目标检测论文笔记 2019.11
初入门目标检测,近两个月看的一些论文笔记汇总。
尽量用简单的语言概括论文的思想,提出highlight,具体实现细节参考各论文。
文章目录
- General
- 《MoCo: Momentum Contrast for Unsupervised Visual Representation Learning 》2019
- Instance Segmentation
- 《Mask RCNN》2018
- Object detection
- Pipeline
- 《selective search for object recognition》2012
- 《R-CNN》2014 /《Fast R-CNN》2015 /《Faster R-CNN》2015 /《R-FCN》2016
- 《Cascade R-CNN: delving into high quality object detection》
- 《Grid R-CNN》
- 《YOLO: you only look once》2016
- 《YOLO v2》2016 / 《YOLO v3》2018
- 《SSD:single shot multibox detector》2016
- 《CornerNet: detecting objects as paired keypoints》2019
- 《CenterNet: Objects as points》2019
- 《FCOS: Fully convolutionall one-stage object detection》2019
- Tricks
- 《FPN: feature pyramid networks for object detection》 2017
- 《DCN: Deformable convolutional networks》2017
- 《RetinaNet: Focal loss for dense object detection》2018
- 《GA: Region Proposal by Guided Anchoring 》2019
General
《MoCo: Momentum Contrast for Unsupervised Visual Representation Learning 》2019
阅读日期:2019.11.21
Highlight
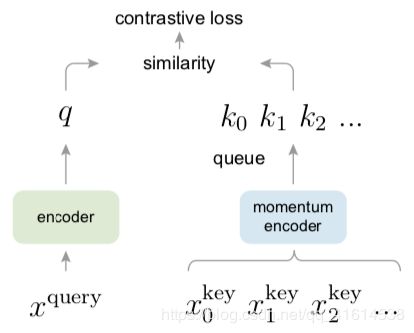
- unsupuvised visual representation learning
- buiding large and consistent dictionary
- Dictionary as Queue: 解耦dict大小与mini-batch大小,使得dict可以足够大,不受制于内存
- Momentum update: 逐渐更新key encoder的模型参数,保持queue中keys的一致性
- shuffling BN:多块GPU各自进行BN。在key_encoder进行编码前,先shuffle minibatch,编码完后shuffle back,而query_encoder不进行shuffle,保证两者进行BN用的batch信息不来自同一组batch,避免intra-batch信息泄漏,使模型过于容易找到一个low-loss solution,而representation的提取却不够general.
算法流程
-
query-encoder 和 key-encoder 初始化为相同的网络
-
对于每个minibatch,对图像做两次随机增强,分别用两个encoder进行编码(生成queries和keys),keys不计算梯度
-
将当前batch对应图片生成的key作为正例(1个),Queue中的所有keys作为负例,计算交叉熵损失
contrastive loss: similarity of sample pairs in representation space
L q = − l o g e x p ( q ⋅ k + / τ ) ∑ i = 0 K e x p ( q ⋅ k i / τ ) L_q = -log{exp(q·k_+/\tau) \over \sum_{i=0}^K exp(q·k_i/\tau)} Lq=−log∑i=0Kexp(q⋅ki/τ)exp(q⋅k+/τ)
-
back propagation 更新query-encoder的模型参数, momentum update 更新key-encoder
-
更新Queue(Dictionary): enqueue current minibatch, dequeue the earliest minibatch
Instance Segmentation
《Mask RCNN》2018
阅读日期:2019.11.22
Highlight
-
在faster-RCNN上做了微小改动,添加一个head用于预测binary mask,实现实例分割,5FPS。还可以被拓展用于keypoint检测任务,把每个关键点作为一个one-hot mask.
