在腾讯,已经有很多产品已使用或者正在尝试使用istio来作为其微服务治理的基础平台。不过在使用istio时,也有一些对通信性能要求较高的业务会对istio的性能有一些担忧。由于envoy sidecar的引入,使两个微服务之间的通信路径变长,导致服务延时受到了一些影响,istio社区一直以来也有这方面的声音。基于这类抱怨,我们希望能够对这一通信过程进行优化,以更好的满足更多客户的需求。
首先,我们看一下istio数据面的通信模型,来分析一下为什么会对延时有这么大的影响。可以看到,相比于服务之间直接通信,在引入istio 之后,通信路径会有明显增加,主要包括多出了两次本地进程之间的tcp连接通信和用户态网络代理envoy对数据的处理。所以我们的优化也分为了两部分进行。
内核态转发优化
那么对于本地进程之间的通信优化,我们能做些什么呢?
其实在开源社区已经有了这方面的探索了。istio官方社区在2019年1月的时候已经有了这方面讨论,在文档里面提到了使用ebpf的技术来做socket转发的数据代理,使数据在socket层进行转发,而不需要再往下经过更底层的TCP/IP协议栈的一个处理,从而减少它在数据链路上的通信链路长度。
另外,网络开源项目cilium也在这方面有一个比较深入的实践,同样也是使用了ebpf的技术。不过在cilium中本地网络加速只是其中的一个模块,没有作为一个独立的服务进行开发实践,在腾讯云内部没法直接使用,这也促使了我们开发一个无依赖的解决方案。
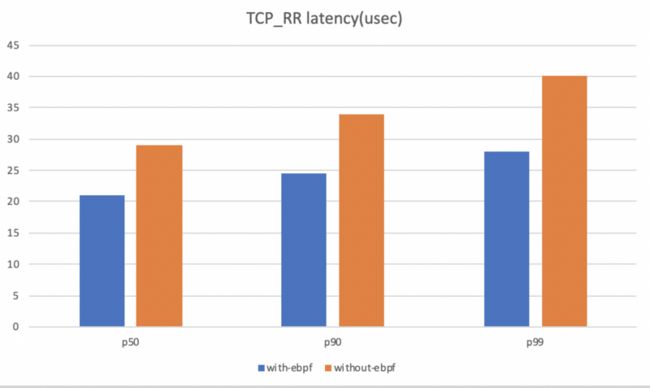
当然在初期的时候,我们也对ebpf的技术进行了一个验证,从验证结果中可以看到,在使用了ebpf的技术之后,它的延时大概有20%到30%的提升,说明ebpf的技术应用在本地通讯上还是有一定优化能力的。
简单介绍一下ebpf,看一下它是怎么做到加速本地通讯的。首先ebpf可以看作是一个运行在内核里面的虚拟机,用户编写的ebpf程序可以被加载到内核里面进行执行。内核的一个verify组件会保证用户的ebpf程序不会引发内核的crash,也就是可以保证用户的ebpf程序是安全的。目前ebpf程序主要用来追踪内核的函数调用以及安全等方面。下图可以看到,ebpf可以用在很多内核子系统当中做很多的调用追踪。
另外一个比较重要的功能,就是我们在性能优化的时候使用到的在网络上的一个能力,也就是下面提到的sockhash。sockhash本身是一个ebpf特殊的一个kv存储结构,主要被用作内核的一个socket层的代理。它的key是用户自定义的,而value是比较特殊的,它存储的value是内核里面一个socket对象。存储在sockhash中的socket在发送数据的时候,如果能够通过我们挂在sockhash当中的一个ebpf当中的程序找到接收方的socket,那么内核就可以帮助我们把发送端的数据直接拷贝到接收端socket的一个接收队列当中,从而可以跳过数据在更底层的处理,比如TCP/IP协议栈的处理。
