shell常用脚本
什么是shell?
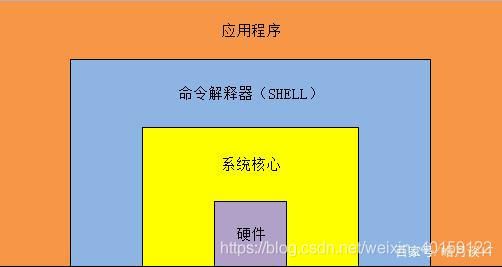
如上图所示:最底下是计算机硬件,然后硬件被系统核心包住,在系统核心外层的就是shell,然后shell外层的就是我们最容易理解的应用程序,我们平时接触最多的就是应用程序了。
看图可知:shell其实是一个命令解释器,它的作用是解释用户输入的命令和程序,命令和程序可以理解成我们途中的应用程序,我们linux中的那些命令其实也都是一个个的小程序,只不过完成的是系统的应用功能。我们在系统的终端输入一条命令,可以马上看到一条或者几条系统回复我们的信息,其实就是shell在帮我们回复,所以shell可以称之为命令解释器。这种从键盘一输入命令就可以立马得到相应的回复信息,叫做交互方式,相当于我们在和电脑进行相互交流,shell存在于系统的最外层,所以算作操作系统的外壳,他之外的应用程序就不能算作操作系统了。我们从输入系统的账户密码开始,到登录系统以后的所有操作都是shell在帮我们解释执行的。
了解了shell之后,我们再来了解下shell脚本,如果我们的命令或者应用程序不在命令行直接执行,而是通过一个程序文件来执行时,这个程序就称之为shell脚本。shell脚本里面通常内置了多条命令,有的还包含控制语句,比如if和else的条件控制语句,for和select的循环控制语句等。这些内置在shell脚本中的命令通常是一次性执行完成,不会不停的返回信息给用户,这种通过文件执行脚本的方式称之为非交互方式。shell脚本类似于windows下的批处理,但是它比批处理要强大一些。现在的win10系统下有一个功能叫做power shell,它可以和linux下的shell功能相媲美。
我们可以在文本中输入一系列的命令、控制语句和变量,这一切有机的结合起来就形成了功能强大的shell脚本。
在linux中我们一般通过vim来创建shell脚本(后缀名为.sh),创建完成以后保存并退出,当我们运行shell脚本的时候需要通过:chmod +x ./shell.sh 命令使得shell脚本具有执行权限,否则shell.sh只是一个文件;在赋予shell脚本执行权限以后通过:./shell.sh 命令即可执行shell脚本。另外,在shell脚本的第一行需要指定解释器的信息如下所示:#!/bin/bash
常用的shell脚本
打印形状:
#!/bin/bash
# 等腰三角形
read -p "Please input the length: " n
for i in `seq 1 $n`
do
for ((j=$n;j>i;j--))
do
echo -n " "
done
for m in `seq 1 $i`
do
echo -n "* "
done
echo
done
# 倒直角三角形
read -p "Please input the length: " len
for i in `seq 1 $len`
do
for j in `seq $i $len`
do
echo -n "* "
done
echo
done
# 菱形
read -p "Please input the length: " n
for i in `seq 1 $n`
do
for ((j=$n;j>i;j--))
do
echo -n " "
done
for m in `seq 1 $i`
do
echo -n "* "
done
echo
done
for i in `seq 1 $n`
do
for((j=1;j<=$i;j++))
do
echo -n " "
done
for((k=$i;k<=$len-1;k++))
do
echo -n "* "
done
echo
done截取字符串
http://www.aaa.com/root/123.htm
请根据以下要求截取出字符串中的字符:
1.取出www.aaa.com/root/123.htm
2.取出123.htm
3.取出http://www.aaa.com/root
4.取出http:
5.取出http://
6.取出www.aaa.com/root/123.htm
7.取出123
8.取出123.htm
#!/bin/bash
var="http://www.aaa.com/root/123.htm"
#1.
echo $var |awk -F '//' '{print $2}'
#2.
echo $var |awk -F '/' '{print $5}'
#3.
echo $var |grep -o 'http.*root'
#4.
echo $var |awk -F '/' '{print $1}'
#5.
echo $var |grep -o 'http://'
#6.
echo $var |grep -o 'www.*htm'
#7.
echo $var |grep -o '123'
#8.
echo $var |grep -o '123.htm'tomcat启动脚本
tomcat没有自带的能够给service开机启动的脚本,该脚本是一个简单的启动的脚本
#!/bin/bash
# chkconfig:2345 64 36
# description: Tomcat start/stop/restart script.
### BEGIN INIT INFO
# Provides: tomcat
# Required-Start:
# Should-Start:
# Required-Stop:
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: start and stop Tomcat
# Description: Tomcat Service start&restart&stop script
### END INIT INFO
##Written by zero.##
JAVA_HOME=/usr/local/jdk1.8/
JAVA_BIN=/usr/local/jdk1.8/bin
JRE_HOME=/usr/local/jdk1.8/jre
PATH=$PATH:/usr/local/jdk1.8/bin:/usr/local/jdk1.8/jre/bin
CLASSPATH=/usr/local/jdk1.8/jre/lib:/usr/local/jdk1.8/lib:/usr/local/jdk1.8/jre/lib/charsets.jar
TOMCAT_BIN=/usr/local/tomcat/bin
RETVAL=0
prog="Tomcat"
start()
{
echo "Starting $prog......"
/bin/bash $TOMCAT_BIN/startup.sh
RETVAL=$?
return $RETVAL
}
stop()
{
echo "Stopping $prog......"
/bin/bash $TOMCAT_BIN/shutdown.sh
RETVAL=$?
return $RETVAL
}
restart(){
echo "Restarting $prog......"
stop
start
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
*)
echo $"Usage: $0 {start|stop|restart}"
RETVAL=1
esac
exit $RETVAL自定义rm命令
linux系统的rm命令太危险,一不小心就会删掉系统文件。写一个shell脚本来替换系统的rm命令,要求删除一个文件或者目录的时候,都要做一个备份,然后再删除。下面分两种情况:
1.简单的实现:
假设有一个大的分区/data/,每次删除文件或目录之前,都要在/data/下面创建一个隐藏目录,以日期/时间命名,比如/data/.201903271012/,然后把所有删除的文件同步到该目录下面,可以使用rsync -R把文件路径一同同步,示例:
#!/bin/bash
fileName=$1
now=`date +%Y%m%d%H%M`
read -p "Are you sure delete the file or directory $1? yes|no: " input
if [ $input == "yes" ] || [ $input == "y" ]
then
mkdir /data/.$now
rsync -aR $1/ /data/.$now/$1/
/bin/rm -rf $1
elif [ $input == "no" ] || [ $input == "n" ]
then
exit 0
else
echo "Only input yes or no"
exit
fi2.复杂的实现;
不知道那个分区有剩余空间,再删除之前先计算删除的文件或者目录大小,然后对比计算机系统的磁盘空间,如果能够按照上面的规则创建隐藏目录,并备份,如果没有足够空间,要提醒用户没有足够的空间备份并提示是否放弃备份,如果用户输入yes,则直接删除文件或者目录,如果输入no,则提示未删除,然后退出脚本,示例:
#!/bin/bash
fileName=$1
now=`date +%Y%m%d%H%M`
f_size=`du -sk $1 |awk '{print $1}'`
disk_size=`LANG=en; df -k |grep -vi filesystem |awk '{print $4}' |sort -n |tail -n1`
big_filesystem=`LANG=en; df -k |grep -vi filesystem |sort -n -k4 |tail -n1 |awk '{print $NF}'`
if [ $f_size -lt $disk_size ]
then
read -p "Are you sure delete the file or directory: $1 ? yes|no: " input
if [ $input == "yes" ] || [ $input == "y" ]
then
mkdir -p $big_filesystem/.$now && rsync -aR $1 $big_filesystem/.$now/ && /bin/rm -rf $1
elif [ $input == "no" ] || [ $input == "n" ]
then
exit 0
else
echo "Only input 'yes' or 'no'."
