RocketMQ学习(三)——底层存储设计
MQ消息队列的一般存储方式
当前业界几款主流的MQ消息队列采用的存储方式主要有以下三种方式:
(1)分布式KV存储: 这类MQ一般会采用诸如levelDB、RocksDB和Redis来作为消息持久化的方式,由于分布式缓存的读写能力要优于DB,所以在对消息的读写能力要求都不是比较高的情况下,采用这种方式倒也不失为一种可以替代的设计方案。消息存储于分布式KV需要解决的问题在于如何保证MQ整体的可靠性?
(2)文件系统: 目前业界较为常用的几款产品(RocketMQ/Kafka/RabbitMQ)均采用的是消息刷盘至所部署虚拟机/物理机的文件系统来做持久化(刷盘一般可以分为异步刷盘和同步刷盘两种模式)。消息刷盘为消息存储提供了一种高效率、高可靠性和高性能的数据持久化方式。除非部署MQ机器本身或是本地磁盘挂了,否则一般是不会出现无法持久化的故障问题。
(3)关系型数据库DB: Apache下开源的另外一款MQ—ActiveMQ(默认采用的KahaDB做消息存储)可选用JDBC的方式来做消息持久化,通过简单的xml配置信息即可实现JDBC消息存储。由于,普通关系型数据库(如Mysql)在单表数据量达到千万级别的情况下,其IO读写性能往往会出现瓶颈。因此,如果要选型或者自研一款性能强劲、吞吐量大、消息堆积能力突出的MQ消息队列,并不推荐采用关系型数据库作为消息持久化的方案。在可靠性方面,该种方案非常依赖DB,如果一旦DB出现故障,则MQ的消息就无法落盘存储会导致线上故障;
因此,综合上所述从存储效率来说, 文件系统>分布式KV存储>关系型数据库DB,直接操作文件系统肯定是最快和最高效的,而关系型数据库TPS一般相比于分布式KV系统会更低一些(简略地说,关系型数据库本身也是一个需要读写文件server,这时MQ作为client与其建立连接并发送待持久化的消息数据,同时又需要依赖DB的事务等,这一系列操作都比较消耗性能),所以如果追求高效的IO读写,那么选择操作文件系统会更加合适一些。但是如果从易于实现和快速集成来看,关系型数据库DB>分布式KV存储>文件系统,但是性能会下降很多。
另外,从消息中间件的本身定义来考虑,应该尽量减少对于外部第三方中间件的依赖。一般来说依赖的外部系统越多,也会使得本身的设计越复杂,所以个人的理解是采用文件系统作为消息存储的方式,更贴近消息中间件本身的定义。
RocketMQ存储相关的模型与封装类简析
(1)CommitLog
消息主体以及元数据的存储主体,存储Producer端写入的消息主体内容。单个文件大小默认1G ,文件名长度为20位,左边补零,剩余为起始偏移量,比如00000000000000000000代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当第一个文件写满了,第二个文件为00000000001073741824,起始偏移量为1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件;
(2) ConsumeQueue
消息消费的逻辑队列,其中包含了这个MessageQueue在CommitLog中的起始物理位置偏移量offset,消息实体内容的大小和Message Tag的哈希值。从实际物理存储来说,ConsumeQueue对应每个Topic和QueuId下面的文件。单个文件大小约5.72M,每个文件由30W条数据组成,每个文件默认大小为600万个字节,当一个ConsumeQueue类型的文件写满了,则写入下一个文件;
(3)IndexFile
用于为生成的索引文件提供访问服务,通过消息Key值查询消息真正的实体内容。在实际的物理存储上,文件名则是以创建时的时间戳命名的,固定的单个IndexFile文件大小约为400M,一个IndexFile可以保存 2000W个索引;
(4)MapedFileQueue
对连续物理存储的抽象封装类,源码中可以通过消息存储的物理偏移量位置快速定位该offset所在MappedFile(具体物理存储位置的抽象)、创建、删除MappedFile等操作;