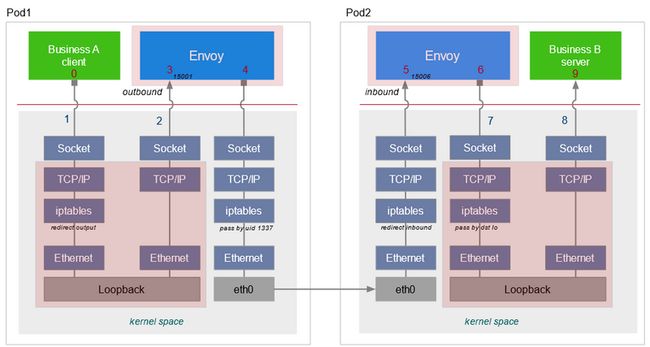
在sidecar中,socket是怎样被识别并存储在sockhash当中来完成一个数据拷贝的呢?我们需要分析一下数据链的本地通讯的流量特征。
首先从ingress来讲,ingress端的通信会比较简单一点,都是一个本地地址的通信。ingress端的envoy进程和用户服务进程之间通信,它的原地址和目的地址刚好是一一对应的。所以我们可以利用这个地址的四元组构造它的key,把它存储到sockhash当中。在发送数据的时候,根据这个地址信息反向构造这个key,从sockhash当中拿到接收端的socket返回给内核,这样内核就可以帮我们将这个数据直接拷贝给接收端的socket。
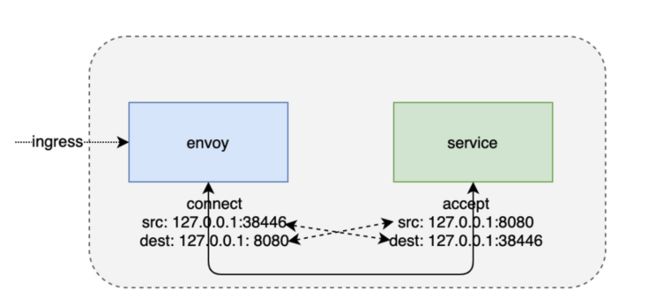
egress会稍微复杂一点,在一个egress端服务程序对外发出的请求被iptables规则重定向到了envoy监听的一个15001的端口。在这里,发起方的源地址和接收方的目的地址是一一对应的,但是发起方的目的地址和接收端的源地址有了一个变化,主要是由于iptables对地址有一个重写。所以我们在存储到sockhash中的时候,需要对这部分信息进行一个处理。由于istio的特殊性,直接可以把它改写成envoy所监听的一个本地服务地址。这样再存储到sockhash当中,它们的地址信息还是可以反向一一对应的。所以在查找的时候,还是可以根据一端的socket地址信息查找到另一端的socket,达到数据拷贝的目的。
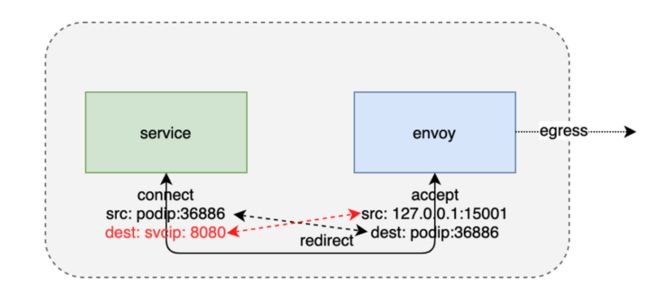
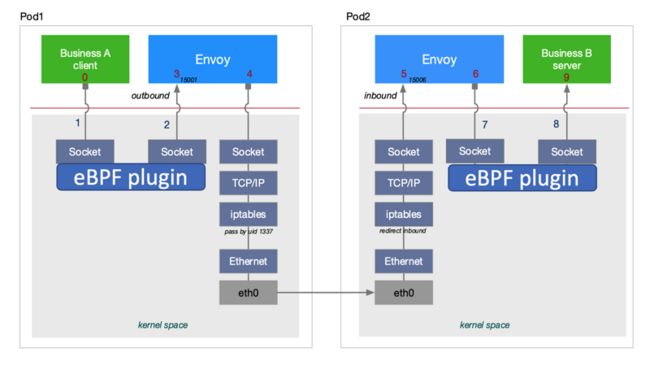
经过对ebpf加速原理的分析,我们开发出来一个ebpf的插件,这个插件可以不依赖于集群本身的网络模式,使用daemonset方式部署到k8s集群的各个节点上。其中的通信效果如下图所示,本地进程的一个通信在socket层直接被ebpf拦截以后,就不会再往下发送到TCPIP协议栈了,直接在socket层就进行了一个数据拷贝,减少了数据链路上的一个处理流程
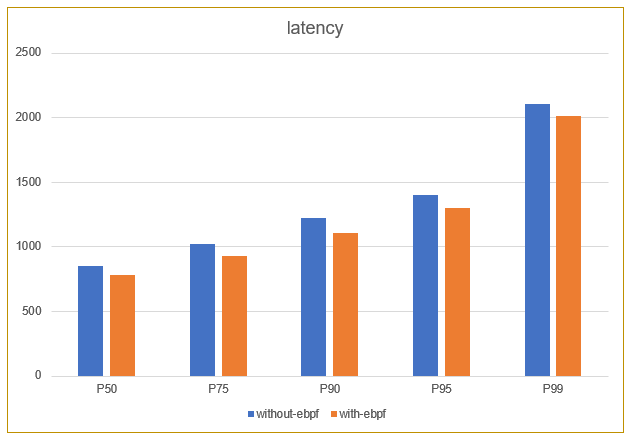
下面是对效果的一个测试,从整体来看,它的延时有大概5到8%的延时提升,其实提升的幅度不是很大,主要原因其实在整个通信的流程当中,内核态的一个处理占整个通信处理的时间,延时其实是比较少的一部分,所以它的提升不是特别明显。
