Jmeter压测思路+实操+报告分析
RBI性能测试方法,快速瓶颈识别法。
RBI强调了80%的性能问题可以通过吞吐量测试来发现,其他20%的性能问题可以通过引入并发用户数等更复杂的场景来发现。
执行方案
核心思路: 性能测试中不只关注并发数,尤其是单接口性能测试的时候,更多关注吞吐量、响应时间等指标来评估服务端性能。验证服务端最高每秒能正确处理的请求数,以及请求的响应延时情况。
首先明确下并发的概念。在性能测试中并发可以理解为同一时刻做不同的事,或同一时刻做同样的事。一般我们在性能测试的时候也是这么去模拟的。那这个同一时刻的并发是很难做到的。要知道我们用来发起压力的测试工具本身要能做到同一时刻发起压力,如果设置线程数过多,负载机本身资源不足会有排队,请求建立和服务端的连接过程会排队,请求数据发送到服务的时候在网络队列上也会排队,请求数据达到服务端,在服务端也会进行排队,所以严格意义上的并发多少用户数等等是比较难做到的。
为什么要压测
这个问题问的其实挺没有必要的,做开发的同学应该都很清楚,压测的必要性,压力测试主要目的就是让我们在上线前能够了解到我们系统的承载能力,和当前、未来系统压力的提升情况,能够评估出当前系统的承载情况能不能满足当前和未来一段时间的正常运行。压力测试也让架构师和开发人员能够对自己负责的系统做到心中有数,当有大并发需求的活动或者其他突发事件导致的访问暴增,能够提前做好预估和准备应急预案。
压测难点
说了那么多,都是压测的必要性,那么既然要测那么重要,我们每次发版本都做一下压测不就好了,这么说的同学一定是没真正参与过压测的,参与过压测的同学都是谈压测色变,不管是测试人员还是开发人员都很害怕压测。大家为什么这么害怕压测,主要原因主要有下面这些压测的难点导致的:
1)压测环境难准备
在日常工作过程中,我们肯定遇到过压测环境难申请的问题,为什么难申请主要是因为压测一般要求环境和生产环境一致,那么就意味着压测机器资源的稀缺,没有哪家公司会长期准备所有系统的压测环境,毕竟成本太高,所以一般公司都是准备一些机器让所有系统共用压测环境,每次一个系统要做压测之前都要把上一个压测系统的数据和应用版本、中间件、数据库停掉或删掉,这是非常浪费时间的工作,所以很多公司现在在压测的环境准备都使用docker来准备环境,只需要定期更新docker image就可以,这就可以做到快速还原环境,需要用的时候直接把被测系统的docker image拉下来就行了,所以压测环境已经不再是我们的问题了。
2)压测数据难准备
在压测过程中还有个难点就是压测数据准备,如何能尽量真实的模拟生产的数据,最简单的就是录制一段时间生产的访问报文,然后在用压测环境进行正常回放和倍数回放。录制生产真实报文的工作,目前还没有遇到特别好的工具,大部分公司都是自己写个工具进行网络层面的嗅探,将嗅探到的生产报文再加工成Jmeter或者LoadRunner这些压测工具能够识别的压测脚本。这个工作其实只要搞通了一遍以后也没有那么复杂了。
3)压测工具使用复杂
