Spark基础
Spark 的组件
Spark Core
包括Spark的基本功能,包含任务调度,内存管理,容错机制。
内部定义了RDDs(弹性分布式数据集)。
提供了很多APIs来创建和操作这些RDDs。
为其它场景提供了底层的服务
Spark SQL:
是Spark处理结构化数据的库,就像Hive SQL,Mysql一样。
应用场景,企业中用来做报表统计
Spark Streaming:
是实时数据流处理组件,类似Storm
Spark Streaming提供了API来操作实时流数据
应用场景,企业中用来从Kafka接收数据做实时统计
MLlib:
一个包含通用机器学习功能的包,Machine learning lib。
包含分类,聚类,回归等,还包括模型评估,和数据导入
MLlib提供的上面这些方法,都支持集群上的横向拓展。
应用场景:机器学习
GraphX
是处理图的库(例如社交网络图),并进行图的并行计算。
像Spark Streaming,Spark SQL一样,它也继承了RDD API。
它提供了各种图的操作,和常用的图算法,例如PangeRank算法。
Cluster Managers:
就是集群管理,Spark自带一个集群管理是单独调度器。
常见集群管理包括Hadoop YARN,Apache Mesos
紧密继承的优点:
Spark底层优化了,给予Spark底层的组件,也得到了相应的优化。
紧密继承,节省了各个组件组合使用时的部署,测试等时间。
向Spark增加新的组件时,其它组件,可立刻享用新组件的功能。
这些RDDs,并行的分布在整个集群中。
RDDs是Spark分发数据和计算的基础抽象类
scala>val lines = sc.textFile("/home/maixia/soft/helloSpark.txt")
scala>lines.count()//能够统计出helloSpark.txt的行数
res0:Long = 3
一个RDD代表着一个不可改变的分布式集合对象
Spark中,所有的计算都是通过RDDs的创建,转换,操作完成的。
一个RDD内部由许多partitions(分片)组成
分片:每个分片包括一部分数据,partitions可在集群不同节点上计算
分片是Spark并行处理的单元,Spark顺序地,并行地处理分片
RDDs的创建方法:
(1)把一个存在的集合传给SparkContext的parallelize()方法,测试用
val rdd = sc.parallelize(Array(1,2,2,4),4)
第1个参数:待并行化处理的集合,第2个参数:分区个数
(2)加载外部数据集
val rddText = sc.textFile("helloSpark.txt")
spark程序示例(wordCount)
rdd可支持distinct、union(并集)、intersection(交集)、subtract(差集)等操作
rdd.distinct()
rdd1.union(rdd2)
rdd1.intersection(rdd2)
rdd1.subtract(rdd2) //rdd1有而rdd2没有的。
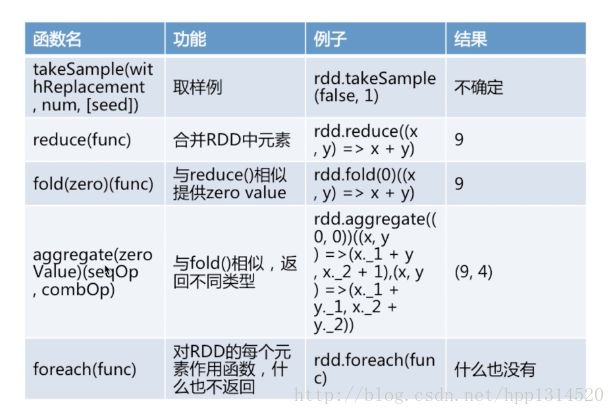
rdd几个常用的Action
图截自慕课网:https://www.imooc.com/video/14399
1、RDDs的血统关系
图截自慕课网:https://www.imooc.com/video/14399
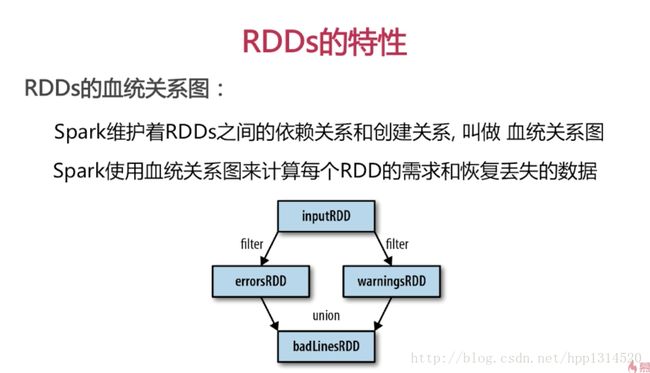
2、延迟计算
Spark对RDDs的计算是,他们第一次使用action操作的时候,这种方式在处理大数据的时候特别有用,可以减少数据的传输
Spark内部记录metadata表名transformations操作已经被响应了
加载数据也是延迟计算,数据只有在必要的时候才会被加载进去
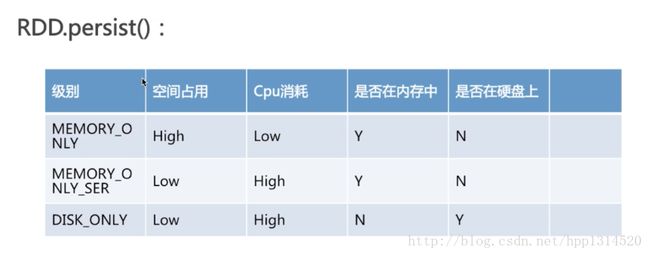
3、RDD.persist():
持久化。默认每次在RDDs上面进行action操作时,Spark都重新计算RDDs,如果想重复利用一个RDD,可以使用RDD.persist()
