4. ProcessLifecycleOwner 原理
在 ProcessLifecycleOwner 出来之前,我们自己也可以通过计数的方式来判断是不是所有 Activity 都隐藏了,是的话则断定为应用隐藏了。
而 ProcessLifecycleOwner 只是帮我们把这件事情做了,在 ProcessLifecycleOwner 的初始化方法 ini 中调用了 attach 方法,而 attach 方法中实现了 Activity 生命周期回调接口。
以 onStart 为例,ProcessLifecycleOwner 中有一个 mStartdCounter,每次有一个 Activity 的 onStart 方法被调用了,mStartdCounter 就会加 1,如果 mStartCounter 等于 1 ,则表明应用启动了,然后 ProcessLifecycleOnwer 就会通过 mRegistry 调用我们自定义的 onAppForeground 方法。

3.1.5 四步上传数据
下面是上报性能日志的大概的四个步骤。
-
后台任务
在 App 启动时,执行一个后台任务;
-
间隔统计
这个任务每隔一段时间(如 30 秒内)就获取网络数据;
-
自定数据
自己维护一份数据统计,给数据加上标志,记住用户在前后台的流量消耗总量;
-
上报数据
在合适的时机(如用户反馈、达到阈值、处于 WiFi 网络下)把数据上报到 APM 后台,这样对用户的流量就不会造成影响,而且数据也能作为流量治理依据;
3.2 NetworkStatsManager
NetworkStatsManager 是 API 23 后的流量统计管理器,它可以获取某个时段的流量信息,也可以获取不同网络类型下的流量消耗,它最大的不足就是用户体验比较差,需要用户开启“查看使用情况”权限。
下面是一些使用网络或对流量的消耗比较多的场景。
-
API 请求
-
升级包
各种升级的资源包,比如 App 升级包、WebView 使用的 H5 Zip 包、RN 使用到的 bundle 包等;
-
配置
在 App 做大后,还要用到各种配置信息,比如做 A/B 测试时使用的配置信息、运营活动下发的配置信息;
-
图片
图片是流量消耗的大户,图片的下载和上传都非常消耗流量;
-
监控