fi
else
echo "The disk size is not enough to backup the file: $1."
read -p "Do you want to delete "$1"? yes|no: " input
if [ $input == "yes" ] || [ $input == "y" ]
then
echo "It will delete "$1" after 5 seconds whitout backup."
for i in `seq 1 5`; do echo -ne "."; sleep 1; done
echo
/bin/rm -rf $1
elif [ $input == "no" ] || [ $input == "n" ]
then
echo "It will not delete $1."
exit 0
else
echo "Only input 'yes' or 'no'."
fi
fi数字求和
编写shell脚本,要求输入一个数字,然后计算出从1到输入数字的和,要求,如果输入的数字小于1 ,则重新输入,直到输入正确的数字为止,示例:
#!/bin/bash
while :
do
read -p "Please enter a positive integer: " n
if [ $n -lt 1 ]
then
echo "It can't be less than 1"
else
break
fi
done
num=1
for i in `seq 2 $n`
do
num=$[$num+$i]
done
echo $num拷贝目录
编写shell脚本,把/root/目录下的所有目录(只需一级)拷贝到/temp/目录下:
#!/bin/bash
cd /root/
list=(`ls`)
for i in ${list[@]}
do
if [ -d $i ]
then
cp -r $i /tmp/
fi
done批量建立用户
编写shell脚本,批量建立用户user_00,user_01,....user_100并且所有用户同属于users组;
#!/bin/bash
group=`cat /etc/group |grep -o users`
if [ $group == "users" ]
then
for i in `seq 0 100`
do
if [ $i -lt 10 ]
then
useradd -g users user_0$i
else
useradd -g users user_$i
fi
done
else
echo "users group not found!"
exit 1
fi删除以上脚本批量田间的用户:
#!/bin/bash
for i in `seq 0 100`
do
if [ $i -lt 10 ]
then
userdel -r user_0$i
else
userdel -r user_$i
fi
done每日生成一个文件
要求:请按照这样的日期格式(xxxx-xx-xx)每日生成一个文件,例如今天生成的文件为2019-01-31.log,并且把磁盘的使用情况写到这个文件中(不用考虑corn,仅仅写脚本即可)
#!/bin/bash
fileName=`date +%F`
c=`df -h`
echo "$c" > /root/$fileName.log统计ip
有一个日志文件,日志片段:如下:
112.111.12.248 – [25/Sep/2013:16:08:31 +0800]formula-x.haotui.com “/seccode.php?update=0.5593110133088248″ 200″http://formula-x.haotui.com/registerbbs.php” “Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1;)”
61.147.76.51 – [25/Sep/2013:16:08:31 +0800]xyzdiy.5d6d.com “/attachment.php?aid=4554&k=9ce51e2c376bc861603c7689d97c04a1&t=1334564048&fid=9&sid=zgohwYoLZq2qPW233ZIRsJiUeu22XqE8f49jY9mouRSoE71″ 301″http://xyzdiy.×××thread-1435-1-23.html” “Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)”
要求:统计出每个IP的访问量有多少?
awk '{print $1}' 1.log |sort -n |uniq -c |sort -n
解释:sort -n会按照数值而不是ASCII码来排序awk截取出来的ip。然后uniq命令用于报告或者忽略文件中的重复行,
加上-c选项后会在每列旁边显示该行重复出现的次数,在这一步就完成了统计。不过最后还得让
sort -n排序一下uniq -c统计出来的结果统计内存使用
写一个脚本计算linux系统所有进程占用内存大小的和。脚本如下;
#!/bin/bash
count=0
# 这个循环会遍历出每个进程占用的内存大小
for i in `ps aux |awk '{print $6}' |grep -v 'RSS'`
do
# 将遍历出来的数字进行累加
count=$[$count+$i]
done
# 就得到所有进程占用内存大小的和了
echo "$count/kb"
也可以使用awk 一条命令计算:
ps aux |grep -v 'RSS TTY' |awk '{sum=sum+$6};END{print sum}'解释:grep -v是忽略 'RSS TTY' 所存在的那一行,后面的awk声明了一个变量sum,sum将前面命令列出来的数字进行累加,END之后就将累加后的sum打印出来,就得到所有进程占用内存大小的和了。
简单的监控脚本
设计一个简单的脚本,监控远程的一台机器(假设ip为123.23.11.21)的存货状体啊,当发现当宕机的时候发一封邮件给你自己
#!/bin/bash
ip="123.23.11.21"
email="user@example"
while 1
do
ping -c10 $ip > /dev/null 2>/dev/null
if [ $? != "0" ]
then
# 调用一个用于发邮件的脚本
python /usr/local/sbin/mail.py $email "$ip down" "$ip is down"
fi
sleep 30
done
mail.py 脚本代码:
#!/usr/bin/env python
#-*- coding: UTF-8 -*-
import os,sys
reload(sys)
sys.setdefaultencoding('utf8')
import getopt
import smtplib
from email.MIMEText import MIMEText
from email.MIMEMultipart import MIMEMultipart
from subprocess import *
def sendqqmail(username,password,mailfrom,mailto,subject,content):
# 邮箱的服务地址
gserver = 'smtp.qq.com'
gport = 25
try:
msg = MIMEText(unicode(content).encode('utf-8'))
msg['from'] = mailfrom
msg['to'] = mailto
msg['Reply-To'] = mailfrom
msg['Subject'] = subject
smtp = smtplib.SMTP(gserver, gport)
smtp.set_debuglevel(0)
smtp.ehlo()
smtp.login(username,password)
smtp.sendmail(mailfrom, mailto, msg.as_string())
smtp.close()
except Exception,err:
print "Send mail failed. Error: %s" % err
def main():
to=sys.argv[1]
subject=sys.argv[2]
content=sys.argv[3]
#定义QQ邮箱的账号和密码,你需要修改成你自己的账号和密码
sendqqmail('[email protected]','aaaaaaaaaa','[email protected]',to,subject,content)
if __name__ == "__main__":
main()#####脚本使用说明######
#1. 首先定义好脚本中的邮箱账号和密码
#2. 脚本执行命令为:python mail.py 目标邮箱 "邮件主题" "邮件内容"
批量更改文件名
需求:
找到/123目录下所有后缀名为.txt的文件
批量修改.txt为.txt.bak
把所有的.bak文件打包压缩为123.tar.gz
批量还原文件的名字,即把增加的.bak再删除
代码:
#!/bin/bash
now=`date +%F_%T`
mkdir /tmp/123_$now
for txt in `ls /123/*.txt`
do
mv $txt $txt.bak
for f in $txt
do
cp $txt.bak /tmp/123_$now
done
done
cd /tmp/
tar czf 123.tar.gz 123_$now/
for txt in `ls /123/*.txt.bak`
do
name=`echo $txt |awk -F '.' '{OFS="."} {print $1,$2}'`
mv $txt $name
done监控80端口
需求:写一个脚本,判断本机的80端口(假如服务为httpd)是否开着,如果开启这什么都不做,如果发现端口不存在,那么重启一下httpd服务,并发邮件通知你自己。脚本写好后,可以每一分钟执行一次,也可以写一个死循环的脚本,30s检测一次。
代码:
#!/bin/bash
email="[email protected]"
if netstat -lntp |grep ':80' |grep 'httpd'
then
echo "80 port no problem"
exit
else
/usr/local/apache2.4/bin/apachectl restart
python mail.py $email "check_80port" "The 80 port is down."
