opencv使用svm
作者 群号 C语言交流中心 240137450 微信 15013593099
OpenCV开发SVM算法是基于LibSVM软件包开发的,LibSVM是台湾大学林智仁(LinChih-Jen)等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包。用OpenCV使用SVM算法的大概流程是
1)设置训练样本集
需要两组数据,一组是数据的类别,一组是数据的向量信息。
2)设置SVM参数
利用CvSVMParams类实现类内的成员变量svm_type表示SVM类型:
CvSVM::C_SVC C-SVC
CvSVM::NU_SVC v-SVC
CvSVM::ONE_CLASS 一类SVM
CvSVM::EPS_SVR e-SVR
CvSVM::NU_SVR v-SVR
成员变量kernel_type表示核函数的类型:
CvSVM::LINEAR 线性:u‘v
CvSVM::POLY 多项式:(r*u'v +coef0)^degree
CvSVM::RBF RBF函数:exp(-r|u-v|^2)
CvSVM::SIGMOID sigmoid函数:tanh(r*u'v +coef0)
成员变量degree针对多项式核函数degree的设置,gamma针对多项式/rbf/sigmoid核函数的设置,coef0针对多项式/sigmoid核函数的设置,Cvalue为损失函数,在C-SVC、e-SVR、v-SVR中有效,nu设置v-SVC、一类SVM和v-SVR参数,p为设置e-SVR中损失函数的值,class_weightsC_SVC的权重,term_crit为SVM训练过程的终止条件。其中默认值degree= 0,gamma = 1,coef0 = 0,Cvalue = 1,nu = 0,p = 0,class_weights =0
3)训练SVM
调用CvSVM::train函数建立SVM模型,第一个参数为训练数据,第二个参数为分类结果,最后一个参数即CvSVMParams
4)用这个SVM进行分类
调用函数CvSVM::predict实现分类
5)获得支持向量
除了分类,也可以得到SVM的支持向量,调用函数CvSVM::get_support_vector_count获得支持向量的个数,CvSVM::get_support_vector获得对应的索引编号的支持向量。
实现代码如下:
- // step 1:
- float labels[4] = {1.0, -1.0, -1.0, -1.0};
- Mat labelsMat(3, 1, CV_32FC1, labels);
- float trainingData[4][2] = { {501, 10}, {255, 10}, {501, 255}, {10, 501} };
- Mat trainingDataMat(3, 2, CV_32FC1, trainingData);
- // step 2:
- CvSVMParams params;
- params.svm_type = CvSVM::C_SVC;
- params.kernel_type = CvSVM::LINEAR;
- params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6);
- // step 3:
- CvSVM SVM;
- SVM.train(trainingDataMat, labelsMat, Mat(), Mat(), params);
- // step 4:
- Vec3b green(0, 255, 0), blue(255, 0, 0);
- for (int i=0; i
- {
- for (int j=0; j
- {
- Mat sampleMat = (Mat_<
- float response = SVM.predict(sampleMat);
- if (fabs(response-1.0) < 0.0001)
- {
- image.at(j, i) = green;
- }
- else if (fabs(response+1.0) < 0.001)
- {
- image.at(j, i) = blue;
- }
- }
- }
- // step 5:
- int c = SVM.get_support_vector_count();
- for (int i=0; i
- {
- const float* v = SVM.get_support_vector(i);
- }
总结:
1、SVM是一个分类器(Classifier) ,也可以做回归 (Regression) 。
2、 SVM的主要思想可以概括为两点 :
(1)它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而 使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能;
(2)它基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。
3、 最优超平面 :使得每一类数据与超平面距离最近的向量与超平面之间的距离最大的这样的平面。
4、 支持向量 :那些在间隔区边缘的训练样本点。
5、 核函数 :SVM的关键在于核函数。简单说就是将低维空间线性不可分的样本转化为高维空间线性可分的。低维空间向量集通常难于划分,解决的方法是将它们映射到高维空间。但这个办法带来的困难就是计算复杂度的增加,而核函数正好巧妙地解决了这个问题。也就是说,只要选用适当的核函数,就可以得到高维空间的分类函数。在SVM理论中,采用不同的核函数将导致不同的SVM算法。在确定了核函数之后,由于确定核函数的已知数据也存在一定的误差,考虑到推广性问题,因此引入了松弛系数 以及 惩罚系数 两个参变量来加以校正。在确定了核函数基础上,再经过大量对比实验等将这两个系数取定,该项研究就基本完成,适合相关学科或业务内应用,且有一定能力的推广性。当然误差是绝对的,不同学科、不同专业的要求不一。
<5-1> 径向基(RBF)核函数(高斯核函数) 的说明常用的核函数有以下4种:
⑴ 线性核函数⑵ 多项式核函数⑶ 径向基(RBF)核函数(高斯核函数)
⑷ Sigmoid 核函数(二层神经网络核函数)
<5-2> 径向基(RBF)核函数的参数选取
径向基( RBF )核函数主要确定 惩罚因子 C 和 参数 。其中C 控制着使间隔margin 最大且错误率最小的折中,就是在确定的特征空间中调节学习机器的置信范围和经验风险的比例;而是RBF 核函数参数,主要影响样本数据在高维特征空间中分布的复杂程度。因此分类器的好坏取决于参数C 、 的确定。参数选择的好坏直接影响到分类器性能的好坏,但这方面目前缺乏理论指导,没有合适的方法,传统的参数选取都是通过反复的试验,人工选取令人满意的解。这种方法需要人的经验指导,并且需要付出较高的时间代价。常用的参数选择方法有:
I、网格法【OpenCV中SVM用到】
选取 U 个 C 和 V 个 ,就会有的组合状态,每种组合状态对应一种SVM 分类器,通过测试对比,找出推广识别率最高的 C 和 组合。一般取U=V=15 ,C 取值分别为,取值分别为共255 个 C 、 组合。网格法实质上是一种穷举法,随着排列组合的可能情况越多,其运算量将急剧增加。
II、双线性法
利用 RBF 核 SVM 的性能,首先对线性 SVM 求解最佳参数,使之为参数的线性 SVM 推广识别率最高,称为 ;然后固定,对满足
的 ,训练SVM ,根据对其推广识别率的估算,得到最优参数。虽然这种方法对有非常明确的公式,但首先要求解C ,而很难确定最优的C 。
III、梯度下降搜索法
设泛化误差为
核函数为 ,是待定的核参数,基本过程为:
a 将 置一个初始值