在 App 做大后,还会做各种监控功能,比如 APM 监控的各种数据都需要网络才能上传到服务端;
3.2.1 流量优化的三个要点
在讲怎么用 NetworkStatsManager 获取流量消耗前,我们要先了解下流量优化的三个要点。
1. 不能只看绝对值
绝对值不能作为流量消耗偏高的唯一统计标准,不能说 App 消耗了 10M 的流量,那就要马上去优化。
绝对值的对比是没有意义的,比如用了 App 30 分钟,浏览了很多的商品或视频,那用了 10M 可能已经算少了。
2. 对比竞品
那要以什么为标准呢?我们最好是对比竞品,对比两个 App 在相同的场景下的流量消耗。
比如和竞品一起跑一个发布评论的主流程,这里要注意,要保证两个 App 发布的评论是相同的,而且图片也是相同的,以保证变量是唯一的。
这样对比一下,如果我们和竞品的流量消耗差距比较大,那我们对流量优化的步伐,就应该加快一些,这个绝对值跟竞品的对比,应该结合使用。
3. 设定预期
我们要判断一下新上功能的流量消耗,比如我们要预期是用户使用新功能后,单次消耗流量应该为 300K 左右,但是上线后超过了 300K 时,我们就要确认下流量消耗是否偏高。
3.2.2 NetworkStatsManager 基本用法
如果我们不使用 OkHttp 的 EventListener ,而是用了 NetworkStatsManager,那么当用户反馈说某个时间段内的流量消耗较多时,我们就也可以在后台给客户端下发一个指令,让客户端上传特定时间段内的流量统计数据,然后结合用户使用时长判断 App 的流量消耗是否真的存在异常。
1. readNetworkStats
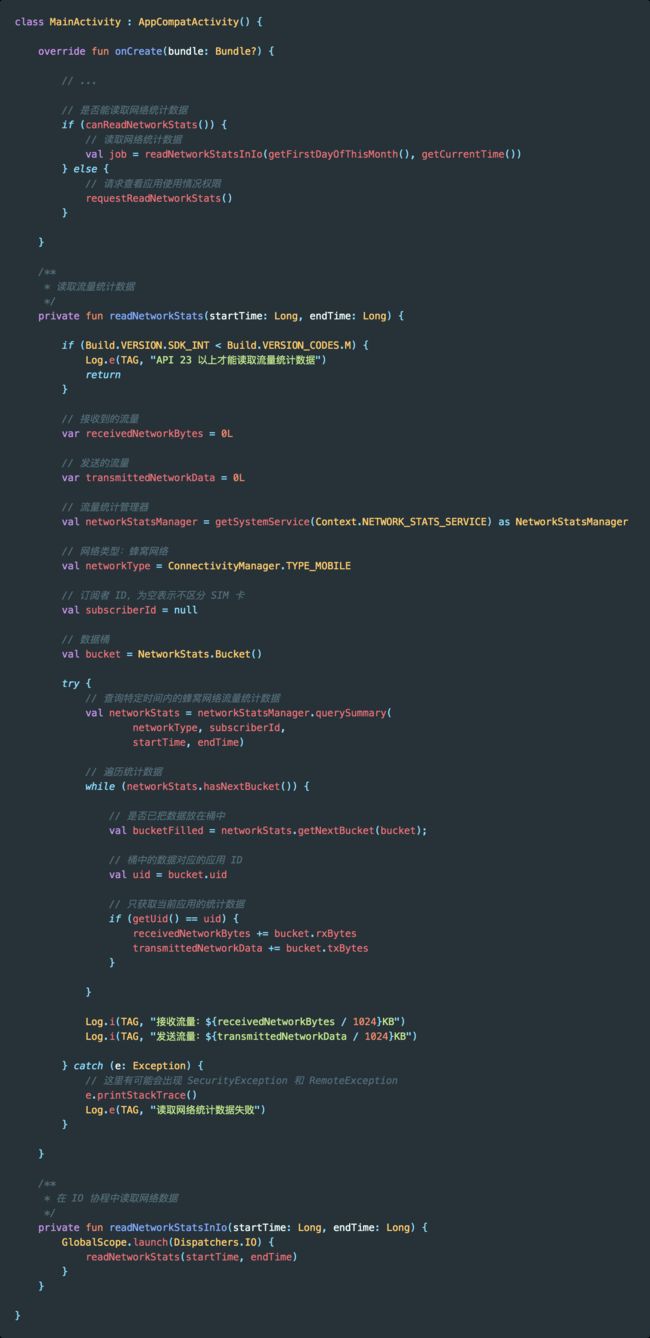
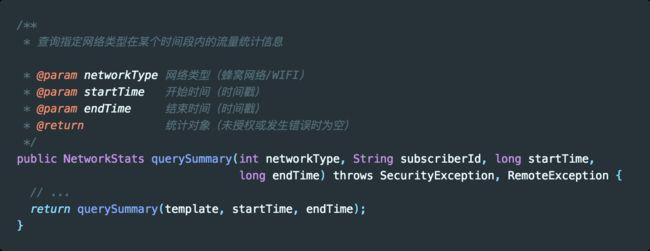
2. querySummary
下面是常用的 querySummary 方法各个参数的介绍。
querySummary 的内部处理流程如下。
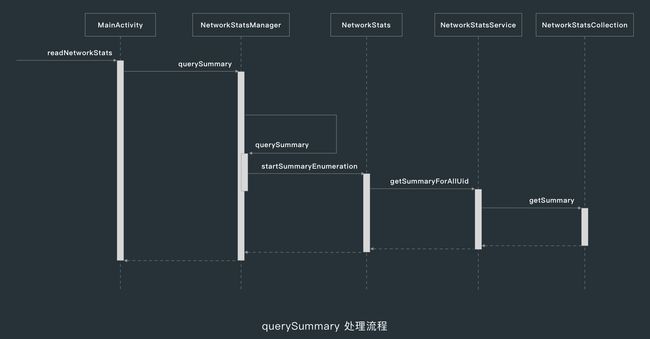
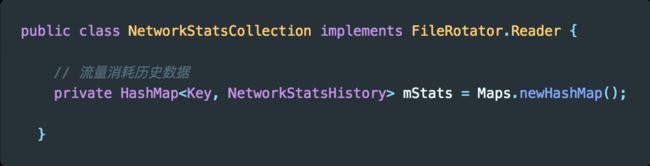
在这个流程中,最重要的就是在 NetworkStatsCollection 的 mStats 中读取系统已经保存好的网络统计数据。
3. 申请授权
