【ElasticSearch从入门到放弃系列 三】Lucene的基本概念和使用
上一篇blog介绍了全文检索的实现思路,这一篇呢主要介绍开源的搜索引擎Lucene是如何基于这样的思路来进行具体的实现的。
Lucene基本概念
Lucene是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。在Java开发环境里Lucene是一个成熟的免费开源工具。一句话概括,就是一组实现全文检索的Jar包。
Lucene环境搭建
首先需要从官网 下载Lucene,Java需要1.8以上的版本支持,,内容组成如下,实际上我们这里用到的就是以下的5个jar包:

其中commons-io是为了进行文件的读写,junit是为了进行单元测试。首先我们提供如下待检索文件:
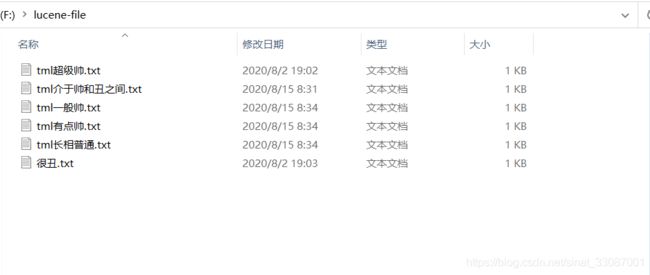
然后使用lucene建立倒排索引,来通过关键字快速检索文档。按照上一篇blog提到的需求我们来做一下。
索引的基本使用
接下来我们看看如何创建索引、查询索引,完成全流程
创建索引
创建一个java工程,并导入jar包:

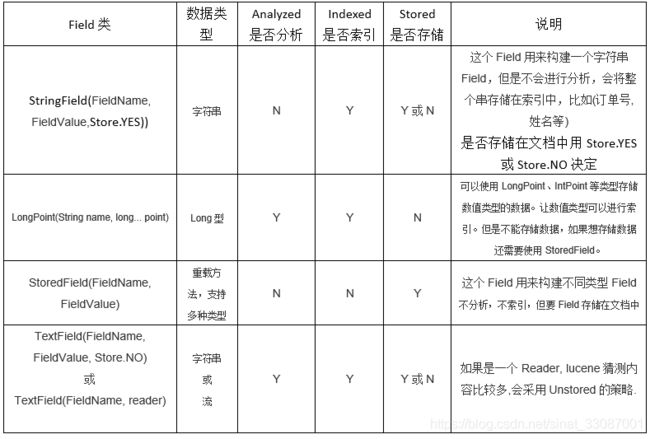
Field的几个属性
创建Field的时候,有几种重载方法可以选择:其实string就是索引不分词、textfield就是索引分词。
代码执行
然后在程序里读取文件转为lucene使用到的相关对象:
package com.company;
import org.apache.commons.io.FileUtils;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.junit.Test;
import java.io.File;
public class Main {
//创建索引
@Test
public void createIndex() throws Exception {
//创建indexwriter对象
Directory directory = FSDirectory.open(new File("F:\\lucene-index").toPath());
IndexWriterConfig config = new IndexWriterConfig();
IndexWriter indexWriter = new IndexWriter(directory, config);
//原始文档的路径