n=`ps aux |grep httpd|grep -cv grep`
if [ $n -eq 0 ]
then
/usr/local/apache2/bin/apachectl start 2>/tmp/apache_start.err
fi
if [ -s /tmp/apache_start.err ]
then
python mail.py $mail 'apache_start_error' `cat /tmp/apache_start.err`
fi
fi
备份数据库
需求:设计一个shell脚本来备份数据库,首先在本地服务器上保存一份数据,然后再远程拷贝一份,本地保存一周的数据,远程保存一个月。
假定,我们知道mysql root账号的密码,要备份的数据库为discuz,本地备份目录为/bak/mysql,远程服务器为192.168.123.30,远程提供了一个rsync服务,备份地址是192.168.123.30::backup 写完脚本后,需要加入到cron中,每天凌晨三点执行。
脚本代码:
#!/bin/bash
PATH=$PATHi:/usr/local/mysql/bin
week=`date +%w`
today=`date +d`
passwd="123456"
backdir="/data/mysql"
r_backupIP="192.168.123.30::backup"
exec 1>/var/log/mysqlbak.log 2>/var/log/mysqlbak.log
echo "mysql backup begin at `date +%F %T`."
# 本地备份
mysqldump -uroot -p$passwd --default-character-set=utf8 discuz >$backdir/$week.sql
# 同步备份到远程机器
rsync -az $backdir/$week.sql $r_backupIP/$today.sql
echo "mysql backup end at `date +%F %T`."然后加入cron
0 3 * * * /bin/bash /usr/local/sbin/mysqlbak.sh
启动容器
docker每次关闭都会连带着将运行中的容器关闭,所以每次启动docker以后都需要逐个去启动容器,很麻烦,由于实验用的虚拟机不是线上的机器,所以就直接写了一个简单的循环来启动容器;
#!/bin/bash
/usr/bin/systemctl start docker
for i in `docker ps -a |grep 'Exited' |awk '{print $1}'`
do
/usr/bin/docker start $i
done输入数字执行对应命令
写一个脚本实现如下功能:输入一个数字,然后运行对应的一个命令。显示命令如下:
*cmd meau** 1—date 2–ls 3–who 4–pwd
当输入1的时候,会运行date,输入2时运行ls,以此类推。
实现脚本如下:
#!/bin/bash
echo "*cmd meau** 1—date 2–ls 3–who 4–pwd"
read -p "please input a number 1-4: " n
case $n in
1)
date
;;
2)
ls
;;
3)
who
;;
4)
pwd
;;
*)
echo "Please input a number: 1-4"
;;
esac监控httpd进程
在服务器上写一个监控的脚本
每隔十秒去检测一次服务器上的httpd进程数,如果大雨等于500的时候,就需要自动重启一下apache服务,并检测启动是否成功 ?
若没有正常启动还需要再重启一次,最大不成功次数超过五次则需要立即发邮件通知管理员,并且以后不需要再检测。如果启动成功后,1分钟后再检测httpd进程数,若正常则重复之前操作(每隔10秒检测一次)若还是大于等于500,那放弃重启并需要发邮件给管理员,然后自动退出该脚本。假设其中发邮件脚本为mail.py
实现脚本如下:
#!/bin/bash
check_service(){
n=0
for i in `seq 1 5`
do
# apachectl命令所在路径
/usr/local/apache2/bin/apachectl restart 2> /tmp/apache.err
if [$? -ne 0 ]
then
n=$[$n-1]
else
break
fi
done
if [ $n -eq 5 ]
then
## mail.py的内容参考https://coding.net/u/aminglinux/p/aminglinux-book/git/blob/master/D22Z/mail.py
python mail.py "[email protected]" "httpd service down" `cat /tmp/apache.err`
exit
fi
}
while :
do
t_n=`ps -C httpd --no-heading |wc -l`
if [ $t_n -ge 500 ]
then
/usr/local/apache2/bin/apachectl restart
if [ $? -ne 0 ]
then
check_service
fi
sleep 60
t_n=`ps -C httpd --no-heading |wc -l`
if [ $t_n -ge 500]
then
python mail.py "[email protected]" "httpd service somth wrong" "the httpd process is budy."