-
提出RoI Align,通过双线性插值,避免量化,使提取的特征更好地保持原图位置信息,这一点对生成准确的mask非常重要,而分类任务则对位置信息更鲁棒一些。
-
解耦classification和segmentation,对每个类别都分别预测一个binary mask,避免类别竞争
Models Per pixel Loss 解耦 Mask RCNN sigmoid BCE 竞争 traditional FCN Softmax Multinomial cross-entropy
Object detection
Pipeline
Two-stage系列:R-CNN,fast R-CNN,faster R-CNN,R-FCN
One-stage with anchor:YOLO,SSD
One-stage anchor-free :CornerNet,CenterNet,FCOS
《selective search for object recognition》2012
阅读日期:2019.10.23
Highlight
- 结合exhaustive search & segmentation提出了一种类别无关的region proposal方法,召回率99%
- 捕捉多尺度信息(by hierarchical algorithm),多样化的选区合并策略,计算速度快(在当时可能成立,但在R-CNN系列成为性能瓶颈)
算法流程
- 生成原始选区(using region-based feature algorithm),加入region proposals L L L
- 计算选区间相似度(多样化策略:颜色/纹理/大小/吻合度),放入 S S S
- 通过贪心策略每次合并相似度最高的两个选区,合并结果放入 L L L,从 S S S中删除原来两个小选区相关的相似度,并计算新选区与各剩余选区的相似度放入 S S S。重复直到最终所有选区合并为一个大选区( S = ϕ S=\phi S=ϕ)
- 输出所有region proposal L L L
《R-CNN》2014 /《Fast R-CNN》2015 /《Faster R-CNN》2015 /《R-FCN》2016
阅读日期:2019.10.23 -24
共同点:都属于two-stage detection,先生成类别无关的proposal region(区分前景/背景),再对每个proposal进行分类。利用了transfer learning的思想。考虑平移不变性,多尺度性。采用非极大值抑制消重。
不同点:速度越来越快(faster RCNN可以达到实时5fps),共享参数越来越多,整体网络结构越来越整合。
R-CNN
先由selective search算法提出region proposal,每个proposal分别通过CNN编码为一个4096维的特征,再单独训练SVM针对不同类别进行打分。额外训练一个CNN对bbx的位置进行回归修正。
每个阶段都是单独训练的,所以开销大。训练/测试时间都很长。
Fast R-CNN
- Feature map sharing & ROI pooling layer
在R-CNN中,每个proposal分别做卷积有大量重复操作,因此本论文提出对整张输入图片做卷积,生成一个被全体proposal共享的feature map,大大减少了卷积次数。各proposal根据感受野映射到feature map上,再通过RoI pooling layer转换为同样大小的特征。
- trained end-to-end with multi-task loss: 同时做分类和bbox regression
RoI feature vector同时连接两个sibling FC layer,一个做分类,一个做回归
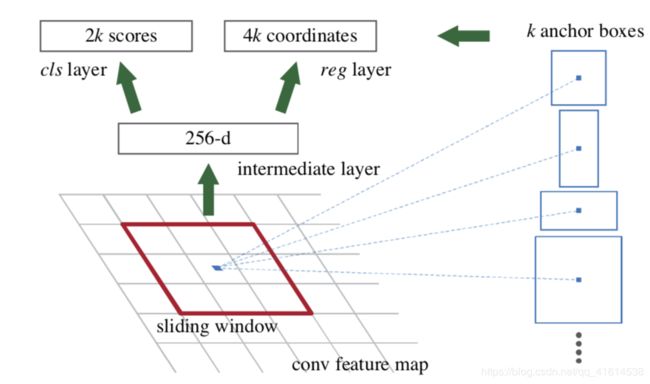
Faster R-CNN
- Region proposal network(RPN)
对于前两种算法而言,bottleneck都是最初提出region proposal的速度太慢。因此本论文提出一种通过CNN,自动预测每个位置的bbx和objectness score的方法。
通过pyramid of anchors,达到高效的多尺度提取的效果(相比于pyramids of features / pyramids of filters)。虽然每个feature感受野一样,得益于anchor,能够提取不同尺度的信息。
- merge RPN and Fast R-CNN -> train a unified single network
