keepalived+lvs结合nginx压力测试实践
需求
最近做一个kafka的中间件,需求比较简单,就一个需求:支持的吞吐量为5WQps。
尝试
- 接口内容比较简单:根据topic,key,value发送到kafka一条数据。把代码撸好-单元测试-部署-单节点压测,然后使用比较熟悉的jmeter在本地测试。
- 问题一:此时就出现了第一个问题,无论开多少个线程并发去访问,Qps大概也就2000左右,嗯哼?!这完全不符合心理预期啊,一个异步发送kafka的接口就这点能力?不可能啊,瓶颈难道是kafka生产者 producer参数配置不对?
- 问题二:压测总条数达到5W条左右时,就会出现如下异常:
org.apache.kafka.common.errors.TimeoutException: Expiring 1 record(s) for t2-0: 30042 ms has passed since batch creation plus linger time
针对问题二,增大了request.timeout.ms配置,默认是30s,我修改成了60s。( kafka配置参考) 折腾了大半天,发现是网络的瓶颈,
本地到服务器使用的是连接,带宽大概10Mbyte左右,这样就导致了发送队列的积累,最终导致部分数据发送超时!同时联想到问题一是同一个原因导致的。于是更换压力发起端到线上,jmeter换成比较有名的ab。
- 问题三:ab测试开启500个线程,吞吐量大约可以到达1WQps了,有点开心了,但继续往上压效果并不显著,并发达到1000多的时候ab就会报错:
apr_socket_recv: Connection reset by peer (104)
修改linux内核配置:
参考文件:1.参数含义 2. linux内核调优
kernel.panic=60
net.ipv4.ip_local_port_range=1024 65535
#net.ipv4.ip_local_reserved_ports=3306,4369,4444,4567,4568,5000,5001,5672,5900-6200,6789,6800-7100,8000,8004,8773-8777,8080,8090,9000,9191,9393,9292,9696,9898,15672,16509,25672,27017-27021,35357,49000,50000-59999
net.core.netdev_max_backlog=261144
net.ipv4.conf.default.arp_accept=1
net.ipv4.conf.all.arp_accept=1
net.ipv4.neigh.default.gc_thresh1=10240
net.ipv4.neigh.default.gc_thresh2=20480
net.ipv4.neigh.default.gc_thresh3=40960
net.ipv4.neigh.default.gc_stale_time=604800
net.ipv4.ip_forward=1
net.ipv4.conf.all.rp_filter=0
net.ipv4.conf.default.rp_filter=0
net.nf_conntrack_max=1048576
net.netfilter.nf_conntrack_tcp_timeout_established=900
net.ipv4.tcp_retries2=5
net.core.somaxconn=65535
net.core.rmem_max=16777216
net.core.wmem_max=16777216
net.ipv4.tcp_rmem=4096 87380 16777216
net.ipv4.tcp_wmem=4096 65536 16777216
net.ipv4.tcp_keepalive_intvl=3
net.ipv4.tcp_keepalive_time=20
net.ipv4.tcp_keepalive_probes=5
net.ipv4.tcp_fin_timeout=15
# 是指定所能接受SYN同步包的最大客户端数量
net.ipv4.tcp_max_syn_backlog=8192
# 表示是否打开TCP同步标签(syncookie),内核必须打开了CONFIG_SYN_COOKIES项进行编译,同步标签可以防止一个套接字在有过多试图连接到达时引起过载。
net.ipv4.tcp_syncookies = 1
# 表示是否允许将处于TIME-WAIT状态的socket(TIME-WAIT的端口)用于新的TCP连接 。
net.ipv4.tcp_tw_reuse = 1
# 能够更快地回收TIME-WAIT套接字。
net.ipv4.tcp_tw_recycle = 1
net.ipv4.ip_nonlocal_bind=1
# 最大打开文件句柄
fs.file-max=655350
vm.swappiness=0