压测工具曾几何时不管是测试人员还是开发人员都觉得很高大上,很难使用和学习,其实这个观念在10年前确实是这样的,但是随着越来越多的开源压测工具的兴起,那些复杂又笨重的商用压测工具渐渐被大家淡忘,现在有很多开源的服务端压测工具,使用起来还是很简单的,而且该有的功能基本都有了,前面废话了那么多,就是要说明压测已经不像以前那么复杂了,现在通过简单的环境配置和工具就可以快速的完成一次压力测试,环境准备这个我帮不了大家,今天文章重点就是介绍下开源压测工具的翘楚“Jmeter”的使用和结果分析,让大家爱上压测。
压测指标
压测结果指标基本概念:
Samples:表示一共发出的请求数
Average:平均响应时间,默认情况下是单个Request的平均响应时间(ms)
Error%:测试出现的错误请求数量百分比。若出现错误就要看服务端的日志,配合开发查找定位原因
Throughput:简称tps,吞吐量,默认情况下表示每秒处理的请求数,也就是指服务器处理能力,tps越高说明服务器处理能力越好
我们常用的压测指标其实并不多,主要就是用户并发量和tps,一般这两个指标是一起使用的,就是在用户这么大的并发量的前提下tps是每秒多少。这么说有点绕口,举个简单的例子,500个用户同时发起服务请求,服务端能够稳定正确处理的交易数。这里能够稳定正确处理的交易数就是我们常说的tps,也叫做服务处理吞吐量,例子中提到的500个用户同时发起服务请求,“同时发起”也很容易被误解,这里说的500用户同时发起请求是指的是500个用户同一秒钟发起的请求,并不是系统同时只能承载500个在线用户,这两个概念是完全不一样的,在制定指标的时候千万不要搞混,尤其是和业务人员沟通的时候一定要说清楚。一般来说我们会统计一段时间生产环境当前在线用户的会话数和接口当时被调用的次数,做个线性的乘数,通过这个乘数可以根据最后压测出的数据来评估系统大概能够承载的用户数。
使用Jmeter随时压测
下面我们就详细介绍下如何使用Jmeter来进行服务端接口压测,Jmeter安装起来非常方便,只需要去官网下载解压直接运行shell就可以了。
官网下载地址:http://jmeter.apache.org/download_jmeter.cgi
基本概念
在介绍如何使用Jmeter之前先介绍下Jmeter里的一些基本概念:
1)测试计划是使用 JMeter 进行测试的起点,它是其它 JMeter 测试元件的容器。
2)线程组:代表一定数量的并发用户,它可以用来模拟并发用户发送请求。实际的请求内容在Sampler中定义,它被线程组包含。可以在“测试计划->添加->线程组”来建立它,然后在线程组面板里有几个输入栏:线程数、Ramp-Up Period(in seconds)、循环次数,其中Ramp-Up Period(in seconds)表示在这时间内创建完所有的线程。如有8个线程,Ramp-Up = 200秒,那么线程的启动时间间隔为200/8=25秒,这样的好处是:一开始不会对服务器有太大的负载。线程组是为模拟并发负载而设计。
3)取样器(Sampler):模拟各种请求。所有实际的测试任务都由取样器承担,存在很多种请求。如:HTTP 、ftp请求等等。
