不重写equals和hashcode难道就不行吗?
不重写equals和hashcode难道就不行吗?

究竟为什么要重写equals和hashcode???
目录
-
1、equals()方法和hashCode()方法介绍
-
1.1、equals()方法
-
1.2、hashCode()方法
-
-
2、Hash算法介绍
-
3、重写equals()方法和hashCode()方法
-
3.1、什么时候需要重写?
-
3.2、为什么要重写?
-
-
4、值得注意的点——内存泄漏
-
5、总结
1、equals()方法和hashCode()方法介绍
equals()方法和hashCode()方法都是根类Obeject中的方法。
1.1、equals()方法
源代码如下:
public boolean equals(Object obj) {
return (this == obj);
}
从源码中可以看到,默认的equals()方法,是直接调用==,通过内存地址来判断对象是否相等。在实际业务中,不同的子类,可以根据实际需求重写此方法,进行两个对象的equals()的判断。实际使用中,equals()更像是用来判断两个对象是否等价,举个简单的例子:假如我们定义黑猫和白猫两个类,黑猫这个类中有两个属性String color = "black;"和String type = "cat";,白猫这个类中同样有两个属性String color = "white";和String type = "cat";,然后new出白猫对象和黑猫对象。如果我们的实际需求是:只要是type的值为"cat",就当成同一个对象处理(白猫黑猫都当成猫),那么默认的equals()方法就不再满足我们的需求,它就要被我们重写成通过判断特征值type来判断是否相同,白猫.equals(黑猫)的返回值应该是true。
1.2、hashCode()方法
Java语言中,Object对象有个特殊的方法:hashcode()。
public native int hashCode();
hashcode()是本地方法,有兴趣的读者可以深入了解一下。这里只要知道hashcode()返回的是对象的地址值。JVM会使用对象的hashcode值来提高对HashMap(HashSet其实就是HashMap)、Hashtable哈希表存取对象的使用效率。在实际开发中,我们经常把String类型作为key,那么String类型是如何重写hashCode()方法的呢?我们来看看代码:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
这段代码的功能是使用char数组中的数字每次乘以31再叠加最后返回,这样由于每个字符串的不同,返回的hashCode值也是不同的。至于为什么使用31这个数字而不是其他,这里我想引用《Effective Java》中31数字的解释:
之所以使用 31, 是因为他是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算(低位补0)。使用素数的好处并不很明显,但是习惯上使用素数来计算散列结果。31 有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能:31 * i == (i << 5) - i, 现代的 VM 可以自动完成这种优化。这个公式可以很简单的推导出来。
在《Effective Java》也说道:编写这种散列函数是个研究课题,最好留给数学家和理论方面的计算机科学家来完成。我们可以理解为使用31是为了性能更佳即可。
那么返回的hashcode值有什么用呢?HashMap之所以速度快,因为它使用的是散列表,根据key的hashcode值生成内存地址,从而可以通过内存地址直接查找,不需要有任何判断,时间复杂度完美情况下可以达到O(1),但是需要多出很多内存,相当于以空间换时间。
2、Hash算法介绍
我们都知道在一个长度为n的线性表中,存放着无序的数字,那么如果我们想要找到一个特定的数字,就不得不通过从头到尾依次遍历来查找,这样的时间复杂度是n/2。我们再来看Hash表。在Hash表里,存放在其中的数据和它的存储位置是用Hash函数关联的,它的时间复杂度接近于1,代价相当小,下面对Hash算法做个简单的介绍。为了方便说明,我们先假设一个长度为11的线性表作为Hash表,并假设一个比较简单的Hash函数是x ^ 2 % 5。如果我们想要把数字5放入表中,那么我们首先对5代入Hash函数计算一下:5 ^ 2 % 5 = 0,所以我们就把5存放到索引号为0的这个位置。当我们反过来从中找5这个元素时,我们可以先通过Hash函数算出5的索引号,然后直接去对应索引号中就可以找到了,这样会显得十分的方便。  但是,用这种方式进行存储也会存在一定的问题,举个简单的例子,这里依然使用上面假设的Hash函数来计算。当我们存数字6时,6 ^ 2 % 5 = 1;而当我们存数字9时,9 ^ 2 % 5 = 1。我们可以清晰的看到6和9有着相同的Hash值,这就是所谓的Hash值冲突问题。针对这个问题,HashMap是采用了链地址法的解决方案,将Hash值相同的元素使用链表来存储。
但是,用这种方式进行存储也会存在一定的问题,举个简单的例子,这里依然使用上面假设的Hash函数来计算。当我们存数字6时,6 ^ 2 % 5 = 1;而当我们存数字9时,9 ^ 2 % 5 = 1。我们可以清晰的看到6和9有着相同的Hash值,这就是所谓的Hash值冲突问题。针对这个问题,HashMap是采用了链地址法的解决方案,将Hash值相同的元素使用链表来存储。  当我们将数字6存放在索引号为1的位置后,想要继续存数字9,那么在存数字9的时候发现索引号为1的位置已经被占了,则会新建一个链表结点存放数字9。同样,如果我们要从中找数字9的话,会先找到索引号为1的位置,发现不是9,那么会沿着链表依此往下查找。
当我们将数字6存放在索引号为1的位置后,想要继续存数字9,那么在存数字9的时候发现索引号为1的位置已经被占了,则会新建一个链表结点存放数字9。同样,如果我们要从中找数字9的话,会先找到索引号为1的位置,发现不是9,那么会沿着链表依此往下查找。 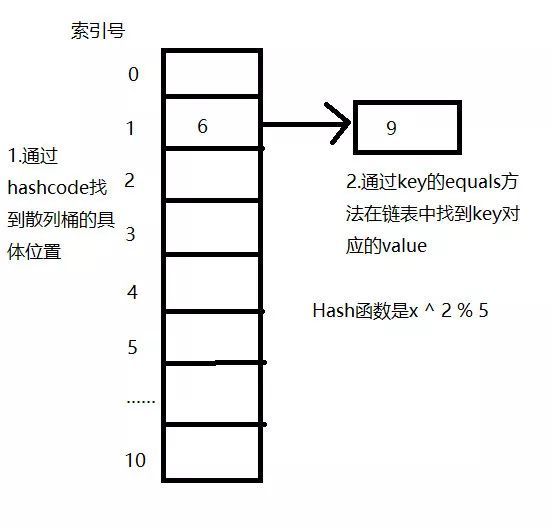
3、重写equals()方法和hashCode()方法
3.1、什么时候需要重写?