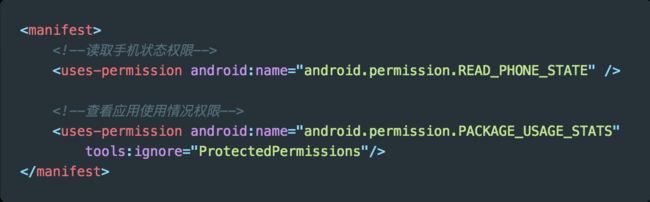
使用 NetworkStatsManager 需要额外的权限 PACKAGE_USAGE_STATS , 这个权限是系统权限,需要主动引导用户开启应用的“有权查看使用情况的应用”权限。
首先在清单文件中权限声明。
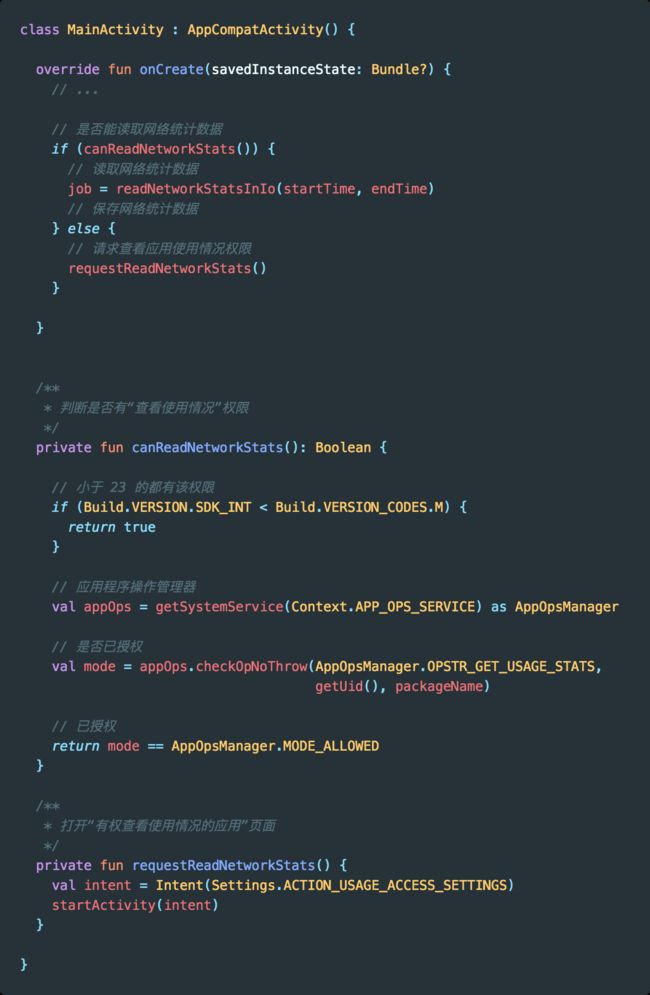
然后在代码中主动引导用户开启权限。
3.3 TrafficStats
TrafficStats 是 API 8 后提供的一种流量数据统计方案,它统计到的数据其实是我们手机上次重启后的流量消耗,也就是重启前的流量是统计不到的。
TrafficStats 常用方法:
-
getUidRxBytes(int uid)
获取指定 Uid 的接收流量;
-
getTotalTxBytes()
获取 App 总发送流量;
下面我们是 TrafficStats 的使用方式。

一般情况下不使用 TrafficStats,因为它存在下面两个问题:
-
无法获取特定应用的流量消耗
无法获取特定应用的流量消耗,只能给我们一个总的流量消耗值,这个值对于我们解决问题来说帮助不大。
-
无法获取特定时间段的流量消耗
比如线上某个用户反馈发现昨天 App 的流量消耗过多,这时我们是无法知道用户具体消耗了多少流量的。
4. 三个流量优化方案
4.1 数据缓存
4.1.1 OkHttp 缓存
如果我们仔细跟一下自己项目中的接口,就会发现很多对实时性没有那么高要求的接口,使用缓存不仅可以节约流量,而且能大幅提升数据访问速度。
我们常用的网络库,比如 OkHttp 和 Volley,都有比较好的缓存实践。
而且没做缓存对用户体验也不好,一般的 App 会在打开后显示一个无数据的界面,和展示上一次的数据相比,这个用户体验其实是比较差的。
1. 无网拦截器
下面我们重点看下 OkHttp 的缓存实践,首先定义一个无网拦截器。

然后是给 OkHttpClient 添加拦截器。

添加了无网络拦截器后,当无网络的情况下打开我们的 App 时,也能获取到上一次的数据,也能使用 App,这样就能提升用户体验。
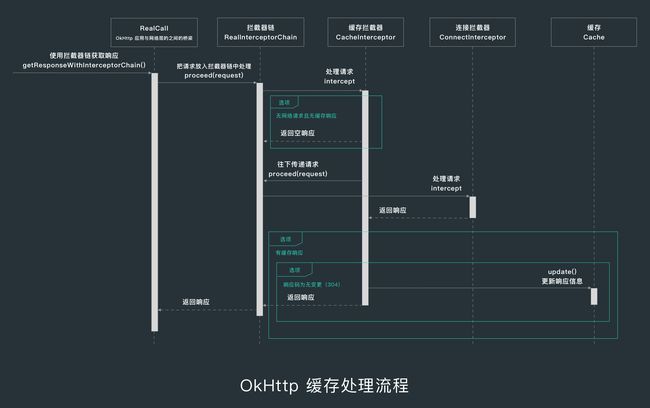
2. OkHttp 缓存处理流程
OkHttp 的缓存拦截器对于请求的处理流程如下。