RPN和detection network共享feature map层,通过alternate training的方法(4-step)进行训练。
R-FCN region-based fully convolutional networks
论文提出观点,分类的平移不变性&目标检测的平移敏感性,这两者之间的矛盾导致使用普通的全共享卷积网络进行目标检测精度极低(用于分类的全卷积网络对位置信息不敏感)。为了解决这个问题,先前的方案插入了RoI-wise子网,在其后构造更深的网络来提高精度,但每个RoI计算不共享导致速度慢。
本论文提出将所有耗时的卷积操作放在整张图片上,并生成最终的position-sensitive score maps在所有RoI之间共享。position-sensitive RoI pooling之后,没有任何需要学习的参数,简单计算平均得分即可得出每个分类上的分数。简单起见,使用了类别无关的bbx的回归。
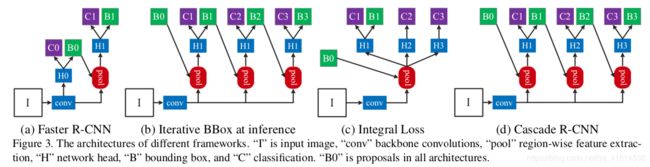
《Cascade R-CNN: delving into high quality object detection》
阅读日期:2019.11.8
这篇论文的关注点很有意思。在two-stage detecor训练过程中,我们都要人为设定一个IoU_threshold,第一阶段提出的proposal的IoU高于阈值的作为正样本,继续第二阶段分类器的训练。根据经验大多设置为0.5,但是为什么要这样设置,这是最好的选择吗?作者对此进行了实验。
实验发现,随着提高训练的IoU_thr至0.7,检测精度反而下降,主要原因有二:
- 正样本更少,导致过拟合
- inference时,由RPN提出的proposal的IoU低于训练时输入的正样本,导致mismatch (作者通过另一实验发现,regressor在输入图片的IoU与设置的IoU_thr接近时优化效果最好,且regressor输出图片的IoU普遍高于输入。也就是说,regressor有普遍优化效果,且对与自身训练精度一致的图片优化更好)
基于上述发现,提出 级联式检测器 cascade R-CNN 解决上面两个问题:
- Resampling:每个stage进行resample,调整合适的正负样本比例,同时因为cascade RCNN能在每个stage逐步提高输出图片的IoU,因此提高IoU_thr后正样本数量不会减少太多
- 级联训练 & 级联检测:保持训练和检测时输入图片的IoU一致性
highlight
这是一个逐步优化的过程,前一个stage的输出是精度更高的图片,该分布刚好适合下一个stage中IoU_thr更高的regressor进行训练。实验证明,该级联训练的方法对二阶段检测算法有着普遍的效果提高。
《Grid R-CNN》
阅读日期:2019.11.9
highlight
- 传统RCNN中将bbox的定位用fc+回归的方式来做,本文提出了用FCN来保持空间信息,通过预测pixel level的grid points来定位物体。
- Feature map level information fusion:对相邻点的feature map进行融合,互相矫正
- Extended region mapping:第一阶段提出的proposal很可能没覆盖整个object,导致许多grid point 没有落在proposal中。如果简单使用enlarge proposal进行RoI pooling会导致引入背景信息或其他物体,导致detector精度下降;本文提出RoI不变,在FCN得到的heatmap映射为原图时,映射到原proposal的两倍大小
模型架构:只是修改了二阶段检测器的bbox regressor部分 -> FCN
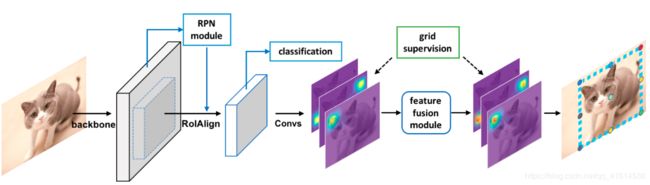
-
将物体的bbox划分为N*N的grid,共生成N*N个grid point(包括内部)
-
对backbone的输出的特征做FCN,得到N*N张heatmap,每个heatmap对应一个grid point的分布概率
-
grid points feature fusion:对相邻点的heatmap做融合(卷积后叠加),起校准效果
-
每个heatmap中找到最大值点作为grid point,映射回原图(extended region mapping),bbox的真实边界通过同一条边上的grid point的heatmap概率加权得到
《YOLO: you only look once》2016
阅读日期:2019.10.24
Highlight
- 提出了一种one-stage的目标检测方法,将目标检测作为一个回归任务(同时对bbx和分类概率),使用简单单一的网络结构,训练方便