File dir = new File("F:\\lucene-file");
for (File f : dir.listFiles()) {
String fileName = f.getName();
String fileContent = FileUtils.readFileToString(f);
String filePath = f.getPath();
long fileSize = FileUtils.sizeOf(f);
//创建文件名域
//第一个参数:域的名称
//第二个参数:域的内容
//第三个参数:是否存储
//(分析、索引、存储)【索引分词存储】
Field fileNameField = new TextField("filename", fileName, Field.Store.YES);
//文件大小域(分析、索引、不存储)【索引分词不存储】
Field fileSizeField = new LongPoint("size", fileSize);
//文件路径域(不分析、索引、存储)【索引不分词存储】
Field filePathField = new StringField("path", filePath, Field.Store.YES);
//文件内容域(不分析、不索引、存储)【不索引不分词存储】
Field fileContentField = new StoredField("content",fileContent);
//创建document对象
Document document = new Document();
document.add(fileNameField);
document.add(fileContentField);
document.add(filePathField);
document.add(fileSizeField);
//创建索引,并写入索引库
indexWriter.addDocument(document);
}
//关闭indexwriter
indexWriter.close();
}
创建完成后的索引文件夹查看:
显然是看不了的,所以需要使用工具去看,就是luke,一定要注意,luke的版本一定要和lucene一毛一样,否则就出问题了,例如我这里使用的都是7.4.0版本。打开luke可以看到每个域拆分的关键字:
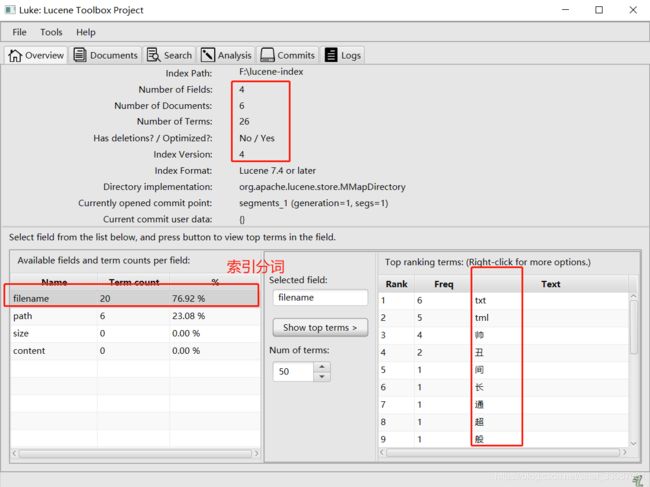
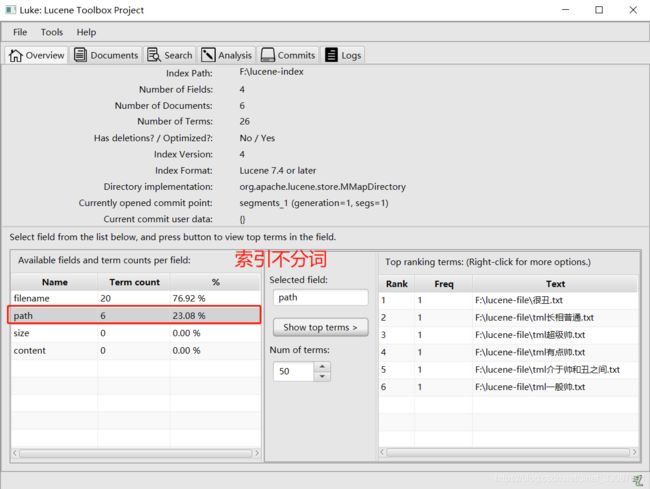

