目标检测中的AnchorFree起源
转载自:https://zhuanlan.zhihu.com/p/62573122
更新:加入一个UnitBox(ACM MM 2016)
最近物体检测又起大的波澜,目标检测也发展了这么久了,每当我以为已经差不多了,达到瓶颈了,却又总会给我惊喜。今年年初,大量的anchor-free(类似吧,也不能说完全)的文章层出不穷,CornerNet,FCOS,FoveaBox,ExtremeNet,FSAF等等吧,我还惊奇的发现百度和中科院自动化所联合出的人脸检测的PyramidBox++(PyramidBox的改进版),竟然也加入了anchor-free,emmm,跟潮流速度很快啊!
我解读的PyramidBox文章:
TeddyZhang:人脸检测:PyramidBox(ECCV2018)
PyramidBox++:
PyramidBox++: High Performance Detector for Finding Tiny FaceDenseBox(2015)
这个工作在2015年就开始了,而现在再回过头来看,这个工作是多么有前瞻性,在论文中,作者就说了,DenseBox是一个不需要产生proposal且可以进行端到端地训练的FCN_Based的物体检测器,且更加关注那么尺寸小和严重遮挡的目标。所以在人脸数据集MALF进行验证模型性能!
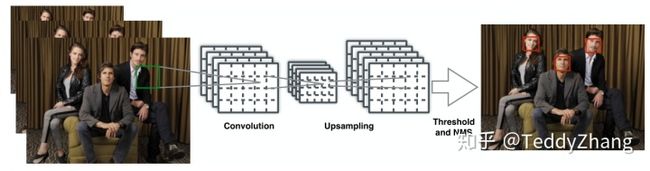

- 首先使用图像金字塔(这个思想后来演变成特征金字塔FPN)
- 经过一系列卷积和池化后,再进行上采样使特征图变大(用于检测更多的目标),再经过一些卷积得到最终的输出
- 把输出的特征图转换成边框,再通过NMS和阈值进行输出
测试阶段
在测试时,除了NMS算法,其余部分为一个全卷积网络,而且propasl的生成是不需要的,假如网络输入一张 的图片,其输出为 的feature map,且维度为5维,即 ,t与b分别代表边框左上角和右下角,所以说输出feature map每个像素都对应一个带分数的边框,那么他的真实框是怎么产生呢?
Ground Truth Generation


如果直接使用整幅图片进行训练的话,会在反向传播时浪费大量时间,于是使用了一种策略,对输入图片进行裁剪包含人脸和丰富背景的patches(目标检测的数据增强),在训练阶段,这些patches被裁剪后resize到240x240,其中人脸区域大约50像素。因此最后的输出为60x60且5通道的张量,因此Ground Truth在构建时,也得是60x60x5的张量,其人脸区域由一个以人脸bounding box的中心为圆心且半径为0.3倍(paper setting)的bounding box size的圆形区域确定,这个东西与segmentation类似。现在看来思想很超前!
在GT的第一个通道,我们用0来进行初始化,如果包含在正样本区域,那么就设置为1。其他的4个通道由该像素点与box的左上角和右下角的距离来确定。对于多张人脸,如果他们落在patch center的一定范围内,那么这些人脸就是正样本,其余的均为负样本。
模型结构
使用了VGG19,由于进行了上采样,所以总体图像尺寸降了4倍!


YOLO(2015)
YOLO算法也是我们的老朋友了,但这一版用的人不多,因为当时SSD的火爆,YOLO的检测准确率并不是那么高。今天我们用Anchor Free的思路再来重读YOLO,又是另一番感受!
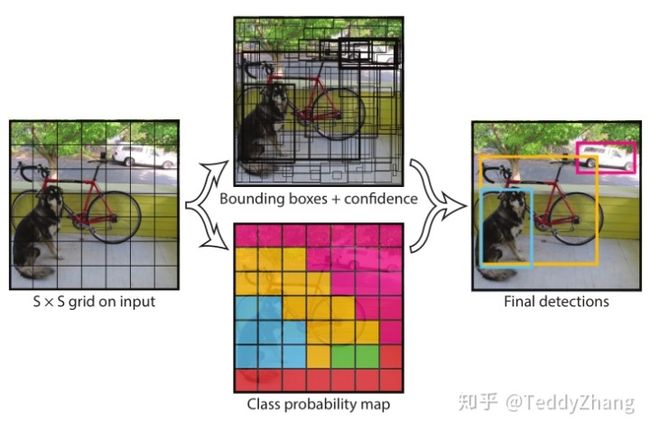