exit
fi
fi
sleep 10
done封ip
需求:根据web服务器上的访问日志,把一些请求量非常高的ip给拒绝掉
分析:我们要做的不仅是找到哪些ip请求量不合法,并且还要每隔一段时间把之前封掉的ip(若不再继续请求了)给解封。所以该脚本的关键点在于定一个合适的时间段和阈值。
比如:我们可以每一分钟去查看一下日志,把上一分钟的日志给过滤出来分析,并且只要请求的ip数量超过100次那么就直接封掉。而解封的时间又规定为每半小时分析一次,把几乎没有请求量的ip给解封。
参考日志文件片段:
157.55.39.107 [20/Mar/2015:00:01:24 +0800] www.aminglinux.com “/bbs/thread-5622-3-1.html” 200 “-” “Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)”
61.240.150.37 [20/Mar/2015:00:01:34 +0800] www.aminglinux.com “/bbs/search.php?mod=forum&srchtxt=LNMP&formhash=8f0c7da9&searchsubmit=true&source=hotsearch” 200 “-” “Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)”
实现代码如下;
#!/bin/bash
## 日志文件路径
log_file="/home/logs/client/access.log"
## 当前时间减一分钟的时间
d1=`date -d "-1 minute" +%H:%M`
## 当前时间的分钟段
d2=`date +%M`
## iptables命令所在的路径
ipt="/sbin/iptables"
## 用于存储访问日志里的ip
ips="/tmp/ips.txt"
## 封ip
block(){
## 把日志文件中的ip过滤出来,去掉重复的ip,并统计ip的重复次数以及对ip进行排序,最后将结果写到一个文件中
grep "$d1:" $log_file |awk '{print $1}' |sort -n |uniq -c |sort -n > $ips
## 将文件里重复次数大于100的ip迭代出来
for ip in `awk '$1 > 100 {print $2}' $ips`
do
## 通过防火墙规则对这些ip进行封禁
$ipt -I INPUT -p -tcp --dport 80 -s $ip -j REJECT
## 将已经封禁的ip输出到一个文件里存储
echo "`date +%F-%T` $ip" >> /tmp/badip.txt
done
}
## 解封ip
unblock(){
## 将流量小于15的规则索引过滤出来
for i in `$ipt -nvL --line-number |grep '0.0.0.0/0' |awk '$2 < 15 {print $1}' |sort -nr`
do
## 通过索引来删除规则
$ipt -D INPUT $i
done
## 清空规则中的数据包计算器和字节计数器
$ipt -Z
}
## 为整点或30分钟就是过了半个小时,就需要再进行分析
if [ $d2 == "00" ] || [ $d2 == "30" ]
then
unblock
block
else
block
fi部署前端项目
最近做了一个web前端的项目,需要编写一个脚本完成项目的上线
脚本实现如下:
#!/bin/bash
#
# 使用方法:
# mmall:front_deploy.sh mmall-fe
# admin:front_deploy.sh admin-fe
#
GIT_HOME=/developer/git-repository/ # 从git仓库拉取下来的源码的存放路径
DEST_PATH=/product/frontend/ # 项目打包后的发布路径
# cd dir
if [ ! -n "$1" ]
then
echo -e "请输入要发布的项目!"
exit
fi
if [ $1 = "mmall-fe" ]
then
echo -e "===========Enter mall-fe============="
cd $GIT_HOME$1
elif [ $1 = "admin-fe" ]
then
echo -e "===========Enter mall-fe============="
cd $GIT_HOME$1
else
echo -e "输入的项目名没有找到!"
exit
fi
# clear git dist
echo -e "===========Clear Git Dist============="
rm -rf ./dist
# git操作
echo -e "===========git checkout master============="
git checkout master
echo -e "===========git pull============="
git pull
# npm install
echo -e "===========npm install============="
npm install --registry=https://registry.npm.taobao.org
# npm run dist
echo -e "===========npm run dist============="
npm run dist
if [ -d "./dist" ]
then
# backup dest
echo -e "===========dest backup============="
mv $DEST_PATH$1/dist $DEST_PATH$1/dist.bak
# copy
echo -e "===========copy============="
cp -R ./dist $DEST_PATH$1
# echo result
echo -e "===========Deploy Success============="
else
echo -e "===========Deploy Error============="
fi监控磁盘使用率
写一个shell脚本,检测所有磁盘分区使用率和inode使用率并记录到以当天日期为命名的日志文件里,当发现某个分区容量或者inode使用量大于85%时,发邮件通知你自己。
思路:就是先df -h 然后过滤出已使用的那一列,然后再想办法过滤出百分比的整数部分,然后和85去比较,同理,inode也是一样的思路。
实现代码:
#!/bin/bash
## This script is for record Filesystem Use%,IUse% everyday and send alert mail when % is more than 85%.
log=/var/log/disk/`date +%F`.log
date +'%F %T' > $log
df -h >> $log
echo >> $log
df -i >> $log
for i in `df -h|grep -v 'Use%'|sed 's/%//'|awk '{print $5}'`; do
if [ $i -gt 85 ]; then
use=`df -h|grep -v 'Use%'|sed 's/%//'|awk '$5=='$i' {print $1,$5}'`
echo "$use" >> use
fi
done
if [ -e use ]; then
##这里可以使用咱们之前介绍的mail.py发邮件
mail -s "Filesystem Use% check" root@localhost < use
rm -rf use
fi
for j in `df -i|grep -v 'IUse%'|sed 's/%//'|awk '{print $5}'`; do
if [ $j -gt 85 ]; then
iuse=`df -i|grep -v 'IUse%'|sed 's/%//'|awk '$5=='$j' {print $1,$5}'`
echo "$iuse" >> iuse
fi
done
if [ -e iuse ]; then
mail -s "Filesystem IUse% check" root@localhost < iuse
rm -rf iuse
fi思路:
df -h、df -i 记录磁盘分区使用率和inode使用率,date +%F 日志名格式
取出使用率(第5列)百分比序列,for循环逐一与85比较,大于85则记录到新文件里,当for循环结束后,汇总超过85的一并发送邮件(邮箱服务因未搭建,发送本地root账户)。
此脚本正确运行前提:
该系统没有逻辑卷的情况下使用,因为逻辑卷df -h、df -i 时,使用率百分比是在第4列,而不是第5列。如有逻辑卷,则会漏统计逻辑卷使用情况。
【脚本28】获取文件列表
有一台服务器作为web应用,有一个目录(/data/web/attachment)不定时地会被用户上传新的文件,但是不知道什么时候会上传。所以,需要我们每5分钟做一次检测是否有新文件生成。
请写一个shell脚本去完成检测。检测完成后若是有新文件,还需要将新文件的列表输出到一个按年、月、日、时、分为名字的日志里。请不要想的太复杂,核心命令只有一个 find /data/web/attachment -mmin -5
思路: 每5分钟检测一次,那肯定需要有一个计划任务,每5分钟去执行一次。脚本检测的时候,就是使用find命令查找5分钟内有过更新的文件,若是有更新,那这个命令会输出东西,否则是没有输出的。固,我们可以把输出结果的行数作为比较对象,看看它是否大于0。
实现代码:
#!/bin/bash
d=`date -d "-5 min" +%Y%m%d%H%M`
basedir=/data/web/attachment
find $basedir/ -type f -mmin -5 > /tmp/newf.txt
n=`wc -l /tmp/newf.txt`
if [ $n -gt 0 ]; then
/bin/mv /tmp/newf.txt /tmp/$d
fi统计常用命令
写一个shell脚本来看看你使用最多的命令是哪些,列出你最常用的命令top10。
思路:我们要用到一个文件就是.bash_history,然后再去sort、uniq,剩下的就不用我多说了吧。很简单一个shell。
一条命令即可:
sort /root/.bash_history |uniq -c |sort -nr |head
检测文件改动
有两台Linux服务器A和B,假如A可以直接ssh到B,不用输入密码。A和B都有一个目录叫做/data/web/ 这下面有很多文件,当然我们不知道具体有几层子目录,假若之前A和B上该目录下的文件都是一模一样的。但现在不确定是否一致了。固需要我们写一个脚本实现这样的功能,检测A机器和B机器/data/web/目录下文件的异同,我们以A机器上的文件作为标准。比如,假若B机器少了一个a.txt文件,那我们应该能够检测出来,或者B机器上的b.txt文件有过改动,我们也应该能够检测出来(B机器上多了文件我们不用考虑)。
提示: 使用核心命令 md5sum a.txt 算出md5值,去和B机器上的比较。
实现代码:
#!/bin/bash
#假设A机器到B机器已经做了无密码登录设置
dir=/data/web
##假设B机器的IP为192.168.0.100
B_ip=192.168.0.100
find $dir -type f |xargs md5sum >/tmp/md5.txt
ssh $B_ip "find $dir -type f |xargs md5sum >/tmp/md5_b.txt"
scp $B_ip:/tmp/md5_b.txt /tmp
for f in `awk '{print $2}' /tmp/md5.txt`
do
if grep -q "$f" /tmp/md5_b.txt
then
md5_a=`grep $f /tmp/md5.txt|awk '{print $1}'`
md5_b=`grep $f /tmp/md5_b.txt|awk '{print $1}'`
if [ $md5_a != $md5_b ]
then
echo "$f changed."