net.unix.max_dgram_qlen=128
- 问题四:内核调优后单个kafka服务平均处理2Wqps请求,偶尔可以达到3W+,好像很接近结果了。。开始考虑横向扩展,引入nginx做负载均衡。nginx应用总结(2)–突破高并发的性能优化;做了一系列的优化,发现平均吞吐量还是2Wqps+,没有显著的增长。翻阅书籍和资料介绍说nginx采用的是七层负载均衡,效率低,最高支持4Wqps+。可以参考四层、七层负载均衡的区别;此外nginx也支持了四层负载,感兴趣的自己查阅一下资料。由于lvs比较成熟了(资料多),此时暂时选型lvs作为负载均衡软件。
- 问题五: LVS搭建不成功,一开始是原理不理解,后来是对keepalived配置文件的不理解。后来在度娘和同事的帮助下成功搭建了LVS-DR模式。
参考LVS安装使用详解和keepalived配置详解
keepalived+LVS配置:(忽略了其他的配置)
virtual_server 192.168.17.176 86 {
delay_loop 1 #探测的时间间隔
lb_algo rr #轮询调度
lb_kind DR #MAC路由模式
persistence_timeout 0 #一定时间内对于同一IP的请求调度到同一Server上
protocol TCP #TCP协议
real_server 192.168.17.57 86 { #定义后端服务器
weight 1 #权重
inhibit_on_failure #当服务器健康检查失败时,将其weight设置为0,而不是从Virtual Server中移除。
HTTP_GET {
url {
path /kafka/check # 指定要检查的URL的路径。如path / or path /mrtg2
#digest # 摘要。计算方式:genhash -s 172.17.100.1 -p 80 -u /index.html
status_code 200 # 状态码。
}
connect_timeout 3 #探测超时
nb_get_retry 3 #重试次数
delay_before_retry 3 #重试时间间隔
}
}
real_server 192.168.17.64 86 { #定义后端服务器
weight 1 #权重
inhibit_on_failure
HTTP_GET {
url {
path /kafka/check
status_code 200
}
connect_timeout 3 #探测超时
nb_get_retry 3 #重试次数
delay_before_retry 3 #重试时间间隔
}
}
real_server 192.168.17.65 86 { #定义后端服务器
weight 1 #权重
inhibit_on_failure
HTTP_GET {
url {
path /kafka/check
status_code 200
}
connect_timeout 3 #探测超时
nb_get_retry 3 #重试次数
delay_before_retry 3 #重试时间间隔
}
}
}
real_server中需要执行的命令:
# ip addr add 192.168.17.176/32 dev lo
# echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
# echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
# echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
# echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce
- 问题六:LVS四层协议只转发ip或者说修改目标mac地址,即所有kafka服务端口号需要一致!公司资源紧张,只有几台服务器可以使用,怎么办,于是想到用nginx再做一层代理,于是就产生了下面的架构:
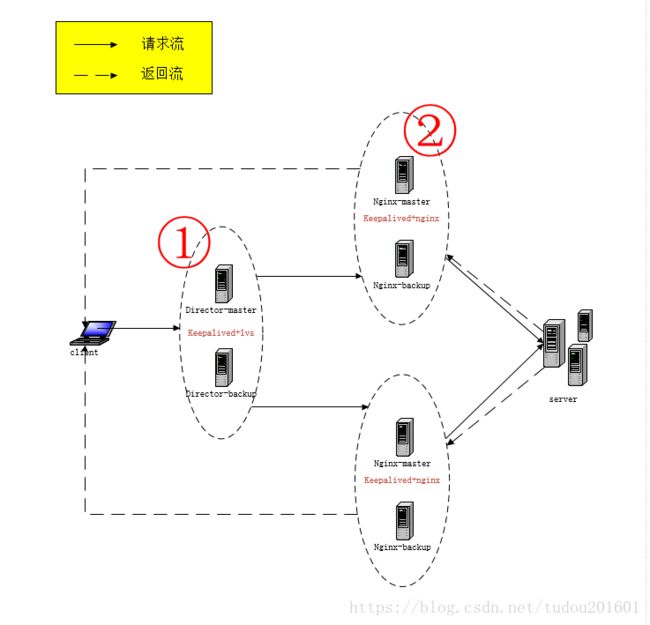
测试结果
部署模式:
- keepalived+lvs*2, 主备
- keepalive+nginx2,主备,单节点nginx1
- server62,server部署了六台机器每台机器部署两个server节点,每个nginx代理4个serve
- 压力测试:三台测试机器同时使用ab进行压力测试:
- 短期测试,总吞吐量最高达到8Wqps
- 长期压测,每台机器的吐吞量可达到1.5Wqps,总吐吞量4.5W
- 破坏测试: 使用这种架构进行破坏性测试的结果:(总请求数20000个,请求线程数1个)
- 暂停①中master的keepalived,请求失败个数为0
- 暂停②中master的keepalived,请求失败个数为0
- 暂停②中master的nginx请求失败个数1000-2000个
- 暂停②中无keepalived的nginx请求失败个数1000-2000个
