Python 之 C/C++ 混合编程
一、问题
Python模块和C/C++的动态库间相互调用在实际的应用中会有所涉及,在此作一总结。
二、Python调用C/C++
1、Python调用C动态链接库
Python调用C库比较简单,不经过任何封装打包成so,再使用python的ctypes调用即可。
(1)C语言文件:pycall.c
/***gcc -o libpycall.so -shared -fPIC pycall.c*/
#include
#include
int foo(int a, int b)
{
printf("you input %d and %d\n", a, b);
return a+b;
}
(2)gcc编译生成动态库libpycall.so:gcc -o libpycall.so -shared -fPIC pycall.c。使用g++编译生成C动态库的代码中的函数或者方法时,需要使用extern "C"来进行编译。
(3)Python调用动态库的文件:pycall.py
import ctypes
ll = ctypes.cdll.LoadLibrary
lib = ll("./libpycall.so")
lib.foo(1, 3)
print '***finish***'
(4)运行结果:
2、Python调用C++(类)动态链接库
需要extern "C"来辅助,也就是说还是只能调用C函数,不能直接调用方法,但是能解析C++方法。不是用extern “C”,构建后的动态链接库没有这些函数的符号表。
(1)C++类文件:pycallclass.cpp
#include
using namespace std;
class TestLib
{
public:
void display();
void display(int a);
};
void TestLib::display() {
cout<<"First display"< (2)g++编译生成动态库libpycall.so:g++ -o libpycallclass.so -shared -fPIC pycallclass.cpp。
**(3)Python调用动态库的文件:**pycallclass.py
import ctypes
so = ctypes.cdll.LoadLibrary
lib = so("./libpycallclass.so")
print 'display()'
lib.display()
print 'display(100)'
lib.display_int(100)
(4)运行结果:
3、Python调用C/C++可执行程序
(1)C/C++程序:main.cpp
#include
using namespace std;
int test()
{
int a = 10, b = 5;
return a+b;
}
int main()
{
cout<<"---begin---"< (2)编译成二进制可执行文件:g++ -o testmain main.cpp。
(3)Python调用程序:main.py
import commands
import os
main = "./testmain"
if os.path.exists(main):
rc, out = commands.getstatusoutput(main)
print 'rc = %d, \nout = %s' % (rc, out)
print '*'*10
f = os.popen(main)
data = f.readlines()
f.close()
print data
print '*'*10
os.system(main)
(4)运行结果:
4、扩展Python(C++为Python编写扩展模块)
所有能被整合或导入到其它python脚本的代码,都可以被称为扩展。可以用Python来写扩展,也可以用C和C++之类的编译型的语言来写扩展。Python在设计之初就考虑到要让模块的导入机制足够抽象。抽象到让使用模块的代码无法了解到模块的具体实现细节。Python的可扩展性具有的优点:方便为语言增加新功能、具有可定制性、代码可以实现复用等。
为 Python 创建扩展需要三个主要的步骤:创建应用程序代码、利用样板来包装代码和编译与测试。
(1)创建应用程序代码
#include
#include
#include
int fac(int n)
{
if (n < 2) return(1); /* 0! == 1! == 1 */
return (n)*fac(n-1); /* n! == n*(n-1)! */
}
char *reverse(char *s)
{
register char t, /* tmp */
*p = s, /* fwd */
*q = (s + (strlen(s) - 1)); /* bwd */
while (p < q) /* if p < q */
{
t = *p; /* swap & move ptrs */
*p++ = *q;
*q-- = t;
}
return(s);
}
int main()
{
char s[BUFSIZ];
printf("4! == %d\n", fac(4));
printf("8! == %d\n", fac(8));
printf("12! == %d\n", fac(12));
strcpy(s, "abcdef");
printf("reversing 'abcdef', we get '%s'\n", \
reverse(s));
strcpy(s, "madam");
printf("reversing 'madam', we get '%s'\n", \
reverse(s));
return 0;
}
上述代码中有两个函数,一个是递归求阶乘的函数fac();另一个reverse()函数实现了一个简单的字符串反转算法,其主要目的是修改传入的字符串,使其内容完全反转,但不需要申请内存后反着复制的方法。
(2)用样板来包装代码