fi
else
echo "$f deleted. "
fi
done统计网卡流量
写一个脚本,检测你的网络流量,并记录到一个日志里。需要按照如下格式,并且一分钟统计一次(只需要统计外网网卡,假设网卡名字为eth0):
2017-08-04 01:11
eth0 input: 1000bps
eth0 output : 200000bps
################
2017-08-04 01:12
eth0 input: 1000bps
eth0 output : 200000bps
提示:使用sar -n DEV 1 59 这样可以统计一分钟的平均网卡流量,只需要最后面的平均值。另外,注意换算一下,1byt=8bit
实现代码;
#!/bin/bash
while :
do
LANG=en
DATE=`date +"%Y-%m-%d %H:%M"`
LOG_PATH=/tmp/traffic_check/`date +%Y%m`
LOG_FILE=$LOG_PATH/traffic_check_`date +%d`.log
[ -d $LOG_PATH ] || mkdir -p $LOG_PATH
echo " $DATE" >> $LOG_FILE
sar -n DEV 1 59|grep Average|grep eth0 \
|awk '{print "\n",$2,"\t","input:",$5*1000*8,"bps", \
"\t","\n",$2,"\t","output:",$6*1000*8,"bps" }' \
>> $LOG_FILE
echo "#####################" >> $LOG_FILE
done系统——批量杀进程
今天发现网站访问超级慢,top看如下:
有很多sh进程,再ps查看:
这个脚本,运行很慢,因为制定了cron,上一次还没有运行完,又有了新的运行任务。太多肯定会导致系统负载升高。当务之急就是先把这些在跑的给kill掉。那么我们可以使用一条命令,直接杀死所有的sh。
命令如下:
ps aux |grep clearmem.sh |grep -v grep|awk '{print $2}'|xargs kill
监控mysql服务
假设,当前MySQL服务的root密码为123456,写脚本检测MySQL服务是否正常(比如,可以正常进入mysql执行show processlist),并检测一下当前的MySQL服务是主还是从,如果是从,请判断它的主从服务是否异常。如果是主,则不需要做什么。
实现代码:
#!/bin/bash
Mysql_c="mysql -uroot -p123456"
$Mysql_c -e "show processlist" >/tmp/mysql_pro.log 2>/tmp/mysql_log.err
n=`wc -l /tmp/mysql_log.err|awk '{print $1}'`
if [ $n -gt 0 ]
then
echo "mysql service sth wrong."
else
$Mysql_c -e "show slave status\G" >/tmp/mysql_s.log
n1=`wc -l /tmp/mysql_s.log|awk '{print $1}'`
if [ $n1 -gt 0 ]
then
y1=`grep 'Slave_IO_Running:' /tmp/mysql_s.log|awk -F : '{print $2}'|sed 's/ //g'`
y2=`grep 'Slave_SQL_Running:' /tmp/mysql_s.log|awk -F : '{print $2}'|sed 's/ //g'`
if [ $y1 == "Yes" ] && [ $y2 == "Yes" ]
then
echo "slave status good."
else
echo "slave down."
fi
fi
fi找出活动ip
写一个shell脚本,把192.168.0.0/24网段在线的ip列出来。
思路:for循环,0.1——0.254依次去ping,能通说明在线;
参考代码:
#!/bin/bash
ips="192.168.1."
for i in `seq 1 254`
do
ping -c 2 $ips$i >/dev/null 2>/dev/null
if [ $? == 0 ]
then
echo "echo $ips$i is online"
else
echo "echo $ips$i is not online"
fi
done检查错误
写一个shell脚本,检查指定的shell脚本是否有语法错误,若有错误,首先显示错误信息,然后提示用户输入q或者Q退出脚本,输入其他内容则直接用vim打开该shell脚本。
提醒: 检查shell脚本有没有语法错误的命令是 sh -n xxx.sh
参考代码:
#!/bin/bash
sh -n $1 2>/tmp/err
if [ $? -eq "0" ]
then
echo "The script is OK."
else
cat /tmp/err
read -p "Please inpupt Q/q to exit, or others to edit it by vim. " n
if [ -z $n ]
then
vim $1
exit
fi
if [ $n == "q" -o $n == "Q" ]
then
exit
else
vim $1
exit
fi
fi检查服务
先判断是否安装http和mysql,没有安装进行安装,安装了检查是否启动服务,若没有启动服务则需要启动服务。
说明:操作系统为centos6,httpd和mysql全部为rpm包安装
参考代码:
#!/bin/bash
if_install()
{
n=`rpm -qa|grep -cw "$1"`
if [ $n -eq 0 ]
then
echo "$1 not install."
yum install -y $1
else
echo "$1 installed."
fi
}
if_install httpd
if_install mysql-server
chk_ser()
{
p_n=`ps -C "$1" --no-heading |wc -l`
if [ $p_n -eq 0 ]
then
echo "$1 not start."
/etc/init.d/$1 start
else
echo "$1 started."
fi
}
chk_httpd
chk_mysqld端口解封
一个小伙伴提到一个问题,他不小心用iptables规则把sshd端口22给封掉了,结果不能远程登陆,要想解决这问题,还要去机房,登陆真机去删除这规则。 问题来了,要写个监控脚本,监控iptables规则是否封掉了22端口,如果封掉了,给打开。 写好脚本,放到任务计划里,每分钟执行一次。
参考代码:
#!/bin/bash
# check sshd port drop
/sbin/iptables -nvL --line-number|grep "dpt:22"|awk -F ' ' '{print $4}' > /tmp/drop.txt
i=`cat /tmp/drop.txt|head -n 1|egrep -iE "DROP|REJECT"|wc -l`
if [ $i -gt 0 ]
then
/sbin/iptables -I INPUT 1 -p tcp --dport 22 -j ACCEPT
fi统计分析日志
已知nginx访问的日志文件在/usr/local/nginx/logs/access.log内
请统计下早上10点到12点 来访ip最多的是哪个?