- 暂停某个server节点,请求失败个数为4-20个
结论和存在的问题
由于测试过程中其他人员也在使用机器,最终架构的测试过程中并没有对一些资源做瓶颈分析,后续的资源来了还会再做几轮测试。主要是从结果中已经能看到吞吐量横向扩展了。(资料上说LVS是10W级别的,暂时信一信。。)
依然存在的问题:破坏性测试中服务的断开和nginx的断开仍然会影响用户使用,待解决。。未完。。
- nginx优化:添加proxy_next_upstream_tries重试机制,添加check机制,可以根据自己的业务结合使用。优化后,暂停某个server节点,请求失败个数1-2个。
upstream kafka_test {
server 192.168.17.57:8006;
server 192.168.17.57:8007;
server 192.168.17.66:8006;
server 192.168.17.66:8007;
server 192.168.17.64:8006;
server 192.168.17.64:8007;
server 192.168.17.70:8006;
server 192.168.17.70:8007;
server 192.168.17.65:8006;
server 192.168.17.65:8007;
server 192.168.17.71:8006;
server 192.168.17.71:8007;
check interval=1000 rise=1 fall=3 timeout=2000 type=http;
check_http_send "HEAD /kafka/check HTTP/1.0\r\n\r\n";
check_http_expect_alive http_2xx;
#ip_hash;
}
server
{
listen 86;
listen [::]:86 default_server;
server_name 103;
location / {
proxy_next_upstream error timeout http_502;
proxy_next_upstream_timeout 60s;
proxy_next_upstream_tries 3;
proxy_pass http://kafka_test/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
- 关于正在使用中的nginx突然挂掉,如:
- 暂停②中master的nginx请求失败个数1000-2000个
- 暂停②中无keepalived的nginx请求失败个数1000-2000个
方案一:使用keepalived+nginx,配置check脚本,如果发现nginx进程消失,则重新启动,如果启动失败返回非0
方案二:使用keepalived+nginx,配置check脚本,如果发现nginx进程消失,则返回非0
keepalived配置:
! Configuration File for keepalived
global_defs {
router_id hadoop4
}
vrrp_script chk_nginx {
script "/etc/keepalived/scripts/monitor_nginx.sh"
interval 2
weight -10 # 如果返回非0,当前keepalived的权重-10,所以要注意backup的权重值的设置
fall 3
rise 1
}
vrrp_instance VI_113 {
interface ens4f0
state MASTER
virtual_router_id 113
priority 111
advert_int 1
garp_master_delay 1
track_interface {
ens4f0
}
virtual_ipaddress {
192.168.17.191/32 dev ens4f0
}
track_script {
chk_nginx
}
authentication {
auth_type PASS
auth_pass secret
}
}
方案一检测脚本:monitor_nginx.sh
#!/bin/bash
if [ "$(ps -ef | grep "nginx: master process"| grep -v grep )" == "" ]
then
service nginx restart
sleep 5
if [ "$(ps -ef | grep "nginx: master process"| grep -v grep )" == "" ]
then
exit 120
fi
fi
方案二检测脚本:monitor_nginx.sh
#!/bin/bash
if [ "$(ps -ef | grep "nginx: master process"| grep -v grep )" == "" ]
then
exit 120
fi