Tensorflow2.0 神经网络分类-手写识别
1下载数据集
from pathlib import Path
import requests
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "http://deeplearning.net/data/mnist/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
2搭建模型
import tensorflow as tf
from tensorflow.keras import layers
model = tf.keras.Sequential()
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
#选择损失和评估函数时候需要选择合适的,Api参考:
tf.losses.CategoricalCrossentropy
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.losses.CategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
损失函数是交叉熵损失
熵代表一个不确定性的信息量 不确定性越大 熵值越大
交叉熵简介
交叉熵是信息论中的一个重要概念,主要用于度量两个概率分布间的差异性,要理解交叉熵,需要先了解下面几个概念。
信息量
信息奠基人香农(Shannon)认为“信息是用来消除随机不确定性的东西”,也就是说衡量信息量的大小就是看这个信息消除不确定性的程度。
“太阳从东边升起”,这条信息并没有减少不确定性,因为太阳肯定是从东边升起的,这是一句废话,信息量为0。
”2018年中国队成功进入世界杯“,从直觉上来看,这句话具有很大的信息量。因为中国队进入世界杯的不确定性因素很大,而这句话消除了进入世界杯的不确定性,所以按照定义,这句话的信息量很大。
根据上述可总结如下:信息量的大小与信息发生的概率成反比。概率越大,信息量越小。概率越小,信息量越大。
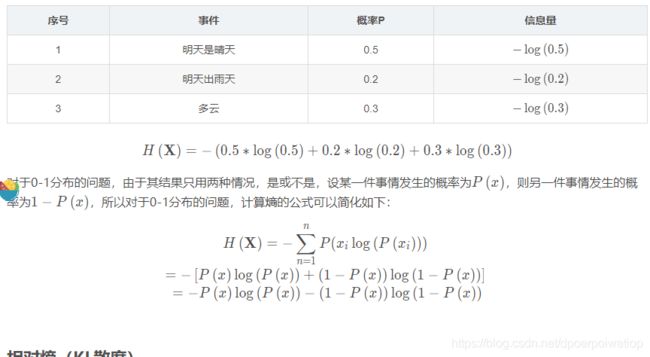
设某一事件发生的概率为P(x),其信息量表示为:
I(x)=−log(P(x))
其中I(x)I\left ( x \right )I(x)表示信息量,这里log\loglog表示以e为底的自然对数。
信息熵
信息熵也被称为熵,用来表示所有信息量的期望。
期望是试验中每次可能结果的概率乘以其结果的总和。
所以信息量的熵可表示为:(这里的XXX是一个离散型随机变量)

使用明天的天气概率来计算其信息熵:


交叉熵
首先将KL散度公式拆开:

tensorflow的交叉熵要求one-hot 编码 但是这里不是one-hot编码 所有用另外的损失函数
完整代码如下:
#%% md
### Tensorflow分类任务:
#%% md
读取Mnist数据集
- 会自动进行下载
#%%
#%%
from pathlib import Path
import requests
DATA_PATH = Path("data")
PATH = DATA_PATH / "mnist"
PATH.mkdir(parents=True, exist_ok=True)
URL = "http://deeplearning.net/data/mnist/"
FILENAME = "mnist.pkl.gz"
if not (PATH / FILENAME).exists():
content = requests.get(URL + FILENAME).content
(PATH / FILENAME).open("wb").write(content)
#%%
import pickle
import gzip
with gzip.open((PATH / FILENAME).as_posix(), "rb") as f:
((x_train, y_train), (x_valid, y_valid), _) = pickle.load(f, encoding="latin-1")
#%% md
784是mnist数据集每个样本的像素点个数
#%%
from matplotlib import pyplot
import numpy as np
pyplot.imshow(x_train[0].reshape((28, 28)), cmap="gray")
print(x_train.shape)
#%% md
<img src="./img/4.png" alt="FAO" width="790">
#%% md
<img src="./img/5.png" alt="FAO" width="790">
#%%
y_train[0]
#%%
import tensorflow as tf
from tensorflow.keras import layers
#%%
model = tf.keras.Sequential()
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(32, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
#%% md
选择损失和评估函数时候需要选择合适的,Api参考:https://tensorflow.google.cn/api_docs/python/tf/keras/metrics/SparseCategoricalAccuracy?version=stable
#%% md
一定选择合适的损失函数
#%%
tf.losses.CategoricalCrossentropy
#%%
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.losses.CategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
#%%
model.fit(x_train, y_train, epochs=5, batch_size=64,
validation_data=(x_valid, y_valid))
#%%
model.compile(optimizer=tf.keras.optimizers.Adam(0.005),
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()])
#%%
model.fit(x_train, y_train, epochs=5, batch_size=64,
validation_data=(x_valid, y_valid))
#%% md
### tf.data模块常用函数
#%%
import numpy as np
input_data = np.arange(16)
input_data
#%%
dataset = tf.data.Dataset.from_tensor_slices(input_data)
for data in dataset:
print (data)
#%% md
#### repeat操作
#%%
dataset = tf.data.Dataset.from_tensor_slices(input_data)
dataset = dataset.repeat(2)
for data in dataset:
print (data)
#%% md
#### batch操作
#%%
dataset = tf.data.Dataset.from_tensor_slices(input_data)
dataset = dataset.repeat(2).batch(4)
for data in dataset:
print (data)
#%% md
#### shuffle操作
#%%
dataset = tf.data.Dataset.from_tensor_slices(input_data).shuffle(buffer_size=10).batch(4)
for data in dataset:
print (data)
#%% md
#### 重新训练
#%%
train = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train = train.batch(32)
train = train.repeat()
valid = tf.data.Dataset.from_tensor_slices((x_valid, y_valid))
valid = valid.batch(32)
valid = valid.repeat()
model.fit(train, epochs=5,steps_per_epoch=100, validation_data=valid,validation_steps=100)
#%% md
### 练手的fashion数据集
#%%
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
#%%
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
#%%
train_images.shape
#%%
len(train_labels)
#%%
test_images.shape
#%%
import matplotlib.pyplot as plt
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
#%%
train_images = train_images / 255.0
test_images = test_images / 255.0
#%%
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
#%%
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])
#%%
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#%%
model.fit(train_images, train_labels, epochs=10)
#%% md
### 评估操作
#%%
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
#%%
predictions = model.predict(test_images)
#%%
predictions.shape
#%%
predictions[0]
#%%
np.argmax(predictions[0])
#%%
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
#%%
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
#%%
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
#%% md
### 保存训练好的模型
#%% md
保存权重参数与网络模型
#%%
model.save('fashion_model.h5')
#%% md
网络架构
#%%
config = model.to_json()
config
#%%
with open('config.json', 'w') as json:
json.write(config)
#%%
model = keras.models.model_from_json(json_config)
model.summary()
#%% md
权重参数
#%%
weights = model.get_weights()
weights
#%%
model.save_weights('weights.h5')
#%%
model.load_weights('weights.h5')
#%%