RDD 的转换可以产生新的 RDD。
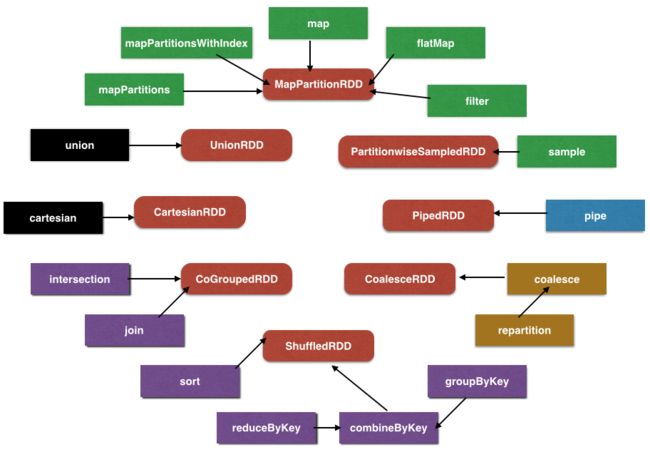
如上图,外圈是 RDD 的转换,内圈红色 RDD 是转换产生的新 RDD。
按颜色区分转换:
- 绿色是单 RDD 窄依赖转换
- 黑色是多 RDD 窄依赖转换
- 紫色是 KV 洗牌型转换
- 黄色是重分区转换
- 蓝色是特例的转换
单 RDD 窄依赖转换
MapPartitionRDD
这个 RDD 在第一次分析中已经分析过。简单复述一下:
- 依赖列表:一个窄依赖,依赖上游 RDD
- 分区列表:上游 RDD 的分区列表
- 计算流程:映射关系(输入一个分区,返回一个迭代器)
- 分区器 :上游 RDD 的分区器
- 存储位置:上游 RDD 的优先位置
可见除了计算流程,其他都是上游 RDD 的内容。
- map 传入一个带“值到值”转化函数的迭代器(例如字符串到字符串长度)
- mapPartitions 传入一个“迭代器到迭代器”的转化函数,如果需要按分区做一些比较重的过程(例如数据库连接等)
- flatMap 传入一个“迭代器到迭代器的迭代器”的转化函数(例如,统计字母,“字符串的迭代器”到“‘字符的迭代器’的迭代器”)
- filter 传入了一个带“值到布尔值”筛选函数的迭代器
PartitionwiseSampledRDD
在分区中采样的RDD
- 分区列表:在上游的分区的基础上包装一个采样过程,形成一个新的分区
PartitionwiseSampledRDDPartition - 计算流程:采样器返回的迭代器
- 其他成分:与上游 RDD 相同
PartitionwiseSampledRDD,有放回的采样用泊松采样器,无放回的采样用伯努利采样器,传给分区器。
多 RDD 窄依赖
UnionRDD
- 依赖列表:每个上游 RDD 一个
RangeDependency,每个RangeDependency依赖上游 RDD 的所有分区 - 分区列表:每个上游 RDD 一个
UnionPartition,构成列表 - 计算流程:获得目标分区的迭代器
- 分区器 :None
- 存储位置:每个上游 RDD 的优先位置
CartesianRDD
笛卡尔积,是两个 RDD 每个数据都进行一次关联。下文中两个 RDD 的关联中,两个 RDD 分别称为 rdd1、rdd2。
- 依赖列表:两个窄依赖组成的数组,分别依赖 rdd1、rdd2
- 分区列表:“rdd1的分区数 乘以 rdd2的分区数”个分区
- 计算流程:rdd1的一条记录与 rdd2的一条记录合成元组
- 分区器 :None
- 存储位置:rdd1、rdd2的存储位置的积
洗牌型转换
洗牌型转换,是多个 RDD 关联的的转换。
CoGroupedRDD
多个源 RDD 依据 key 关联,key 相同的合并,形成最终的目标 RDD。
- 依赖列表:每个源 RDD 一个依赖,构成列表。如果源 RDD 的分区器与目标的分区器相同,则是1-to-1依赖,如果不同,则是洗牌依赖
- 分区列表:目标 RDD 分区器指定的分区数量个
CoGroupPartition,每个分区记录了数据来源分区。其中如果是洗牌依赖的数据源,需要洗牌过程,具体洗牌过程以后再分析 - 计算流程:返回一个迭代器,迭代对象是 key 和 key 对应源分区迭代器的数组 组成的元祖
- 分区器 :目标 RDD 的分区器
- 存储位置:None
ShuffledRDD
同样是多个源 RDD 依据 key 关联,key 相同的做排序或聚合运算,形成最终的目标 RDD。
- 依赖列表:一个洗牌依赖,依赖所有上游 RDD
- 分区列表:目标 RDD 分区器指定的分区数量个
ShuffledRDDPartition,每个分区只有一个编号(因为每个上游分区) - 计算流程:洗牌过程,具体洗牌过程以后再分析
- 分区器 :目标 RDD 的分区器
- 存储位置:None
除了这五个成员以外,还有另外几个重要的成员:序列化器、key 排序器、聚合器、map 端合并器,他们都将用于洗牌
其他
- coalesce,是减少分区数量,可以在过滤之后,使数据更集中,以提高效率
- repartition,是重新分区,增加或减少分区数量,数据随机重新分配,可以消除分区间的数据量差异
- pipe,是与外部程序管道关联,从外部程序中获取数据。
Scala语法
在 RDD.scala中,几乎每一个转换和操作函数都会有一个withScope,例如:
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}
withScope是一个函数,调用了RDDOperationScope.withScope方法:
private[spark] def withScope[U](body: => U): U = RDDOperationScope.withScope[U](sc)(body)
withScope就像是一个 AOP(面向切面编程),嵌入到所有RDD 的转换和操作的函数中,RDDOperationScope会把调用栈记录下来,用于绘制Spark UI的 DAG(有向无环图,可以理解为 Spark 的执行计划)。
我们用下面的代码简单演示一下 Scala 用函数做 AOP:
object Day1 {
def main(args: Array[String]) = {
Range(1,5).foreach(twice)
println()
Array("China", "Beijing", "HelloWorld").foreach(length)
}
def twice(i: Int): Int = aopPrint {
i * 2
}
def length(s: String): Int = aopPrint {
s.length
}
def aopPrint[U](i: => U): U = {
print(i + " ")
i
}
}
aopPrint的 入参是“一个返回类型为U的函数”。这段程序中aopPrint就是一个模拟的切面,作用是把所有的函数返回值打印出来。结果是:
2 4 6 8
5 7 10
从代码上看,aopPrint并没有降低代码的可读性。读者依然能很清楚地读懂twice和length函数。打印返回结果这个流程是独立于函数之外的切面。
结论
- RDD 的转换分图上几种
- RDD 的转换可以看成是产生新的 RDD,而新的 RDD 记录了每一个分区依赖上游的哪些分区、每个分区如何用上游分区计算而来
本文源码
spark/core/rdd包下的部分 RDD 类spark/core/src/main/scala/org/apache/spark/rdd at master · apache/spark · GitHub
@ Kangying Village, Beijing, China