(5)MappedFile
文件存储的直接内存映射业务抽象封装类,源码中通过操作该类,可以把消息字节写入PageCache缓存区(commit),或者原子性地将消息持久化的刷盘(flush);
RocketMQ消息存储整体架构
假如集群有一个Broker,Topic为binlog的队列(Consume Queue)数量为4,如下图所示,按顺序发送这5条消息。Consumer端线程采用的是负载订阅的方式进行消费。

先关注下Commit Log和Consume Queue。
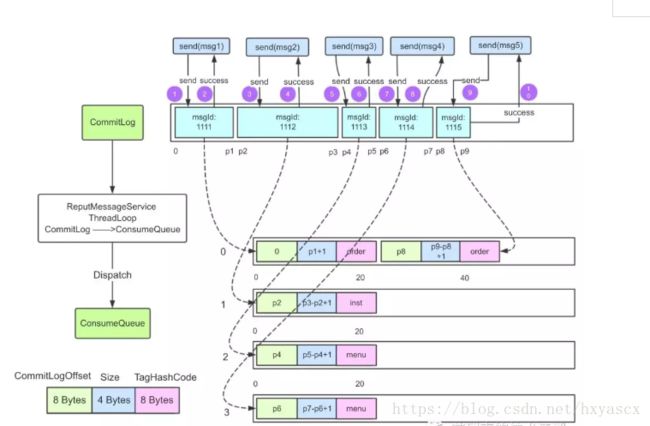
RMQ的消息整体是有序的,所以这5条消息按顺序将内容持久化在Commit Log中。Consume Queue则是用于将消息均衡地按序排列在不同的逻辑队列,集群模式下多个消费者就可以并行消费Consume Queue的消息。
从图中可以总结出如下几个关键点:
(1)消息生产与消息消费相互分离
Producer端发送消息最终写入的是CommitLog(消息存储的日志数据文件),Consumer端先从ConsumeQueue(消息逻辑队列)读取持久化消息的起始物理位置偏移量offset、大小size和消息Tag的HashCode值,随后再从CommitLog中进行读取待拉取消费消息的真正实体内容部分;而IndexFile(索引文件)则只是为了消息查询提供了一种通过key或时间区间来查询消息的方法(ps:这种通过IndexFile来查找消息的方法不影响发送与消费消息的主流程)。
(2)RocketMQ的CommitLog文件采用混合型存储
所有的Topic下的消息队列共用同一个CommitLog的日志数据文件,并通过建立类似索引文件—ConsumeQueue的方式来区分不同Topic下面的不同MessageQueue的消息,同时为消费消息起到一定的缓冲作用(只有ReputMessageService异步服务线程通过doDispatch异步生成了ConsumeQueue队列的元素后,Consumer端才能进行消费)。这样,只要消息写入并刷盘至CommitLog文件后,消息就不会丢失,即使ConsumeQueue中的数据丢失,也可以通过CommitLog来恢复。
(3)RocketMQ每次读写文件的时候真的是完全顺序读写么?
这里,发送消息时,生产者端的消息确实是顺序写入CommitLog;订阅消息时,消费者端也是顺序读取ConsumeQueue,然而根据其中的起始物理位置偏移量offset读取消息真实内容却是随机读取CommitLog。 在RocketMQ集群整体的吞吐量、并发量非常高的情况下,随机读取文件带来的性能开销影响还是比较大的,那么这里如何去优化和避免这个问题呢?后面的章节将会逐步来解答这个问题。
这里,同样也可以总结下RocketMQ存储架构的优缺点:
优点:
1、ConsumeQueue消息逻辑队列较为轻量级;
2、对磁盘的访问串行化,避免磁盘竟争,不会因为队列增加导致IOWAIT增高;
缺点:
1、对于CommitLog来说写入消息虽然是顺序写,但是读却变成了完全的随机读;
2、Consumer端订阅消费一条消息,需要先读ConsumeQueue,再读Commit Log,一定程度上增加了开销;
RocketMQ文件存储模型层次结构
RocketMQ文件存储模型层次结构如上图所示,根据类别和作用从概念模型上大致可以划分为5层,下面将从各个层次分别进行分析和阐述:
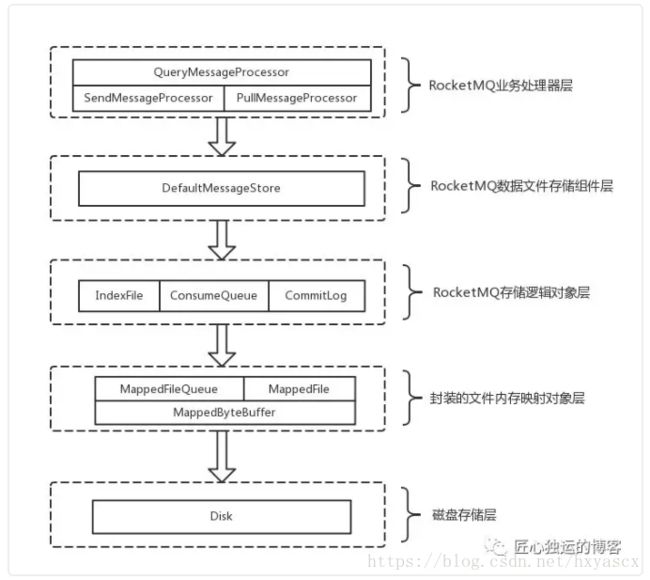
(1)RocketMQ业务处理器层: Broker端对消息进行读取和写入的业务逻辑入口,这一层主要包含了业务逻辑相关处理操作(根据解析RemotingCommand中的RequestCode来区分具体的业务操作类型,进而执行不同的业务处理流程),比如前置的检查和校验步骤、构造MessageExtBrokerInner对象、decode反序列化、构造Response返回对象等;
