特征金字塔(FPN)的学习过程
1、作者将不改变feature map大小的层归为一个stage
2、图像的混叠现象:“所谓混叠,即高于采样频率一半的高频信号被映射到信号的低频部分,与原有低频信号叠加,对信号的完整性和准确性产生影响”
采样频率必须大于原始信号最高频率的两倍,才能完整地还原原始信号,这就是著名的尼奎斯特定律。
有两种方法可以消除混叠现象:
一是直接提高采样频率,以获得更高的尼奎斯特频率,但是采样频率不能无限提高;
二是在采样频率固定的情况下,可通过低通滤波器消除大于尼奎斯特频率的高频信号,从而消除混叠现象。
学习自:https://www.cnblogs.com/doctorbill/articles/3820088.html
3、亚采样:亚采样层就是使用pooling技术将小邻域内的特征点整合得到新的特征
4、aps,apm,apl:分别表示对小目标,中目标,大目标的平均准确度。
5、FPN算法的“新路历程”:
转载自:(原文:https://blog.csdn.net/WZZ18191171661/article/details/79494534)
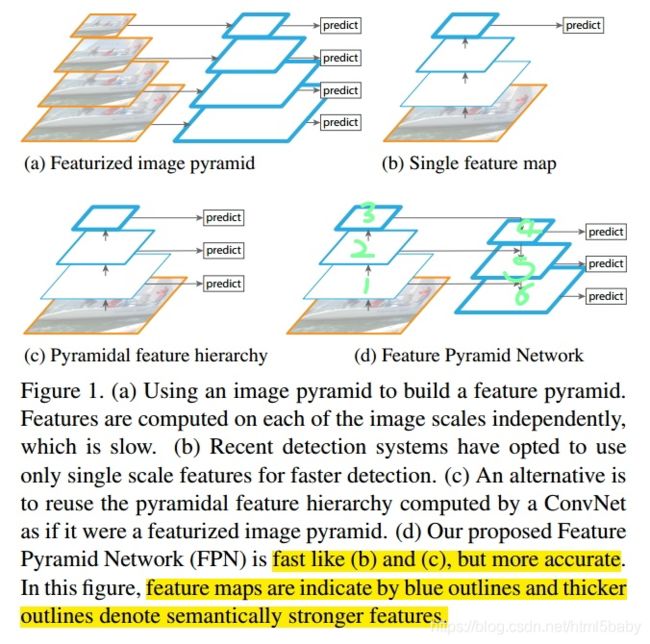
识别不同大小的物体是计算机视觉中的一个基本挑战,我们常用的解决方案是构造多尺度金字塔。
如上图a所示,这是一个特征图像金字塔,整个过程是先对原始图像构造图像金字塔,然后在图像金字塔的每一层提出不同的特征,然后进行相应的预测(BB的位置)。这种方法的缺点是计算量大,需要大量的内存;优点是可以获得较好的检测精度。它通常会成为整个算法的性能瓶颈,由于这些原因,当前很少使用这种算法。
如上图b所示,这是一种改进的思路,学者们发现我们可以利用卷积网络本身的特性,即对原始图像进行卷积和池化操作,通过这种操作我们可以获得不同尺寸的feature map,这样其实就类似于在图像的特征空间中构造金字塔。实验表明,浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助我们准确的检测出目标,因此我们可以利用最后一个卷积层上的feature map来进行预测。这种方法存在于大多数深度网络中,比如VGG、ResNet、Inception,它们都是利用深度网络的最后一层特征来进行分类。这种方法的优点是速度快、需要内存少。它的缺点是我们仅仅关注深层网络中最后一层的特征,却忽略了其它层的特征,但是细节信息可以在一定程度上提升检测的精度。
因此有了图c所示的架构,它的设计思想就是同时利用低层特征和高层特征,分别在不同的层同时进行预测,这是因为我的一幅图像中可能具有多个不同大小的目标,区分不同的目标可能需要不同的特征,对于简单的目标我们仅仅需要浅层的特征就可以检测到它,对于复杂的目标我们就需要利用复杂的特征来检测它。整个过程就是首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。它的优点是在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不需要进行多余的前向操作),这样可以在一定程度上对网络进行加速操作,同时可以提高算法的检测性能。它的缺点是获得的特征不鲁棒,都是一些弱特征(因为很多的特征都是从较浅的层获得的)。
(讲了这么多终于轮到我们的FPN啦)
它的架构如图d所示,整个过程如下所示,首先我们在输入的图像上进行深度卷积,然后对Layer2上面的特征进行降维操作(即添加一层1x1的卷积层),对Layer4上面的特征就行上采样操作,使得它们具有相应的尺寸,然后对处理后的Layer2和处理后的Layer4执行加法操作(对应元素相加),将获得的结果输入到Layer5中去。其背后的思路是为了获得一个强语义信息,这样可以提高检测性能。认真的你可能观察到了,这次我们使用了更深的层来构造特征金字塔,这样做是为了使用更加鲁棒的信息;除此之外,我们将处理过的低层特征和处理过的高层特征进行累加,这样做的目的是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此我们将其结合其起来使用,这样我们就构建了一个更深的特征金字塔,融合了多层特征信息,并在不同的特征进行输出。这就是上图的详细解释。(个人观点而已)