接口的代码被称为“样板”代码,它是应用程序代码与Python解释器之间进行交互所必不可少的一部分。样板主要分为4步:a、包含Python的头文件;b、为每个模块的每一个函数增加一个型如PyObject* Module_func()的包装函数;c、为每个模块增加一个型如PyMethodDef ModuleMethods[]的数组;d、增加模块初始化函数void initModule()。
#include
#include
#include
int fac(int n)
{
if (n < 2) return(1);
return (n)*fac(n-1);
}
char *reverse(char *s)
{
register char t,
*p = s,
*q = (s + (strlen(s) - 1));
while (s && (p < q))
{
t = *p;
*p++ = *q;
*q-- = t;
}
return(s);
}
int test()
{
char s[BUFSIZ];
printf("4! == %d\n", fac(4));
printf("8! == %d\n", fac(8));
printf("12! == %d\n", fac(12));
strcpy(s, "abcdef");
printf("reversing 'abcdef', we get '%s'\n", \
reverse(s));
strcpy(s, "madam");
printf("reversing 'madam', we get '%s'\n", \
reverse(s));
return 0;
}
#include "Python.h"
static PyObject *
Extest_fac(PyObject *self, PyObject *args)
{
int num;
if (!PyArg_ParseTuple(args, "i", &num))
return NULL;
return (PyObject*)Py_BuildValue("i", fac(num));
}
static PyObject *
Extest_doppel(PyObject *self, PyObject *args)
{
char *orig_str;
char *dupe_str;
PyObject* retval;
if (!PyArg_ParseTuple(args, "s", &orig_str))
return NULL;
retval = (PyObject*)Py_BuildValue("ss", orig_str,
dupe_str=reverse(strdup(orig_str)));
free(dupe_str); #防止内存泄漏
return retval;
}
static PyObject *
Extest_test(PyObject *self, PyObject *args)
{
test();
return (PyObject*)Py_BuildValue("");
}
static PyMethodDef
ExtestMethods[] =
{
{ "fac", Extest_fac, METH_VARARGS },
{ "doppel", Extest_doppel, METH_VARARGS },
{ "test", Extest_test, METH_VARARGS },
{ NULL, NULL },
};
void initExtest()
{
Py_InitModule("Extest", ExtestMethods);
}
Python.h头文件在大多数类Unix系统中会在/usr/local/include/python2.x或/usr/include/python2.x目录中,系统一般都会知道文件安装的路径。
增加包装函数,所在模块名为Extest,那么创建一个包装函数叫Extest_fac(),在Python脚本中使用是先import Extest,然后调用Extest.fac(),当Extest.fac()被调用时,包装函数Extest_fac()会被调用,包装函数接受一个 Python的整数参数,把它转为C的整数,然后调用C的fac()函数,得到一个整型的返回值,最后把这个返回值转为Python的整型数做为整个函数调用的结果返回回去。其他两个包装函数Extest_doppel()和Extest_test()类似。
从Python到C的转换用PyArg_Parse系列函数,int PyArg_ParseTuple():把Python传过来的参数转为C;int PyArg_ParseTupleAndKeywords()与PyArg_ParseTuple()作用相同,但是同时解析关键字参数;它们的用法跟C的sscanf函数很像,都接受一个字符串流,并根据一个指定的格式字符串进行解析,把结果放入到相应的指针所指的变量中去,它们的返回值为1表示解析成功,返回值为0表示失败。从C到Python的转换函数是PyObject Py_BuildValue():把C的数据转为Python的一个对象或一组对象,然后返回之;Py_BuildValue的用法跟sprintf很像,把所有的参数按格式字符串所指定的格式转换成一个Python的对象。
C与Python之间数据转换的转换代码:
为每个模块增加一个型如PyMethodDef ModuleMethods[]的数组,以便于Python解释器能够导入并调用它们,每一个数组都包含了函数在Python中的名字,相应的包装函数的名字以及一个METH_VARARGS常量,METH_VARARGS表示参数以tuple形式传入。 若需要使用PyArg_ParseTupleAndKeywords()函数来分析命名参数的话,还需要让这个标志常量与METH_KEYWORDS常量进行逻辑与运算常量 。数组最后用两个NULL来表示函数信息列表的结束。
所有工作的最后一部分就是模块的初始化函数,调用Py_InitModule()函数,并把模块名和ModuleMethods[]数组的名字传递进去,以便于解释器能正确的调用模块中的函数。
(3)编译
为了让新Python的扩展能被创建,需要把它们与Python库放在一起编译,distutils包被用来编译、安装和分发这些模块、扩展和包。
创建一个setup.py 文件,编译最主要的工作由setup()函数来完成:
#!/usr/bin/env python
from distutils.core import setup, Extension
MOD = 'Extest'
setup(name=MOD, ext_modules=[Extension(MOD, sources=['Extest2.c'])])
Extension()第一个参数是(完整的)扩展的名字,如果模块是包的一部分的话,还要加上用’.'分隔的完整的包的名字。上述的扩展是独立的,所以名字只要写"Extest"就行;sources参数是所有源代码的文件列表,只有一个文件Extest2.c。setup需要两个参数:一个名字参数表示要编译哪个内容;另一个列表参数列出要编译的对象,上述要编译的是一个扩展,故把ext_modules参数的值设为扩展模块的列表。
运行setup.py build命令就可以开始编译我们的扩展了,提示部分信息:
creating build/lib.linux-x86_64-2.6
gcc -pthread -shared build/temp.linux-x86_64-2.6/Extest2.o -L/usr/lib64 -lpython2.6 -o build/lib.linux-x86_64-2.6/Extest.so
(4)导入和测试
你的扩展会被创建在运行setup.py脚本所在目录下的build/lib.*目录中,可以切换到那个目录中来测试模块,或者也可以用命令把它安装到Python中:python setup.py install,会提示相应信息。
测试模块:
(5)引用计数和线程安全
Python对象引用计数的宏:Py_INCREF(obj)增加对象obj的引用计数,Py_DECREF(obj)减少对象obj的引用计数。Py_INCREF()和Py_DECREF()两个函数也有一个先检查对象是否为空的版本,分别为Py_XINCREF()和Py_XDECREF()。
编译扩展的程序员必须要注意,代码有可能会被运行在一个多线程的Python环境中。这些线程使用了两个C宏Py_BEGIN_ALLOW_THREADS和Py_END_ALLOW_THREADS,通过将代码和线程隔离,保证了运行和非运行时的安全性,由这些宏包裹的代码将会允许其他线程的运行。
三、C/C++调用Python
C++可以调用Python脚本,那么就可以写一些Python的脚本接口供C++调用了,至少可以把Python当成文本形式的动态链接库,
需要的时候还可以改一改,只要不改变接口。缺点是C++的程序一旦编译好了,再改就没那么方便了。
(1)Python脚本:pytest.py
#test function
def add(a,b):
print "in python function add"
print "a = " + str(a)
print "b = " + str(b)
print "ret = " + str(a+b)
return
def foo(a):
print "in python function foo"
print "a = " + str(a)
print "ret = " + str(a * a)
return
class guestlist:
def __init__(self):
print "aaaa"
def p():
print "bbbbb"
def __getitem__(self, id):
return "ccccc"
def update():
guest = guestlist()
print guest['aa']
#update()
(2)C++代码:
/**g++ -o callpy callpy.cpp -I/usr/include/python2.6 -L/usr/lib64/python2.6/config -lpython2.6**/
#include
int main(int argc, char** argv)
{
// 初始化Python
//在使用Python系统前,必须使用Py_Initialize对其
//进行初始化。它会载入Python的内建模块并添加系统路
//径到模块搜索路径中。这个函数没有返回值,检查系统
//是否初始化成功需要使用Py_IsInitialized。
Py_Initialize();
// 检查初始化是否成功
if ( !Py_IsInitialized() ) {
return -1;
}
// 添加当前路径
//把输入的字符串作为Python代码直接运行,返回0
//表示成功,-1表示有错。大多时候错误都是因为字符串
//中有语法错误。
PyRun_SimpleString("import sys");
PyRun_SimpleString("print '---import sys---'");
PyRun_SimpleString("sys.path.append('./')");
PyObject *pName,*pModule,*pDict,*pFunc,*pArgs;
// 载入名为pytest的脚本
pName = PyString_FromString("pytest");
pModule = PyImport_Import(pName);
if ( !pModule ) {
printf("can't find pytest.py");
getchar();
return -1;
}
pDict = PyModule_GetDict(pModule);
if ( !pDict ) {
return -1;
}
// 找出函数名为add的函数
printf("----------------------\n");
pFunc = PyDict_GetItemString(pDict, "add");
if ( !pFunc || !PyCallable_Check(pFunc) ) {
printf("can't find function [add]");
getchar();
return -1;
}
// 参数进栈
*pArgs;
pArgs = PyTuple_New(2);
// PyObject* Py_BuildValue(char *format, ...)