4.1.2 过期时间与增量更新
1. 过期时间
在服务端返回的数据中加上一个过期时间,这样我们每次请求的时候判断一下有没有过期,如果没有过期就不需要去重新请求。
2. 增量更新
数据增量更新的具体思路,就是在数据中加上一个版本的概念,每次接收数据都进行版本对比,只接收有变化的数据。
这样传输的数据量就会减少很多,比如省市区和配置等数据比较少更新,如果每次都要请求省市区的数据,这就是在浪费流量。
我们只需要更新发生变化的数据,因为和服务器相关比较密切,在这里就不给大家举例了。
4.2 数据压缩
1. Gzip
对于 Post 请求,Body 是用 Gzip 压缩的,也就是请求的时候带上 Gzip 请求头,服务端返回的时候也加上 Gzip 压缩,这样数据流就是被压缩过的。
2. 压缩请求头
请求头也占用一定的体积,在请求头不变的情况下,我们可以只传递一次,以后都只需要传递上一次请求头的 MD5 值,服务端做一个缓存,在需要请求头中的某些信息时,就可以直接从之前的缓存中取。
3. 合并网络请求
每一个网络请求都会有冗余信息,比如请求头,而合并网络请求就可以减少冗余信息的传递;
4.3 图片压缩
1. 缩略图
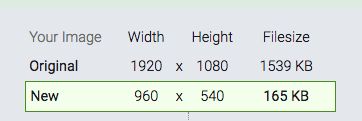
图片压缩的第一个手段,就是在列表中优先使用缩略图,因为展示原图会加大内存消耗和流量消耗,而且在列表中直接展示原图没有意义。
下面是原图和缩略图的对比大小,缩略图尺寸为原图的 50%,大小为原图的 10%。
2. WebP
图片压缩的第二个手段,就是使用 Webp 格式,下面是同一张图片在 PNG 格式和 WebP 格式下的对比,WebP 格式的大小为 PNG 格式的 51%。
3. Luban
比如我们在上传图片的时候,做一个压缩比如在本地是一个 2M 的图片,完整地上传上去意义不大,只会增加我们的流量消耗,最好是压缩后再上传。
而在图片压缩上做得比较好的就是鲁班,下面我们来看下鲁班的使用方法。
首先添加依赖。
dependencies {
// 图片压缩
implementation 'top.zibin:Luban:1.1.8'
}
然后添加对图片进行压缩。
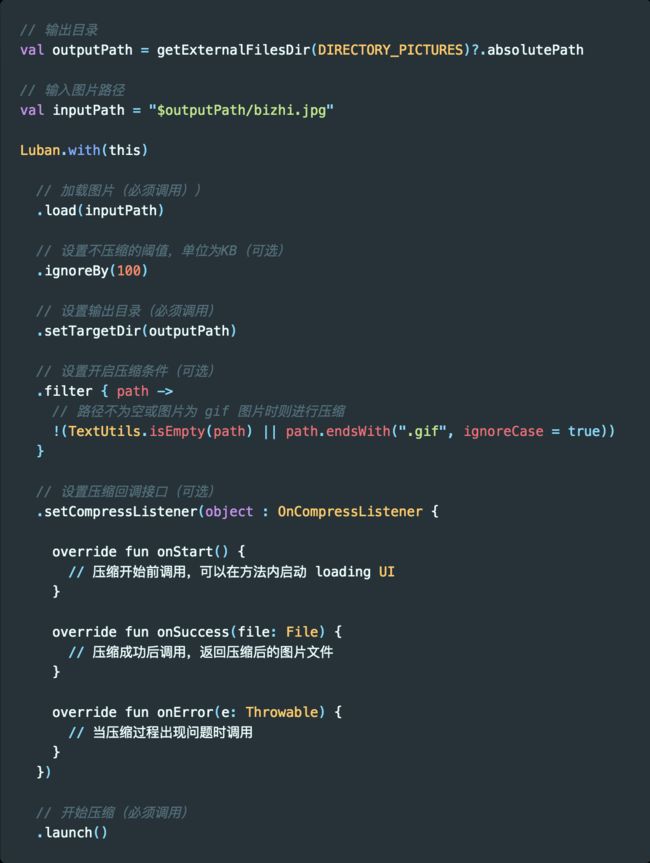