unpersist()方法从缓存中移除
例子-persist()
图截自慕课网:https://www.imooc.com/video/14399
(createCombiner(),mergeValue(),mergeCombiners,partitioner)
最常用的基于key的聚合函数,返回的类型可以与输入类型不一样
许多基于key的聚合函数都用到了它,像groupByKey()
如果是新元素,使用我们提供的createCombiner()函数
如果是这个partition中已存在的key,就会使用mergeValue()函数
合计每个partition的结果的时候,使用mergeCombiners()函数
combineByKey():
例子,求平均值
Spark Core
包括Spark的基本功能,包含任务调度,内存管理,容错机制。
内部定义了RDDs(弹性分布式数据集)。
提供了很多APIs来创建和操作这些RDDs。
为其它场景提供了底层的服务
Spark SQL:
是Spark处理结构化数据的库,就像Hive SQL,Mysql一样。
应用场景,企业中用来做报表统计
Spark Streaming:
是实时数据流处理组件,类似Storm
Spark Streaming提供了API来操作实时流数据
应用场景,企业中用来从Kafka接收数据做实时统计
MLlib:
一个包含通用机器学习功能的包,Machine learning lib。
包含分类,聚类,回归等,还包括模型评估,和数据导入
MLlib提供的上面这些方法,都支持集群上的横向拓展。
应用场景:机器学习
GraphX
是处理图的库(例如社交网络图),并进行图的并行计算。
像Spark Streaming,Spark SQL一样,它也继承了RDD API。
它提供了各种图的操作,和常用的图算法,例如PangeRank算法。
Cluster Managers:
就是集群管理,Spark自带一个集群管理是单独调度器。
常见集群管理包括Hadoop YARN,Apache Mesos
紧密继承的优点:
Spark底层优化了,给予Spark底层的组件,也得到了相应的优化。
紧密继承,节省了各个组件组合使用时的部署,测试等时间。
向Spark增加新的组件时,其它组件,可立刻享用新组件的功能。
RDDs介绍
RDDs:Resilient distributed datasets(弹性分布式数据集,简写RDDs)这些RDDs,并行的分布在整个集群中。
RDDs是Spark分发数据和计算的基础抽象类
scala>val lines = sc.textFile("/home/maixia/soft/helloSpark.txt")
scala>lines.count()//能够统计出helloSpark.txt的行数
res0:Long = 3
一个RDD代表着一个不可改变的分布式集合对象
Spark中,所有的计算都是通过RDDs的创建,转换,操作完成的。
一个RDD内部由许多partitions(分片)组成
分片:每个分片包括一部分数据,partitions可在集群不同节点上计算
分片是Spark并行处理的单元,Spark顺序地,并行地处理分片
RDDs的创建方法:
(1)把一个存在的集合传给SparkContext的parallelize()方法,测试用
val rdd = sc.parallelize(Array(1,2,2,4),4)
第1个参数:待并行化处理的集合,第2个参数:分区个数
scala>val rdd = sc.parallelize(Array(1,2,2,4),4)
scala>rdd.count()
res0:Long = 4
scala>rdd.foreach(print)
1224
scala>rdd.foreach(println)
2
1
2
4
scala>rdd.foreach(println)
1
2
2
4(2)加载外部数据集
val rddText = sc.textFile("helloSpark.txt")
spark程序示例(wordCount)
object WordCount{
def main(args:Array[String]){