日志样例:
111.199.186.68 – [15/Sep/2017:09:58:37 +0800] “//plugin.php?id=security:job” 200 “POST //plugin.php?id=security:job HTTP/1.1″”http://a.lishiming.net/forum.php?mod=viewthread&tid=11338&extra=page%3D1%26filter%3Dauthor%26orderby%3Ddateline” “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.7 Safari/537.36” “0.516”
203.208.60.208 – [15/Sep/2017:09:58:46 +0800] “/misc.php?mod=patch&action=ipnotice&_r=0.05560809863330207&inajax=1&ajaxtarget=ip_notice” 200 “GET /misc.php?mod=patch&action=ipnotice&_r=0.05560809863330207&inajax=1&ajaxtarget=ip_notice HTTP/1.1″”http://a.lishiming.net/forum.php?mod=forumdisplay&fid=65&filter=author&orderby=dateline” “Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3141.7 Safari/537.36” “0.065”
实现这个需求使用如下命令即可:
grep '15/Sep/2017:1[0-2]:[0-5][0-9]:' /usr/local/nginx/logs/access.log|awk '{print $1}'|sort -n|uniq -c |sort -n|tail -n1
杀死进程
把当前用户下所有进程名字中含有“java”的进程关闭
示例如下:
ps -u $USER |awk '$NF ~ /java/ {print $1}'|xargs kill
备份数据表
用shell实现,以并发进程的形式将mysql数据库所有的表备份到当前目录,并把所有的表压缩到一个压缩包文件里。
假设数据库名字为mydb,用户名为zero,密码为passwd。
提示: 在shell中加上&可以将命令丢到后台,从而可以同时执行多条命令达到并发的效果。
代码如下:
#!/bin/bash
pre=`date +%F`
for d in `mysql -uaming -ppasswd mydb -e "show tables"|grep -v 'Tables_in_'`
do
mysqldump -uaming -ppasswd mydb $d > $d.sql &
done
tar czf $pre.tar.gz *.sql
rm -f *.sql监控节点
一个网站,使用了cdn,全国各地有几十个节点。需要你写一个shell脚本来监控各个节点是否正常。
假如:
监控的url为www.xxx.com/index.php
源站ip为88.88.88.88
参考代码:
#!/bin/bash
url="www.xxx.com/index.php"
s_ip="88.88.88.88"
curl -x $s_ip:80 $url > /tmp/source.html 2>/dev/null
for ip in `cat /tmp/ip.txt`
do
curl -x $ip:80 $url 2>/dev/null >/tmp/$ip.html
[ -f /tmp/$ip.diff ] && rm -f /tmp/$ip.diff
touch /tmp/$ip.diff
diff /tmp/source.html /tmp/$ip.html > /tmp/$ip.diff 2>/dev/null
n=`wc -l /tmp/$ip.diff|awk '{print $1}'`
if [ $n -lt 0 ]
then
echo "node $ip sth wrong."
fi
done监控cpu使用率
用shell写一个监控服务器cpu使用率的监控脚本。
思路:用top -bn1 命令,取当前空闲cpu百份比值(只取整数部分),然后用100去剑这个数值。
实现代码:
#!/bin/bash
while :
do
idle=`top -bn1 |sed -n '3p' |awk '{print $5}'|cut -d . -f1`
use=$[100-$idle]
if [ $use -gt 90 ]
then
echo "cpu use percent too high."
#发邮件省略
fi
sleep 10
done处理日志
写一个脚本查找/data/log目录下,最后创建时间是3天前,后缀是*.log的文件,打包后发送至192.168.1.2服务上的/data/log下,并删除原始.log文件,仅保留打包后的文件
参考代码:
#!/bin/bash
find /data/log -name “*.log” -mtime +3 > /tmp/file.list
cd /data/log
tar czvf log.tar.gz `cat /tmp/file.list|xargs`
rsync -a log.tar.gz 192.168.1.2:/data/log # 这一步需要提前做一个免密码登录
for f in `cat /tmp/file.list`
do
rm -f $f
done监控磁盘io
阿里云的机器,今天收到客服来的电话,说服务器的磁盘io很重。于是登录到服务器查看,并没有发现问题,所以怀疑是间歇性地。
正要考虑写个脚本的时候,幸运的抓到了一个线索,造成磁盘io很高的幕后黑手是mysql。此时去show processlist,但未发现队列。原来只是一瞬间。
只好继续来写脚本,思路是,每5s检测一次磁盘io,当发现问题去查询mysql的processlist。
提示:你可以用iostat -x 1 5 来判定磁盘的io,主要看%util
参考代码;
#!/bin/bash
while :
do
n=`iostat -x 1 5 |tail -n3|head -n1 |awk '{print $NF}'|cut -d. -f1`
if [ $n -gt 70 ]
then
echo "`date` util% is $n%" >>/tmp/mysql_processlist.log
mysql -uroot -pxxxxxx -e "show full processlist" >> /tmp/mysql_processlist.log
fi
sleep 5
done批量同步代码
需求背景是:
一个业务,有3台服务器(A,B,C)做负载均衡,由于规模太小目前并未使用专业的自动化运维工具。有新的需求时,开发同事改完代码会把变更上传到其中一台服务器A上。但是其他2台服务器也需要做相同变更。
写一个shell脚本,把A服务器上的变更代码同步到B和C上。
其中,你需要考虑到不需要同步的目录(假如有tmp、upload、logs、caches)
参考代码;
#!/bin/bash
echo "该脚本将会把A机器上的/data/wwwroot/www.aaa.com目录同步到B,C机器上";
read -p "是否要继续?(y|n) "
rs() {
rsync -azP \
--exclude logs \
--exclude upload \
--exclude caches \
--exclude tmp \
www.aaa.com/ $1:/data/wwwroot/www.aaa.com/
}
if [ $REPLY == 'y' -o $REPLY == 'Y' ]
then
echo "即将同步……"
sleep 2
cd /data/wwwroot/
rs B机器ip
rs C机器ip
echo "同步完成。"
elif [ $REPLY == 'n' -o $REPLY == 'N' ]
then
exit 1
else
echo "请输入字母y或者n"
fi统计并发量
需求背景:
需要统计网站的并发量,并绘图。
思路:
借助zabbix成图
通过统计访问日志每秒的日志条数来判定并发量
zabbix获取数据间隔30s
说明: 只需要写出shell脚本即可,不用关心zabbix配置。
假设日志路径为:
/data/logs/www.aaa.com_access.log
日志格式如下:
112.107.15.12 - [07/Nov/2017:09:59:01 +0800] www.aaa.com "/api/live.php" 200"-" "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)"
参考代码;
#!/bin/bash
log=/data/logs/www.aaa.com_access.log
t=`date -d "-1 second" +%Y:%H:%M:%S`
#可以大概分析一下每分钟日志的量级,比如说不超过3000
n=tail -3000 $log |grep -c "$t"
echo $n关闭服务
在centos6系统里,我们可以使用ntsysv关闭不需要开机启动的服务,当然也可以使用chkconfig工具来实现。
写一个shell脚本,用chkconfig工具把不常用的服务关闭。脚本需要写成交互式的,需要我们给它提供关闭的服务名字。
参考代码:
#!/bin/bash
LANG=en
c="1"
while [ ! $c == "q" ]
do
echo -e "\033[35mPlease chose a service to close from this list: \033[0m"
chkconfig --list |awk '/3:on/ {print $1}'
read -p "Which service to close: " s
chkconfig $s off
service $s stop
read -p "If you want's to quit this program, tab "q", or tab "Ctrl c": " c
done重启tomcat服务
在生产环境中,经常遇到tomcat无法彻底关闭,也就是说用tomcat自带shutdown.sh脚本无法将java进程完全关掉。所以,需要借助shell脚本,将进程杀死,然后再启动。
写一个shell脚本,实现上述功能。彻底杀死一个进程的命令是 kill -9 pid.