b 用一个标准的 SVM 解法(如 SMO ),求出 SVM 的解—— Lagrange 乘子
c
d 跳转到 b 直至 T 最小
其中 是足够小且最终收敛到零的数列。步骤c 是一个标准的梯度下降算法。由分类函数公式可以求解,的求解较麻烦,需要通过求解一个二次规划问题得到。
IV、遗传算法
基本步骤为:
a t=0
b 随机选择初始种群 P(t)
c 计算个体适应度函数值 F(t)
d 若种群中最优个体所对应的适应度函数值足够大或者算法已经连续运行多代,且个体的最佳适应度无明显改进则转到第h 步
e t=t+1
f 应用选择算子法从 P(t-1) 中选择P(t)
g 对 P(t) 进行交叉、变异操作,转到第c 步
h 给出最佳的核函数参合和惩罚因子 C ,并用其训练数据集以获得全局最优分类面。
遗传算法的缺点是收敛很慢,容易受局部极小值干扰。
<5-3>验证核函数性能的方法(3种)(衡量泛化能力)
I、单一验证估计
将大数量的样本分为两部分:训练样本和测试样本,此时测试集的错误率为:
式中, p 为样本数, 为样本实际所属的类别,为对训练样本预测出的类别。这种方法直观简单。可以通过理论证明,当样本数量趋近于无穷大时,该估计为无偏估计,但现实中处理的总是数量有限的样本问题,所以此方法的应用范围在一定程度上受到了限制。
II、K 折交叉验证【OpenCV中SVM用到】
K 折交叉验证是一种迭代方式,一共迭代 K 次,每次将所有训练样本分为K 份相等的子集样本,训练样本是选择其中K-1 份样本,测试样本是剩余的一个样本。通过K 次迭代后,可以利用平均值来评估期望泛化误差,根据期望泛化误差选择一组性能最佳的参数。K 折交叉验证由 K 折交叉验证误差决定, K 折交叉验证误差是算法错误率的估计,其计算方式为:假设为错分类的样本个数,经过K 次迭代后,得到 ,那么算法的错误率可以近似为错误分类数和总样本点数之比。该方法具有操作简单的优点,成为目前应用最广泛 的方法,但是这种方法容易受样本划分方式的影响。
III、留一法
留一法是 K 折交叉验证的特例,其基本思想是当可用样本数为N 时,训练集由其中N-1 个样本构成,测试样本为剩余的一个样本,经N 次重复,使所有的样本都参加过测试。通过理论证明,这种估计是无偏估计。因此,从实现原理来说,留一法的效果是最佳的;但是,在参数固定的情况下,确定其错误率对样本要训练N-1 次,运算量很大。为了解决留一法计算量大的缺陷,目前该方法确定核函数及其参数的常用方法是估计经验风险的上界,只要上界小,分类器的推广能力就强。
二、OpenCV中SVM的参数和函数说明
1、训练参数结构体 CvSVMParams (可参考 【OpenCV2.4】SVM的参数和函数介绍 )
(1)注意: 该结构必须被初始化后,传给CvSVM(2)构造函数的原型:
C++: CvSVMParams:: CvSVMParams ()
C++: CvSVMParams:: CvSVMParams (int svm_type ,
(3)注释int kernel_type ,
double degree ,
double gamma ,
double coef0 ,
double Cvalue ,
double nu ,
double p ,
CvMat* class_weights ,
CvTermCriteria term_crit
)
A. 默认的构造函数初始化有以下值:
CvSVMParams::CvSVMParams() : svm_type(CvSVM::C_SVC), kernel_type(CvSVM::RBF), degree(0),
gamma(1), coef0(0), C(1), nu(0), p(0), class_weights(0)
{
term_crit = cvTermCriteria( CV_TERMCRIT_ITER+CV_TERMCRIT_EPS, 1000, FLT_EPSILON );
}
<1> svm_type: 指定SVM的类型(5种):
- CvSVM::C_SVC : C类支持向量分类机。 n类分组 (n 2),允许用异常值惩罚因子C进行不完全分类。
- CvSVM::NU_SVC : 类支持向量分类机。n类似然不完全分类的分类器。参数为 取代C(其值在区间【0,1】中,nu越大,决策边界越平滑)。
- CvSVM::ONE_CLASS : 单分类器,所有的训练数据提取自同一个类里,然后SVM建立了一个分界线以分割该类在特征空间中所占区域和其它类在特征空间中所占区域。
- CvSVM::EPS_SVR : 类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离需要小于p。异常值惩罚因子C被采用。
- CvSVM::NU_SVR : 类支持向量回归机。 代替了 p。
<2> kernel_type: SVM的内核类型(4种):
- CvSVM::LINEAR : 线性内核,没有任何向映射至高维空间,线性区分(或回归)在原始特征空间中被完成,这是最快的选择。
- CvSVM::POLY : 多项式内核:
- CvSVM::RBF : 基于径向的函数,对于大多数情况都是一个较好的选择:
- CvSVM::SIGMOID : Sigmoid函数内核:
<3> degree: 内核函数(POLY)的参数degree。
<4> gamma: 内核函数(POLY/ RBF/ SIGMOID)的参数 。
<5> coef0: 内核函数(POLY/ SIGMOID)的参数coef0。
<6> Cvalue: SVM类型(C_SVC/ EPS_SVR/ NU_SVR)的参数C。
<7> nu: SVM类型(NU_SVC/ ONE_CLASS/ NU_SVR)的参数 。
<8> p: SVM类型(EPS_SVR)的参数 。
<9> class_weights: C_SVC中的可选权重,赋给指定的类,乘以C以后变成 。所以这些权重影响不同类别的错误分类惩罚项。权重越大,某一类别的误分类数据的惩罚项就越大。
<10> term_crit: SVM的迭代训练过程的中止条件,解决部分受约束二次最优问题。您可以指定的公差和/或最大迭代次数。
2、支持向量机 CvSVM 类(8个函数)
<1>构造函数的原型
C++: CvSVM:: CvSVM ()
C++: CvSVM:: CvSVM (const Mat& trainData ,
const Mat& responses ,
const Mat& varIdx=Mat() ,
const Mat& sampleIdx=Mat() ,
CvSVMParams params=CvSVMParams()
)
C++: CvSVM:: CvSVM (const CvMat* trainData ,
<2>构造函数的参数注释(5个)const CvMat* responses ,
const CvMat* varIdx=0 ,
const CvMat* sampleIdx=0 ,
CvSVMParams params=CvSVMParams()
)
- trainData : 训练数据,必须是CV_32FC1 (32位浮点类型,单通道)。数据必须是CV_ROW_SAMPLE的,即特征向量以行来存储。
- responses : 响应数据,通常是1D向量存储在CV_32SC1 (仅仅用在分类问题上)或者CV_32FC1格式。
- varIdx : 指定感兴趣的特征。可以是整数(32sC1)向量,例如以0为开始的索引,或者8位(8uC1)的使用的特征或者样本的掩码。用户也可以传入NULL指针,用来表示训练中使用所有变量/样本。
- sampleIdx : 指定感兴趣的样本。描述同上。
- params : SVM参数。
(2)训练函数
<1>作用:训练一个SVM
<2>训练函数的原型