// 把C++的变量转换成一个Python对象。当需要从
// C++传递变量到Python时,就会使用这个函数。此函数
// 有点类似C的printf,但格式不同。常用的格式有
// s 表示字符串,
// i 表示整型变量,
// f 表示浮点数,
// O 表示一个Python对象。
PyTuple_SetItem(pArgs, 0, Py_BuildValue("l",3));
PyTuple_SetItem(pArgs, 1, Py_BuildValue("l",4));
// 调用Python函数
PyObject_CallObject(pFunc, pArgs);
//下面这段是查找函数foo 并执行foo
printf("----------------------\n");
pFunc = PyDict_GetItemString(pDict, "foo");
if ( !pFunc || !PyCallable_Check(pFunc) ) {
printf("can't find function [foo]");
getchar();
return -1;
}
pArgs = PyTuple_New(1);
PyTuple_SetItem(pArgs, 0, Py_BuildValue("l",2));
PyObject_CallObject(pFunc, pArgs);
printf("----------------------\n");
pFunc = PyDict_GetItemString(pDict, "update");
if ( !pFunc || !PyCallable_Check(pFunc) ) {
printf("can't find function [update]");
getchar();
return -1;
}
pArgs = PyTuple_New(0);
PyTuple_SetItem(pArgs, 0, Py_BuildValue(""));
PyObject_CallObject(pFunc, pArgs);
Py_DECREF(pName);
Py_DECREF(pArgs);
Py_DECREF(pModule);
// 关闭Python
Py_Finalize();
return 0;
}
(3)C++编译成二进制可执行文件:g++ -o callpy callpy.cpp -I/usr/include/python2.6 -L/usr/lib64/python2.6/config -lpython2.6,编译选项需要手动指定Python的include路径和链接接路径(Python版本号根据具体情况而定)。
(4)运行结果:
四 使用SWIG,来生成独立的wrap文件
SWIG是个帮助使用C或者C++编写的软件能与其它各种高级编程语言进行嵌入联接的开发工具。
SWIG能应用于各种不同类型的语言包括常用脚本编译语言例如Perl, PHP, Python, Tcl, Ruby, PHP,C#,Java,R等。
操作上,是针对c/c++程序编写独立的接口声明文件(通常很简单),swig会分析c/c++源程序自动分析接口要如何包装。在指定目标语言后,swig会生成额外的包装源码文件。编译so库时,把包装文件一起编译、连接即可。
看个c代码例子:
int system(const char* command)
{
sts = system(command);
if (sts < 0) {
return NULL;
}
return sts;
}
c源码中去掉适配python的包装,仅定义system函数本身,c代码通用性更好。
然后编写swig接口声明文件spam.i:
%module spam
%{
#include "spam.h"
%}
%include "spam.h"
%include "typemaps.i"
int system(const char* INPUT);
这是一段语言无关的模块声明,要创建一个叫spam的模块,对system做一个声明,主要是声明参数作为入参使用。然后执行swig编译程序:
>swig -c++ -python spam.i
swig会生成spam_wrap.cxx和spam.py两个文件。先看spam_wrap.cxx,这个生成的文件很长,但关键的就是对函数的包装:
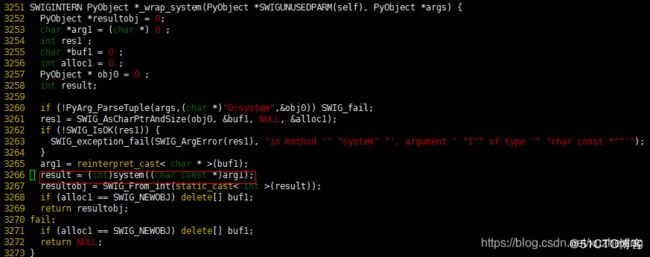
包装函数传入的还是PyObejct对象,内部进行了类型转换,最终调了源码中的system函数。
生成的了另一个spam.py实际上是对so库又用python包装了一层(实际比较多余):

这里使用_spam模块,这里实际上是把扩展命名为了_spam。关于swig在python上的应用可以参见:http://www.swig.org/Doc1.3/Python.html
下面就是编译和安装python 模块,Python提供了distutils module,可以很方便的编译安装python的module。像下面这样写一个安装脚本setup.py:
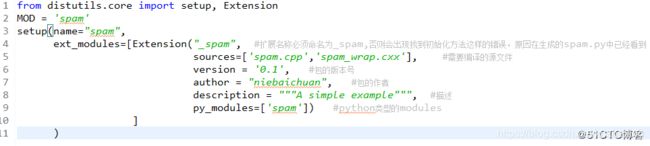
执行 python setup.py build,即可以完成编译,程序会创建一个build目录,下面有编译好的so库。so库放在当前目录下,其实Python就可以通过import来加载模块了。当然也可以用 python setup.py install 把模块安装到语言的扩展库——site-packages目录中。关于build python扩展,可以参考https://docs.python.org/2/extending/building.html#building
五 混合编程性能分析
混合编程的使用场景中,很重要一个就是性能攸关。那么这小节将通过几个小实验验证下混合编程的性能如何,或者说怎样写程序能发挥好混合编程的性能优势。
我们使用冒泡排序算法来验证性能。
1)实验一 使用冒泡程序验证python和c/c++程序的性能差距
python版冒泡程序:
def bubble(arr,length):
j = length - 1
while j >= 0:
i = 0
while i < j:
if arr[i] > arr[i+1]:
tmp = arr[i+1]
arr[i+1] = arr[i]
arr[i] = tmp
i += 1
j -= 1
c语言版冒泡排序
void bubble(int* arr,int length){
int j = length - 1;
int i;
int tmp;
while(j >= 0){
i = 0;
while(i < j){
if(arr[i] > arr[i+1]){
tmp = arr[i+1];
arr[i+1] = arr[i];
arr[i] = tmp;
}
i += 1;
}
j -= 1;
}
}
使用一个长度为100内容固定的数组,反复排序10000次(每次排序后,再把数组恢复成原始序列),记录执行时间:
在相同的机器上多次执行,Python版执行时间是10.3s左右,而c语言版本(未使用任何优化编译参数)执行时间只有0.29s左右。相比之下python的性能的确差很多(主要是python中list的操作跟c的数组相比,效率差非常多),但python中很多扩展都是c语言写的,目的就是为了提升效率,python用于数据分析的numpy库就拥有不错的性能。下个实验就验证,如果python使用c语言版本的冒泡排序扩展库,性能会提升多少。
2)实验二 python语言使用ctypes方式调用
这里直接使用c_int来定义了数组对象,这也节省了调用时数据类型转换的开销:
import time
from ctypes import *
IntArray100 = c_int * 100
arr = IntArray100(87,23,41, 3, 2, 9,10,23,0,21,5,15,93, 6,19,24,18,56,11,80,34, 5,98,33,11,25,99,44,33,78,
52,31,77, 5,22,47,87,67,46,83, 89,72,34,69, 4,67,97,83,23,47, 69, 8, 9,90,20,58,20,13,61,99,7,22,55,11,30,56,87,29,92,67,
99,16,14,51,66,88,24,31,23,42,76,37,82,10, 8, 9, 2,17,84,32,66,77,32,17, 5,68,86,22, 1, 0)
... ...
if __name__ == "__main__":
libbubble = CDLL('libbubble.so')
time1 = time.time()
for i in xrange(100000):
libbubble.initArr(arr1,arr,100)
libbubble.bubble(arr1,100)
time2 = time.time()
print time2 - time1
再次执行:
为了减少误差,把循环增加到10万次,结果c原生程序使用优化参数编译后用时0.65s左右。python使用c扩展后(相同编译参数)执行仅需2.3s左右。
3)实验三 在c语言中使用PyObject处理入参
这种方式是在python中依然使用list装入待排序数列,在c函数中把list赋值给数组,再进行排序,排好序后,再对原始list赋值。循环排序10万次,执行用时1.0s左右。
4) 实验四 使用swig来包装c方法
在接口文件中声明%array_class(int,intArray);然后在Python中使用initArray来作为数组,同样修改成10万次排序。python版本的程序(相同编译参数)执行仅需0.7s左右,比c原生程序慢大概7%。
六、总结
(1)Python和C/C++的相互调用仅是测试代码,具体的项目开发还得参考Python的API文档。
(2)两者交互,C++可为Python编写扩展模块,Python也可为C++提供脚本接口,更加方便于实际应用。
(3)建议采用SWIG的方式!