- 相比于SOTA的方法,localization error更高,但对背景的假正例预测更少
- 速度极快!YOLO 45 fps, fast YOLO 155 fps
- 泛化能力强:能在自然风景上训练,在艺术作品上预测
模型架构
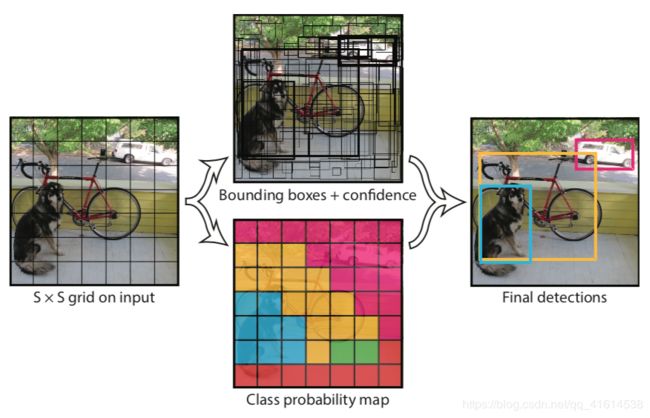
-
将输入的完整图像划分为 S ∗ S S*S S∗S个grid,对每个grid预测 ( 5 ∗ B + C ) (5*B+C) (5∗B+C)个值 -> 卷积+全连接
- B个bbx : 包括五个参数,位置x,y,w,h, 包含物体的概率$confidence $(IoU)
- 针对每个分类的条件概率,共C个
-
测试时各bbx的confidence乘以各分类条件概率p,可得到各bbx属于某分类的概率,再做NMS
-
训练时先在ImageNet上预训练卷积层,再fine tune。训练时对每个ground truth object只取一个IoU最大的bbx作为responsible bbx。
Multi-part loss = bbx + confidence + classification
Limitations
- 对一群出现的小物体识别能力差 <- 空间限制强,每个grid提出的bbx少
- 难以泛化到特殊长宽比例的物体 <- 通过数据来学习预测bbx
- localization的精度差
《YOLO v2》2016 / 《YOLO v3》2018
阅读日期:2019.10.25
《YOLO9000: Better, Faster, Stronger》
改进YOLO,简化网络结构
- Batch normalization 替代 dropout 来预防过拟合
- 使用更高分辨率的图片先在分类网络上fine tune,再迁移到detection任务上微调
- 使用类似faster RCNN的 anchor box 替代 原YOLO只对每个grid预测两个bbx
- 提出更多的预选bbx,解决YOLO对密集小物体的检测缺陷
- 对每个anchor box预测 分类条件概率、objectiveness、边界框修正(YOLO的分类条件概率是对每个grid进行预测,而不是对每个bbx)
- 对anchor的形状先验不再人工指定,而是用在训练集做k-means的方法得到更能表征的anchor
- 边界框修正的参数进行约束,预测绝对位置,使bbx的中心落在对应的grid cell中
- 添加feature map的通道数,通过stack前面高分辨率的特征(passthrough layer)类似ResNet
Multi-scale training
因为网络是全卷积的,所有在训练时使用不同大小的图片,这样网络对不同分辨率的图片的特征提取能力都会提升,在test time就可以用同一个模型预测不同分辨率的图片,自由选择speed/accuracy trade-off
分类、检测联合训练,使YOLO v2可以分类超过9000种物体
Hierarchical classification,根据类别从属关系构造WordTree,在每个节点预测条件概率。
训练时混合detection和classification数据集,碰到detection数据时,正常BP,但对层级分类部分只传递标签分类以上的;碰到classification数据时,找到对标签分类打分最高的bbx,只在这个bbx的分类预测树上做BP。
通过这种联合训练,可对detection数据集中没有的分类进行预测,也可预测出未被方框标注过的物体。
《YOLO v3: An Incremental Improvement》
- 用LR对各bbx的objectness进行预测,取IOU>0.5为正例 (原先是作为IOU回归任务处理的)
- 对multilabel分类任务,对每个类别独立使用LR并用cross entropy loss
对比softmax(mutual exclusive)- 对小物体检测能力好,IOU=0.5的标准下准确度很好,但不能更精准地localization
《SSD:single shot multibox detector》2016
和YOLO很类似,一些区别如下
- 在多尺度的feature maps上用多个不同尺寸的anchor作bbx预测,最后将所有bbx结果合并考虑做NMS
- 用卷积的方法来做bbx和cls的预测,而YOLO最后采用了2个FC层
《CornerNet: detecting objects as paired keypoints》2019
阅读日期:2019.11.8
highlight
-