另外ebpf还有一些缺陷,比如它对内核版本的要求是在4.18版本之后才有sockhash这个特性。另外sockhash本身还有一些bug,我们在测试当中也发现了一些bug,并且把它提交到社区进行解决。
Envoy 性能研究与优化
前面介绍了对istio数据面对流量在内核的处理所进行的一些优化。在istio数据面的性能问题上,社区注意到比较多的是在内核态有一个明显的转发流程比较长的问题,因此提出了使用eBPF进行优化的方案,但是在Envoy上面没有太多的声音。虽然Envoy本身是一个高性能的网络代理,但我们还是无法确认Envoy本身的损耗是否对性能造成了影响,所以我们就兵分两路,同时在Envoy上面进行了一些研究。
首先什么是Envoy?Envoy是为分布式环境而生的高性能网络代理,可以说基本上是作为服务网格的通用数据平面被设计出来的。Envoy提供不同层级的filter架构,如listenerFilter、networkFilter以及HTTPFilter,这使envoy具有非常好的可扩展性。Envoy还具有很好的可观察性,内置有stats、tracing、logging这些子系统,可以让我们更容易地对系统进行监控。
进行istio数据面优化的时候,我们面对的第一个问题是Envoy在istio数据面中给消息转发增加了多少延时?Envoy本身提供的内置指标是很难反映Envoy本身的性能。因此,我们通过修改Envoy源码,在Envoy处理消息的开始与结束的位置进行打点,记录时间戳,可以获得Envoy处理消息的延时数据。Envoy是多线程架构,在打点时我们考虑了性能和线程安全问题:如何高效而又准确地记录所有消息的处理延时,以方便后续的进行分析?这是通过如下方法做到的:
a. 给压测消息分配唯一数字ID;
b. 在Envoy中预分配一块内存用于保存打点数据,其数据类型是一个结构体数组,每个元素都是同一条消息的打点数据;
c. 提取消息中的数字ID当作时间戳记录的下标,将时间戳记录到预分配的内存的固定位置。通过这种方式,我们安全高效地实现了Envoy内的打点记录(缺点是需要修改Envoy以及压测工具)。
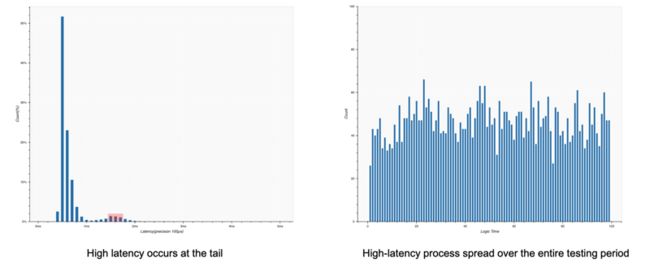
经过离线分析,我们发现了Envoy内消息处理延时的一些分布特征。左图是对Envoy处理延时与消息数量分布图,横轴是延时,纵轴是消息数量。可以看到在高延时部份,消息数量有异常增加的现象,这不是典型的幂率分布。进一步对高延时部份进行分析后发现,这些高延时消息均匀地分布于整个测试期间(如上图右所示)。 根据我们的经验,这通常是Envoy内部转发消息的worker在周期性的执行一些消耗CPU的任务,导致有一部分消息没办法及时转发而引起的。