一般来讲,我们应该根据实际中的具体业务来重写equals()方法用于比较不同的对象,但是我们在重写equals()方法的同时最好也要重写一下hashCode()方法。当然,如果没有重写hashCode()方法,程序依然可以执行,只不过以后用起来可能会存在bug。一般一个类的对象如果会存储在HashTable,HashSet,HashMap等散列存储结构中,如果重写equals()后没有重写hashCode(),很可能会因为存储了两个equals相等的数据而导致存储数据的不唯一性。如果确定不会存储在这些散列结构中,则可以不重写hashCode()。但是个人觉得还是重写比较好一点,万一后期要存储在这些结构中呢,况且重写了hashCode()也不会降低性能,因为在线性结构(如ArrayList)中是不会调用hashCode(),所以重写了也不要紧,保证有备无患嘛。
3.2、为什么要重写?
这里将通过HashSet的几个例子来一起体会一下。例1:equals()方法和hashCode()方法均没有重写
public class Student {
private String id; //学号
private String name; //姓名
public Student(String id, String name) {
super();
this.id = id;
this.name = name;
}
}
public class EqualTest {
public static void main(String[] args){
HashSet set = new HashSet();
Student stu1 = new Student("01","小明");
Student stu2 = new Student("02","小明");
System.out.println("stu1==stu2: " + (stu1==stu2));
System.out.println("stu1.equals(stu2): " + (stu1.equals(stu2)));
System.out.println("stu1的哈希值: " + stu1.hashCode());
System.out.println("stu2的哈希值: " + stu2.hashCode());
set.add(stu1);
set.add(stu2);
System.out.println("set size: " + set.size());
}
}
运行结果如下:
stu1==stu2: false
stu1.equals(stu2): false
stu1的哈希值: 607427769
stu2的哈希值: 376812645
set size: 2结果分析:默认的hashCode()是根据对象的内存地址返回哈希值,因此两个不同对象的hashCode是不同的。默认的equals()是比较两个对象的内存地址,两个不同对象的地址肯定不会相同,因此equals()的运行结果为false。由于hashCode()和equals()的运行结果均为不等,HashSet会认为这是两个不同的对象存入,因此set的长度为2。
例2:重写hashCode()方法,以学号作为返回hashCode的标准 重写代码如下:
public class Student {
private String id; //学号
private String name; //姓名
public Student(String id, String name) {
super();
this.id = id;
this.name = name;
}
/*
* 采用学号的哈希值作为返回值
*/
@Override
public int hashCode() {
// TODO Auto-generated method stub
return id.hashCode();
}
}
运行结果如下:
stu1==stu2: false
stu1.equals(stu2): false
stu1的哈希值: 537561016
stu2的哈希值: 537561016
set size: 2结果分析:我们创建的两个学生对象学号是一样的,因此hashCode是相同的。但是由于没有重写equals()方法,因此仍以两个对象的内存地址作为比较,因此equals()方法的运行结果仍为false。由于只有hashCode一致,equals()方法仍为false,因此Set会认为这是两个不同的对象,因此HashSet的长度仍为2。
例3:只重写equals()方法,不重写hashCode()方法 重写代码如下:
public class Student {
private String id; //学号
private String name; //姓名
public Student(String id, String name) {
super();
this.id = id;
this.name = name;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
if(this==obj)
return true;
if(obj==null)
return false;
if(getClass() != obj.getClass())
return false;
final Student stu = (Student) obj;
if(this.id!=stu.id || this.name!=stu.name)
return false;
return true;
}
}
运行结果:
stu1==stu2: false
stu1.equals(stu2): true
stu1的哈希值: 607427769
stu2的哈希值: 376812645
set size: 2结果分析:当我们重写equals()方法以后,equals()方法的运行结果为true。而没有重写hashCode()方法时,hashCode()的返回值默认是以对象的内存地址作为返回值的,因此两个对象的哈希值一定不同。这时候的set长度依然为2,说明HashSet认为这是两个不同对象。因为HashSet、HashMap、HashTable这类的散列存储结构,按照java的机制会先调用hashCode()方法来确定元素所在的“桶”,然后再调用equals()方法来确定该桶内是否已经存在该元素。因此,在先调用hashCode()方法返回值不一致时,Set会把元素存储到不同的“桶”内,所以Set的长度仍为2。
例4:equals()方法和hashCode()方法均重写 重写代码如下:
public class Student {
private String id; //学号
private String name; //姓名
public Student(String id, String name) {
super();
this.id = id;
this.name = name;
}
@Override
public boolean equals(Object obj) {
// TODO Auto-generated method stub
if(this==obj)
return true;
if(obj==null)
return false;
if(getClass() != obj.getClass())
return false;
final Student stu = (Student) obj;
if(this.id!=stu.id || this.name!=stu.name)
return false;
return true;
}
/*
* 采用学号的哈希值作为返回值
*/
@Override
public int hashCode() {
// TODO Auto-generated method stub
return id.hashCode();
}
}
运行结果如下:
stu1==stu2: false
stu1.equals(stu2): true
stu1的哈希值: 537561016
stu2的哈希值: 537561016
set size: 1结果分析:在同时重写equals()方法和hashCode()方法时,才能保证Set集合认为这是同一个对象。
4、值得注意的点——内存泄漏
下面代码是在重写了equals()和hashcode()的情况下运行。
public class EqualTest {
public static void main(String[] args){
HashSet set = new HashSet();
Student stu1 = new Student("01","小明");
Student stu2 = new Student("02","小红");
System.out.println("stu1==stu2: " + (stu1==stu2));
System.out.println("stu1.equals(stu2): " + (stu1.equals(stu2)));
System.out.println("stu1的哈希值: " + stu1.hashCode());
System.out.println("stu2的哈希值: " + stu2.hashCode());
set.add(stu1);
set.add(stu2);
stu2.setId("03"); //导致内存泄漏的代码
System.out.println("删除元素前set size: " + set.size());
set.remove(stu2);
System.out.println("删除元素后set size: " + set.size());
}
}
运行结果如下:
stu1==stu2: false
stu1.equals(stu2): false
stu1的哈希值: 537561016
stu2的哈希值: 537561016
删除元素前set size: 2
删除元素后set size: 2我们从运行结构可以看到,删除stu2元素的前后的size都是2,显然删除失败了。那这是什么原因呢?
我们来看一下remove方法源码:
/**
* Removes the mapping for the specified key from this map if present.
*
* @param key key whose mapping is to be removed from the map
* @return the previous value associated with key, or
* null if there was no mapping for key.
* (A null return can also indicate that the map
* previously associated null with key.)
*/
public V remove(Object key) {
Entry e = removeEntryForKey(key);
return (e == null ? null : e.value);
/**
* Removes and returns the entry associated with the specified key
* in the HashMap. Returns null if the HashMap contains no mapping
* for this key.
*/
final Entry removeEntryForKey(Object key) {
int hash = (key == null) ? 0 : hash(key);
int i = indexFor(hash, table.length);
Entry prev = table[i];
Entry e = prev;
while (e != null) {
Entry next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
我们可以看到在调用remove方法的时候,会先使用对象的hashCode值去找到这个对象,然后进行删除。那对于我们的例子来说,Set的remove操作同样是先调用hashCode()方法找到元素所在的“桶”,再调用equals()方法确定“桶”内是否存在该元素。我们修改了stu2的学号id,导致其hashCode值发生了变化,而这个hashCode值又参与了运算,就好比是stu2根据原先的hashCode值是在“桶1”中,执行remove操作时会到现在的hashCode值的“桶5”中寻找,这样肯定是找不到的,所以删除也不会成功,set长度同样不会有变化。因此,如果我们将对象的属性值参与了hashCode的运算中,在进行删除的时候,就不能对其属性值进行修改,否则会出现严重的内存泄露问题。
5、总结
希望大家通过这篇文章,能够更好的认识equals()方法和hashCode()方法,了解Hash算法,掌握散列表的特性,方便以后更好的使用。