One-stage, anchor-free
-
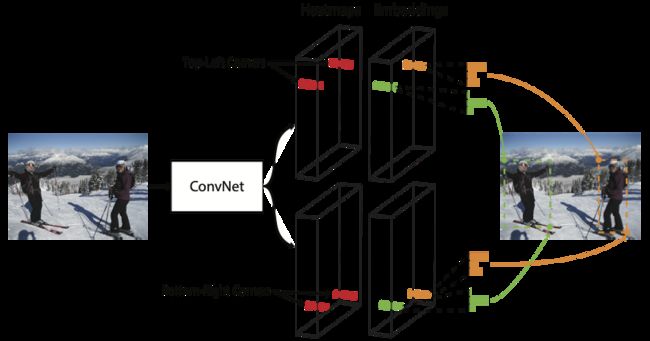
把检测bbox的任务简化为检测bbox的左上和右下两个角点(heatmap),并对每个角点生成embedding vector,用embedding的距离来匹配角点生成bbox
-
角点往往远离物体中心,为了找到角点,提出corner pooling
-
使用hourglass作为backbone,只是用网络最后一层特征输出,不用FPN
-
使用角点匹配的好处是,减少了bbox的离散空间, O ( w h ) O(wh) O(wh)个角点可以生成 O ( w 2 h 2 ) O(w^2h^2) O(w2h2)个可能的bbox.
模型loss设计:先coner pooling,再生成heat map / embedding / offset
- heatmap:label在gt角点周围呈高斯分布,variant of focal loss 使越接近gt的点penalty越小
- offset:不同类别共享offset,SmoothL1Loss
- Embedding: pull & push loss (同类相近,不同类相斥)
<--有趣的loss
《CenterNet: Objects as points》2019
Highlight
- 通过每个类别的heatmap找到center point,其他参数(size of bbx/3D location)通过回归得到
- 不需要post-processing,NMS(不可微)被提取中心点时的max pooling取代,实现真正的end-to-end training
模型
-
Loss = keypoint probability(heatmap) + local offset of keypoint + bbx regression
-
Inference
- 对每个类别分别在heatmap上提取局部最大值,3*3 max pooling
- 保留数值最大的100个峰值点,把heatmap看作分类置信度
- 计算每个峰值点的offset和bbx regression,确定bbx
《FCOS: Fully convolutionall one-stage object detection》2019
阅读日期:2019.11.6
Highlight
-
与其他FCN-solvable tasks比如语义分割相统一,对per-pixel进行目标检测任务
-
anchor free & proposal free,避免敏感的超参,避免类别不平衡,且省时省内存。与CenterNet只有keypoint点是正样本不同,本模型中每个落在目标区域内的像素点都被认为是正样本
-
采用了FPN的结构,解决传统FCN用于目标检测的两个问题:low recall / ambiguous overlapping bboxes
在不同层级的feature map上预测不同大小的物体
模型

对每个像素点,计算classification \ centerness \ regression
- classification 通过C个二分类器组成,focal loss。每个落在目标区域内的像素点都被认为是正样本。
- Centerness 用于抑制目标区域内远离中心的点,因为它们回归出来的bbox不理想。
- Regression 直接计算每个正样本点到对应bbox的四个距离,用 e x p ( s i x ) exp(s_ix) exp(six)做基,FPN的不同层共享heads
Tricks
《FPN: feature pyramid networks for object detection》 2017
阅读日期:2019.11.5
Highlight:特征金字塔在手工提取特征时期被广泛使用,能够保持检测任务中的尺度不变性。本文利用深度卷积网络内在的金字塔特性,在很小的cost下构造一个多尺度的层级金字塔,并使每一层都能表达高层语义。每一层都能用于预测,并共享head部分的参数。
模型架构
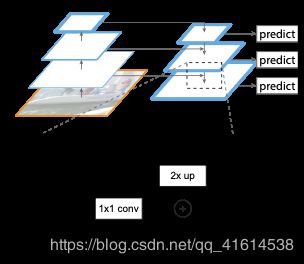
- Bottom-up pathway:就是backbone的前向传播CNN,把输出的空间大小相同的层分为同一个
stage,取每个stage的最后一层输出作为金字塔的一层,相邻stage的大小相差2倍。 - Top-down pathway and lateral connections:通过对top feature上采样得到空间上更粗粒度但语义更强的feature,再element-wise加上lateral connections(1*1 conv)来维持空间信息,最后通过一个3*3 conv 消除由上采样引入的空间偏差,生成最终的feature map。