深入研究Envoy在istio数据面的功能实现后,我们发现mixer遥测可能是导致这个问题的根本原因。Mixer是istio老版本(1.4及以前)实现遥测和策略检查功能的一个组件。在数据面的Envoy中,Mixer会提取所有消息的属性,然后批量压缩上报到mixer server,而属性的提取和压缩是一个高CPU的消耗的操作,这会引起延时数据分析中得到的结果:高延时消息转发异常增多。
在确定了原因之后,我们对Envoy的架构作了一些改进,给它增加了执行非关键任务的AsyncWorker线程,称为异步任务线程。通过把遥测的逻辑拆分出来放到了AsyncWorker线程中去执行,就解决了worker线程被阻塞的问题,进而可以降低envoy转发消息的延时。
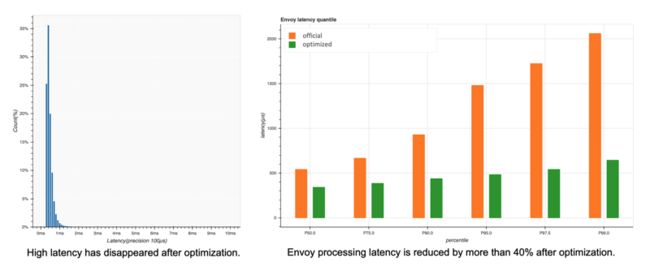
进行架构优化之后,我们也做了对比测试,上图左测是延时与消息数量图,可以看到它高延时部分得到明显的改善。上图右可以看出Envoy整体的延时降低了40%以上。
优化Envoy架构给我们带来了第一手的经验,首先CPU是影响Istio数据面性能的关键资源,它的瓶颈主要出现在CPU上面,而不是网络IO操作。第二,我们对Envoy进行架构优化,可以降低延时,但是没有解决根本问题,因为CPU的使用没有降低,只是遥测逻辑转移到另外的线程中执行,降低Envoy转发消息的延时。优化CPU使用率才是数据面优化的核心。第三点,Envoy的不同组件当中,mixer消化掉了30%左右的CPU,而遥测是mixer的核心功能,因此后续遥测优化就变成了优化的重要方向。
怎么进行遥测优化呢?其实mixer实现遥测是非常复杂的一套架构,使用Istio mixer遥测的人都深有体会,幸好istio新版本中,不止对istio的控制面作了大的调整,在数据面mixer也同样被移除了,意味着Envoy中高消耗的遥测就不会存在了,我们是基于istio在做内部的service mesh,从社区得到这个消息之后,我们也快速跟进,引入适配新的架构。
没有Mixer之后,遥测是如何实现的。Envoy提供了使用wasm对其进行扩展的方式,以保持架构的灵活性。而istio社区基于Wasm的扩展开发了一个stats extension扩展,实现了一个新的遥测方案。与mixer遥测相比,这个stats extension不再上报全量数据到mixer server,只是在Envoy内的stats子系统中生成遥测指标。遥测系统拉取Envoy的指标,就可以获得整个遥测数据,会大大降低遥测在数据面的性能消耗。
然后我们对istio 1.5使用Wasm的遥测,做了一个性能的测试。发现整个Envoy代理在同样测试条件下,它的CPU降低10%,而使用mixer的遥测其实占用了30%的CPU,里面大部分逻辑是在执行遥测。按我们的理解,Envoy至少应该有20%的CPU下降,但是实际效果只有10%左右,这是为什么呢?