参考代码;
#!/bin/bash
###功能: 重启 tomcat 进程
###要求:对于tomcat中的某些应用,使用shutdown.sh是无法完全停掉所有服务的 实际操作中都需要kill掉tomcat再重启
##
### root can not run this script.
##
if [ $USER = root ]
then
echo "root cann't run this script!please run with other user!"
exit 1
fi
##
### check the Parameter
##
if [[ $# -ne 1 ]]
then
echo "Usage:$0 tomcatname"
exit 1
fi
##
### only one process can run one time
##
TMP_FILE_U=/tmp/.tmp.ps.keyword.$USER.956327.txt
#echo $TMP_FILE_U
KEYWORD1="$0"
KEYWORD2="$1"
# 使用赋值会多fork出一个进程,所以要先重定向到一个文本,再统计.
ps ux |grep "$KEYWORD1"|grep "\<$KEYWORD2\>"|grep -v "grep" > $TMP_FILE_U
Pro_count=`cat $TMP_FILE_U |wc -l`
if [ $Pro_count -gt 1 ]
then
echo "An other process already running ,exit now!"
exit 1
fi
###################################################
# #
# begin of the script #
# #
###################################################
##
### set the Parameter
##
TOM=`echo $1|sed 's#/##g'`
TOMCAT_DIRECTORY=~/usr/local/$TOM
STARTUP_SCRIPT=$TOMCAT_DIRECTORY/bin/startup.sh
TOMCAT_LOG=$TOMCAT_DIRECTORY/logs/catalina.out
CONF_FILE=$TOMCAT_DIRECTORY/conf/server.xml
TEMPFILE=/tmp/.tmpfile.x.89342.c4r3.tmp
##
### check if the tomcat directory exist
##
if [ ! -d "$TOMCAT_DIRECTORY" ]
then
echo "the tomcat \"$TOM\" not exist.check again!"
exit 1
fi
##
### log roteta and delete log one week ago
##
rotate_log(){
TIME_FORMART=$(date +%Y%m%d%H%M%S)
LOG_DIR=$(dirname $TOMCAT_LOG)
mv $TOMCAT_LOG ${TOMCAT_LOG}_${TIME_FORMART}
find $LOG_DIR -type f -ctime +7 -exec rm -rf {} \;
}
##
### function start the tomcat
##
start_tomcat()
{
#echo start-tomcat-func
if [ -x "$STARTUP_SCRIPT" ]
then
rotate_log
$STARTUP_SCRIPT
sleep 1
tail -f $TOMCAT_LOG
else
if [ -e $STARTUP_SCRIPT ]
then
chmod +x $STARTUP_SCRIPT
# echo "permition added!"
if [ -x "$STARTUP_SCRIPT" ]
then
rotate_log
$STARTUP_SCRIPT
sleep 1
tail -f $TOMCAT_LOG
else
echo "The script not have excute permision,Couldn't add permision to Script!"
exit 1
fi
else
echo "error,the script \"startup.sh\" not exist!"
exit 1
fi
fi
}
##
### function stop the tomcat
##
stop_tomcat()
{
rm -rf $TEMPFILE
ps ux |grep /$TOM/ |grep -v "grep /$TOM/"|grep java > $TEMPFILE
Pro_Count=`cat $TEMPFILE|wc -l`
PIDS=`cat $TEMPFILE|awk '{print $2}'`
rm -rf $TEMPFILE
#echo $Pro_Count
if [ $Pro_Count -eq 0 ]
then
echo "The tomcat not running now!"
else
if [ $Pro_Count -ne 1 ]
then
echo "The have $Pro_Count process running,killed!"
kill -9 `echo $PIDS`
WC=`ps aux | grep "/$TOM/" | grep -v "grep /$TOM/" | grep java |wc -l`
[ $WC -ne 0 ] && (echo "kill process failed!";exit 1)
else
echo "Process killed!"
kill -9 `echo $PIDS`
WC=`ps aux | grep "/$TOM/" | grep -v "grep /$TOM/" | grep java |wc -l`
[ $WC -ne 0 ] && (echo "kill process failed!";exit 1)
fi
fi
}
###########################
#### ####
#### The main script ####
#### ####
###########################
echo -e "are you sure restart $TOM?(y or n)"
read ANS
if [ "$ANS"a != ya ]
then
echo -e "bye! \n"
exit 1
fi
stop_tomcat
echo "start tomcat ..."
sleep 2
start_tomcat
# end域名到期提醒
写一个shell脚本,查询指定域名的过期时间,并在到期前一周,每天发一封提醒邮件。
思路: 大家可以在linux下使用命令“whois 域名”,如”whois xxx.com”,来获取该域名的一些信息。
提示: whois命令,需要安装jwhois包
参考代码:
#!/bin/bash
t1=`date +%s`
is_install_whois()
{
which whois >/dev/null 2>/dev/null
if [ $? -ne 0 ]
then
yum install -y jwhois
fi
}
notify()
{
e_d=`whois $1|grep 'Expiry Date'|awk '{print $4}'|cut -d 'T' -f 1`
e_t=`date -d "$e_d" +%s`
n=`echo "86400*7"|bc`
e_t1=$[$e_t-$n]
if [ $t1 -ge $e_t1 ] && [ $t1 -lt $e_t ]
then
/usr/local/sbin/mail.py [email protected] "Domain $1 will be expire." "Domain $1 expire date is $e_d."
fi
}
is_install_whois
notify xxx.com自动增加公钥
写一个shell脚本,当我们执行时,提示要输入对方的ip和root密码,然后可以自动把本机的公钥增加到对方机器上,从而实现密钥认证。
参考代码:
#!/bin/bash
read -p "Input IP: " ip
ping $ip -w 2 -c 2 >> /dev/null
## 查看ip是否可用
while [ $? -ne 0 ]
do
read -p "your ip may not useable, Please Input your IP: " ip
ping $ip -w 2 -c 2 >> /dev/null
done
read -p "Input root\'s password of this host: " password
## 检查命令子函数
check_ok() {
if [ $? != 0 ]
then
echo "Error!."