以及可以看到所有的文档,如果有存储,对应域上会有数据:
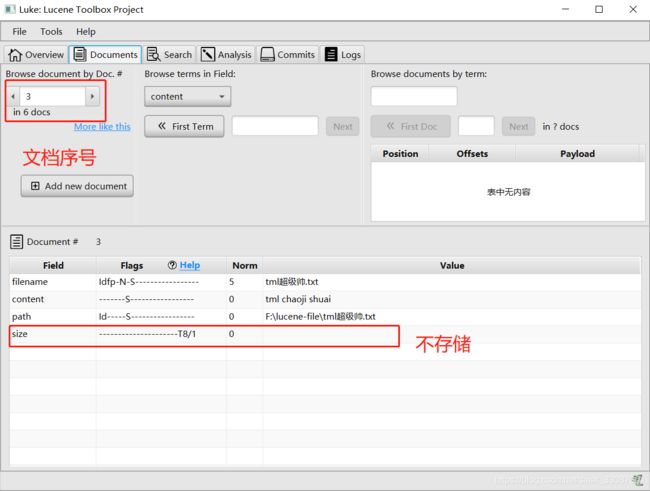
查询索引
查询索引的代码内容如下所示:
//查询索引
@Test
public void searchIndex() throws Exception {
//第一步:创建一个Directory对象,也就是索引库存放的位置。
Directory directory = FSDirectory.open(new File("F:\\lucene-index").toPath());
//第二步:创建一个indexReader对象,需要指定Directory对象。
IndexReader indexReader= DirectoryReader.open(directory);
//第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
//第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
TermQuery termQuery=new TermQuery(new Term("filename","丑"));
//第五步:执行查询。
TopDocs topDocs = indexSearcher.search(termQuery, 5); //查询参数和返回最大数
System.out.println("总命中数为"+topDocs.totalHits); //实际总命中数,不被返回数限制,就是真实的命中数
//第六步:返回查询结果。遍历查询结果并输出。
for (ScoreDoc scoreDoc:topDocs.scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("filename"));
System.out.println(document.get("path"));
System.out.println("-------------------------");
}
//第七步:关闭IndexReader对象
indexReader.close();
}
查询结果如下,共命中了两篇文档:
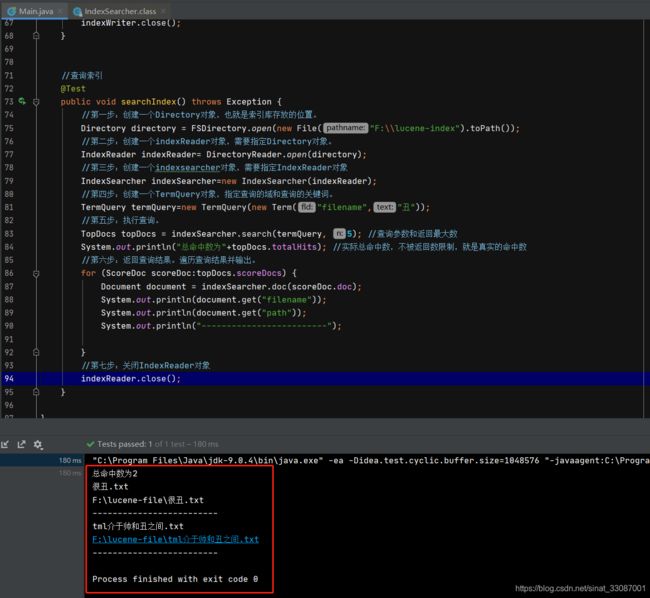
对于索引不分词的查询,只能输入全名,例如对路径查询,替换下terms:
//第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
TermQuery termQuery=new TermQuery(new Term("path","F:\\lucene-file\\tml一般帅.txt"));
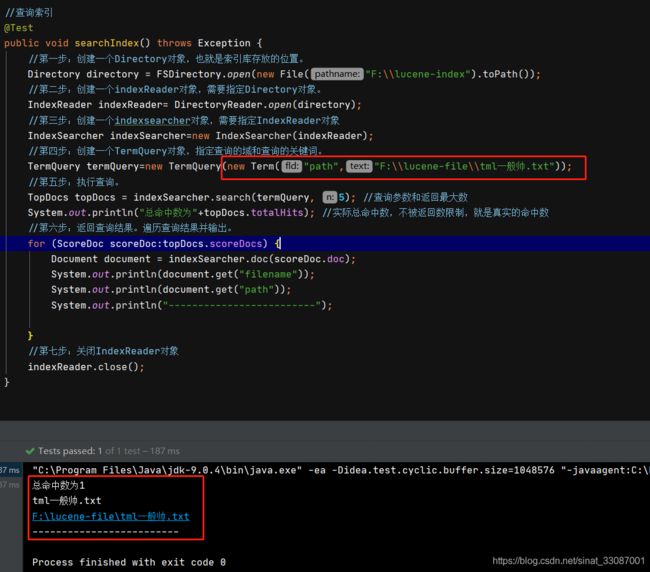
只搜帅或者tml这些关键词是搜不出来的,因为对于path域没有分过词:
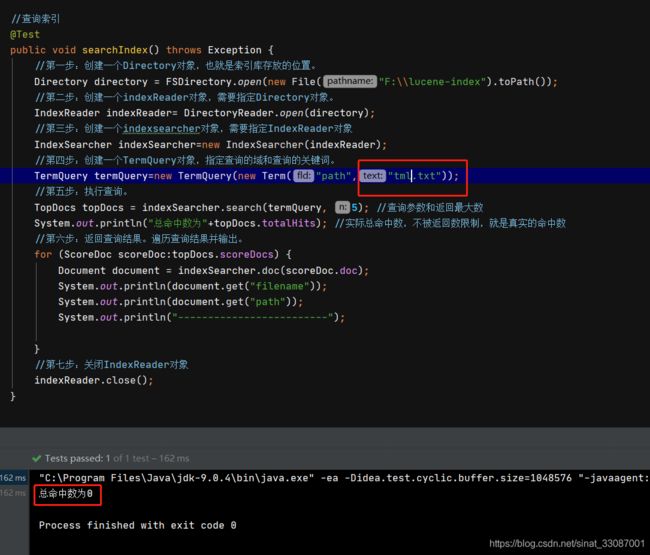
中文分词器的使用
Lucene标准的StandardAnalyzer只支持单个的中文字。例如:

所以,如果查询很丑一定是搜索不出来的,因为根本就还没索引到文档。

这个时候为了符合中国人的使用习惯,我们使用第三方的IK分词器。
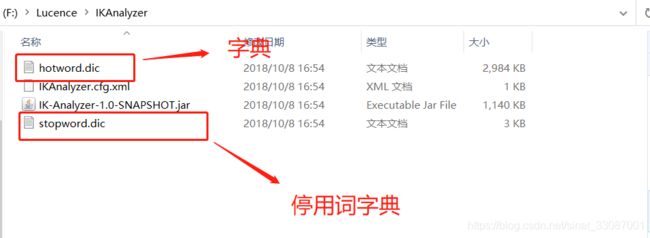
首先需要把Jar包导入到项目中,然后需要注意hotword.dic和ext_stopword.dic文件的格式为UTF-8,注意是无BOM 的UTF-8 编码。

调整下使用的分词器后,我们重建索引,写索引的时候使用IK分词器进行索引写入:

这个时候我们再看下分词效果,中文的词组就出来了。

那么为什么会这样呢?因为这些词都存在字典里,我们拿【很丑】举例:
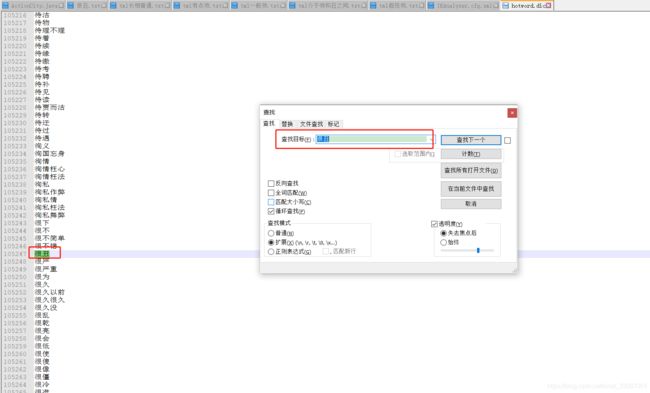
然后我们再来跑一遍程序,看看查询的时候是分词是否生效:

这个时候搜【很丑】就能命中文件了。
索引库维护
上小节搞定了索引的基本创建和查询以及中文分词器的使用,本小结来看看如何增、删、改、查索引库。
创建document对象
使用如下代码添加索引
//添加索引
@Test
public void addIndex() throws Exception {
Directory directory = FSDirectory.open(new File("F:\\lucene-index").toPath());
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory, config);
Document document=new Document();
//不同的document可以有不同的域,同一个document可以有相同的域。
document.add(new TextField("filename", "新添加的文档", Field.Store.YES));
document.add(new TextField("content", "新添加的文档的内容", Field.Store.NO));
//LongPoint创建索引
document.add(new LongPoint("size", 100000000l));
//StoreField存储数据
document.add(new StoredField("size", 100000000l));
//不需要创建索引的就使用StoreField存储
document.add(new StoredField("path", "F:\\lucene-file\\新添加的文档.txt"));
//添加文档到索引库
indexWriter.addDocument(document);
//关闭indexwriter
indexWriter.close();
}
添加完成后可以从luke里查看:
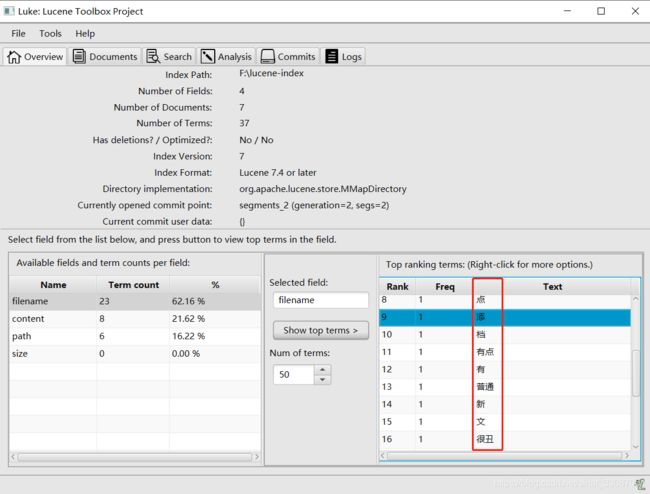
但是新添加三个字没有作为一个词出现,我们怎么才能查到呢?其实可以把新词添加到热词字典中:
代码中引入了词典配置后,在热词字典里添加上三个字新添加

