【图像分割论文阅读】DenseASPP for Semantic Segmentation in Street Scenes

本文由谷歌DeepMotion团队发布,发表于CVPR2018.
论文地址:DenseASPP for Semantic Segmentation in Street Scenes
背景
在自动驾驶领域,语义图像分割是基本的街道场景理解任务,它要求给高分辨率图像分每一个像素点进行分类.由于自动驾驶领域中场景中的目标尺度变化非常大.要求对高层次的特征在多尺度上正确编码.ASPP在获得更大感受野的同时没有以牺牲空间分辨率为代价.整篇文章是基于ASPP模型.尽管ASPP能够产生多尺度特征,但是特征不够密集.
FCN通过改进特征表示,图像语义分割任务取得良好效果.高层语义信息对分割精度产生巨大影响.为了提取高层语义信息,FCN模型利用多个池化层增加感受野.使得上采样得到输入般大小的分割结果变得困难.但是如果输出的分割结果分辨率高那么可能没有充分的利用到高层特征.dilated convolution是为了解决大的特征图分辨率与大的感受野之间的矛盾.[意思是在传统CNN里面随着池化的操作,特征图会变小,与此同时感受野增大.想要获得高层特征需要较大的感受野,但是不希望特征图分辨率减小]在不增加参数个数的前提下,获得更大的感受野.因而能编码高层语义信息.
纵然dilated convolution解决了特征图分辨率与感受野之间的矛盾.,但是dilated convolution中所有特征贴图共享同一大小的感受野.也仅在单一尺度上利用特征.但是显然利用多尺度信息可以是分类结果更加准确.ASPP整合不同的dilation系数产生的特征,因而输出的特征图使用多个尺寸的感受野编码多尺度特征最后提升模型性能.
而ASPP仍有约束.对于输入图像是自动驾驶场景下的高分辨率图像,在处理时需要很大的感受野.在ASPP中就需要使用大的dilation系数.但是如果dilation>24会降低模型的分割能力.
作者提出:通过串联一系列的特征,每个中间特征图上的神经元对来自多个尺度的语义信息进行编码.不同的中间特征图对不同尺度范围的多尺度信息进行编码.
模型结构
ASPP
DeepLab V3中对高层特征图使用不同dilation的卷积并行编码高层.通过级联模式底层的扩张卷积的结果输入到高层以扩大感受野.并行过程利用多尺度Dilation对同一特征图进行处理而后合并.

ASPP模型可由下图表示,其中 H 表 示 扩 张 卷 积 H表示扩张卷积 H表示扩张卷积;
y = H 3 , 6 ( x ) + H 3 , 12 ( x ) + H 3 , 18 ( x ) + H 3 , 24 ( x ) y=H_{3,6}(x)+H_{3,12}(x)+H_{3,18}(x)+H_{3,24}(x) y=H3,6(x)+H3,12(x)+H3,18(x)+H3,24(x)
DenseASPP
相较于ASPP的做法,本文设计的模型能够提供更密集的多尺度特征.每一层都包含扩张卷积的输出,除顶层外,其余层全都整合了多尺度(扩张系数)对特征图进行处理,经过五层级联堆叠,得到更为密集的特征图输出。