(2)RocketMQ数据存储组件层: 该层主要是RocketMQ的存储核心类—DefaultMessageStore,其为RocketMQ消息数据文件的访问入口,通过该类的“putMessage()”和“getMessage()”方法完成对CommitLog消息存储的日志数据文件进行读写操作(具体的读写访问操作还是依赖下一层中CommitLog对象模型提供的方法);另外,在该组件初始化时候,还会启动很多存储相关的后台服务线程,包括AllocateMappedFileService(MappedFile预分配服务线程)、ReputMessageService(回放存储消息服务线程)、HAService(Broker主从同步高可用服务线程)、StoreStatsService(消息存储统计服务线程)、IndexService(索引文件服务线程)等;
(3)RocketMQ存储逻辑对象层: 该层主要包含了RocketMQ数据文件存储直接相关的三个模型类IndexFile、ConsumerQueue和CommitLog。IndexFile为索引数据文件提供访问服务,ConsumerQueue为逻辑消息队列提供访问服务,CommitLog则为消息存储的日志数据文件提供访问服务。这三个模型类也是构成了RocketMQ存储层的整体结构(对于这三个模型类的深入分析将放在后续篇幅中);
(4)封装的文件内存映射层: RocketMQ主要采用JDK NIO中的MappedByteBuffer和FileChannel两种方式完成数据文件的读写。其中,采用MappedByteBuffer这种内存映射磁盘文件的方式完成对大文件的读写,在RocketMQ中将该类封装成MappedFile类。这里限制的问题在上面已经讲过;对于每类大文件(IndexFile/ConsumerQueue/CommitLog),在存储时分隔成多个固定大小的文件(单个IndexFile文件大小约为400M、单个ConsumerQueue文件大小约5.72M、单个CommitLog文件大小为1G),其中每个分隔文件的文件名为前面所有文件的字节大小数+1,即为文件的起始偏移量,从而实现了整个大文件的串联。这里,每一种类的单个文件均由MappedFile类提供读写操作服务(其中,MappedFile类提供了顺序写/随机读、内存数据刷盘、内存清理等和文件相关的服务);
(5)磁盘存储层: 主要指的是部署RocketMQ服务器所用的磁盘。这里,需要考虑不同磁盘类型(如SSD或者普通的HDD)特性以及磁盘的性能参数(如IOPS、吞吐量和访问时延等指标)对顺序写/随机读操作带来的影响(ps:小编建议在正式业务上线之前做好多轮的性能压测,具体用压测的结果来评测);
RocketMQ存储关键技术—Mmap与PageCache
Mmap内存映射技术—MappedByteBuffer
(1)Mmap内存映射技术的特点
Mmap内存映射和普通标准IO操作的本质区别在于它并不需要将文件中的数据先拷贝至OS的内核IO缓冲区,而是可以直接将用户进程私有地址空间中的一块区域与文件对象建立映射关系,这样程序就好像可以直接从内存中完成对文件读/写操作一样。只有当缺页中断发生时,直接将文件从磁盘拷贝至用户态的进程空间内,只进行了一次数据拷贝。对于容量较大的文件来说(文件大小一般需要限制在1.5~2G以下,这也是CommitLog设置成1G的原因),采用Mmap的方式其读/写的效率和性能都非常高。
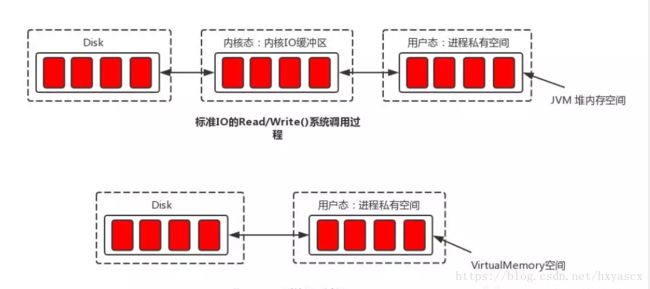
(2)JDK NIO的MappedByteBuffer简要分析