新架构下我们遇到了新的问题。我们对新架构进行了一些实现原理和技术细节上的分析,发现Envoy使用Wasm的扩展方式,虽然带来了灵活性和可扩展性,但是对性能有一定的影响。
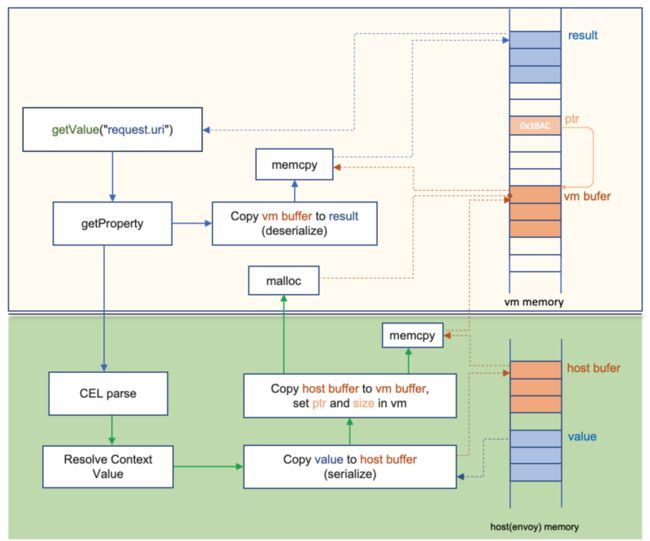
首先,Wasm扩展机制跟Envoy host环境是通过内存拷贝的方式进行通信,这是Wasm虚拟机的隔离性机制决定的。Envoy为了保持架构灵活性的同时保证性能,使设计了一个非Wasm虚拟机运行扩展(如stats extension)的模式,即NullVM模式,它是一个假的Wasm虚拟机,实际上运行的扩展还是被编译在Envoy内部,但它也逃离不掉Wasm架构带来的内存拷贝影响。
其次,在实现extension与Envoy的通信时,一个属性的获取要经过多次的内存拷贝,是一个非常复杂的过程。如上图所示,获取request.url这个属性需要在Envoy的内存和Wasm虚拟机内存之间进行一个复杂的拷贝操作,这种方式的消耗远大于通过引用或指针提取属性。
第三,在实现遥测的时候,有大量的属性需要获取,通常有十几二十个属性,因此Wasm扩展带来的总体额外损耗非常可观。
另外,Wasm实现的遥测功能还需要另外一个叫做metadata_exchange扩展的支持。metadata_exchange用来获得调用对端的一些节点信息,而metadata_exchange扩展运行在另外一个虚拟机当中,通过Envoy的Filter state机制与stats 扩展进行通信,进一步增加了遥测的额外消耗。
那么如何去优化呢?简单对Wasm插件优化是没有太大帮助,因为它的底层Wasm机制已经决定了它有不少的性能损耗,所以我们就开发了一个新的遥测插件tstats。
tstats使用Envoy原生的扩展方式开发。在tstats扩展内部,实现了遥测和metadata_exchange的结合,消除了Wasm带来的性能弊端。Tstats遥测与社区遥测兼容,生成相同的指标,tstats基于istio控制面的EnvoyFilter CRD进行部署,用户可以平滑升级,当用户发现tstats的功能没有满足需求或者出现一些问题时,也可以切换使用到社区提供的遥测扩展。
在tstats扩展还优化了遥测指标的计算过程。在计算指标的时候有许多维度信息需要填充,(目前大指标有二十几个维度的填充),这其实是一个比较复杂的操作,其实,有很多指标的维度都是节点信息,就是发起服务调用的客户端和服务端的一些信息,如服务名、版本等等。其实我们可以将它进行一些缓存,加速这些指标的计算。

经过优化之后,对比tstats遥测和官方的基于Wasm的遥测的性能,我们发现CPU降低了10到20%,相对于老版本的mixer来说降低了20%以上,符合了我们对envoy性能调研的一个预期。上图右可以看到在延时上有一个明显的降低,即使在P99在不同的QPS下,也会有20%到40%的总体降低(这个延时是使用echo service做End-to-End压测得到的)。
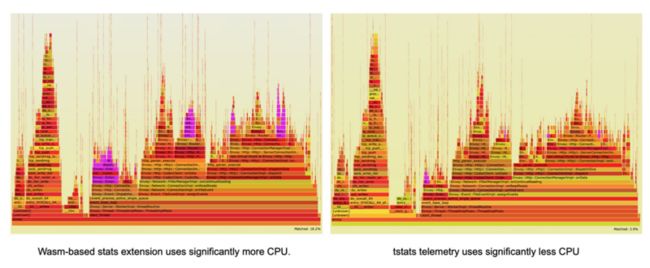
使用火焰图重新观察一下Envoy内部的CPU使用分布,我们发现tstats遥测插件占用CPU的比例明显更少,而使用wasm的遥测插件有一个明显的CPU占用来实现遥测,这也证明了tstats优化是有效果的。
总结
前面我们分享了在优化istio数据面过程当中,在内核态和Envoy内探索的一些经验。这是我们优化的主要内容,当然还有一些其它的优化点,例如:
- 使用XDP进行加速,因为由于istio proxy的引入,Pod和Pod之间的访问实际上是不需要经过主机上的iptables规则处理。基于这一点,我们可以利用XDP的快速转发能力直接将包发送到对应的网卡,完成快速转发。
- 链路跟踪在Envoy中消耗的CPU也比较可观,即使在1%的采样率下也消耗了8%的CPU,是可以进行优化的,所以我们也在做这部分的工作。
- Envoy内部有非常多的内置统计,Istio的一些指标与Envoy内置的指标有一部分重复,可以考虑进行一些裁剪优化,或者增加一些特性开关,当不需要使用的时候对它进行关闭。
总体来说,Istio数据面性能的损耗分布在各个环节,并不是单独的内核态消息转发或者用户态Envoy就消耗特别多。在使用Mixer架构的Istio版本中,Envoy内一个明显的性能热点, mixer遥测,这也在版本迭代中逐步解决了。
最后,在进行Istio数据面优化的时候需要综合考虑各个环节,这也是我们目前总体上对Istio数据面性能的一个认识,通过这次分享,希望社区和大家都会在更注重Istio数据面的性能,帮助ServiceMesh更好地落地。腾讯云基于Istio提供了云上ServiceMesh产品TCM,大家有兴趣可以来体验。
问题
- 怎么判断项目需要使用服务网格?