C++: bool CvSVM:: train (const Mat& trainData ,
const Mat& responses ,
const Mat& varIdx=Mat() ,
const Mat& sampleIdx=Mat() ,
CvSVMParams params=CvSVMParams()
)
C++: bool CvSVM:: train (const CvMat* trainData ,
<3>训练函数的参数注释(5个)const CvMat* responses ,
const CvMat* varIdx=0 ,
const CvMat* sampleIdx=0 ,
CvSVMParams params=CvSVMParams()
)
和构造函数的参数是一样的,请参考构造函数的参数注释。
(3)自动训练函数
<1>作用: 根据可选参数训练一个SVM。
<2>自动训练函数原型
C++: bool CvSVM:: train_auto (const Mat & trainData ,
const Mat & responses ,
const Mat & varIdx ,
const Mat & sampleIdx ,
CvSVMParams params ,
int k_fold=10 ,
CvParamGrid Cgrid=CvSVM::get_default_grid(CvSVM::C) ,
CvParamGrid gammaGrid=CvSVM::get_default_grid(CvSVM::GAMMA) ,
CvParamGrid pGrid=CvSVM::get_default_grid(CvSVM::P) ,
CvParamGrid nuGrid=CvSVM::get_default_grid(CvSVM::NU) ,
CvParamGrid coeffGrid=CvSVM::get_default_grid(CvSVM::COEF) ,
CvParamGrid degreeGrid=CvSVM::get_default_grid(CvSVM::DEGREE) ,
bool balanced=false
)
C++: bool CvSVM:: train_auto (const CvMat * trainData ,
<3>自动训练函数的参数注释(13个)const CvMat * responses ,
const CvMat * varIdx ,
const CvMat * sampleIdx ,
CvSVMParams params ,
int kfold=10 ,
CvParamGrid Cgrid=get_default_grid(CvSVM::C) ,
CvParamGrid gammaGrid=get_default_grid(CvSVM::GAMMA) ,
CvParamGrid pGrid=get_default_grid(CvSVM::P) ,
CvParamGrid nuGrid=get_default_grid(CvSVM::NU) ,
CvParamGrid coeffGrid=get_default_grid(CvSVM::COEF) ,
CvParamGrid degreeGrid=get_default_grid(CvSVM::DEGREE) ,
bool balanced=false
)
- 前5个参数参考 构造函数的参数注释。
- k_fold: 交叉验证参数。训练集被分成k_fold的自子集。其中一个子集是用来测试模型,其他子集则成为训练集。所以,SVM算法复杂度是执行k_fold的次数。
- *Grid: (6个) 对应的SVM迭代网格参数。
- balanced: 如果是true则这是一个2类分类问题。这将会创建更多的平衡交叉验证子集。
<4>自动训练函数的使用说明
- 这个方法根据CvSVMParams中的最佳参数C, gamma, p, nu, coef0, degree自动训练SVM模型。
- 参数被认为是最佳的交叉验证,其测试集预估错误最小。
- 如果没有需要优化的参数,相应的网格步骤应该被设置为小于或等于1的值。例如,为了避免gamma的优化,设置gamma_grid.step = 0,gamma_grid.min_val, gamma_grid.max_val 为任意数值。所以params.gamma 由gamma得出。
- 最后,如果参数优化是必需的,但是相应的网格却不确定,你可能需要调用函数CvSVM::get_default_grid(),创建一个网格。例如,对于gamma,调用CvSVM::get_default_grid(CvSVM::GAMMA)。
- 该函数为分类运行 (params.svm_type=CvSVM::C_SVC 或者 params.svm_type=CvSVM::NU_SVC) 和为回归运行 (params.svm_type=CvSVM::EPS_SVR 或者 params.svm_type=CvSVM::NU_SVR)效果一样好。如果params.svm_type=CvSVM::ONE_CLASS,没有优化,并指定执行一般的SVM。
<5>网格搜索法+K交叉验证
上述使用说明是OpenCV使用文档中的,这里再加其他一些补充:
A、可参考文章《 SVM分类核函数和参数选择比较 》《 基于改进的网格搜索法的SVM参数优化 》《LibSVM分类的实用指南》《 libsvm交叉验证与网格搜索(参数选择) 》,讲到了K交叉验证和网格搜索法。
B、优化参数的方式一般是用网格搜索法取值,然后对这组参数进行K交叉验证,计算精确值(交叉验证的准确率等于能够被正确分类的数量百分比),寻求最优参数。
(4)预测函数
<1>作用 :对输入样本做预测响应。
<2>预测函数的函数原型
C++: float CvSVM:: predict (const Mat& sample , bool returnDFVal=false ) const
C++: float CvSVM:: predict (const CvMat* sample , bool returnDFVal=false ) const
C++: float CvSVM:: predict (const CvMat* samples , CvMat* results ) const
<3>预测函数的参数注释
- sample: 需要预测的输入样本。
- samples: 需要预测的输入样本们。
- returnDFVal: 指定返回值类型。如果值是true,则是一个2类分类问题,该方法返回的决策函数值是边缘的符号距离。
- results: 相应的样本输出预测的响应。
<4>预测函数的使用说明
- 这个函数用来预测一个新样本的响应数据(response)。
- 在分类问题中,这个函数返回类别编号;在回归问题中,返回函数值。
- 输入的样本必须与传给trainData的训练样本同样大小。
- 如果训练中使用了varIdx参数,一定记住在predict函数中使用跟训练特征一致的特征。
- 后缀const是说预测不会影响模型的内部状态,所以这个函数可以很安全地从不同的线程调用。
(5)生成SVM网格参数的函数
<1>作用 : 生成一个SVM网格参数。
<3>函数的参数注释
- param_id: SVM参数的IDs必须是下列中的一个:(网格参数将根据这个ID生成 )
- CvSVM::C
- CvSVM::GAMMA
- CvSVM::P
- CvSVM::NU
- CvSVM::COEF
- CvSVM::DEGREE
<4>函数的使用说明
该函数生成一个指定的SVM网格参数,主要用于传递给自动训练函数 CvSVM::train_auto()。
(6)获取当前SVM参数的函数
<1>作用:获取当前SVM参数
<3>函数的使用说明
这个函数主要是在使用CvSVM::train_auto()时去获得最佳参数。(7)获取支持向量及其数量的函数