下面这张图片的原始大小为 1.6M,压缩后变成了 213KB,体积为原始大小的 13%。
5. 网络请求质量优化
在前面我们学习了网络请求流量优化,但是实际上,对用户体验破坏最大的是网络请求质量差,很多同学忽略了这点。
因为我们一般在开发或测试阶段,都是在公司用 WiFi 测试,网络质量比较好,假设我们的 App 在流量消耗上问题不大,但是用户经常反馈界面打不开、打开慢、图片加载不出来等问题。
这时用户很有可能会卸载我们的 App ,转向竞品,只有在网络请求质量高,用户体验好,继续使用我们的 App 时,用户才有可能遇到流量消耗的问题,所以网络质量优化比流量优化更关键。
网络质量优化的两个指标:
- 网络请求成功率
- 网络请求速度
这两个指标都会影响用户体验,在介绍网络请求质量优化前,我们先来看下一个 Http 请求的过程。
-
发出请求
客户端发出一个请求,这个请求到达运营商的 DNS 服务器,然后被解析成对应的 IP 地址;
-
创建连接
第二步就是创建连接,会走 TCP 三次握手,然后根据 IP 地址找对对应的服务器,发送一个请求;
-
返回资源
服务器找到对应的资源,然后原路返回给客户端;
5.1 HttpDNS
首先来看怎么在发出请求这一步上优化,网络请求成功率与速度一上来就受 DNS 服务器的影响,如果我们的 DNS 解析到 IP 地址的过程被劫持或 DNS 解析慢,都会严重影响用户体验。
DNS 被劫持的结果就是用户得到的数据并不是我们真实想要提供给用户的数据,如果 DNS 解析慢,那用户等待的请求时间就会变长。
所以 DNS 优化是网络质量优化的第一步,我们使用 HttpDNS,绕过运营商域名解析过程,HttpDNS 不是使用传统的 DNS 协议,向 DNS 服务器的 53 端口发送请求,而是使用 Http 协议,向服务器的 80 端口发送请求。
这样做的好处有两个:
-
防劫持
降低 Local DNS 劫持,绕过运营商域名解析过程;
-
提升速度
降低平均访问时长,因为节省了一次解析过程;
腾讯云和阿里云都提供了 HttpDNS 服务,具体的实现可能看他们的官方文档。
5.2 Http 协议版本优化
刚刚说到了网络请求的第二步是创建连接,当中涉及 TCP 三次握手,这个过程是比较长的,如果每次请求都要走三次握手,那这个效率是比较低的。
所以 Http 的不同版本对这点的优化也非常多,下面是 Http 协议不同版本之间的主要区别。