4)监听器:负责收集测试结果,同时也被告知了结果显示的方式。功能是对取样器的请求结果显示、统计一些数据(吞吐量、KB/S……)等。
5)逻辑控制器:允许自定义JMeter发送请求的行为逻辑,它与Sampler结合使用可以模拟复杂的请求序列。
6)断言:用于来判断请求响应的结果是否如用户所期望,是否正确。它可以用来隔离问题域,即在确保功能正确的前提下执行压力测试。这个限制对于有效的测试是非常有用的。
7)定时器:负责定义请求(线程)之间的延迟间隔,模拟对服务器的连续请求。
8)配置元件维护Sampler需要的配置信息,并根据实际的需要会修改请求的内容。
9)前置处理器和后置处理器负责在生成请求之前和之后完成工作。前置处理器常常用来修改请求的设置,后置处理器则常常用来处理响应的数据。
执行步骤【探索tps模式】
1,配置线程【线程数配置,需求并发用户在1000,这里线程数可配置100–300,一般来说,tps模式不一定需要高并发,线程数尽量不超过1000】;
持续时间,时间越长,准确性越高,一般定义为5–30分钟内:300秒–1800秒;
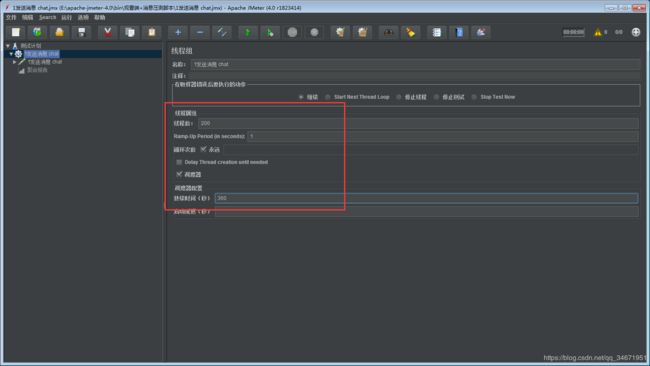
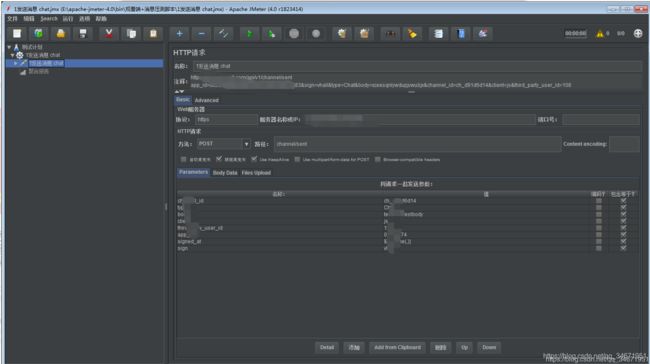
2,配置http或https协议请求
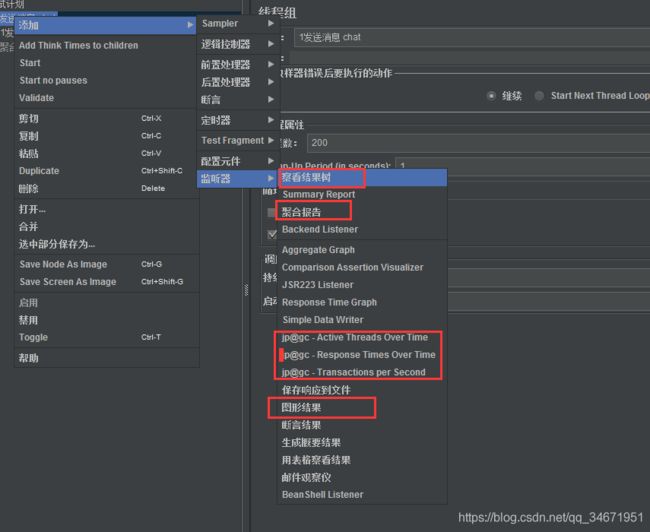
3,配置监听器【1,注意监听器影响性能,尽量少增加监听器;2,察看结果树只用在请求调试,调试通过后,务必删除或屏蔽;】
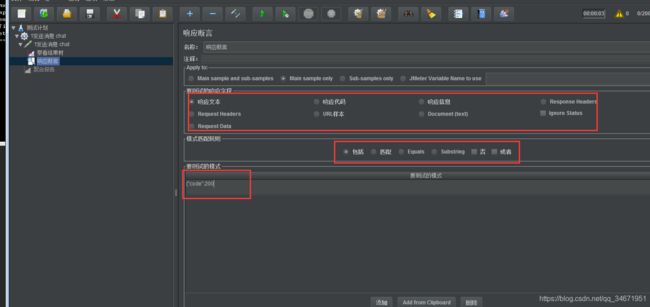
4,响应断言【形成完整校验,尽量添加;根据实际修改】
何时可以结束压测
一般来说,主要监控聚合报告中三个指标:
1,95%line>=3000ms或5000ms;
90%line、95%line、99%line,性能要求高的情况下,监控99%line,一般使用90%line或95%line都可;
释义:90%Line不等于:90%用户的平均响应时间
真正解释:一组n个观测值按数值大小排列如,处于p%位置的值称第p百分位数
举例说明:
有10个数:
1、2、3、4、5、6、7、8、9、10 按由大到小将其排列。
求它的第90%百分位,也就是第9个数刚好是9 ,那么他的90%Line 就是9
再来解释90%Line
一组数由小到大进行排列,找到他的第90%个数(假如是12),那么这个数组中有90%的数将小于等于12
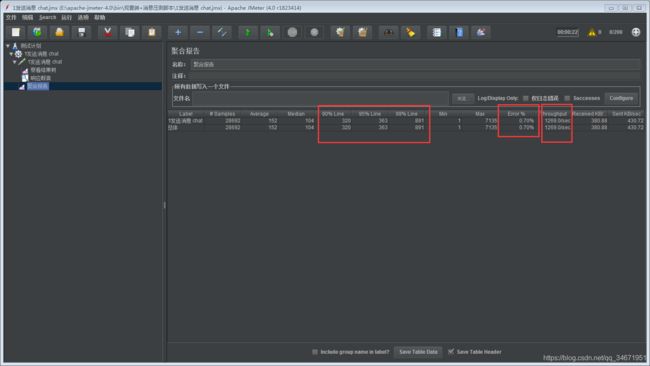
2,error%>=预期范围(一般来说1%左右)
3,throughput>=预期值【吞吐量一般来说等于tps,jmeter衡量性能重要指标,当不断增加并发线程的情况下,tps恒定一个指标后,出现下降状态,最高的tps则为阈值tps】
这里可见,单接口吞吐量,95%=363ms,error%<0.70%的情况下,tp在1269左右,性能说明很高了
测试监控
1,并发测试监控