从JDK的源码来看,MappedByteBuffer继承自ByteBuffer,其内部维护了一个逻辑地址变量—address。在建立映射关系时,MappedByteBuffer利用了JDK NIO的FileChannel类提供的map()方法把文件对象映射到虚拟内存。仔细看源码中map()方法的实现,可以发现最终其通过调用native方法map0()完成文件对象的映射工作,同时使用Util.newMappedByteBuffer()方法初始化MappedByteBuffer实例,但最终返回的是DirectByteBuffer的实例。在Java程序中使用MappedByteBuffer的get()方法来获取内存数据是最终通过DirectByteBuffer.get()方法实现(底层通过unsafe.getByte()方法,以“地址 + 偏移量”的方式获取指定映射至内存中的数据)。
(3)使用Mmap的限制
Mmap映射的内存空间释放的问题
由于映射的内存空间本身就不属于JVM的堆内存区(Java Heap),因此其不受JVM GC的控制,卸载这部分内存空间需要通过系统调用 unmap()方法来实现。然而unmap()方法是FileChannelImpl类里实现的私有方法,无法直接显示调用。RocketMQ中的做法是,通过Java反射的方式调用“sun.misc”包下的Cleaner类的clean()方法来释放映射占用的内存空间;
MappedByteBuffer内存映射大小限制
因为其占用的是虚拟内存(非JVM的堆内存),大小不受JVM的-Xmx参数限制,但其大小也受到OS虚拟内存大小的限制。一般来说,一次只能映射1.5~2G 的文件至用户态的虚拟内存空间,这也是为何RocketMQ默认设置单个CommitLog日志数据文件为1G的原因了;
使用MappedByteBuffe的其他问题
会存在内存占用率较高和文件关闭不确定性的问题;
OS的PageCache机制
PageCache是OS对文件的缓存,用于加速对文件的读写。一般来说,程序对文件进行顺序读写的速度几乎接近于内存的读写访问,这里的主要原因就是在于OS使用PageCache机制对读写访问操作进行了性能优化,将一部分的内存用作PageCache。
(1)对于数据文件的读取
如果一次读取文件时出现未命中PageCache的情况,OS从物理磁盘上访问读取文件的同时,会顺序对其他相邻块的数据文件进行预读取(ps:顺序读入紧随其后的少数几个页面)。这样,只要下次访问的文件已经被加载至PageCache时,读取操作的速度基本等于访问内存。
(2)对于数据文件的写入
OS会先写入至Cache内,随后通过异步的方式由pdflush内核线程将Cache内的数据刷盘至物理磁盘上。
对于文件的顺序读写操作来说,读和写的区域都在OS的PageCache内,此时读写性能接近于内存。RocketMQ的大致做法是,将数据文件映射到OS的虚拟内存中(通过JDK NIO的MappedByteBuffer),写消息的时候首先写入PageCache,并通过异步刷盘的方式将消息批量的做持久化(同时也支持同步刷盘);订阅消费消息时(对CommitLog操作是随机读取),由于PageCache的局部性热点原理且整体情况下还是从旧到新的有序读,因此大部分情况下消息还是可以直接从Page Cache中读取,不会产生太多的缺页(Page Fault)中断而从磁盘读取。

PageCache机制也不是完全无缺点的,当遇到OS进行脏页回写,内存回收,内存swap等情况时,就会引起较大的消息读写延迟。
对于这些情况,RocketMQ采用了多种优化技术,比如内存预分配,文件预热,mlock系统调用等,来保证在最大可能地发挥PageCache机制优点的同时,尽可能地减少其缺点带来的消息读写延迟。
RocketMQ存储优化技术
RocketMQ存储层采用的几项优化技术方案在一定程度上可以减少PageCache的缺点带来的影响,主要包括内存预分配,文件预热和mlock系统调用。
预先分配MappedFile
在消息写入过程中(调用CommitLog的putMessage()方法),CommitLog会先从MappedFileQueue队列中获取一个 MappedFile,如果没有就新建一个。