服务网格解决的最直接的场景就是你的服务需要进行微服务治理,但是你们之前可能有多个技术栈,没有一个统一的技术框架,比如没有使用SpringCloud等。缺少微服务治理能力,但是又想最低成本获得链路跟踪、监控、流量管理、熔断等这样的能力,这个时候可以使用服务网格实现。
- 这次优化有没有考虑到回归到社区?
其实我们也考虑过这个问题,我们在进行mixer优化的时候,当时考虑到需要对Envoy做比较多的改动,并且了解到社区规划从架构中去掉mixer,所以这个并没有回归到社区,异步任务线程架构的方案目前保留在内部。对于第二点开发的tstats扩展,它的功能和社区的遥测是一样的,如果提交到社区我们觉得功能会有重叠,所以没有提交给社区。
- 服务网格数据调优给现在腾讯的业务带来了哪些改变?
我想这里主要还是可观测性上面吧,之前很多的服务和开发,他们的监控和调用面的上面做得都是差强人意的,但是他们在业务的压力之下,其实是没有很完善的方式、没有很大的动力快速实现这些服务治理的功能,使用istio之后,有不少团队都获得了这样的能力,他们给我们的反馈都是比较好的。
- 在减少延迟方面,腾讯做了哪些调整,服务网格现在是否已经成熟,对开发者是否友好?
在延迟方面,我们对性能的主要探索就是今天分享的内容,我们最开始就注意到延时比较高,然后在内核做了相应的优化,并且研究了在Envoy内为什么会有这些延迟。所以我们得出的结论,CPU是核心的资源,需要尽量降低数据面Proxy代理对CPU的使用,这是我们做所有优化最核心的出发点,当CPU降下来,延时就会降低。服务网格现在是否已经成熟。我觉得不同的人有不同答案,因为对一些团队,目前他们使用服务网格使用得很好的,因为他们有多个技术栈,没有统一的框架。他们用了之后,获得这些流量的管理和监控等等能力,其实已经满足了他们的需求。但是对一些成熟的比较大的服务,数据面性能上面可能会有一些影响,这个需要相应的团队进行仔细的评估才能决定,并没办法说它一定就是能在任何场景下可以直接替换现有的各个团队的服务治理的方式。
- 为什么不直接考虑1.6?
因为我们做产品化的时候,周期还是比较长的。istio社区发版本的速度还是比较快的,我们还在做1.5产品化的时候,可能做着做着,istio1.6版本就发出来了,所以我们也在不停更新跟迭代,一直在跟随社区,目前主要还是在1.5版本上。其实我们在1.4的时候就开始做现在的产品了。
- 公司在引入多种云原生架构,包括SpringCloud和Dubbo,作为运维,有必要用Istio做服务治理吗?另外SpringCloud和Dubbo这种架构迁移到Istio,如何调整?
目前SpringCloud和Dubbo都有不错的服务治理功能,如果没有非常紧迫的需求,比如你们又需要引入新的服务并且用别的语言实现,我觉得继续使用这样的框架,可能引入istio没有太大的优势。但是如果考虑进行更大规模的服务治理,包括融合SpringCloud和Dubbo,则可以考虑使用istio进行一个合并的,但是这个落地会比较复杂。那么SpringCloud和Dubbo迁移到Istio如何调整?目前最复杂的就是他们的服务注册机制不一样,服务注册模型不一样。我们之前内部也有在预研如何提供一个统一的服务注册模型,以综合Istio和其它技术框架如SpringCloud的服务注册和服务发现,以及SpringCloud如何迁移进来。这个比较复杂,需要对SDK做一些改动,我觉得可以下来再进行交流。
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!!