YOLO是一个单CNN模型的同时可以预测多个bounding box以及其分类概率,直接对全图进行训练。首先,YOLO会把输入图片分为SxS个网格,如果目标的中心落在了网格内,那么这个网格负责检测这个目标。接着我们定义其置信度
, 因此每个bounding box包括了5个预测值:x, y, w, h和confidece。YOLO算法把检测当做一个回归问题来解决,加入把图片分成SxS个网格且每个网格预测B个bounding box以及对应的confidence以及最终的类别预测C。那么最后一张图片的预测结果应该是一个 的张量。
论文中B=2,S=7,C=20.
YOLO缺点分析
作者在论文中也谈到了YOLO的缺点,最主要的缺点就是识别小物体,如小鸟。以及边框的位置偏差很大,当识别物体数量很多时也不可以。
其主要原因为只使用最后一层作为预测,且只有49个网格进行预测,而每个网络的感受野又很大,所以导致小物体检测不到。
UnitBox (ACM MM 2016)
这篇论文的思路可能受DenseBox的启发,大致的框架是差不多的,主要贡献就是把DenseBox中的L2损失进行了优化,改成了一个IOU loss.


可以看出这个架构和DenseBox差不多,也是通过上采样把BBox和Confidence尺寸保持一致,但不同的是对于位置参数的定义,在UnitBox中,其位置参数定义为:
分别表示中心区域到上、下、左、右四个边的距离,具体我们可以看下图的表示,而且 表示真实标签!

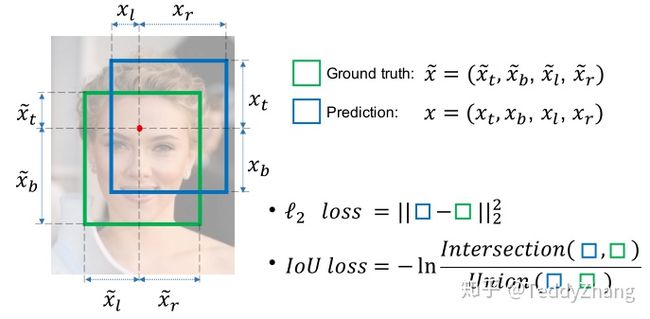
那么为什么不使用L2 loss呢?IOU loss如何构建呢?
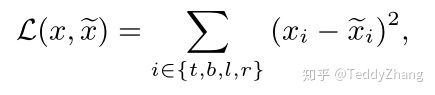
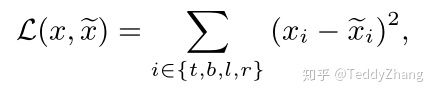
如上图的L2损失需要同时去优化四个独立的变量,这就会导致一个预测框的一个或两个变量非常接近真实框,但整体来看却不是那么好!另外一个原因,给定两个像素点,一个落在较大的bounding box,另外一个落在较小的bounding box,这样去计算L2 loss时,显而易见,前者对于bounding box影响更大,这就导致模型优化更加关注较大的物体,而忽略较小的物体。为了解决这个问题,有的工作提出了normalized l2 loss,但相应的也影响检测效率。
所以作者提出了一个基于IOU的loss函数,假设我们经过上上图ReLU层后得到 ,真实框为 , 分别表示中心区域到上、下、左、右四个边的距离。


我们可以看出,IoU loss是将boundingbox当做一个整体来进行优化的,而L2 是对bounding box的4个分量来进行优化的,另外,由于IoU最后被计算范围到[0, 1],这个优点就允许网络可以通过多尺度的目标进行训练,然后再单尺度的图像上进行测试!
思考
为什么现在Anchor Free算法又这么火了呢?我觉得这篇文章讲的很好,FPN和Focal loss的发展是很重要的一环!
陈恺:物体检测的轮回: anchor-based 与 anchor-free
至于最近刚出的一些论文,待我慢慢读完,再来解读,哈哈~