val conf = new SparkConf().setAppName("wordCount")
val sc = new SparkContext(conf)
val input = sc.textFile("/home/maixia/soft/helloSpark.txt")
val lines = input.flatMap(line=>line.split(" "))
val count = lines.map(word=>(word,1)).reduceByKey{case (x,y)=>x+y}
val output = count.saveAsTextFile("/home/maixia/soft/helloSparkRes")
}
}rdd可支持distinct、union(并集)、intersection(交集)、subtract(差集)等操作
rdd.distinct()
rdd1.union(rdd2)
rdd1.intersection(rdd2)
rdd1.subtract(rdd2) //rdd1有而rdd2没有的。
rdd几个常用的Action
图截自慕课网:https://www.imooc.com/video/14399

1、RDDs的血统关系
图截自慕课网:https://www.imooc.com/video/14399
2、延迟计算
Spark对RDDs的计算是,他们第一次使用action操作的时候,这种方式在处理大数据的时候特别有用,可以减少数据的传输
Spark内部记录metadata表名transformations操作已经被响应了
加载数据也是延迟计算,数据只有在必要的时候才会被加载进去
3、RDD.persist():
持久化。默认每次在RDDs上面进行action操作时,Spark都重新计算RDDs,如果想重复利用一个RDD,可以使用RDD.persist()
unpersist()方法从缓存中移除
例子-persist()
图截自慕课网:https://www.imooc.com/video/14399
KeyValue对RDD的Transformations(example:{(1,2),(3,4),(3,6)})


KeyValue对RDDs
combineByKey():(createCombiner(),mergeValue(),mergeCombiners,partitioner)
最常用的基于key的聚合函数,返回的类型可以与输入类型不一样
许多基于key的聚合函数都用到了它,像groupByKey()
常见的RDD API
http://blog.csdn.net/jewes/article/details/39896301
遍历partition中的元素,元素的key,要么之前见过的,要么不是。如果是新元素,使用我们提供的createCombiner()函数
如果是这个partition中已存在的key,就会使用mergeValue()函数
合计每个partition的结果的时候,使用mergeCombiners()函数
combineByKey():
例子,求平均值
scala>scores.foreach(println)
(jake,80.0)
(jake,90.0)
(jake,85.0)
(mike,85.0)
(mike,92.0)
(mike,90.0)
scala>val score2 = scores.combineByKey(
score=>(1,score),
(c1:(Int,Double),newScore)=>(c1._1+1,c1._2+newScore),
(c1:(Int,Double),c2:(Int,Double))=>(c1._1+c2._1),c1._2 + c2._2)
)
scala>score2.foreach(println)
(jake,(3,255.0))
(mike,(3,267.0))
scala>val average = scores2.map{case(name,(num,score))=>(name,score/num)}
scala>average.foreach(println)
(mike,89.0)
(jake,85.0)