这样再重建索引就能看到这三个词了

可以看到文档里也多了一条记录:

删除索引库
整库删除操作如下:
//删除索引
@Test
public void deleteIndex() throws Exception {
Directory directory = FSDirectory.open(new File("F:\\lucene-index").toPath());
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory, config);
//删除全部索引
indexWriter.deleteAll();
//关闭indexwriter
indexWriter.close();
}
可以看到相关索引文件已经没有了,但是文件夹还在

索引已经看不到了
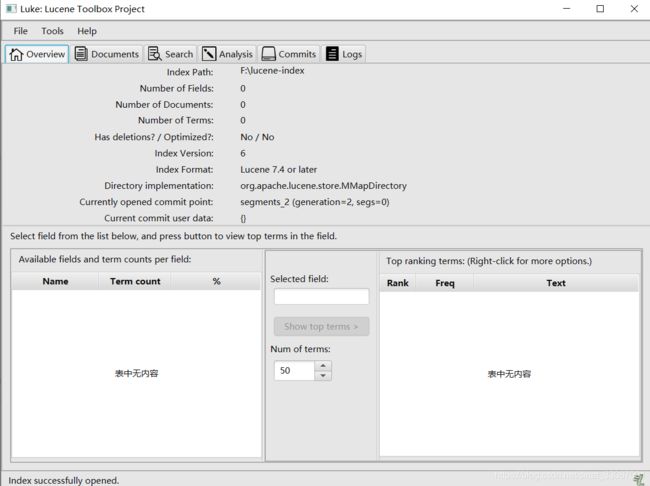
删除单条索引
使用如下代码删除所有标题包含tml的文件。
//删除指定查询条件索引
@Test
public void deleteSearchIndex() throws Exception {
Directory directory = FSDirectory.open(new File("F:\\lucene-index").toPath());
IndexWriterConfig config = new IndexWriterConfig(new IKAnalyzer());
IndexWriter indexWriter = new IndexWriter(directory, config);
//创建一个查询条件
Query query = new TermQuery(new Term("filename", "tml"));
//根据查询条件删除
indexWriter.deleteDocuments(query);
//关闭indexwriter
indexWriter.close();
}
再次查看,只能看到很丑.txt文档
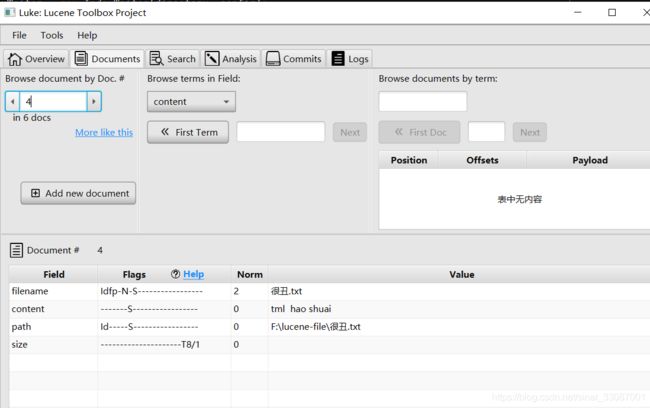
更新索引
原理就是先删除后添加。
@Test
public void updateIndex() throws Exception {
IndexWriter indexWriter = getIndexWriter();
//创建一个Document对象
Document document = new Document();
//向document对象中添加域。
//不同的document可以有不同的域,同一个document可以有相同的域。
document.add(new TextField("filename", "要更新的文档", Field.Store.YES));
document.add(new TextField("content", " Lucene 简介 Lucene 是一个基于 Java 的全文信息检索工具包," +
"它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。",
Field.Store.YES));
indexWriter.updateDocument(new Term("content", "java"), document);
//关闭indexWriter
indexWriter.close();
}
索引查询
索引查询有三种方式:term查询、数值范围查询以及queryparser查询,
Term Query查询
根据关键词进行查询,需要指定查询的域或关键词,我们以上用到的就是Term Query,在对应的域搜索中国人,能搜索到我是中国人。需要注意的是要查询的term必须是个关键词

