【ElasticSearch从入门到放弃系列 七】Spring Data Elasticsearch的使用
上一篇blog介绍了如何通过java客户端来操作ES,可以看到,操作还是很繁琐的,需要连接集群、开启客户端连接等一系列繁琐的动作,在正式介绍前,先了解下概念
- Spring Data:Spring Data 项目的目的是为了简化构建基于 Spring 框架应用的数据访问计数,包括非关系数据库、Map-Reduce 框架、云数据服务等等;另外也包含对关系数据库的访问支持,当然Spring Data Elasticsearch就是为了简化对Elasticsearch访问的一个Spring Data的子模块。可以理解为对现有Jar的一个框架级封装。
- Spring Data ElasticSearch: 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端API进行封装 。Spring Data为Elasticsearch项目提供集成搜索引擎。Spring Data Elasticsearch POJO的关键功能区域为中心的模型与Elastichsearch交互文档和轻松地编写一个存储库数据访问层
我们来看下实际的使用效果
环境搭建
分为以下几个步骤:实际上就是先创建JavaBean,然后去扫描JavaBean,在测试使用的时候直接注入该JavaBean去使用:
- 引入spring data elasticsearch命名空间:引入相关的spring data依赖
- 数据模型设置:编写实体Article和编写Dao
- 扫描数据模型:创建和配置配置applicationContext.xml
- 调用测试:创建测试类SpringDataESTest
实际上还是对Spring的一个使用。
引入spring data elasticsearch命名空间
引入Spring Data的相关依赖,包括其父模块spring以及自身,在pom.xml里添加依赖就可以了:
<!--指定编译来源为jdk1.9-->
<properties>
<maven.compiler.source>1.9</maven.compiler.source>
<maven.compiler.target>1.9</maven.compiler.target>
</properties>
<!--引入的es和es客户端的版本-->
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<!--引入的日志版本-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.24</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<!--引入的单元测试版本-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!--引入的json序列化版本-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.6</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.9.0</version>
</dependency>
<!--引入的spring data版本-->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>3.0.5.RELEASE</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>transport-netty4-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.0.4.RELEASE</version>
</dependency>
</dependencies>
编写实体Article并改装为JavaBean
@Document(indexName="tml_blog",type="article"):
indexName:索引的名称(必填项)
type:索引的类型
@Id:主键的唯一标识
@Field(index=true,analyzer="ik_smart",store=true,searchAnalyzer="ik_smart",type = FieldType.text)
index:是否设置分词
analyzer:存储时使用的分词器
searchAnalyze:搜索时使用的分词器
store:是否存储
type: 数据类型
package entity;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Document(indexName = "tml_spring_blog", type = "article")
public class Article {
@Id
@Field(type = FieldType.Long, store = true)
private long id;
@Field(type = FieldType.text, store = true, analyzer = "ik_smart")
private String title;
@Field(type = FieldType.text, store = true, analyzer = "ik_smart")
private String content;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "Article{" +
"id=" + id +
", title='" + title + '\'' +
", content='" + content + '\'' +
'}';
}
}
编写Dao
创建一个Dao,是一个接口,需要继承ElasticSearchRepository接口。
package dao;
import entity.Article;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
public interface ArticleRepository extends ElasticsearchRepository<Article, Long> {
List<Article> findByTitle(String title); //基于标题检索
List<Article> findByTitleOrContent(String title, String content);//基于标题或内容检索
List<Article> findByTitleOrContent(String title, String content, Pageable pageable);
}//基于标题或内容分页检索
配置applicationContext.xml
配置spring的启动扫描文件,扫描出elasticsearch的客户端对象和我们创建的数据模型对象
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/elasticsearch
http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch-1.0.xsd">
<!-- 配置elasticSearch的连接 -->
<elasticsearch:transport-client id="esClient" cluster-name="elasticsearch-tml" cluster-nodes="127.0.0.1:9300,127.0.0.1:9301,127.0.0.1:9302"/>
<!-- ElasticSearch模版对象 -->
<bean id="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="esClient"/>
</bean>
<!--配置包扫描器,扫描dao的接口-->
<elasticsearch:repositories base-package="dao"/>
</beans>
创建测试类SpringDataESTest
我们可以进行一个索引创建测试,代码如下,启动后直接扫描配置文件实例化对象,然后进行索引创建并直接创建对应type的映射。
import dao.ArticleRepository;
import entity.Article;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:applicationContext.xml")
public class SpringDataElasticSearchTest {
@Autowired
private ArticleRepository articleRepository;
@Autowired
private ElasticsearchTemplate template;
@Test
public void createIndex() throws Exception {
//创建索引,并配置映射关系
template.createIndex(Article.class);
}
}
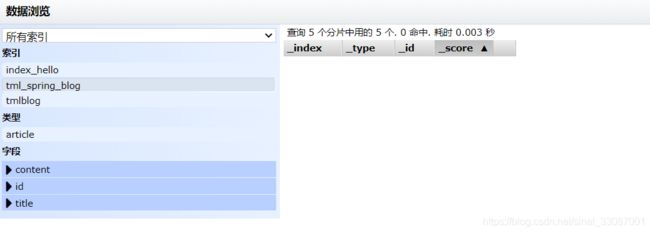
创建结果如下:

索引库维护
包括创建文档、依据id删除文档及删除全部文档
创建文档
我们可以通过循环批量创建文档:
@Test
public void addDocument() throws Exception {
for (int i = 10; i <= 20; i++) {
//创建一个Article对象
Article article = new Article();
article.setId(i);
article.setTitle("tml-spring" + i);
article.setContent("tml-spring帅丑结合");
//把文档写入索引库
articleRepository.save(article);
}
}