与ASPP不同的是,DenseASPP每一层的处理可表示为,其中 y l y_l yl表示该层接收的特征图
y l = H K , d l ( [ y l − 1 , y l − 2 , ⋯ , y 0 ] ) y_{l}=H_{K, d_{l}}\left(\left[y_{l-1}, y_{l-2}, \cdots, y_{0}\right]\right) yl=HK,dl([yl−1,yl−2,⋯,y0])
对比两种方式获得的感受野;如果扩张卷积系数分别为[6,12,18,24],则ASPP可获得的最大感受野为: R max = max [ R 3 , 6 , R 3 , 12 , R 3 , 18 , R 3 , 24 ] = R 3 , 24 = 51 \begin{aligned} R_{\max } &=\max \left[R_{3,6}, R_{3,12}, R_{3,18}, R_{3,24}\right] \\ &=R_{3,24} \\ &=51 \end{aligned} Rmax=max[R3,6,R3,12,R3,18,R3,24]=R3,24=51
而DenseASPP能获得的最大的感受野为; R max = R 3 , 6 + R 3 , 12 + R 3 , 18 + R 3 , 24 − 3 = 122 \begin{aligned} R_{\max } &=R_{3,6}+R_{3,12}+R_{3,18}+R_{3,24}-3 \\ &=122 \end{aligned} Rmax=R3,6+R3,12+R3,18+R3,24−3=122
在本文中采用的扩张系数为[3,6,12,18,24],最后可获得的最大感受野大小为122+6=128
model size control
为了防止模型过大需要控制模型大小,这里对所有dilated convolution操作进行filter_size=1*1的卷积操作,减少特征图的深度。
假设DenseASPP的输入特征图大小为 C 0 C_0 C0,输入到该层进行dialted convolution操作的特征图大小为 C l C_l Cl,经过dilated convolution操作后每层输出特征图个数为 n n n,那么有:
c l = c 0 + n × ( l − 1 ) c_{l}=c_{0}+n \times(l-1) cl=c0+n×(l−1)
设定经过1*1卷积后特征图深度减半 c 0 / 2 c_0/2 c0/2,并且设 n = c 0 / 8 n=c_0/8 n=c0/8,那么DenseASPP中包含的参数有:
S = ∑ l = 1 L [ c l × 1 2 × c 0 2 + c 0 2 × K 2 × n ] = ∑ l = 1 L [ c 0 2 ( c 0 + ( l − 1 ) × c 0 8 ) + c 0 2 × K 2 × c 0 8 ] = c 0 2 32 ( 15 + L + 2 K 2 ) L \begin{aligned} S &=\sum_{l=1}^{L}\left[c_{l} \times 1^{2} \times \frac{c_{0}}{2}+\frac{c_{0}}{2} \times K^{2} \times n\right] \\ &=\sum_{l=1}^{L}\left[\frac{c_{0}}{2}\left(c_{0}+(l-1) \times \frac{c_{0}}{8}\right)+\frac{c_{0}}{2} \times K^{2} \times \frac{c_{0}}{8}\right] \\ &=\frac{c_{0}^{2}}{32}\left(15+L+2 K^{2}\right) L \end{aligned} S=l=1∑L[cl×12×2c0+2c0×K2×n]=l=1∑L[2c0(c0+(l−1)×8c0)+2c0×K2×8c0]=32c02(15+L+2K2)L
这个对应着上面的图应该很好理解。
那么如果channel=512个通道,那么则 n = 64 n=64 n=64,在进行扩张卷积之前先利用1*1卷积将通道数降为channel=256,那么整个DenseASPP的通道数为:channel=832=52+5x64[这里每一层的通道数都是64,加上初始的通道数即为832],参数个数只有1556480个,百万级,同比`DenseNet’的 1 0 7 10^7 107要少了一个数量级的参数。
实验
实验所用数据为Cityscapes数据集,评价指标为mIoU.实验基于Pytorch实现。
本文所使用的基础模型为DenseNet,作者基于DenseNet121对比DenseASPP和ASPP所取得的结果,证实DenseASPP提升了4.2%。而后又采用更深的DenseNet模型取得更好的mIoU.

另一方面,作者验证了使用不同扩张系数对模型的影响.证明当使用的扩张系数为[3,6,12,18,24]时取得最优结果。如图;
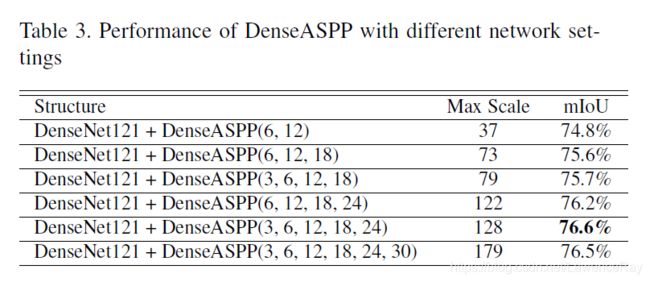
最终的分割效果为80.6%.
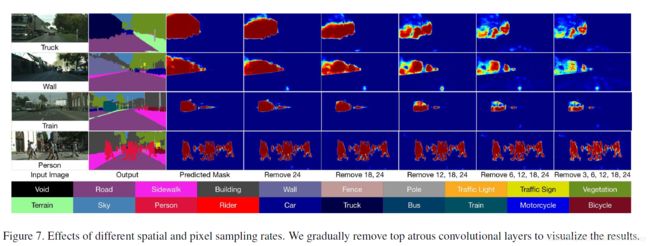
部分可视化分割结果如下:
思考:
- 个人感觉与PSPNet的想法很x像,结构图也类似。
- 如何解释
Denser呢?一般使用扩张卷积时,假设卷积核大小为filter_size=3x3,扩张系数dilation=6,则获得的感受野大小为FOV=13,但仅有三个参数参与计算【一维状态下】!并且这种状况在扩展到二维时更加明显。在计算过程中大量的信息都被丢弃了,这就是corase。在文中DenseASPP中膨胀因子逐层增加,下层卷积因子较大的层使用上层卷积因子较小的特征,这使得像素采样更为密集。
反思:实验实施细节没有详细看,如果之后复现模型的话再去看。