<1>作用 :获取支持向量及其数量
C++: int CvSVM:: get_support_vector_count () const //获取支持向量的数量
C++: const float* CvSVM:: get_support_vector (int i ) const //获取支持向量
参数: i – 指定支持向量的索引。
(8)获取所用特征的数量的函数
<1>作用 :获取所用特征的数量
<2>函数原型:
三、OpenCV的简单的程序例子
1、 Introduction to Support Vector Machines (可参考 【OpenCV2.4】SVM的参数和函数介绍 )
上述讲述了处理一个 线性可分情况 的例子,包含了SVM使用的几个步骤:
(1)准备训练样本及其类别标签( trainingDataMat,labelsMat )
(2)设置训练参数(CvSVMParams)
(3)对SVM进行训练( CvSVM:: train)
(4)对新的输入样本进行预测( CvSVM:: predict)
(5)获取支持向量( CvSVM:: get_support_vector_count ,CvSVM::get_support_vector )
2、 Support Vector Machines for Non-Linearly Separable Data (可参考 【OpenCV2.4】SVM处理线性不可分的例子 )
上述讲述了处理一个 线性不可分情况 的例子,着重讲述了 惩罚因子C 的作用:
- C比较大时:分类错误率较小,但是间隔也较小。 在这种情形下, 错分类对模型函数产生较大的影响,既然优化的目的是为了最小化这个模型函数,那么错分类的情形必然会受到抑制。
- C比较小时:间隔较大,但是分类错误率也较大。 在这种情形下,模型函数中错分类之和这一项对优化过程的影响变小,优化过程将更加关注于寻找到一个能产生较大间隔的超平面。
换而言之,C越大,优化时越关注错分问题;C越小,越关注能否产生一个较大间隔的超平面。
3、多分类的简单例子 (可参考 利用SVM解决2维空间向量的3级分类问题 )
上述讲述了一个三分类的例子,核函数用了RBF,并用到了其参数gamma,以及惩罚因子C,训练与预测和二分类一样,只要对样本赋予第三类的类别标签。
4、文字识别的简单例子 (可参考 SVM对文字识别的简单使用 和 使用OPENCV训练手写数字识别分类器 )
训练与预测的使用方法和上述一样,主要看下对图像数据的处理(简单的特征提取)。
5、HOG+SVM的例子 (可参考 OpenCV中的HOG+SVM物体分类 和 利用HOG+SVM训练自己的XML文件 )
训练与预测的使用方法还是和上述一样,主要看下Hog特征的使用( HOGDescriptor::compute )。
四、SVM处理流程总结:
1、收集数据 , 相关性分析 (比如p卡方检验), 特征选择 (比如主成份分析PCA)。
2、归一化数据 :就是根据实际要求,将数据的取值范围转化为统一的区间如[a,b],a,b为整数。(参考 缩放训练和测试数据时的常见错误 [附录B])
3、分训练集和测试集 :利用抽样技术将数据集分为训练集和测试集。抽样技术有分层抽样,简单抽样(等概率抽样)。 一般训练集数量大于测试集数量 ,就是要保证足够的训练样例。
4、将数据转化为软件(接口)所支持的格式 。
5、选择核函数 ,可以优先考虑RBF。
6、使用交叉验证(cross-validation)寻找最佳参数C和Υ: 对训练集利用交叉验证法选择最好的参数C和r(西格玛)(RBF核函数中的参数gama)。可以通过网格法寻找出最优的参数,注意一次交叉验证得到一个参数对所对应的模型精度,网格法目的就是找到使得模型精度达到对高的参数对(这里的参数对可能不止两个,有可能也有其他的),可以使用一些启发式的搜索来降低复杂度,虽然这个方法笨了点,但是它能得到很稳定的搜索结果。需要提到的这里在对训练集进行分割的时候涉及到抽样,一个较好的方法就是分层抽样。从这步可以看出其实 Cross-Validation是一种评估算法的方法。
a. 训练的目的得到参数和支持向量(存储在xml文件中),得到参数就能得到支持向量,带进算式计算SVM分类的准确度,以准确度最高的一组参数作为最终的结果,没有绝对线性可分的,都有一个误差,参数就是把那个误差降到最低。
b. 这里的准确性是指将训练集的每个样本的向量与支持向量做运算,将运算结果与标记值比较,判断是否属于这个类,统计这个类的正确的样本数,最高的那一组参数准确性最高。
c. 最终训练得到分类器。SVM只能分两类,所以这里的分类器是两个类组成一个分类器,如果有K类,就有k(k-1)/2个分类器。
7、使用最佳参数C和Υ来训练整个训练集: 用6中得到的参数对在整个训练集合上进行训练,从而得出模型。
8、测试: 利用测试集测试模型,得到精度。这个精度可以认为是模型最终的精度。当然有人会担心3步中抽样会有一定的误差,导致8得到的精度不一定是最好的,因此可以重复3-8得到多个模型的精度,然后选择最好的一个精度最为模型的精度(或者求所有精度的均值做为模型精度)。(需要多次选择训练集和测试集,然后每一次得到一个精度的模型,选择最好的一个精度作为模型,也就是我们项目里面要多次训练的原因)。
9. 识别分类: 两个类超平面的形成,意味着目标函数的形成,然后代入待识别样本,识别时对应的组代入对应的参数,得出结果进行投票,判定属于那个类。
SVM样本训练步骤
1、引言
2、步骤
(1)生成SVM描述文件;
plane/飞机训练正样本Normalize/0.jpg
1
plane/飞机训练正样本Normalize/1.jpg 命名为:SVM_DATA.txt
1(2)将描述文件读入容器中;
定义两个容器,用于保存样本路径和分类标号,如:
vector img_path;
vector img_catg;
读入数据:
int nLine = 0;
string buf;
ifstream svm_data( "SVM_DATA.txt" );
while( svm_data )
{
if( getline( svm_data, buf) )
/*原型
istream& getline ( istream &is , string &str , char delim ); istream& getline ( istream& , string& );
参数 is 进行读入操作的输入流 str 存储读入的内容 delim 终结符 返回值 与参数is是一样的
功能 将输入流is中读到的字符存入str中,直到遇到终结符delim才结束。
对于第一个函数delim是可以由用户自己定义的终结符;对于第二个函数delim默认为 '\n'(换行符)。
函数在输入流is中遇到文件结束符(EOF)或者在读入字符的过程中遇到错误都会结束。
在遇到终结符delim后,delim会被丢弃,不存入str中。在下次读入操作时,将在delim的下个字符开始读入。*/
{
nLine ++;
if( nLine % 2 == 0 )
{
img_catg.push_back( atoi( buf.c_str() ) );//atoi将字符串转换成整型,值为0或1 用0,1区分正负样本
//功 能: 把字符串转换成整型数。 名字来源:array to integer 的缩写。
//原型: int atoi(const char *nptr);
//函数说明: 参数nptr字符串,如果第一个非空格字符不存在或者不是数字也不是正负号则返回零,否则开始做类型转换,
//之后检测到非数字(包括结束符 \0) 字符时停止转换,返回整型数。
// 函数声明:const char *c_str(); c_str()函数返回一个指向正规C字符串的指针, 内容与本string串相同.