6、fpn用于fast rcnn
转载整理自:https://blog.csdn.net/wfei101/article/details/79301881
ROI Pooling层,需要对不同层级的金字塔制定不同尺度的ROI。不同尺度的ROI,使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。那怎么判断ROI改用哪个层
的输出呢?这里作者定义了一个系数Pk,通常,我们将宽度为w、高度为h的RoI(在输入到网络的图像上)分配给特征金字塔的Pk级
![]()
224*224是标准的预训练图片的大小,K0是224*224的roi层被映射到的层。类比使用resnet模型的faster rcnn系统,使用C4作为单尺度的特征图,设k0=4。如果ROI的尺度更小,例如是112*112,则k=向下取整(4+log2(112/224))=3,(第三层的特征金字塔)尺度更为精细的一层。
7、实验部分
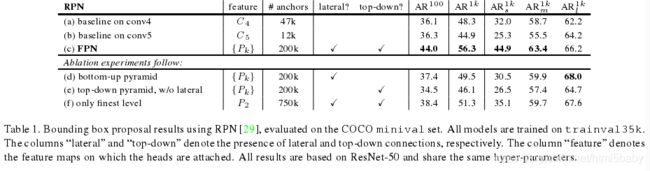
- 对于rpn网络
根据[21]中的定义,我们评估了其在coco数据集的AR以及对于coco中小型、中型和大型对象的AR。我们设置每幅图片有100或是1000个anchors(AR100和AR1k)。
实现细节。表1中的所有架构都是端到端训练的。输入图像调整大小,较短的边的像素设置为:800。我们在8个gpu上采用同步SGD训练。一个小批处理涉及到每个GPU 2张图像和每个图像256个锚。权重衰减(L2正则化)为0.0001(正则损失前权重), momentum就是一种优化的梯度下降算法参数设置为0.9。前30k个小批次的学习率为0.02,后10k为0.002。对于所有RPN实验(包括baseline),我们都包含用于训练的图像外的锚框。在8个gpu上用FPN训练RPN需要8个小时。
消融实验:
(1)对比了使用baseline中的conv4和conv5(a)和(b),发现AR没有提高,但是用fpn却对AR有8个百分点的提高。尤其是对小目标效果明显。说明我们的金字塔表示大大提高了RPN对目标尺度变化的鲁棒性。低分辨率和强语义信息存在权衡
(2)自上而下的作用:实验结果d只使用自下到上特征提取,我们的改进是进行1*1的lateral connection和3*3的卷积用以连接自下而上的金字塔。实验结果d可见只使用自下而上的特征提取和只使用baseline的效果差不多,推测是因为自底向上的金字塔各层的差异比较大。
(3)横向连接的作用:实验结果e是使用了从上到下的金字塔但是没有使用1*1的横向连接,这种自上而下的金字塔的语义信息很强分辨率很高,但是问题在于定位不够精细,可能是由于多次上下采样导致的。e和c的对比就可以看出横向连接的意义。
(4)图像金字塔的作用:相比图像金字塔只使用高分辨率的特征图,使用语义信息很强的P2。这时比baseline的效果好但没有我们的方法好,RPN是一种基于滑窗的方法,对于多尺度有很好的鲁棒性;但使用P2这种高分辨率产生较多的anchors,却没有很好的提高准确度,就是说单独的增多anchors效果一般。
- 对于faster rcnn和fast rcnn目标检测的影响
……………………
8 、L2正则化(权重衰减)
学习链接:https://www.jianshu.com/p/c9bb6f89cfcc (这其中包含一些数学基础知识)
https://blog.csdn.net/red_stone1/article/details/80755144
当模型过于复杂时,容易导致过拟合,训练数据的performance很好但是测试时就不好了。使用正则化可以避免这种过拟合问题。
L2正则化就是在代价函数后面再加上一个正则化项,让梯度下降在一个规定的范围内进行。
附录:
学习链接:
https://blog.csdn.net/u014380165/article/details/72890275
fpn的结构图:
https://blog.csdn.net/dcxhun3/article/details/59055974
https://blog.csdn.net/WZZ18191171661/article/details/79494534