Applications
- FPN for RPN:anchor对每层feature map固定scale,取不同ratio;head参数共享。
- FPN for Fast RCNN:对越小的RoI,用更高分辨率的feature map进行特征提取。
《DCN: Deformable convolutional networks》2017
阅读日期:2019.11.5
Highlight:传统CNN受卷积层几何转换的限制,本文提出一种可学习的dense offset来使高层特征可以有不规则的感受野,可解释性强效果好。减轻了对数据增强、设计变换不变特征/算法的依赖。
两种模型
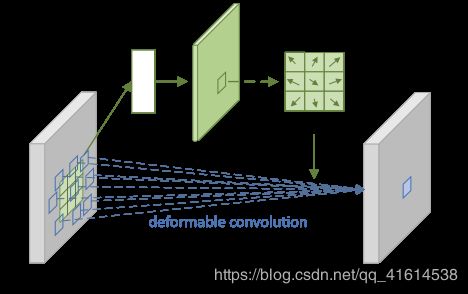
- deformable convolution:对输入的feature map上的每个特征点计算一个2D-offset(通过对该input feature map的卷积),应用于卷积,小数偏移量用邻近位置的双线性插值来逼近。
- Deformable ROI pooling:先对RoI做普通RoI pooling得到pooled feature maps,加一个fc层得到offsets(RoI的每个bin共享一个offset,整个bin一起平移)。在实验中发现,Deformable RoI pooling得到的bins会向前景偏移。
《RetinaNet: Focal loss for dense object detection》2018
阅读日期:2019.11.6
highlight
-
提出观点:前景-背景样本数量的极度不平衡,是one-stage detectors精度普遍低于two-stage detectors的关键。过多的负样本主导了loss,使正样本的分类器根本无法学习。
在two-stage detecor中,可以通过(1)第一阶段region proposal过滤大量简单负样本 (2)第二阶段训练前进行有偏采样使正负样本比例保持在合适范围。one-stage detectors 多使用anchors进行密集采样,引入了大量 easy negative.
-
Robust loss希望outliers(hard example with large errors)贡献更少的loss,而focal loss的设计理念刚好与之相反,focal loss更关注hard examples。
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) . FL(p_t) = -\alpha_t(1-p_t)^\gamma log(p_t). FL(pt)=−αt(1−pt)γlog(pt).
其中 p t p_t pt代表预测gt的概率, α t \alpha_t αt 是超参数,用于调节正负样本的不平衡; ( 1 − p t ) γ (1-p_t)^\gamma (1−pt)γ 使得loss更加关注hard exmaple.
-
focal loss的设计非常简洁直观,只是在交叉熵 C E ( p t ) = − l o g ( P t ) CE(p_t) = -log(P_t) CE(pt)=−log(Pt)上略加改动,可以很容易地应用到多种模型中。且其效果很好,应用了该loss的RetinaNet能够达到one-stage的速度,同时超过two-stage的精度。
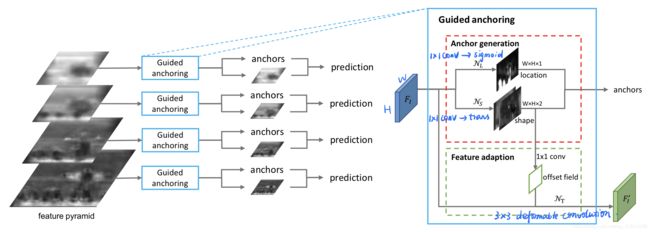
《GA: Region Proposal by Guided Anchoring 》2019
阅读日期:2019.11.23
hightlight
-
dense amd predefined anchors -> Non-uniform and arbitrary shaped sparse anchors
产生更少的anchor,recall几乎不变,precision提高
-
将anchor的联合分布拆解为两个条件概率分布(location/wh)的连乘
-
提出anchor应该遵循的原则:alignment / consistency
- 为保证alignment,不对center位置作回归,只回归wh
- feature adaption: 由于在同一层feature上使用了任意形状大小的anchor,要求feature map上不同位置的表意程度也不同,要适应该位置对应的anchor(即consistency),采用deformable conv
model