}
else
{
img_path.push_back( buf );//图像路径
}
}
}
svm_data.close();//关闭文件 (3)读入样本数量,生成样本矩阵和类型矩阵
CvMat *data_mat, *res_mat;
int nImgNum = nLine / 2; //读入样本数量
样本矩阵,nImgNum:横坐标是样本数量, WIDTH * HEIGHT:样本特征向量,即图像大小
data_mat = cvCreateMat( nImgNum, 144, CV_32FC1 );
cvSetZero( data_mat );
//类型矩阵,存储每个样本的类型标志
res_mat = cvCreateMat( nImgNum, 1, CV_32FC1 );
cvSetZero( res_mat ); (4)读入样本图像
(5)提取HOG特征
//以下为提取Hog特征
cvResize(src,trainImg); //读取图片,归一化大小
HOGDescriptor *hog=new HOGDescriptor(cvSize(64,64),cvSize(16,16),cvSize(16,16),cvSize(16,16),9);
vectordescriptors;//结果数组
hog->compute(trainImg, descriptors,Size(8,8), Size(0,0)); //调用计算函数开始计算
cout<<"HOG dims: "<::iterator iter=descriptors.begin();iter!=descriptors.end();iter++) //迭代器
{
cvmSet(data_mat,z,n,*iter); //将HOG特征 存入data_mat矩阵中
x=cvmGet(data_mat,z,n);
cout<<"hog"< (6)将HOG特征写入txt文件
FILE *fp1;
int i,j;
if((fp1=fopen("Hog.txt","ab"))==NULL)// 读写打开一个二进制文件,允许读或在文件末追加数据。
{
printf("can not open the hu file\n");
exit(0);//正常退出程序
}
for (i = 0; i <144; ++i)
{
fprintf(fp1,"%lf ",descriptors[i]);
}
//fprintf(fp1,"\r\n");
fclose(fp1);
cvmSet( res_mat, z, 0, img_catg[z] ); //将正负样本标记存入矩阵res_mat中
cout<<" end processing "<(7)进行SVM训练
CvSVM svm = CvSVM();
CvSVMParams param;
CvTermCriteria criteria;
criteria = cvTermCriteria( CV_TERMCRIT_EPS, 1000, FLT_EPSILON );
param = CvSVMParams( CvSVM::C_SVC, CvSVM::RBF, 10.0, 0.09, 1.0, 10.0, 0.5, 1.0, NULL, criteria );
/*
SVM种类:CvSVM::C_SVC
Kernel的种类:CvSVM::RBF
degree:10.0(此次不使用)
gamma:8.0
coef0:1.0(此次不使用)
C:10.0
nu:0.5(此次不使用)
p:0.1(此次不使用)
然后对训练数据正规化处理,并放在CvMat型的数组里。
*/
//SVM学习
svm.train( data_mat, res_mat, NULL, NULL, param );
//利用训练数据和确定的学习参数,进行SVM学习
svm.save( "SVM_DATA1.xml" );
cvReleaseImage(&src);
cvReleaseMat( &data_mat );
cvReleaseMat( &res_mat );
return 0; 在以上训练过程中,要特别注意的是在创建样本矩阵的时候,其矩阵大小由样本数量和样本提取的特征维数决定的。比如上面创建的样本矩阵大小为:
int nImgNum = nLine / 2; 行,144列; 144是由提取HOG特征时,由窗口大小、块大小、胞元大小和每个抱怨大小中的特征数共同决定的。BOW特征提取函数(特征点篇)
简单的通过特征点分类的方法:
一、train
1.提取+/- sample的feature,每幅图提取出的sift特征个数不定(假设每个feature有128维)
2.利用聚类方法(e.g K-means)将不定数量的feature聚类为固定数量的(比如10个)words即BOW(bag of word)
(本篇文章主要完成以上的工作!)
3.normalize,并作这10个类的直方图e.g [0.1,0.2,0.7,0...0];
4.将each image的这10个word作为feature_instance 和 (手工标记的) label(+/-)进入SVM训练
二、predict
1. 提取test_img的feature(如137个)
2. 分别求each feature与10个类的距离(e.g. 128维欧氏距离),确定该feature属于哪个类
3. normalize,并作这10个类的直方图e.g [0,0.2,0.2,0.6,0...0];
4. 应用SVM_predict进行结果预测
1.特征点提取
Ptr
Bag of Word闲谈
Bag of Word, 顾名思义,即将某些Word打包,就像我们经常会把类似的物品装到一个柜子,或者即使是随意打包一些物品,也是为了我们能够方便的携带,在对大数据作处理的时候,为了能够方便的携带这些数据中的信息,与其一个一个的处理,还不如打包来的容易一点。 Bag of Word 因其理论简单,易懂,在vision界也得到了广泛的应用,有人将Bag of Word改成Bag of Visual Word来提出,充其量只是炒炒概念罢了,其基本的思想还是BOW(Bag of Word)。
Anyway, 简单谈一些关于Bag of Word的东西:
Bag of word实现步骤:
step 1: 大数据聚类,找到适当的聚类中心点----Vocabulary。
std::string image_folder_path("C:\\img\\train\\");
bool ReadImageNames(std::vector& image_file_names, std::string folder, std::string list_file_name)
{
using namespace std;
ifstream label_file(folder + list_file_name);
if (!label_file)
return false;
string fname;
while (!label_file.eof())
{
label_file >> fname;
if (fname.length() == 0)
continue;
image_file_names.push_back(folder + fname + ".jpg");
label_file >> fname;
}
label_file.close();
return true;
}
// resize to 256x256
void UnifyImageSize(cv::Mat& image)
{
using namespace cv;
Mat unified_image;
int s = cv::min(image.rows, image.cols);
float scale = 128.0 / s;
Size size(image.cols * scale, image.rows * scale);
cv::resize(image, unified_image, size);
cv::medianBlur(unified_image, unified_image, 3);
image = unified_image;
}
int getVocabulary(string &image_folder_path, string &image_list_file)
{
if (image_folder_path.back() != '\\' || image_folder_path.back() != '/')
image_folder_path += "\\";
int minHessian = 400;
//Ptr feature_detector(new SurfFeatureDetector(minHessian));
Ptr feature_detector = Ptr(new PyramidAdaptedFeatureDetector(Ptr(new SurfFeatureDetector(minHessian))));
//Ptr descriptor_extractor = DescriptorExtractor::create("GridFAST");
Ptr descriptor_extractor(new OpponentColorDescriptorExtractor(Ptr(new SurfDescriptorExtractor(minHessian))));
//Ptr descriptor_extractor(new SurfDescriptorExtractor());
vector keypoints;
Mat descriptors;
Mat training_descriptors;
int i;
//cout << "------ build vocabulary -----" << endl;
//cout << "reading " << image_list_file << " ..." << endl;
vector image_file_names;
if(!ReadImageNames(image_file_names, image_folder_path, image_list_file))
{
cerr << "cannot read image names" << endl;
return -1;
}
Mat image;
//cout << "extract descriptors ... ";
//#pragma omp parallel for schedule(dynamic) private(image, keypoints, descriptors)
for (i = 0; i < image_file_names.size(); i++)
{
image = imread(image_file_names[i]);//, CV_LOAD_IMAGE_GRAYSCALE);
UnifyImageSize(image);
feature_detector->detect(image, keypoints);
descriptor_extractor->compute(image, keypoints, descriptors);
//#pragma omp critical
{
training_descriptors.push_back(descriptors);
//cout << "\b\b\b\b\b\b\b\b\b";
//cout << setfill(' ') << setw(4) << i << "/" << setw(4) << image_file_names.size();
}
}
//cout << endl;
//cout << "Total Descriptors: " << training_descriptors.rows << endl;
