【文末送书】《从零开始学习自然语言处理(NLP)》-BERT推理加速实践(6)

作者:刘才全
编辑:陈人和
环境搭建
Pre-train模型获取
结合自身业务Fine-tuning
模型单精度(FP32)转半精度(FP16)
Fast-transformer编译
Fast-transformer集成
TensorFlow estimator线上推理
01
环境搭建
BERT的Fine-tuning需要GPU环境(CPU训练估计要慢到天长地久),而GPU的环境配置又相对麻烦。除了显卡驱动外,还需要对应版本的安装CUDA、CUDNN、Python、TensorFlow-GPU。版本不匹配很容易出问题。简单的环境搭建,推荐直接使用Nvidia的NGC镜像。针对BERTFine-tuning(Pre-train同样适用),本文中使用Docker镜像:nvcr.io/nvidia/tensorflow:19.10-py3(镜像说明:https://ngc.nvidia.com/catalog/containers/nvidia:tensorflow)。
Python 3.6.8
Tensorflow-estimator 1.14.0
Tensorflow-gpu 1.14.0+nv
TensorRT 6.0.1(Fast transformer基于TensorRT实现,需要依赖TensorRT)
02
Pre-train模型获取
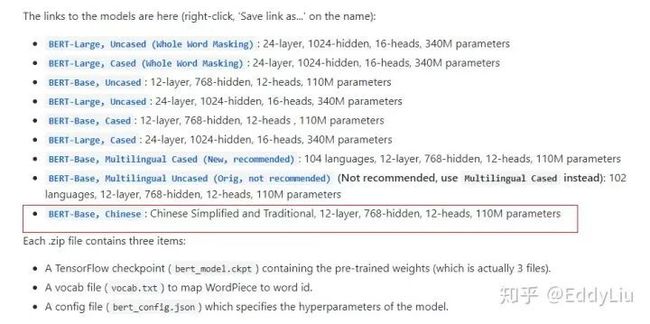
中文的BERT预训练模型直接从google-research/bert获得即可,具体地址:https://github.com/google-research/bert
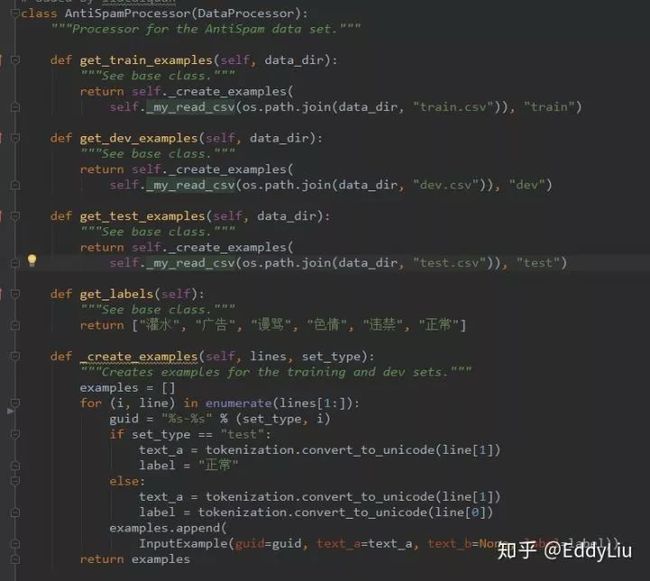
Fine-tuning主要是根据自己的使用场景,修改训练的数据读取逻辑,这里以文本分类(多分类、单标签)为例进行展开。文本分类的入口是run_classifier.py文件,主要增加一个自定义的数据获取类,比如:
需要注意的是,如果训练样本提前没有进行shuffle操作,可以将代码中的shuffle值修改的大一些,否则,训练结果会很差,比如,

Fine-tuning的代码可以使用Google官方的代码(代码地址:https://github.com/google-research/bert),也可以使用Nvidia提供的BERT代码(代码地址:https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow/LanguageModeling/BERT)。
03
模型单精度(FP32)转半精度(FP16)
ckpt_type_convert.py
ckpt_type_convert.py地址:
https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer/sample/tensorflow_bert
04
Fast-transformer编译
Fast-transformer由C++编写实现,使用前需要先进行编译。
编译环境之间使用当前的Docker环境即可,需要注意的是要先下载TensorRT的压缩包。虽然环境中已经有了TensorRT,但为了方便起见,还是直接下载一个(直接编译会出错)。注意对齐环境中的TensorRT版本(环境中使用的是TenorRT6.0版本)。
TensorRT下载地址:https://developer.nvidia.com/tensorrt
编译命令:

命令地址:
https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer
要正常使用Fast transformer还需要gemm_config.in文件,这个文件通过命令生成:
gemm_config.in文件生成
命令地址:
https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer
05
Fast-transformer集成
Fast transformer的集成相对简单,直接将
DeepLearningExamples/FasterTransformer/sample/tensorflow_bert/目录中的内容,拷贝到BERT源码目录即可。这里需要注意的是拷贝到google-research/bert的官方源码目录,而不是NVIDIA/DeepLearningExamples的BERT源码目录。
拷贝到后者中,会运行出错(Fast transformer Demo应该是基于Google官方BERT源码实践的)。
同时,需要注意的是上一个步骤中生成的C++层Fast transformer动态链接库,以及gemm_config.in文件的位置。
动态链接引用
gemm_config.in文件放在源码目录下即可(执行命令的根目录)。
最后,设置
FLAGS.floatx = 'float16'从而开启半精能力。
1 Fast transformer example代码拷贝到Google的BERT官方源码中;
2 包含libtf_fastertransformer.so的build文件放置在正确位置;
3 http://gemm_config.in文件放置在执行命令的目录;
4 设置FLAGS.floatx = 'float16',开启半精推理能力;
06
TensorFlow estimator线上推理
话题模型(topic model)是一族生成式有向图模型,主要用于处理离散型的数据(如文本集合),在信息检索、自然语言处理等领域有广泛应用。隐狄利克雷分配模型(Latent Dirichlet Allocation,简称LDA)是话题模型的典型代表。
基于Fast transformer推理速度:
推理速度对比
数据来源:
https://github.com/NVIDIA/DeepLearningExamples/blob/master/FasterTransformer/sample/tensorflow_bert/sample.md
07
小结
本文基于Nvidia的Fast transformer,详细介绍了BERT推理加速优化的完整步骤,包括环境搭建、Pre-train模型获取、结合自身业务Fine-tuning、模型单精度(FP32)转半精度(FP16)、Fast-transformer编译、Fast-transformer集成、TensorFlow estimator线上推理等步骤,以及其中需要注意的问题,为BERT推理服务上线提供参考。
参考文献:
往期回顾之作者刘才权

*.规则说明: 参与人员需要点亮文章右下角“在看”按钮!
1.所有参与送书活动的小伙伴必须加管理员微信号:yimudeguo,二维码见文末,在活动截止前未加好友的为无效参与。
2.书籍送完为止,先到先得,数量有限,按实际公平情况寄送。3.本次活动11月17日20:00截止,中奖名单会及时公布,第一时间送出礼物。4.本次活动最终解释权归“机器学习算法工程师”公众号团队所有
针对本文内容,在本文留言板处留言,讲讲你的理解或者对以后文章的期待。
根据要求参加即可。
符合要求前提下,根据点赞数前3,即可获奖。
并结合留言质量选出2名,送书。
11月17日结束!
机器学习算法工程师
一个用心的公众号

进群,学习,得帮助
你的关注,我们的热度,
我们一定给你学习最大的帮助