删除文档
可以通过id删除指定文档或全部文档:
@Test
public void deleteDocumentById() throws Exception {
articleRepository.deleteById(14l);
//全部删除
articleRepository.deleteAll();
}

也可以一次性删除所有文档:
查找文档
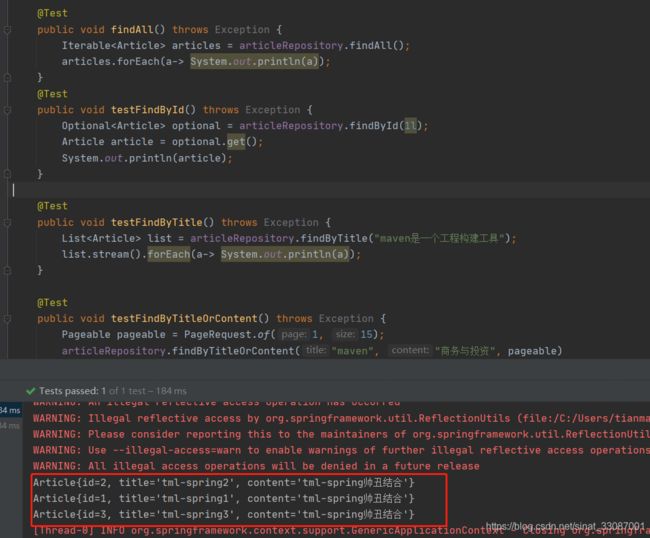
一次性找出全部文档,或依据id查找文档
@Test
public void findAll() throws Exception {
Iterable<Article> articles = articleRepository.findAll();
articles.forEach(a-> System.out.println(a));
}
@Test
public void testFindById() throws Exception {
Optional<Article> optional = articleRepository.findById(1l);
Article article = optional.get();
System.out.println(article);
}
复合查询
需要依据SpringDataES的明明规则来给接口命名,当然复合查询的时候也是queryString查询,查询内容先做分词再进去查询
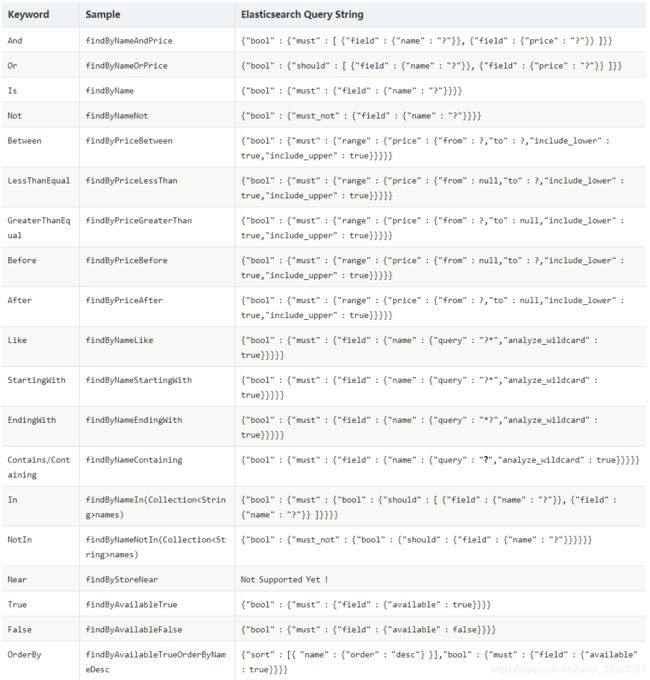
例如使用如下方式命名:
package dao;
import entity.Article;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
public interface ArticleRepository extends ElasticsearchRepository<Article, Long> {
List<Article> findByTitle(String title);
List<Article> findByTitleOrContent(String title, String content);
List<Article> findByTitleOrContent(String title, String content, Pageable pageable);
}
常用的有以下几种:

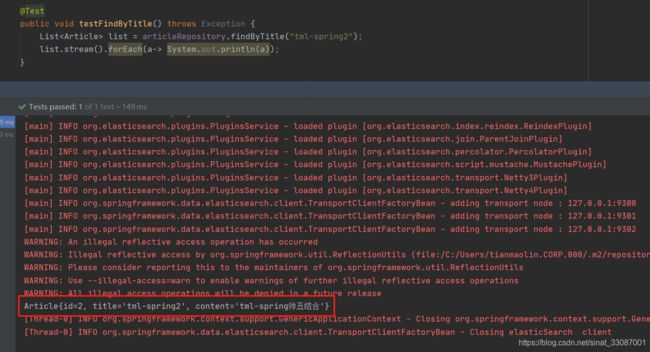
例如依据标题进行查询,语义为must,可以对搜索的内容先分词然后再进行查询。每个词之间都是and的关系。
@Test
public void testFindByTitle() throws Exception {
List<Article> list = articleRepository.findByTitle("tml-spring2");
list.stream().forEach(a-> System.out.println(a));
}
原生查询
可以调用原生的ES语句进行查询
@Test
public void testNativeSearchQuery() throws Exception {
//创建一个查询对象
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.queryStringQuery("帅").defaultField("content"))
.withPageable(PageRequest.of(0, 15))
.build();
//执行查询
List<Article> articleList = template.queryForList(query, Article.class);
articleList.forEach(a-> System.out.println(a));
}

以上就是所有关于Spring Data Elasticsearch的使用,实际上,就是将ES的原生操作依据我们的一些常用逻辑封装了方法,方便使用。