//cout << "Saving training_descriptors.yml" << endl;
FileStorage fs_descriptors("c:\\img\\train\\training_descriptors.yml", FileStorage::WRITE);
fs_descriptors << "training_descriptors" << training_descriptors;
fs_descriptors.release();
BOWKMeansTrainer bowtrainer(2000); // 1000 clusters
bowtrainer.add(training_descriptors);
cout << "clustering BOW features ..." << endl;
Mat vocabulary = bowtrainer.cluster();
//cout << "Saving vocabulary_color_crop_2000.yml" << endl;
FileStorage fs_vocabulary("c:\\img\\train\\vocabulary_color_surf_2000.yml", FileStorage::WRITE);
fs_vocabulary << "vocabulary" << vocabulary;
fs_vocabulary.release();
return 0;
} step 2: 训练数据像聚类中心映射,得到每一个训练数据在该聚类中心空间的一个低维表示。
bool ReadImageNamesAndLabels(std::vector& image_file_names, std::vector& image_labels, std::string folder, std::string list_file_name)
{
using namespace std;
ifstream label_list_file(folder + list_file_name);
if (!label_list_file)
return false;
string fname;
string label;
while (!label_list_file.eof())
{
label_list_file >> fname >> label;
if (fname.length() == 0 || label.length() == 0)
continue;
image_file_names.push_back(folder + fname + ".jpg");
image_labels.push_back(label);
}
label_list_file.close();
return true;
}
void ExtractTrainingSamples(cv::Ptr& detector, cv::BOWImgDescriptorExtractor& bowide, std::map& classes_training_data)
{
using namespace cv;
using namespace std;
vector image_file_names;
vector image_labels;
//ReadImageNamesAndLabels(image_file_names, image_labels, image_folder_path, "all.train.label");
ReadImageNamesAndLabels(image_file_names, image_labels, "C:\\Users\\Hongze Zhao\\Downloads\\MLKD-Final-Project-Release\\ic-data\\extra\\", "extra.label");
ReadImageNamesAndLabels(image_file_names, image_labels, "C:\\Users\\Hongze Zhao\\Downloads\\MLKD-Final-Project-Release\\ic-data\\check\\", "check.label");
cout << "extracting training samples ... ";
#pragma omp parallel for
for (int i = 0; i < image_file_names.size(); i++)
{
vector keypoints;
Mat response_hist;
string& class_label = image_labels[i];
Mat image = imread(image_file_names[i]);//, CV_LOAD_IMAGE_GRAYSCALE);
UnifyImageSize(image);
detector->detect(image, keypoints);
bowide.compute(image, keypoints, response_hist);
#pragma omp critical
{
if (classes_training_data.count(class_label) == 0) // not yet created...
classes_training_data[class_label].create(0, response_hist.cols, response_hist.type());
classes_training_data[class_label].push_back(response_hist);
cout << "\b\b\b\b\b\b\b\b\b";
cout << setfill(' ') << setw(4) << i << "/" << setw(4) << image_file_names.size();
}
}
cout << endl;
cout << "saving to file ..." << endl;
FileStorage fs("training_samples.yml", FileStorage::WRITE);
for (map::iterator ite = classes_training_data.begin(); ite != classes_training_data.end(); ++ite)
{
cout << "save " << ite->first << endl;
fs << "class" + ite->first << ite->second;
}
fs.release();
}
step 3: 得到每一个训练数据的低维表示后,选择适当的分类器训练。
void TrainSVM(std::map& classes_training_data, std::string& file_postfix, int response_cols, int response_type)
{
using namespace cv;
using namespace std;
vector class_names;
for (map::iterator ite = classes_training_data.begin(); ite != classes_training_data.end(); ++ite)
class_names.push_back(ite->first);
// one vs. all classifiers
#pragma omp parallel for schedule(dynamic)
for (int i = 0; i < class_names.size(); i++)
{
string& class_name = class_names[i];
cout << "training class : " << class_name << " ..." << endl;
// copy class samples and label
Mat samples(0, response_cols, response_type);
Mat labels(0, 1, CV_32FC1); // 0 rows, 1 cols
samples.push_back(classes_training_data[class_name]);
Mat class_label = Mat::ones(classes_training_data[class_name].rows, 1, CV_32FC1);
labels.push_back(class_label);
// copy rest samples and label
for (map::iterator ite = classes_training_data.begin(); ite != classes_training_data.end(); ++ite)
{
string not_class_name = ite->first;
if (not_class_name == class_name)
continue;
Mat& not_class_mat = classes_training_data[not_class_name];
samples.push_back(not_class_mat);
class_label = Mat::zeros(not_class_mat.rows, 1, CV_32FC1);
labels.push_back(class_label);
}
// train and save
if (samples.rows == 0)
continue;
Mat sample_32f;
samples.convertTo(sample_32f, CV_32F);
CvSVMParams svm_param;
svm_param.svm_type = CvSVM::C_SVC;
svm_param.kernel_type = CvSVM::RBF;
//svm_param.nu = 0.5; // in the range 0..1, the larger the value, the smoother the decision boundary
svm_param.C = 5;
svm_param.gamma = 0.1;
//svm_param.degree = 3;
svm_param.term_crit.epsilon = 1e-8;
svm_param.term_crit.max_iter = 1e9;
svm_param.term_crit.type = CV_TERMCRIT_ITER | CV_TERMCRIT_EPS;
CvSVM svm_classifier;
svm_classifier.train(sample_32f, labels, Mat(), Mat(), svm_param);
//svm_classifier.train(sample_32f, labels);
//svm_classifier.train_auto(sample_32f, labels, Mat(), Mat(), svm_param);
// save classifier
string classifier_file_name("SVM_classifier_");
classifier_file_name += file_postfix + "_" + class_name + ".yml";
svm_classifier.save(classifier_file_name.c_str());
cout << classifier_file_name << " saved" << endl;
}
}