这里,MappedFile的创建过程是将构建好的一个AllocateRequest请求(具体做法是,将下一个文件的路径、下下个文件的路径、文件大小为参数封装为AllocateRequest对象)添加至队列中,后台运行的AllocateMappedFileService服务线程(在Broker启动时,该线程就会创建并运行),会不停地run,只要请求队列里存在请求,就会去执行MappedFile映射文件的创建和预分配工作,分配的时候有两种策略,一种是使用Mmap的方式来构建MappedFile实例,另外一种是从TransientStorePool堆外内存池中获取相应的DirectByteBuffer来构建MappedFile(ps:具体采用哪种策略,也与刷盘的方式有关)。并且,在创建分配完下个MappedFile后,还会将下下个MappedFile预先创建并保存至请求队列中等待下次获取时直接返回。RocketMQ中预分配MappedFile的设计非常巧妙,下次获取时候直接返回就可以不用等待MappedFile创建分配所产生的时间延迟。

文件预热&&mlock系统调用
(1)mlock系统调用
其可以将进程使用的部分或者全部的地址空间锁定在物理内存中,防止其被交换到swap空间。对于RocketMQ这种的高吞吐量的分布式消息队列来说,追求的是消息读写低延迟,那么肯定希望尽可能地多使用物理内存,提高数据读写访问的操作效率。
(2)文件预热
预热的目的主要有两点;第一点,由于仅分配内存并进行mlock系统调用后并不会为程序完全锁定这些内存,因为其中的分页可能是写时复制的。因此,就有必要对每个内存页面中写入一个假的值。其中,RocketMQ是在创建并分配MappedFile的过程中,预先写入一些随机值至Mmap映射出的内存空间里。第二,调用Mmap进行内存映射后,OS只是建立虚拟内存地址至物理地址的映射表,而实际并没有加载任何文件至内存中。程序要访问数据时OS会检查该部分的分页是否已经在内存中,如果不在,则发出一次缺页中断。这里,可以想象下1G的CommitLog需要发生多少次缺页中断,才能使得对应的数据才能完全加载至物理内存中(ps:X86的Linux中一个标准页面大小是4KB)?RocketMQ的做法是,在做Mmap内存映射的同时进行madvise系统调用,目的是使OS做一次内存映射后对应的文件数据尽可能多的预加载至内存中,从而达到内存预热的效果。
RocketMQ消息刷盘的主要过程
在RocketMQ中消息刷盘主要可以分为同步刷盘和异步刷盘两种。

(1)同步刷盘
只有在消息真正持久化至磁盘后,RocketMQ的Broker端才会真正地返回给Producer端一个成功的ACK响应。同步刷盘对MQ消息可靠性来说是一种不错的保障,但是性能上会有较大影响,一般适用于金融业务应用领域。RocketMQ同步刷盘的大致做法是,基于生产者消费者模型,主线程创建刷盘请求实例—GroupCommitRequest并在放入刷盘写队列后唤醒同步刷盘线程—GroupCommitService,来执行刷盘动作(其中用了CAS变量和CountDownLatch来保证线程间的同步)。这里,RocketMQ源码中用读写双缓存队列(requestsWrite/requestsRead)来实现读写分离,其带来的好处在于内部消费生成的同步刷盘请求可以不用加锁,提高并发度。
(2)异步刷盘
能够充分利用OS的PageCache的优势,只要消息写入PageCache即可将成功的ACK返回给Producer端。消息刷盘采用后台异步线程提交的方式进行,降低了读写延迟,提高了MQ的性能和吞吐量。异步和同步刷盘的区别在于,异步刷盘时,主线程并不会阻塞,在将刷盘线程wakeup后,就会继续执行。
同步复制和异步复制
当集群中有master和slave两个角色时,就要涉及到主从复制,同步复制是指在master刷盘后,需要在slave同步成功后才返回。而异步复制是在master刷盘成功后就直接返回。在高可用的角度去考虑,同步复制是不会在突然宕机时,丢失数据的。所以我们在工作中是使用同步复制异步刷盘的。