-
Http 1.0
较老的版本,现在已经很少见到用这个版本的服务了,它最大的缺点就是 TCP 连接不复用,每个 TCP 连接只能发送 1 个请求,如果要请求别的资源,就必须重新建立一个连接。
TCP 创建连接的成本非常高,需要三次握手,并且在开始阶段发送速度比较慢,也就是 Http 1.0 的性能非常差。
-
Http 1.1
Http 1.1 的出现只比 1.0 晚了半年,它最大的变化就是引入了持久连接,从这个版本开始,是默认不关闭的,可以被多个网络请求复用,这样效率就有了很大的提升。
它还是有些缺陷,就是它虽然允许 TCP 复用,但是同一个 TCP 连接里面的所有数据通讯必须按顺序来,也就是处理完一个请求后,再响应下一个请求。
如果前面的网络请求比较慢,那后面的请求也只能等着。
-
Http 2.0
Http 2.0 是一个二进制协议,它最大的改进就是客户端和服务端可以同时发送多个请求和响应,不需要像 Http 1.1 一样按顺序请求,是一个双向的实时通信。
这点是 Http 2.0 相对于 Http 1.1 的最大的改进,大家以后要跟服务端配合时,有得选的前提下,尽可能选择高版本的 Http 协议。
5.3 资本优化
最后一个优化方案就是砸钱,常见的手段有 CDN 加速、提高带宽、动静资源分离。
大家需要注意,使用 CDN 后,如果某个资源需要更新,更新完成后是需要清理缓存的,这些优化不涉及客户端,同时也不要忘了减少传输量,注意请求的时机和频率,这一条和我们前面讲到的流量优化相关。
参考资料
- Top团队大牛带你玩转Android性能分析与优化
- macOS Charles 4.x版本的安装及使用
- Setting up Charles to Proxy your Android Device
- 网络安全配置
- Charles网络设置
- Stetho
- Android应用流量统计——NetworkStatsManager使用
- AppOpsManager权限检测适配
- Android中的uid
- Glide 4.X 使用自定义okhttp 加载图片(忽略https验证)
- ProcessLifecycleOwner判断Android应用程序前后台切换
- NetworkStatsCollection