int vocabularySvmTrain(string& vocabulary_file , string& postfix_for_output)
{
cout << " ------- Train SVM Classifier -------" << endl;
// read vocabulary from file
cout << "reading vocabulary form file ..."<> vocabulary;
fs.release();
if (vocabulary.rows == 0)
{
//cerr << "Cannot Load Vocabulary File :" << argv[1] << endl;
return -1;
}
// setup BOWImgDescriptorExtractor with vocabulary
Ptr feature_detector(new SurfFeatureDetector(400));
//Ptr feature_detector = Ptr(new PyramidAdaptedFeatureDetector(Ptr(new SurfFeatureDetector(400))));
//Ptr feature_detector = FeatureDetector::create("GridSURF");
//Ptr descriptor_extractor(new SurfDescriptorExtractor());
Ptr descriptor_extractor(new OpponentColorDescriptorExtractor(Ptr(new SurfDescriptorExtractor(400))));
Ptr descriptor_matcher(new FlannBasedMatcher());
//Ptr descriptor_matcher(new BruteForceMatcher>());
BOWImgDescriptorExtractor bowide(descriptor_extractor, descriptor_matcher);
bowide.setVocabulary(vocabulary);
descriptor_matcher->train(); // call this to load dll, for omp
// setup training data for classifiers and extract samples from image files
map classes_training_data;
ExtractTrainingSamples(feature_detector, bowide, classes_training_data);
// show samples information
cout << "Got " << classes_training_data.size() << " classes." << endl;
for (map::iterator ite = classes_training_data.begin(); ite != classes_training_data.end(); ++ite)
cout << "class " << ite->first << " has " << ite->second.rows << " samples" << endl;
// train SVM for each classes
cout << "Training SVMs" << endl;
string postfix = postfix_for_output;
TrainSVM(classes_training_data, postfix, bowide.descriptorSize(), bowide.descriptorType());
system("pause");
return 0;
} step 4: 对新来的样本先映射到聚类中心空间,然后利用得到的分类器进行预测。
// resize to 256x256
void ProcessImage(const cv::Mat& image, cv::Mat& unified_image)
{
int s = cv::min(image.rows, image.cols);
float scale = 256.0 / s;
scale = scale < 1.0 ? scale : 1.0;
Size size(image.cols * scale, image.rows * scale);
cv::resize(image, unified_image, size);
cv::GaussianBlur(unified_image, unified_image, Size(11, 11), 5.0);
}
SVMPredictor::SVMPredictor(std::string vovabulary_file_name, std::string svm_classifier_file_name):
feature_detector(new SurfFeatureDetector()),
descriptor_matcher(new BruteForceMatcher>),
//descriptor_matcher(new FlannBasedMatcher()),
descriptor_extractor(new OpponentColorDescriptorExtractor(Ptr(new SurfDescriptorExtractor())))
{
bool ret = LoadVocabulary(vovabulary_file_name);
assert(ret);
ret = LoadSVMClassifier(svm_classifier_file_name);
assert(ret);
bowide = Ptr(new BOWImgDescriptorExtractor(descriptor_extractor, descriptor_matcher));
bowide->setVocabulary(vocabulary);
}
SVMPredictor::~SVMPredictor(void)
{
}
bool SVMPredictor::LoadVocabulary(std::string file_name)
{
try
{
FileStorage fs(file_name, FileStorage::READ);
fs["vocabulary"] >> vocabulary;
fs.release();
}
catch(...)
{
cerr << "LoadVocabulary error" << endl;
return false;
}
if (vocabulary.rows == 0)
return false;
return true;
}
bool SVMPredictor::LoadSVMClassifier(std::string file_name)
{
try
{
svm.load(file_name.c_str());
}
catch (...)
{
cerr << "LoadSVMClassifiers error" << endl;
return false;
}
return true;
}
std::string SVMPredictor::PredictClass(cv::Mat& input_image)
{
Mat unified_image;
ProcessImage(input_image, unified_image);
vector keypoints;
Mat response_hist;
feature_detector->detect(unified_image, keypoints);
bowide->compute(unified_image, keypoints, response_hist);
int predict_result = (int)svm.predict(response_hist);
char class_buf[8];
itoa((int)predict_result, class_buf, 10);
return class_buf;
} 图片快速分类
ImageClassPredictor::ImageClassPredictor(std::string vocabulary_file_name, std::string classifier_file_prefix):
feature_detector(new SurfFeatureDetector(400)),
//descriptor_matcher(new BruteForceMatcher>),
descriptor_matcher(new FlannBasedMatcher()),
descriptor_extractor(new OpponentColorDescriptorExtractor(Ptr(new SurfDescriptorExtractor(400))))
{
bool ret = LoadVocabulary(vocabulary_file_name);
assert(ret);
ret = LoadSVMClassifiers(classifier_file_prefix);
assert(ret);
//feature_detector = Ptr(new PyramidAdaptedFeatureDetector(Ptr(new SurfFeatureDetector(400))));
bowide = Ptr(new BOWImgDescriptorExtractor(descriptor_extractor, descriptor_matcher));
bowide->setVocabulary(vocabulary);
descriptor_matcher->train();
}
ImageClassPredictor::~ImageClassPredictor(void)
{
}
bool ImageClassPredictor::LoadVocabulary(std::string file_name)
{
try
{
FileStorage fs(file_name, FileStorage::READ);
fs["vocabulary"] >> vocabulary;
fs.release();
}
catch(...)
{
cerr << "LoadVocabulary error" << endl;
return false;
}
if (vocabulary.rows == 0)
return false;
return true;
}
bool ImageClassPredictor::LoadSVMClassifiers(std::string file_prefix)
{
const int classes_count = 10; // totally 10 classes of images
classes_classifiers.clear();
try
{
for (int i = 0; i < classes_count; i++)
{
char class_name[4];
itoa(i + 1, class_name, 10);
string file_name = file_prefix + class_name + ".yml";
//classes_classifiers.insert(pair(class_name, CvSVM()));
classes_classifiers[class_name].load(file_name.c_str());
}
}
catch (...)