RangeQuery查询
范围查询9000000到10000001中检测数值大小:
//数值范围查询
@Test
public void rangeSearchIndex() throws Exception {
//第一步:创建一个Directory对象,也就是索引库存放的位置。
Directory directory = FSDirectory.open(new File("F:\\lucene-index").toPath());
//第二步:创建一个indexReader对象,需要指定Directory对象。
IndexReader indexReader= DirectoryReader.open(directory);
//第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
Query query = LongPoint.newRangeQuery("size", 9000000l, 10000001l);
//执行查询
TopDocs topDocs = indexSearcher.search(query, 10);
//共查询到的document个数
System.out.println("查询结果总数量:" + topDocs.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("filename"));
//System.out.println(document.get("content"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
}
//关闭indexreader
indexSearcher.getIndexReader().close();
}
可以查到我们之前添加进去的文档

QueryParser 查询
当我们想通过一条语句去搜索所有相似记录的时候,通过关键词就不容易做到了,这个时候可以用QueryParser,当然要想使用需要引入相应的jar包:

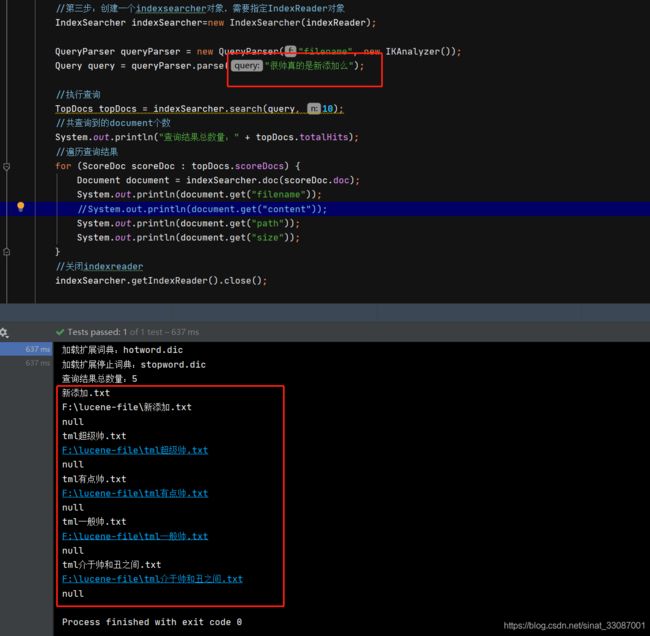
然后我们在程序中输入一段话很帅真的是新添加么,term是查不出来的。需要带分析的查询,queryparse会先将语句分词然后搜索按得分排列
//queryparse范围查询
@Test
public void querySearchIndex() throws Exception {
//第一步:创建一个Directory对象,也就是索引库存放的位置。
Directory directory = FSDirectory.open(new File("F:\\lucene-index").toPath());
//第二步:创建一个indexReader对象,需要指定Directory对象。
IndexReader indexReader= DirectoryReader.open(directory);
//第三步:创建一个indexsearcher对象,需要指定IndexReader对象
IndexSearcher indexSearcher=new IndexSearcher(indexReader);
QueryParser queryParser = new QueryParser("filename", new IKAnalyzer());
Query query = queryParser.parse("很帅真的是新添加么");
//执行查询
TopDocs topDocs = indexSearcher.search(query, 10);
//共查询到的document个数
System.out.println("查询结果总数量:" + topDocs.totalHits);
//遍历查询结果
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("filename"));
//System.out.println(document.get("content"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
}
//关闭indexreader
indexSearcher.getIndexReader().close();
}
这样,很帅和新添加相关文档都被搜索出来了
以上就是所有Lucene的基本概念和使用,下一篇blog正式进入ElasticSearch的入门和了解,其实大同小异,ElasticSearch就是对Lucene的封装而已