exit 1
fi
}
## yum需要用到的包
myyum() {
if ! rpm -qa |grep -q "$1"
then
yum install -y $1
check_ok
else
echo $1 already installed
fi
}
for p in openssh-clients openssh expect
do
myyum $p
done
## 在主机A上创建密钥对
if [ ! -f ~/.ssh/id_rsa ] || [ ! -f ~/.ssh/id_rsa.pub ]
then
if [ -d ~/.ssh ]
then
mv ~/.ssh/ ~/.ssh_old
fi
echo -e "\n" | ssh-keygen -t rsa -P ''
check_ok
fi
## 传私钥给主机B
if [ ! -d /usr/local/sbin/rsync_keys ]
then
mkdir /usr/local/sbin/rsync_keys
fi
cd /usr/local/sbin/rsync_keys
if [ -f rsync.expect ]
then
d=`date +%F-%T`
mv rsync.expect $d.expect
fi
#创建远程同步的expect文件
cat > rsync.expect <>/root/.ssh/authorized_keys \r"
expect "]*"
send "\[ -f /root/.ssh/authorized_keys \] || mkdir -p /root/.ssh/ \r"
send "\[ -f /root/.ssh/authorized_keys \] || mv /tmp/tmp.txt /root/.ssh/authorized_keys\r"
expect "]*"
send "chmod 700 /root/.ssh; chmod 600 /root/.ssh/authorized_keys\r"
expect "]*"
send "exit\r"
EOF
check_ok
/usr/bin/expect /usr/local/sbin/rsync_keys/rsync.expect $ip $password
echo "OK,this script is successful. ssh $ip to test it" 自动封/解封ip
需求背景:
discuz论坛,每天有很多注册机注册的用户,然后发垃圾广告帖子。虽然使用了一些插件但没有效果。分析访问日志,发现有几个ip访问量特别大,所以想到可以写个shell脚本,通过分析访问日志,把访问量大的ip直接封掉。
但是这个脚本很有可能误伤,所以还需要考虑到自动解封这些ip。
思路:
可以每分钟分析1次访问日志,设定一个阈值,把访问量大的ip用iptables封掉80端口
每20分钟检测一次已经被封ip的请求数据包数量,设定阈值,把没有请求的或者请求量很小的解封
参考代码:
#! /bin/bash
## To block the ip of bad requesting.
## Writen by aming 2017-11-18.
log="/data/logs/www.xxx.com.log"
tmpdir="/tmp/badip"
#白名单ip,不应该被封
goodip="27.133.28.101"
[ -d $tmpdir ] || mkdir -p $tmpdir
t=`date -d "-1 min" +%Y:%H:%M`
#截取一分钟以前的日志
grep "$t:" $log > $tmpdir/last_min.log
#把一分钟内日志条数大于120的标记为不正常的请求
awk '{print $1}' $tmpdir/last_min.log |sort -n |uniq -c |sort -n |tail |awk '$1>120 {print $2}'|grep -v "$good_ip"> $tmpdir/bad.ip
d3=`date +%M`
#每隔20分钟解封一次ip
if [ $d3 -eq "20" ] || [ $d3 -eq "40" ] || [ $d3 -eq "00" ]
then
/sbin/iptables -nvL INPUT|grep 'DROP' |awk '$1<10 {print $8}'>$tmpdir/good.ip
if [ -s $tmpdir/good.ip ]
then
for ip in `cat $tmpdir/good.ip`
do
/sbin/iptables -D INPUT -p tcp --dport 80 -s $ip -j DROP
d4=`date +%Y%m%d-%H:%M`
echo "$d4 $ip unblock" >>$tmpdir/unblock.ip
done
fi
#解封后,再把iptables的计数器清零
/sbin/iptables -Z INPUT
fi
if [ -s $tmpdir/bad.ip ]
then
for ip in `cat $tmpdir/bad.ip`
do
/sbin/iptables -A INPUT -p tcp --dport 80 -s $ip -j DROP
d4=`date +%Y%m%d-%H:%M`
echo "$d4 $ip block" >>$tmpdir/block.ip
done
fi
【脚本102】单机部署SpringBoot项目
有一台测试服务器,经常需要部署SpringBoot项目,手动部署太麻烦,于是写了个部署脚本
脚本代码:
#!/bin/bash
# git仓库路径
GIT_REPOSITORY_HOME=/app/developer/git-repository
# jar包发布路径
PROD_HOME=/prod/java-back
# 应用列表
APPS=(app1 app2 app3)
if [ ! -n "$1" ]
then
echo -e "请输入要发布的项目!"
exit
fi
# cd dir
for((i=0;i<${#APPS[@]};i++))
do
echo $1 ${APPS[i]}
if [ $1 = ${APPS[i]} ]
then
echo -e ===========Enter $1=============
cd ${GIT_REPOSITORY_HOME}/$1
break
fi
done
if [ `pwd` != ${GIT_REPOSITORY_HOME}/$1 ]
then
echo -e "输入的项目名没有找到!"
exit
fi
echo "==========git切换分之到master==============="
git checkout master
echo "==================git fetch======================"
git fetch
echo "==================git pull======================"
git pull
echo "===========选择线上环境编译并跳过单元测试===================="
mvn clean package -Dmaven.test.skip=true -Pprod
jar_path=${GIT_REPOSITORY_HOME}/$1/target/*-0.0.1-SNAPSHOT.jar
echo ${jar_path}
if [ -f ${jar_path} ]
then
# backup dest
echo -e "===========jar backup============="
mv ${PROD_HOME}/$1/*-0.0.1-SNAPSHOT.jar ${PROD_HOME}/$1/$1-0.0.1-SNAPSHOT.jar.back
# copy
echo "======拷贝编译出来的jar包拷贝到$PROD_HOME======="
if [ -d ${PROD_HOME}/$1 ]
then
/bin/cp ${GIT_REPOSITORY_HOME}/$1/target/*-0.0.1-SNAPSHOT.jar ${PROD_HOME}/$1
else
mkdir ${PROD_HOME}/$1
/bin/cp ${GIT_REPOSITORY_HOME}/$1/target/*-0.0.1-SNAPSHOT.jar ${PROD_HOME}/$1
fi
echo "============停止项目============="
jar_name=`jps |awk -F" " '{ print $2 }'| egrep ^$1.*jar$`
pid=`jps |grep ${jar_name} | awk -F" " '{ print $1 }'`
echo ${pid}
kill -15 ${pid}
echo "================sleep 10s========================="
for i in 1 2 3 4 5 6 7 8 9 10
do
echo ${i}"s"
sleep 1s
done
echo "============启动项目============="
nohup java -jar ${PROD_HOME}/$1/*-0.0.1-SNAPSHOT.jar > /dev/null 2>&1 &
echo -e "===========Deploy Success============="
else
echo -e "===========Deploy Error============="
fi