{
cerr << "LoadSVMClassifiers error" << endl;
return false;
}
return true;
}
// resize to 256x256
void UnifyImageSize(const cv::Mat& image, cv::Mat& unified_image)
{
int s = cv::min(image.rows, image.cols);
//float scale = 256.0 / s;
//Size size(image.cols * scale, image.rows * scale);
Size size(128, 128);
cv::resize(image, unified_image, size);
//cv::GaussianBlur(unified_image, unified_image, Size(3, 3), 3.0);
//cv::filter2D(unified_image, unified_image, unified_image.depth(), CV_MEDIAN);
cv::medianBlur(unified_image, unified_image, 3);
}
std::string ImageClassPredictor::PredictClass(Mat& input_image)
{
Mat unified_image;
UnifyImageSize(input_image, unified_image);
// sliding window approach
const int window_size = 128; // unified_image.rows < 128 || unified_image.cols < 128 ? cv::min(unified_image.cols, unified_image.rows) : 128;
vector check_points;
for (int i = 0; i < unified_image.cols; i += window_size / 4)
for (int j = 0; j < unified_image.rows; j += window_size / 4)
check_points.push_back(Point(i, j));
map > found_classes;
#pragma omp parallel for
for (int i = 0; i < check_points.size(); i++)
{
Point& p = check_points[i];
// crop window image
Mat image;
unified_image(Rect(p.x - window_size/2, p.y - window_size/2, window_size, window_size) & Rect(0, 0, unified_image.cols, unified_image.rows)).copyTo(image);
if (image.rows == 0 || image.cols == 0)
continue;
// detect keypoints
vector keypoints;
Mat response_hist;
feature_detector->detect(image, keypoints);
bowide->compute(image, keypoints, response_hist);
if (response_hist.cols == 0 || response_hist.rows == 0)
continue;
// predict window image
try
{
float min_distance = FLT_MAX;
string min_class = "!";
for (map::iterator ite = classes_classifiers.begin(); ite != classes_classifiers.end(); ++ite)
{
// signed distance to the margin (support vector)
float predict_distance = ite->second.predict(response_hist, true);
if (predict_distance > 1.0)
continue;
if (predict_distance < min_distance)
{
min_distance = predict_distance;
min_class = ite->first;
}
}
if (min_class == "!")
continue;
#pragma omp critical
{
found_classes[min_class].first++;
found_classes[min_class].second += min_distance;
}
}
catch (cv::Exception)
{
continue;
}
}
// get the best matched class
float max_class_score = -FLT_MAX;
string max_class;
//cout << " -->> ";
for (map >::iterator ite = found_classes.begin(); ite != found_classes.end(); ++ite)
{
float score = abs(ite->second.first * ite->second.second);
//cout << ite->first << ", " << score << " | ";
if (score > 1e10)
continue; // impossible score
if (score > max_class_score)
{
max_class_score = score;
max_class = ite->first;
}
}
//cout << endl;
//cout << "max_score = " << max_class_score << endl;
return max_class;
} 测试
int _tmain(int argc, _TCHAR* argv[])
{
std::string vb_path="c:\\svm\\vocabulary_color_surf_toy.yml";
std::string svm_path="c:\\svm\\SVM_classifier__0.yml";
SVMPredictor predictor(vb_path, svm_path);
//std::cout << "predicting images ... " << std::endl;
//Mat image=imread(argv[1]);
Mat image = imread("c:\\img\\3333.jpg");
//Mat img = imread("G:\\svm\\3333.jpg");
//Mat image;
//cvtColor(img,image,CV_BGR2GRAY);
//imshow("test",image); //cvWaitKey(0);
if (image.rows == 0 || image.cols == 0)
{
std::cout << " test iamge read error!" << endl;
return 0;
}
string predict_label = predictor.PredictClass(image);
if(predict_label=="1")
{
//printf("1");
return 1;
}
else
{
std::string svm_path="c:\\svm\\SVM_classifier__1.yml";
SVMPredictor predictor(vb_path, svm_path);
std::cout << "predicting images ... " << std::endl;
string predict_label = predictor.PredictClass(image);
if(predict_label=="1")
{
//printf("2");
return 2;
}
else
{
//printf("-1");
return 0;
}
}
}在视觉领域,很希望能够利用已知的目标或者图像去得到相关的信息,这在机器人......等领域有着很广泛的应用,所以利用视觉领域中图像检索这一块解释一些基本问题。
Vocabulary建立(数据聚类):
以SIFT 128维特征作为例子。例如现在有1000张训练图片,对每一张训练图片都提取SIFT的128维特征,那么最终可以得到 N(i) * 128的特征,N(i)代表第几张图特征点的个数,因为图片并非完全相同,所以特征点的个数当然是不一样的。接下来就是建立词典的过程,利用现在常用的一些聚类算法,kmeans就OK,选择聚类中心点的个数,1000个也好, 10000个也罢,聚类完成后,得到的就是一个1000(10000) * 128聚类中心点的空间,称之为词典。
这个词典就好比一个容器,通俗一点就是一个直方图的基,利用这个基去统计这些训练样本的个信息。
训练样本的映射:
此时已经得到了一个直方图的基,如下图:
图1: 图中,n表示聚类中心点的个数,用BOW中的文字表示即使字典的个数。
这些直方图的基在像是在空间的一些三维空间的基向量i, j, k, 利用这些基向量去构造别的向量,只需要知道特定的系数就行。所以接下来的步骤就是将原始的图像特征(SIFT 128维)向这些基向量作映射,得到相关的系数,如图:

图2:上图中给出了两个类别的直方图
通过相关的映射,得到不同类别的一个类别的直方图的统计,这样整个BOW特征提取过程就算是完全实现了。接下来如何进行匹配,就是选择分类器的问题了。
分类器的选择:
其实BOW之所以有bag的意思也是将相似的特征进行打包,得到统计的一个范围,这个范围就是直方图的某一个bin。在进行图像检索的时候,接下来就是进行分类器的训练与识别了,例如朴素贝叶斯分类器,支持向量机之类。一般利用BOW的时候,大多数人还是选择支持向量机这玩意,有实验证明BOW结合SVM效果要好于其他的分类器。不过,我没做过对比实验,这里也算提一下。
新来样本的识别:
在训练好分类器后,对于新来的样本,同样先提取SIFT特征,然后将SIFT特征映射到上面图1中的词典中去,然后得到的直方图就可以通过分类器进行分类了。如:
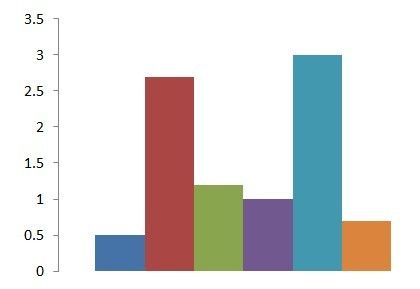
图3 新图片的BOW直方图特征
上图是一张新图映射到词典时得到的直方图,可以看出,这张图片相对于图2的情况而言,更接近类别1,所以通过分类器,理想的装填应该是判断为1。 但是我们都知道,理想状态的出现可能性太小,所以BOW难免会有出错的时候,通过阅读几篇论文,发现现在BOW的识别率大概在60%-80%之间,当然了一方面是数据量巨大的问题,另外一方面也是因为图像之间的相似度高。所以整体来讲,BOW的识别率还是再可以接受的范围。
心得:
其实BOW没有什么特别的理论推导,我觉得仅仅只是将类似SIFT、HOG这些局部特征的统计方法从微观扩展到宏观的过程,利用直方图的统计的特性,构造多个词典,利用简单的距离映射,得到每一副图片的BOW的特征,但是这样一个简单的扩展确实最重要的创新点,同时也构造了一个广泛应用的框架。