jmeter---分布式
一,分布式
概念:
控制机安排工作下去,一堆执行机操作,完成后,数据回归控制机整合。
原理:
- 一台机器做控制台用也就是(master/Controller),其他机器做被指挥的小弟也就是(slave/Agent)
- 执行脚本的时候,控制台把脚本发送到每个子机上面,小弟们开始执行,小弟们执行的时候是不启动GUI(可视化界面),通过命令行模式执行
- 执行完成之后,小弟们把处理结果一同传给控制台机器,控制台做汇总展示,这样就实现了分布式测试
二,举个栗子
因为没有现实那么多机器,就拿本机做展示
在一台电脑上玩的话,开3个JMETER就称为伪分布式
复制2个,就三个了,改两个端口号,想怎么(。・∀・)ノ゙嗨就怎么(。・∀・)ノ゙嗨
1)创建小弟们
先在本机中复制两个Jmeter的文件夹充当slave机(就是奴隶机,小弟),整个jmeter文件夹全部复制
![]()
注:
真实工作是有多台PC一起工作的,我们可以把自己本机(充当指挥的机子)中的Jmeter整个文件夹都发送给需要的小弟机们,保证所有机器上面的版本环境都是一样的,如果有使用外部CSV文件的话,要一起复制过去,可以放置在bin\examples等文件夹中,一并发送过去。
2)建立主仆关系
控制台配置:
找到文件中的代码:
![]()
修改成:
![]()
小弟们配置:
同一个文件夹,小弟1号:
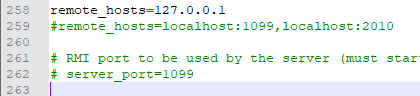
修改为:
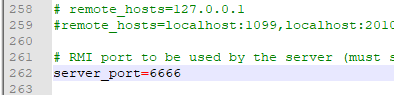
小弟2号:
修改为:

关系建立完成了
未建立关系之前:
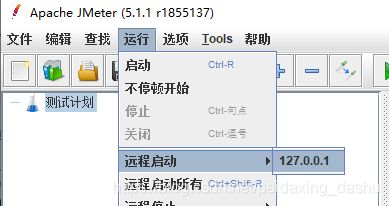
建立关系之后:
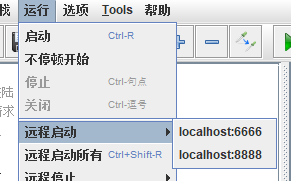
3)将小弟们运行起来
通过下图这个文件用命令行的形式运行起来
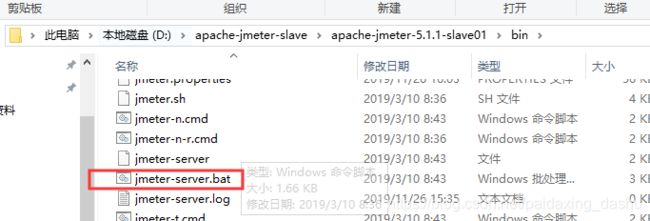
注:如果来了一个下图的报错
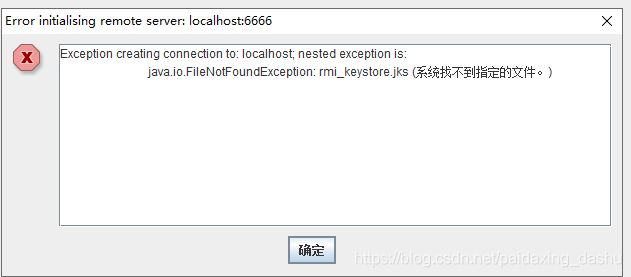
解决方案:
将所有Jmeter文件夹中的bin\jmeter.properties 的代码修改一下:
将server.rmi.ssl.disable=false修改为server.rmi.ssl.disable=true
控制机和小弟机都要改,不然命令行形式启动会报错
![]()
修改为:
![]()
启动成功是这样的:

4)控制台(主机)上运行脚本
随便搞一个请求

设置了50个线程(用户):

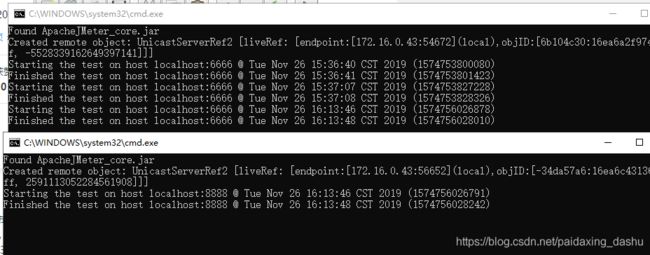
将所有小弟启动:

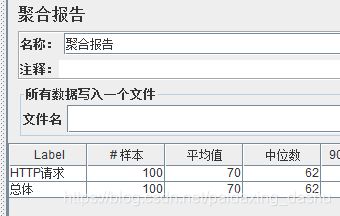
运行结果:
三,注意事项
- 如果有外部CSV作为数据源,记得同步发送给子机器
- 所有做分布式的机器,运行jmeter环境需要一致
- 因为master(调度机,控制机)和slave(执行机,奴隶机)最好都是分开的,因为主机是需要发送信息给多个子机还要接收回来测试数据,本身会有消耗,对于大数据量测试的话,可能会影响测试准确性。
- 作为master主机,一般是不会参与执行测试的,如上,设置的是50个线程(用户),2个子机器,聚合报告数据100
- 在主机上控制某个小弟运行,保存:Bad call to remote host(远程主机呼叫失败)
排查:小弟机器文件夹的jmeter-server.bat是否启动了,主机器上bin\jmeter.properties文件中的remote_hosts配置是否错误 - 子机上执行脚本的时候,如果脚本有断言,执行成功,则不会返回请求响应数据和详细断言信息
- 连接报错:connection refused to host:10.10.90.69 nested exception is…
可能是jmeter安装文件的路径下有中文了
搜刮网络大佬们的知识
(1)Jmeter 是纯java 应用,对于CPU和内存的消耗比较大,并且受到JVM的一些限制;
一般情况下,依据机器配置,单机的发压量为300~600,因此,当需要模拟数以千计的并发用户时,使用单台机器模拟所有的并发用户就容易卡死,引起JAVA内存溢出错误;(在1.4GHz~3GHz的CPU、1GB内存的JMeter客户端上,可以处理线程100~300。但是WebService例外。XML处理是CPU运算密集的,会迅速消耗掉所有的CPU。一般来说,以XML技术为核心的应用系统,其性能将是普通Web应用的10%~25%。)
(2)单台机器模拟的时候,如果并发数量较多且发送的网络包较大时,单机的网络带宽就会成为测试瓶颈,无法真正模拟高并发,导致测试结果失真(例如在要一秒内发送3000个请求,合计512kb,但是测试电脑只有256的上传带宽,那么实际测试的时候只是模拟了在一秒内发送1500个请求(256kb)的场景,导致测试结果失真。下载带宽的影响也是类似的);即:如果所有负载由一台机器产生,网卡和交换机端口都可能产生瓶颈,所以一个JMeter客户端线程数不应超过100。
(以上是测试机器的分析;应该还有别的,如硬盘等)
(3)真正的业务场景并发,我觉得应该是用户数大,每个用户的请求数小。如:更可能是1000个用户在2秒内各发起2个请求,而不是200个用户在2秒内各发起10个请求,虽然总的请求数都是2000个。