并发测试直接发起指定数量的请求,比如一起发起10万请求看一下系统的处理能力,这个时候如果需要服务器的资源使用信息,就不能使用比如zabbix监控系统了,因为一般处理10万请求,对于我们来说20秒可以处理完毕,但是zabbix数据采集是每分钟一次,这样采集到的数据明显是不准的,这样就需要通过系统自带的监控命令,来实时查询服务器的性能,比如可以通过dstat或者glances等动态监控命令来分析系统的性能。
2,稳定性测试监控
稳定性测试就是持续不断模拟指定数量请求,来访问服务器,比如我每秒向测试服务器发起4000请求,持续12小时,来看看服务器会出现什么情况,这个时候就需要用到zabbix来进行监控了,下面是我做性能测试的部分监控接口,包含tomcat每秒请求,服务器入口流量,整个集群每分钟请求的http状态码统计,还有服务器资源使用信息。
测试报告分析思路:
1)Error%:确认是否允许错误的发生或者错误率允许在多大的范围内;
2)Throughput:吞吐量每秒请求的数大于并发数,则可以慢慢的往上面增加;若在压测的机器性能很好的情况下,出现吞吐量小于并发数,说明并发数不能再增加了,可以慢慢的往下减,找到最佳的并发数;
3)压测结束,登陆相应的web服务器查看CPU等性能指标,进行数据的分析;
4)最大的tps:不断的增加并发数,加到tps达到一定值开始出现下降,那么那个值就是最大的tps。
5)最大的并发数:最大的并发数和最大的tps是不同的概率,一般不断增加并发数,达到一个值后,服务器出现请求超时,则可认为该值为最大的并发数。
6)压测过程出现性能瓶颈,若压力机任务管理器查看到的cpu、网络和cpu都正常,未达到90%以上,则可以说明服务器有问题,压力机没有问题。
7)影响性能考虑点包括:数据库、应用程序、中间件(tomact、Nginx)、网络和操作系统等方面。
【友情提示】:
分布式可能需要注意的事项以及压测可能遇到的问题
A、若是脚本中设置的并发线程数是100,采用3台slaver机器去施加压力,那么对于服务端来说,此时的并发线程数是300。
B、为了减少出错的可能性,最好按照如下Jmeter 分布式要求:
1、各个机器在相同目录下安装相同版本的jdk;
2、各个机器在相同的目录下安装相同版本的jmeter;
3、配置/etc/hosts的IP和hostname的映射。
4、修改各个机器的jmeter的默认内存参数,从512m调整为合适大小。
5、 对压测中出现的异常或错误,可以尝试自己分析下。Response code: 500通常情况下是服务端出现问题,可以查看服务端的日志,看看是否有异常或错误信息,根据提示信息来定位分析,排查的时候可以根据服务端的业务架构一层层的排查下去,直至找到发生问题的服务。对自己没见过的或不太熟悉的错误信息建议google。 比如:Non HTTP response code: java.net.SocketException这种错误,google一把大致就有些可行的解决方案。[Jmeter-User] JMeter Non HTTP response code: java.net.SocketException。